Introduction
The document site for light-portal application.
Architecture
Design
Light Portal is an application that connect the providers to the consumers, and it contains many components or applications. Each component will have some API endpoints and a user interface in the portal view single page application.
To allow the users to understand each component in detail in term of design, we have collected all the design documents in this section.
Portal View
Mutliple Environment
This document outlines the necessary changes to configure portal view to work dynamically across different environments (sdx, dev, non-prod, prod) using environment-specific configuration.
1. Environment Variables Setup
Create .env File
Create environment-specific .env files in project root:
# Environment variables
# VITE_BASE_PATH is used as the base URL prefix for API calls.
VITE_BASE_PATH=/bff/admin/
# VITE_PORTAL_URL is the full absolute URL where the frontend static files are served
VITE_PORTAL_URL=https://sdx.lightapi.net/bff
Required Environment Variables
- VITE_BASE_PATH: Defines the sub-path where your application is deployed.
- VITE_PORTAL_URL: The API endpoint base URL.
Benefits of .env Configuration
- Switch environments without code changes
- Maintain a single codebase for all environments
2. Vite Configuration Changes
File: vite.config.js
Location: Project root
Required Change:
import { defineConfig, loadEnv } from 'vite';
import react from '@vitejs/plugin-react';
export default defineConfig(({ mode }) => {
const env = loadEnv(mode, process.cwd(), '');
return {
plugins: [react()],
base: env.VITE_BASE_PATH || "/",
// ... other configurations
};
});
Why This Change is Necessary?
The Problem Without base Configuration
When your application is deployed to a sub-path rather than the domain root, all asset references break.
| Deployment Scenario | Required base Value |
|---|---|
https://example.com/ | "/" (default) |
https://example.com/portal/ | "/portal/" |
https://example.com/app/v2/ | "/app/v2/" |
What base Affects
The base configuration controls how Vite prefixes:
- Static asset URLs (JavaScript, CSS, images, fonts)
- Client-side routing paths
- Public folder references
Example: Without vs With base
Without base Configuration:
- App hosted at:
https://example.com/portal/ - Vite generates:
<script src="/assets/index.js"> - Browser requests:
https://example.com/assets/index.js - Result: 404 Not Found ❌
With base: “/portal/”:
- App hosted at:
https://example.com/portal/ - Vite generates:
<script src="/portal/assets/index.js"> - Browser requests:
https://example.com/portal/assets/index.js - Result: Success ✅
3. React Router Configuration Changes
File: App.tsx
Location: src/App.tsx
Required Change:
import { BrowserRouter } from 'react-router-dom';
function App() {
const basename = import.meta.env.VITE_BASE_PATH || "/";
return (
<BrowserRouter basename={basename}>
{/* Your app routes and components */}
</BrowserRouter>
);
}
export default App;
What basename Does
The basename prop tells React Router the base URL prefix for all routes in your application.
Routing Behavior Comparison
| Scenario | Without basename | With basename=“/portal” |
|---|---|---|
<Link to="/dashboard"> | Navigates to /dashboard | Navigates to /portal/dashboard |
path="/settings" matches | /settings | /portal/settings |
useNavigate("/login") | Goes to /login | Goes to /portal/login |
Why It’s Required
When your app is hosted at a sub-path (e.g., https://example.com/portal/), React Router needs to know that /portal is the deployment prefix, not part of your route definitions.
Without basename:
- You define
<Route path="/dashboard" /> - User visits
/portal/dashboard - React Router sees
/portal/dashboard→ no match → Route Not Found ❌
With basename="/portal":
- React Router strips
/portalfrom the URL - Sees
/dashboard→ matches your route → Success ✅
4. API Call Configuration
Current Behavior Issue
Without a configured base URL, the browser constructs API request URLs relative to the current page origin.
Example:
- App running at:
https://example.com/portal/dashboard - API call:
fetch('/api/users') - Browser sends request to:
https://example.com/api/users
This may work in some cases but breaks when:
- API is hosted on a different domain/subdomain
- API has a different base path
- Cross-environment consistency is needed
Solution: Custom Fetch Wrapper
File: src/utils/fetchClient.js
const BASE_URL = import.meta.env.VITE_API_BASE_URL || "";
/**
* Custom fetch wrapper with automatic base URL prefixing
* @param {string} endpoint - API endpoint path (e.g., '/api/users')
* @param {Object} options - Fetch options (method, headers, body, etc.)
* @returns {Promise} - Response JSON
*/
async function fetchClient(endpoint, options = {}) {
const url = `${BASE_URL}${endpoint}`;
const defaultHeaders = {
"Content-Type": "application/json",
};
const config = {
...options,
headers: {
...defaultHeaders,
...options.headers,
},
};
const response = await fetch(url, config);
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
}
export default fetchClient;
Usage Example
import fetchClient from './utils/fetchClient';
// GET request
const users = await fetchClient('/api/users');
// POST request
const newUser = await fetchClient('/api/users', {
method: 'POST',
body: JSON.stringify({ name: 'John Doe', email: '[email protected]' }),
});
// With custom headers
const data = await fetchClient('/api/protected', {
headers: {
'Authorization': `Bearer ${token}`,
},
});
Benefits
- Consistency: All API calls use the same base URL
- Environment flexibility: Different API endpoints per environment
- Maintainability: Single place to update API configuration
- Error handling: Centralized response validation
5. Build and Deployment Steps
Step 1: Change the .env variables for specific environment (sdx, dev, prod etc.)
VITE_BASE_PATH=/ (base path)
VITE_PORTAL_URL=https://example.com (endpoint URL)
Step 2: Build
npm run build
MCP Registry Design for AI Gateway
This document outlines the registration and management strategy for Model Context Protocol (MCP) tools within the AI Gateway.
Registration Strategy: The Hybrid Model
For a robust and scalable AI Gateway, the recommended approach is a Hybrid Model: Register the MCP Server as the primary entity, but manage and expose the Tools individually.
This approach balances the technical requirements of connectivity with the operational requirements of governance, security, and performance.
1. Register the Server (The “Connection” Layer)
The MCP Server should be treated as the source of truth and the primary unit of connectivity.
- Centralized Configuration: Authentication (API keys, OAuth), base URLs, transport protocols (SSE or Stdio), and environment variables are defined at the server level.
- Connectivity Management: A single server acts as a wrapper around related APIs. Registering tools individually would create significant overhead and redundant connections.
- Lifecycle & Health Monitoring: If an MCP server goes down, all its tools become unavailable. It is more efficient to monitor health and availability at the server level.
- Dynamic Discovery: The MCP protocol includes a
tools/listcapability. By registering the server, the gateway can automatically sync and discover new tools when the server is updated, eliminating the need for manual registration of every new function.
2. Expose Tools Individually (The “Governance” Layer)
While the gateway connects to the server, it should expose and manage tools as individual objects. This is crucial for:
- Granular Permissions (RBAC): Access control can be applied at the tool level. For example, a “Finance” team might be granted access to a
get-invoicetool but restricted from amodify-ledgertool, even if both reside on the same ERP server. - Context Window Optimization: Large Language Models (LLMs) have limited context windows. Sending all 50 tools from a large server to an LLM wastes tokens and increases the “lost in the middle” effect. The Gateway should allow for the activation of specific subsets of tools for a given AI session or agent.
- Rate Limiting & Cost Control: High-compute or high-cost tools (e.g.,
generate-video) can be rate-limited or billed differently compared to lightweight tools (e.g.,get-weather). - Safety & Compliance: Metadata can be attached to individual tools to flag them as
Read-Only,Destructive, orSensitive, enabling specific security flows (like “Human-in-the-loop” approvals) for risky operations.
Recommended Architecture: The “Catalog” Pattern
The implementation should follow a “Catalog” or “App Store” pattern:
- Provider/Server Registration: An admin registers a server (e.g., “The GitHub MCP Server”) with its credentials.
- Automated Discovery: The Gateway calls the server’s
list_toolsmethod and populates a tool catalog. - Governance & Activation: Admins “enable” specific tools for specific model configurations or user groups.
- Routing Layer: When a model requests a tool, the Gateway resolves the request to the owning Server and handles the underlying communication.
Comparison of Approaches
| Feature | Individual Registration | Group (Server) Registration | Recommended: Hybrid |
|---|---|---|---|
| Management | Extremely difficult (manual entry for every tool) | Easy (single connection) | Optimal (Auto-sync tools from server) |
| Security | Granular (Tool-level RBAC) | Coarse (All-or-nothing access) | Granular (Policy per tool) |
| LLM Context | Precise | Potential for bloating | Precise (Selectable subsets) |
| Maintenance | High (Breaks if tool name changes) | Low | Low (Unified lifecycle) |
| Connectivity | Redundant connections | Efficient | Efficient (One connection, many tools) |
Data Model & Schema Design
The AI Gateway leverages the existing API registry schema used by light-gateway, with specific enhancements to accommodate the unique requirements of the MCP protocol.
Conceptual Mapping
| MCP Concept | light-gateway Table | Mapping Strategy |
|---|---|---|
| MCP Server | api_t | Represents the top-level service (e.g., “Postgres MCP Server”). |
| Server Instance | api_version_t | Manages the connectivity parameters and the overall tool manifest. |
| MCP Tool | api_endpoint_t | Each tool is registered as an individual endpoint belonging to an MCP version. |
| Tool Permissions | api_endpoint_scope_t | Handles RBAC and scope-based access to specific tools. |
Core Tables & Enhancements
To support MCP, the following schema adjustments are implemented:
1. API Version (Server Connection)
The api_version_t table is enhanced to store transport-level configurations for stdio or SSE connections.
ALTER TABLE api_version_t ADD COLUMN transport_config TEXT;
-- JSON Example for transport_config:
-- {"transport": "stdio", "command": "npx", "args": ["-y", "@mcp/server-google"]}
2. API Endpoint (Tool Definition)
The api_endpoint_t table acts as the tool registry. We relax the traditional HTTP method constraints and add fields for MCP tool metadata.
-- Allow 'call' as a valid operation for MCP tools
ALTER TABLE api_endpoint_t DROP CONSTRAINT api_endpoint_t_http_method_check;
ALTER TABLE api_endpoint_t ADD CHECK ( http_method IN ( 'delete', 'get', 'patch', 'post', 'put', 'call' ) );
-- Store the Tool Schema (for LLM validation) and Metadata (for safety flags)
ALTER TABLE api_endpoint_t ADD COLUMN tool_schema TEXT; -- JSON Schema of the tool inputs
ALTER TABLE api_endpoint_t ADD COLUMN tool_metadata TEXT; -- e.g., {"destructive": true, "read_only": false}
Full Registry Schema Reference
-- API Definition (The MCP Server)
CREATE TABLE api_t (
host_id UUID NOT NULL,
api_id VARCHAR(16) NOT NULL,
api_name VARCHAR(128) NOT NULL,
api_desc VARCHAR(1024),
api_status VARCHAR(32) NOT NULL,
active BOOLEAN NOT NULL DEFAULT TRUE,
PRIMARY KEY (host_id, api_id)
);
-- API Version (The Connection/Transport)
CREATE TABLE api_version_t (
host_id UUID NOT NULL,
api_version_id UUID NOT NULL,
api_id VARCHAR(16) NOT NULL,
api_version VARCHAR(16) NOT NULL,
api_type VARCHAR(7) NOT NULL, -- 'mcp', 'openapi', etc.
transport_config TEXT, -- MCP-specific connection data
spec TEXT, -- Full tool manifest (optional)
active BOOLEAN NOT NULL DEFAULT TRUE,
PRIMARY KEY(host_id, api_version_id),
FOREIGN KEY(host_id, api_id) REFERENCES api_t(host_id, api_id) ON DELETE CASCADE
);
-- API Endpoint (The Individual Tool)
CREATE TABLE api_endpoint_t (
host_id UUID NOT NULL,
endpoint_id UUID NOT NULL,
api_version_id UUID NOT NULL,
endpoint VARCHAR(1024) NOT NULL, -- Tool Name
http_method VARCHAR(10), -- 'call' for MCP
endpoint_name VARCHAR(128) NOT NULL,
endpoint_desc TEXT,
tool_schema TEXT, -- Input parameter validation
tool_metadata TEXT, -- Safety and cost metadata
active BOOLEAN NOT NULL DEFAULT TRUE,
PRIMARY KEY(host_id, endpoint_id),
FOREIGN KEY(host_id, api_version_id) REFERENCES api_version_t(host_id, api_version_id) ON DELETE CASCADE
);
Tool Metadata & Synchronization
Populating the api_endpoint_t table involves coordinating data from the MCP Server with operational policies defined within the AI Gateway.
Sources of Metadata
The metadata for each tool is synthesized from three primary sources:
1. Standard MCP Server Response (Automated)
When the Gateway performs a tools/list call, the MCP server provides the baseline technical definition for each tool.
- Source Fields:
name,description,inputSchema. - Mapping: These are mapped directly to
endpoint,endpoint_desc, andtool_schemarespectively.
2. Gateway Operational Enrichment (Manual/Policy)
Since the standard MCP protocol does not include operational flags (like safety or cost), the AI Gateway manages these in the tool_metadata JSON column.
- Administrative Enrichment: Platform admins use the Gateway UI to tag specific tools. Common tags include:
destructive: true: Triggers a warning or confirmation flow.human_approval_required: true: Places the request in a queue for manual sign-off.cost_tier: "high": Used for rate-limiting or internal billing.
- Heuristic Auto-Tagging: The Gateway can automatically infer metadata based on patterns. For example, any tool starting with
get_orlist_is auto-flagged asread_only: true.
3. Protocol Extensions (Custom)
The MCP specification allows for additional properties in the tool object. If a custom MCP server includes an extra metadata or annotations block, the Gateway’s synchronization logic can be configured to capture and store these directly.
Synchronization Workflow
The following lifecycle ensures the Gateway’s registry remains accurate:
- Connection: The Gateway establishes a connection to the server using the
transport_config. - Discovery (Sync): The Gateway calls
tools/listand performs an “upsert” for all tools found.- Existing tools have their
tool_schemaandendpoint_descupdated. - New tools are created with a default
activestatus and baselinetool_metadata.
- Existing tools have their
- Review: An administrator reviews the newly discovered tools in the Gateway dashboard.
- Governance Policy: The administrator “enables” the tool for specific roles and configures any required safety metadata (e.g., flagging the
drop_tabletool asdestructive). - LLM Execution: When a model calls the tool, the Gateway uses the stored
tool_schemafor pre-flight validation and thetool_metadatato enforce security policies.
Too Many Pages/Forms
The portal has accumulated many pages, generated forms, custom admin screens, and feature-specific entry points. The sidebar can expose these pages, but it does not help a user understand which pages are required to finish a real business task. The MCP Gateway quick start wizard is a useful experiment, but it also shows the limitation of a rigid linear wizard: real tasks have optional steps, pre-existing data, and multiple valid starting points.
This document proposes a task-oriented navigation layer for portal-view.
Problem
Users currently need to know the portal information architecture before they can complete a task. For example, onboarding an API to MCP Gateway may require some combination of:
- create or select an API
- create or select an API version
- link the API version to a gateway or sidecar instance
- select MCP tools
- configure access control
- revisit instance, API, or role administration later
The same pattern exists across other areas. A task is not a single route; it is a sequence of related pages and forms. The current navigation model makes users pick pages first, then infer the task process themselves.
Current MCP Wizard Observation
The MCP Gateway wizard already has useful building blocks:
flowConfig.tsxkeeps step metadata in one place.McpServerForm.tsxrenders a generic wizard shell.useMcpPrefill.tscan resume from URL context such asapiId,apiVersionId, andinstanceApiId.- Several steps are marked skippable.
However, the wizard is still too rigid:
- Step order is linear even when the task is naturally conditional.
- Initial step selection relies on hard-coded step numbers.
- Optional work is represented as skip buttons instead of task state.
- The wizard duplicates or wraps existing forms instead of treating existing pages/forms as first-class task steps.
- The solution is specific to MCP Gateway and does not help users navigate the rest of the portal.
Design Goals
- Let users start from a task, not a page name.
- Keep existing pages and generated forms as the source of truth.
- Support multiple entry points into the same task.
- Detect what has already been completed and show only relevant next actions.
- Support optional, required, blocked, complete, and skipped steps.
- Preserve role-based visibility and host-specific context.
- Allow users to leave a task, return later, and continue from context.
- Make the approach reusable for MCP, API publishing, access control, deployment, config promotion, migration, and admin workflows.
Non-Goals
- Do not replace every admin page with a wizard.
- Do not create a separate custom form for each task if an existing generated form already works.
- Do not use the sidebar as the only navigation surface.
- Do not force a strict step sequence when the data model allows safe jumping.
Proposed Solution
Add a task-oriented navigation layer above the current pages/forms.
The main pieces are:
- Task Center
- Task Registry
- Task Progress Resolver
- Task Navigation Shell
- Global Search and Command Palette
- Contextual Next Actions
Task Center
The Task Center is a page where users choose what they want to accomplish. It should group work by intent, not by implementation table.
Example task groups:
- API Marketplace
- Register a new API
- Add an API version
- Publish an API
- Review API details
- MCP Gateway
- Onboard an existing API to MCP Gateway
- Register a standalone MCP server
- Configure MCP tools
- Configure MCP access control
- Access Control
- Create role
- Assign permissions
- Configure endpoint access
- Platform Operations
- Register controller/gateway instance
- Link API version to instance
- Promote configuration
- Portal Administration
- Manage host users
- Export/import portal data
- Convert migration snapshot
Each task card should show:
- title
- short description
- required role
- common starting object, such as API, instance, host, or client
- progress status when the current context is known
- primary action such as Start, Continue, Review, or Fix Missing Step
Task Registry
Introduce a registry that describes tasks and steps declaratively. This is the
generalized version of the current MCP flowConfig.tsx, but it should route to
existing pages/forms instead of rendering every step inside one wizard.
Example TypeScript shape:
export type TaskDefinition = {
id: string;
title: string;
description: string;
category: string;
roles?: string[];
keywords: string[];
entryPoints: TaskEntryPoint[];
steps: TaskStep[];
};
export type TaskStep = {
id: string;
title: string;
description?: string;
required: boolean;
dependsOn?: string[];
route: (ctx: TaskContext) => string;
formId?: string;
completeWhen?: TaskCompletionCheck;
visibleWhen?: TaskVisibilityCheck;
blockedWhen?: TaskBlockedCheck;
};
The task registry should live close to portal navigation code, for example:
src/tasks/taskRegistry.ts
src/tasks/taskTypes.ts
src/tasks/resolvers/
src/pages/tasks/TaskCenter.tsx
src/pages/tasks/TaskDetail.tsx
Page And Form Metadata
To make search and tasks work well, pages and generated forms need metadata.
For generated forms, the metadata can come from Forms.json plus a small
registry override when the form title is not enough.
For custom pages, add a route/page registry:
export type PageDefinition = {
route: string;
title: string;
description?: string;
category: string;
roles?: string[];
keywords: string[];
entities?: string[];
};
This registry can feed:
- sidebar sections
- Task Center
- command palette
- page breadcrumbs
- contextual next actions
The important rule is that page/form metadata should be reused, not copied into each wizard.
Task Progress Resolver
A task should not blindly ask users to complete steps that are already done. Each task can have a resolver that checks the current host and entity context.
For MCP Gateway, the resolver can check:
- API exists
- API version exists
- instance API link exists
- MCP tool configuration exists
- access control exists
The UI then marks each step:
- Complete
- Required
- Optional
- Blocked
- Skipped
- Needs review
The resolver should use existing query endpoints where possible. The first implementation can query on page load. Later, it can cache per task/session.
Task Navigation Shell
Instead of a full-screen wizard that owns all steps, use a task shell that can wrap or accompany existing pages.
Recommended behavior:
- A task detail page shows the checklist and current state.
- Selecting a step navigates to the existing page/form with task context in the URL or router state.
- The target page shows a compact “Task” panel or return link.
- After save, the user can return to the checklist or continue to the next recommended step.
Example URL:
/app/form/createService?task=mcp-onboard-api&returnTo=/app/tasks/mcp-onboard-api
This keeps existing page behavior intact while adding guided navigation.
Global Search And Command Palette
The portal should have a global launcher. It should search tasks, pages, forms, and entities.
Examples:
- “onboard mcp”
- “create api”
- “auth client”
- “relation type”
- “instance api”
- “export snapshot”
Search results should be role-aware and host-aware.
Result types:
- Task
- Page
- Form
- Entity
- Recent item
This is the fastest way to help expert users without forcing them through a wizard.
Contextual Next Actions
Detail pages should expose next actions based on the current entity.
Examples:
- API detail
- Add version
- Link version to gateway
- Configure MCP tools
- Configure access control
- Instance detail
- Link API version
- Configure MCP tools
- View gateway servers
- Auth client detail
- Assign owner
- Review sessions
- Review audit
- Snapshot export
- Convert snapshot
- Import snapshot
These actions should come from the same task registry, not from one-off buttons hard-coded on every page.
MCP Gateway Example
The MCP Gateway quick start can be rebuilt as a task:
Task: Onboard API to MCP Gateway
Steps:
1. Select or create API
2. Select or create API version
3. Choose deployment mode
4. Link API version to gateway or sidecar instance
5. Select MCP tools
6. Configure access control
Step behavior:
- API selection is required unless
apiIdis already provided. - API version is required unless
apiVersionIdis already provided. - Spec upload is optional and only shown when creating a new API/version.
- Deployment mode is required when the version is not linked.
- Gateway selection is required only for centralized deployment.
- Tool selection is optional if users only want to register the server first.
- Access control is optional but should be shown as a recommended final step.
This task can support several entry points:
/app/tasks/mcp-onboard-api
/app/tasks/mcp-onboard-api?apiId=...
/app/tasks/mcp-onboard-api?apiId=...&apiVersionId=...
/app/tasks/mcp-onboard-api?instanceApiId=...
The UI should not rely on fixed step numbers. It should compute visible steps from the task context and completion state.
Task State
Start with client-side state:
- URL query parameters for entity context
sessionStoragefor in-progress task context- existing backend records for real completion state
Later, add persisted task state if needed:
- user id
- host id
- task id
- context JSON
- skipped step ids
- last active step
- updated timestamp
Persisting task state should not become the source of truth for business data. It should only remember navigation state and user choices. Completion should be derived from actual portal records.
Sidebar Role
The sidebar should become smaller and more stable. It should expose major areas, not every page/form.
Recommended sidebar sections:
- Home
- Tasks
- Marketplace
- MCP Gateway
- Operations
- Administration
Deep links should still exist, but they should be discoverable through search, contextual actions, and task detail pages.
Implementation Plan
Phase 1: Inventory And Metadata
- Create page/form metadata registry.
- Add task registry types.
- Register the most-used pages and forms.
- Add global search over registered tasks/pages/forms.
Phase 2: Task Center
- Add
/app/tasks. - Add task category cards.
- Add task detail checklist page.
- Implement client-side task context with URL parameters and session storage.
Phase 3: MCP Gateway Task
- Convert the current MCP wizard flow into
mcp-onboard-apitask definition. - Reuse existing MCP components for the pages that still need custom UI.
- Replace hard-coded step numbers with resolver-driven visible steps.
- Add return-to-task behavior after saves.
Phase 4: Contextual Actions
- Add task actions to API detail and instance detail pages.
- Add task actions to access control and config pages where appropriate.
- Use the task registry to drive action visibility.
Phase 5: Broader Rollout
- Add tasks for API publishing, config promotion, host/user management, and snapshot export/import.
- Reduce sidebar clutter once task/search usage is available.
- Add persisted task state only if session storage is not enough.
Risks And Mitigations
| Risk | Mitigation |
|---|---|
| Task registry duplicates sidebar and route definitions | Reuse page/form metadata as the source for labels, roles, and keywords |
| Task state becomes stale | Derive completion from backend records, not saved task status |
| Users lose flexibility | Allow direct page navigation and command-palette search |
| Implementation grows into another wizard framework | Route to existing pages/forms wherever possible |
| Role filtering becomes inconsistent | Centralize role checks in the page/task registry |
Recommendation
Keep the MCP Gateway wizard as a prototype, but do not build more isolated wizards in the same style. The long-term solution should be:
- a task registry
- a Task Center
- resolver-driven progress
- global search
- contextual next actions
- reuse of existing pages and generated forms
This gives new users guided paths while still letting experienced users jump directly to the page or form they already know.
Config Update Page
The current portal-view configuration admin area is complete but split across
many table pages and generated forms. A customer Settings page shows a denser
workflow: list applicable config properties in a tree, edit scalar values
inline, and open a modal for list/map values. This document proposes a similar
page for portal-view that can update config property overrides at the
environment, product, product version, instance, API, app, and app-api levels.
In this document, API, app, and app-api mean the instance-linked config
override scopes represented by instanceApiId, instanceAppId, and
instanceApiId + instanceAppId.
Current Implementation
The customer Settings implementation is centered on these files:
Settings.jsxSettingsListView.jsxSettingsListMapModal.jsxInputForm.jsxJsonSchemaForm.jsx
The useful behavior is:
- one page loads applicable config properties and the current custom values
- properties are displayed as a tree under
configName - scalar values are edited inline
- list and map values open a modal with form, raw JSON, and raw YAML tabs
- save chooses create or update based on whether the override exists
- delete removes the override and lets the inherited value show again
The customer implementation currently handles instance, instance API, instance
app, and instance app API targets. It chooses the query/write action from
instanceId, instanceApiId, and instanceAppId.
portal-view already has separate config override pages:
src/pages/config/ConfigEnvironment.tsxsrc/pages/config/ConfigProduct.tsxsrc/pages/config/ConfigProductVersion.tsxsrc/pages/config/ConfigInstance.tsxsrc/pages/config/ConfigInstanceApi.tsxsrc/pages/config/ConfigInstanceApp.tsxsrc/pages/config/ConfigInstanceAppApi.tsx
Those pages use Material React Table, fetch one override aggregate at a time,
and navigate to generated react-schema-form routes for create/update. The form
definitions live in src/data/Forms.json, and the generic form runner is
src/components/Form/Form.tsx.
The existing form approach works for CRUD, but it is inefficient for config editing because the user must pick a config, pick a property, leave the list page, edit one value, and return.
Goals
- Provide a single task-oriented config editor for the seven override scopes.
- Show the property catalog and current override values together.
- Preserve the existing config-command write APIs.
- Preserve optimistic concurrency by carrying
aggregateVersionfor existing override rows. - Avoid client-side joins across independently paginated result sets.
- Keep existing table pages and generated forms available as admin fallback routes.
- Support scalar editing inline and structured list/map editing in a modal.
- Show inherited/default value and custom override value separately.
- Make delete/reset mean “remove this override”, not “delete the base property”.
- Support read-only and hidden states when the user lacks write permission for a scope or target.
Non-Goals
- Do not replace
react-schema-formglobally. - Do not replace the existing config list pages during the first release.
- Do not edit
FileorCertproperty values inline in the first release. Those can continue to use existing generated forms. - Do not require every config property to have a typed form schema before the page is useful.
- Do not add a bulk transaction command in the first release. The UI can stage multiple changes and then orchestrate the existing single-row commands.
Recommended UX
Add a Config Update page under the configuration task area. The first row is
a scope and target selector:
- Scope: Environment, Product, Product Version, Instance, API, App, App API
- Target: the selected scope’s identity, such as
environment,productId,productVersionId,instanceId,instanceApiId,instanceAppId, or both app/API ids for app-api - Optional filters: config phase, config type, property type, resource type, and “show overridden only”
- Save mode: staged changes by default, with optional single-row Apply for quick edits
Below the selectors, render a tree/table:
- group rows by
configName - property leaf rows show
propertyName - columns: value type, inherited value, override value, effective source, required, resource type, config phase, description, status
- row status: inherited, overridden, dirty, saving, conflict, error
- toolbar actions: expand all, collapse all, refresh, reset override, review changes, apply changes
- row action menu: view history, open fallback form, copy identifiers
Editing behavior:
string: inline text editor or larger popover editor for long valuesboolean: select true/falseintegerandfloat: numeric editor with validation before savelistandmap: open a structured modal- unsupported
valueType: view-only with a link to the existing form route propertyTypeFileorCert: open the existing create/update form in a drawer or modal overlay
The page should keep the inherited/default value visible while editing an override. If the override is deleted, the row remains visible and falls back to the inherited value.
The staged-change panel should list every pending create, update, and reset before applying. This matters for coordinated changes such as enabling a flag and setting a related URL. The backend commands can still run one by one, but the user gets a review step and can see partial failures without losing the full set of intended changes.
The row action menu should include View History. It should link to the audit
log or history page pre-filtered by configId, propertyId, and the selected
scope target. The row already shows updateUser and updateTs; history gives
operators the deeper trail they need when debugging production configuration
changes.
Structured Value Modal
The modal should start with raw JSON and raw YAML tabs. If a schema is available for the property, add a Form tab.
The customer code loads schema assets with:
schemas/<propertyName>/<propertyName>.json
schemas/<propertyName>/config.js
portal-view does not currently have this property-schema convention, so the
first implementation should not depend on local schema assets. Use raw
JSON/YAML with syntax and JSON validation first. Typed form support should come
from the light-portal schema registry through schema-query, schema-command,
and schema_t.
If a row has a schemaId and schemaVersion, the dialog should lazily fetch
the published schema body from schema-query when the user opens the structured
editor. The main getConfigUpdateProperties response should include schema
metadata but not schemaBody, so the paginated table does not move large schema
documents unnecessarily.
The schema association should key by configId + propertyId. Human-friendly
keys such as configName + propertyName can be shown in the UI, but should not
be used as the durable validation key.
List/map values should be saved as compact JSON strings because the command
APIs store propertyValue as a string.
Schema Registry Validation
The schema registry should be used for structured map and list values once
the registry is hardened enough for production validation. The config update
page should treat the registry as optional per property: rows with no schema
still use valueType validation and raw JSON/YAML editing.
getConfigUpdateProperties should return lightweight schema metadata:
{
"schemaId": "security-jwt-claim-mapping",
"schemaVersion": "1.0.0",
"schemaType": "json",
"schemaStatus": "P",
"hasSchema": true
}
The UI should enable the Form tab only when the schema exists, is published, and
is compatible with the property value type. Schema documents should be cached by
hostId + schemaId + schemaVersion, with host-specific lookup falling back to a
global schema.
Validation must run in both places:
- frontend validation gives immediate editor feedback and highlights the JSON path that failed
- backend validation remains authoritative in the config command handlers before a create or update override is accepted
Backend validation should parse propertyValue according to valueType before
running JSON Schema validation. The UI should normalize YAML input to compact
JSON before sending the command payload, so the command APIs continue to receive
string values.
The schema registry needs a config-property binding before this can be enabled.
The preferred minimal binding is schemaId + schemaVersion on the base config
property definition. If tenant-specific schemas are needed later, schema lookup
can resolve the same schema id/version against the selected hostId first and
then fall back to the global row.
API Matrix
The write side can reuse the current command APIs.
| Scope | Create | Update | Delete |
|---|---|---|---|
| Environment | createConfigEnvironment | updateConfigEnvironment | deleteConfigEnvironment |
| Product | createConfigProduct | updateConfigProduct | deleteConfigProduct |
| Product Version | createConfigProductVersion | updateConfigProductVersion | deleteConfigProductVersion |
| Instance | createConfigInstance | updateConfigInstance | deleteConfigInstance |
| API | createConfigInstanceApi | updateConfigInstanceApi | deleteConfigInstanceApi |
| App | createConfigInstanceApp | updateConfigInstanceApp | deleteConfigInstanceApp |
| App API | createConfigInstanceAppApi | updateConfigInstanceAppApi | deleteConfigInstanceAppApi |
For existing override rows, the update/delete payload must include the current
aggregateVersion so the event persistence layer can enforce the monotonic
version check. For new override rows, the page sends the scope identity,
configId, propertyId, and propertyValue.
Security And RBAC
The page must not assume that a user who can view configuration can write every override scope. The selected scope and target should be checked against the same permission model used by the existing config admin routes and command handlers.
Recommended behavior:
- hide scopes the user cannot see
- show read-only rows for scopes the user can read but cannot update
- disable apply/reset controls when the selected target is not writable
- show a lock icon or tooltip for read-only rows
- keep backend command authorization authoritative, even when the UI already filtered the control
Unauthorized command responses should be mapped back to the row that triggered the command. The page should not fail the entire table because one row is not writable.
Read Model
The instance-facing scopes already have applicable-property queries:
getApplicableConfigPropertiesForInstancegetApplicableConfigPropertiesForInstanceApigetApplicableConfigPropertiesForInstanceAppgetApplicableConfigPropertiesForInstanceAppApi
These queries return property metadata and inherited/effective values, including:
configIdconfigNameconfigPhaseconfigTypepropertyIdpropertyNamepropertyTypepropertyValuepropertySourcepropertySourceTypevalueTyperesourceTyperequireddisplayOrder
The same page needs current override metadata from:
getConfigInstancegetConfigInstanceApigetConfigInstanceAppgetConfigInstanceAppApi
The page should not join applicable rows and override rows across separately paginated API calls. That produces brittle pagination, filtering, sorting, and row-count behavior. Instead, Phase 1 should add a merged backend read model that returns one row per configurable property with inherited value, override value, effective value, override metadata, and permission hints.
Environment, product, and product version currently have list/getFresh queries for existing overrides, but they do not have equivalent applicable-property queries:
getConfigEnvironmentgetConfigProductgetConfigProductVersion
The new merged query should cover these scopes before they are exposed in the new page. A temporary client merge is acceptable only for a local prototype with unpaginated data; it should not be shipped as the production page behavior.
Proposed Generic Query
Add a Phase 1 query such as getConfigUpdateProperties in config-query.
Request:
{
"hostId": "host uuid",
"scope": "instance",
"target": {
"instanceId": "instance uuid"
},
"filters": {
"configPhases": ["R"],
"propertyTypes": ["Config"],
"resourceTypes": ["all"]
},
"offset": 0,
"limit": 1000,
"active": true
}
Response:
{
"total": 1,
"properties": [
{
"scope": "instance",
"hostId": "host uuid",
"configId": "config uuid",
"configName": "security.yml",
"configPhase": "R",
"propertyId": "property uuid",
"propertyName": "jwt.clockSkew",
"propertyType": "Config",
"valueType": "integer",
"resourceType": "all",
"required": false,
"schemaId": "security-jwt-clock-skew",
"schemaVersion": "1.0.0",
"schemaType": "json",
"schemaStatus": "P",
"defaultValue": "60",
"defaultSourceType": "config_property",
"overrideValue": "120",
"overrideAggregateVersion": 3,
"effectiveValue": "120",
"effectiveSourceType": "config_instance",
"canUpdate": true,
"canDeleteOverride": true
}
]
}
This query should be read-only. It does not need new write commands.
The query owns inheritance and candidate selection. The frontend owns presentation, editing state, and calls to the existing command APIs.
Frontend Structure
Recommended files:
src/pages/config/update/ConfigUpdatePage.tsx
src/pages/config/update/ConfigUpdateTable.tsx
src/pages/config/update/ConfigValueEditor.tsx
src/pages/config/update/ConfigStructuredValueDialog.tsx
src/pages/config/update/configUpdateScopes.ts
src/pages/config/update/configUpdateApi.ts
src/pages/config/update/configValue.ts
src/pages/config/update/configUpdateDraft.ts
configUpdateScopes.ts should be the single source of truth for scope metadata:
type ConfigUpdateScope = {
id: 'environment' | 'product' | 'productVersion' | 'instance' | 'api' | 'app' | 'appApi';
label: string;
targetKeys: string[];
applicableQuery?: string;
overrideQuery: string;
overrideResponseKey: string;
createAction: string;
updateAction: string;
deleteAction: string;
getFreshAction?: string;
defaultResourceTypes?: string[];
defaultConfigPhases?: string[];
};
The page should avoid hard-coding create/update/delete branching inside cell handlers. The handler asks the selected scope metadata which action and keys to use.
Draft And Apply Flow
The default edit mode should stage changes locally. A dirty row is not saved until the user chooses Apply for that row or Review & Apply from the toolbar.
The draft model should track:
- operation: create, update, reset
- previous effective value
- next override value
- scope target keys
configIdpropertyId- current
aggregateVersion - validation state
The review dialog should group changes by operation and show enough context for operators to catch mistakes before applying. If multiple commands are applied and one fails, the dialog should show which rows succeeded and which rows need attention. The page should refetch or refresh successful rows and leave failed rows dirty with their error state intact.
Save Flow
- User edits a row.
- UI validates the value against
valueTypeand the schema registry when a published schema is attached to the property. - UI marks the row dirty and stores a draft operation.
- User applies a row or opens Review & Apply.
- UI builds payload from selected scope, row
configId, rowpropertyId, and normalizedpropertyValue. - If an active override row exists, call the update action and include
aggregateVersion. - If no active override row exists, call the create action.
- On success, update the row with returned aggregate version or refetch that row.
- On conflict or error, keep the draft value, restore the displayed committed value, and show the row error.
The local override map should store the full override row, not just the string value. At minimum it needs:
propertyValueaggregateVersionactive- scope identity fields
updateUserupdateTs
Before update or delete, the UI should support the same getFresh* pattern
used by the existing admin pages. If the row has been open for a while, the
Apply action can fetch the latest row to get the freshest aggregateVersion.
At minimum, a version conflict must offer a “Refresh Row & Try Again” action
that reloads that row, compares the current backend value with the user’s draft,
and lets the user reapply intentionally.
Validation errors should stay close to the edited cell. For example, an invalid integer should keep the cell in edit/error state with a short message. Backend validation, authorization, and conflict errors should be attached to the row that caused them, not only shown as a global toast.
Reset Flow
Reset means delete the override for the selected target and property.
- User selects an overridden row.
- UI calls the scope’s delete action with target keys,
propertyId, andaggregateVersion. - On success, clear
overrideValueandoverrideAggregateVersion. - The displayed effective value reverts to the inherited/default value.
Rows with no override should not allow reset.
Like update, reset should support getFresh* before delete or expose the same
“Refresh Row & Try Again” conflict path.
Routing
Add a route such as:
/app/config/update
The route should accept task context and target context through query params:
/app/config/update?scope=api&instanceApiId=...&task=mcp-onboard-api
Existing config table pages can link to it when they already have target context. Existing generated forms should remain available from row overflow actions for advanced edits and File/Cert values.
The View History row action should preserve context by opening the audit trail
in a drawer, modal, or task-aware route with filters already applied. The filter
payload should include the selected scope, target keys, configId, and
propertyId.
For fallback forms, prefer opening the existing react-schema-form experience
inside a drawer or modal over navigating away from the table. That keeps the
user’s current scope, filters, expansion state, selected row, and staged changes
intact. Full-page navigation can remain as a secondary fallback for complex
forms that cannot safely render in an overlay.
Implementation Plan
Phase 0: schema registry foundation for config validation
- Harden
schema-query,schema-command, andschema_tenough for production JSON Schema lookup. - Add a durable config-property-to-schema association with
schemaIdandschemaVersion. - Make schema lookup tenant-aware: host-specific schema first, global schema second.
- Validate schema bodies on schema create/update.
- Add backend config value validation for create/update override commands.
- Add tests for schema CRUD, tenant/global lookup, version pinning, and invalid config property values.
Phase 1: merged read model and instance-facing MVP
- Add
getConfigUpdatePropertiesor an equivalent merged query inconfig-query. - Return candidate properties, inherited values, current override values, override metadata, schema metadata, and permission hints in one paginated/sortable result.
- Build the page for Instance, API, App, and App API.
- Use existing command APIs for create/update/delete.
- Support scalar inline edits.
- Support list/map raw JSON/YAML modal.
- Support staged changes and Review & Apply.
- Support row-level validation/error/conflict states.
- Enable the typed Form tab only for properties with a published schema.
Phase 2: higher-level scopes
- Add Environment, Product, and Product Version selectors.
- Expose each scope only through the merged read model, not a client-side paginated join.
- Ensure product version respects product-version config/property mappings where available.
Phase 3: typed structured forms
- Use the schema registry for list/map config properties.
- Support custom validators by property key.
- Add tests for string array, object array, map, and malformed JSON/YAML values.
Phase 4: task integration
- Link from configuration task panels to
/app/config/update. - Add contextual next actions from instance, API, app, and app-api pages.
- Keep generated create/update forms as drawer/modal fallback actions.
Risks And Open Questions
- Environment inheritance needs a precise target rule. Existing applicable
instance queries include
environment_propertyas an inherited source, but the target environment is not selected by the current instance-facing query contract. - Product and product-version candidate lists can be too broad if they are loaded from all config properties. Product version should eventually use the product version config mappings.
- The customer Settings code stores custom values in a map keyed by
propertyId; forportal-view, the key should include scope target pluspropertyIdto avoid collisions when multiple targets are loaded. propertyIdis the stable merge key only after the candidate list has been constrained to the selected target. If multiple configs can contain the same property id in unusual imports, useconfigId + propertyId.- The page should avoid silently editing
FileorCertvalues as plain text. - Staged apply is not atomic until a bulk command exists. The UI must show partial success and partial failure clearly.
- Overlaying generated forms in a drawer depends on the form runner handling router state, success/failure navigation, and task context without forcing a full-page transition.
- The schema registry is not fully implemented and tested yet. Schema-backed validation should not be enabled until tenant-aware lookup, version pinning, and backend command validation are in place.
Recommendation
Build the page as a new task-oriented editor, not as a rewrite of the existing
config admin tables. Make the merged getConfigUpdateProperties read model a
Phase 1 backend requirement so the frontend does not perform brittle
pagination-sensitive joins. Start frontend exposure with the four
instance-facing scopes, then add environment, product, and product version once
the same merged query handles their inheritance and candidate-selection rules.
Implement the minimal schema registry foundation before enabling schema-backed
validation in the config update page. The raw JSON/YAML editor and scalar
valueType validation can be built in parallel, but the Form tab and backend
schema enforcement should wait for the registry work.
Rust Controller Logging
The controller service dashboard already has a logger page for Java runtimes.
That page is built around Logback concepts: named loggers, per-logger levels,
historical log content, and live streaming through controller-mediated MCP
tools. Rust products need a similar operator workflow, but the underlying
logging model is different. Rust services use tracing targets and one runtime
logging.filter expression instead of mutable Logback logger objects.
This document proposes a Rust-aware logger page for gateway, agent, API, deployer, and workflow runtimes:
gtw:light-gatewayagt:light-agentapi: Rust API services built onlight-axumorlight-runtimedpl:light-deployerwf:light-workflow
The goal is to keep the existing controller page entry point while switching the page behavior based on runtime capabilities.
Current State
portal-view has a unified controller logger page at
/app/controller/logger. The page receives a runtime instance from the control
pane dashboard and uses controller MCP tools:
get_loggersset_loggersget_log_contentstart_logsstop_logs
Those contracts work for Java services where the runtime can inspect and update Logback logger levels.
Rust services already expose live logging filter control through the
light-runtime MCP handler:
get_logging_filterset_logging_filterreload_moduleswithmodules: ["runtime/logging"]
The tested config server baseline is:
logging.filter: info,light_pingora::security=debug
This keeps the process at info by default and enables debug only for the
gateway security target.
Goals
- Provide one operator page for Rust log filter control, time-based history, and live streaming.
- Reuse the controller-mediated MCP path instead of adding direct browser access to runtime instances.
- Preserve the existing Java logger page behavior.
- Use Rust
tracingvocabulary in the UI: target, level, filter expression, and source. - Let operators build common filters without memorizing module paths.
- Keep an advanced filter input for exact
EnvFilterexpressions. - Support time-range log lookup from the running process.
- Support live log streaming through
notifications/log. - Make reset behavior explicit: live filter changes are temporary unless the instance configuration is updated separately.
Non-Goals
- Do not replace Java Logback logger management.
- Do not make the browser connect directly to pods, services, or container runtimes.
- Do not keep historical logs in portal-view or controller memory.
- Do not store full authorization headers, tokens, cookies, request bodies, or other secrets in log files, log responses, or live stream payloads.
Runtime Detection
The logger page should select the Rust experience when either condition is true:
- the selected runtime instance advertises product type
gtw,agt,api,dpl, orwf - the runtime MCP
tools/listor controller tool discovery includesget_logging_filter
If detection is uncertain, portal-view can attempt get_logging_filter and
fall back to the Java logger page if the response says logging control is not
available.
The page should show a capability banner when a selected runtime supports only some features:
| Capability | Required runtime support |
|---|---|
| Filter control | get_logging_filter, set_logging_filter, reload_modules |
| History | get_log_content backed by a JSON log file or platform log provider |
| Live stream | start_logs, stop_logs, notifications/log |
Page Layout
Use the current logger page route and high-level structure, but render Rust content when the selected instance is Rust.
Header:
- service label
- runtime instance ID
- service ID
- product type
- address and port
- connection status
- logging capability status
Tabs:
FilterHistoryLive Stream
The Java page can keep Config, History, and Live Stream; the Rust page
uses Filter instead of Config because the operator edits one tracing
filter expression, not a list of Logback logger objects.
Filter Tab
The filter tab controls the active runtime logging.filter.
Controls:
- current effective filter
- filter source, such as
values.yml:logging.filter,env:RUST_LOG, ormcp:set_logging_filter - default level selector
- target rows for common Rust modules
- advanced filter text area
Apply LiveReset From Config
Levels:
errorwarninfodebugtraceoff
Recommended default level is info.
Example generated filter:
info,light_pingora::security=debug
Apply flow:
operator changes target rows
-> portal-view builds EnvFilter expression
-> controller calls runtime set_logging_filter
-> runtime validates and applies the filter immediately
-> portal-view refreshes get_logging_filter
Reset flow:
operator clicks Reset From Config
-> controller calls reload_modules with runtime/logging
-> runtime reloads logging.filter from current resolved values
-> portal-view refreshes get_logging_filter
Baseline changes are handled outside this page. If an operator wants the filter to survive restart or reset, they should update the selected instance configuration, for example:
logging.filter: info,light_pingora::security=debug
Target Presets
The advanced filter must accept any valid Rust tracing target. The module
picker should be backed by reference data so new targets can be added without a
portal-view deployment.
Portal-view should load the dropdown from:
/r/data?name=logging_target
Recommended reference table mapping:
| Reference field | Logging target use |
|---|---|
ref_table_t.table_name | logging_target |
ref_value_t.value_code | exact Rust tracing target, such as light_pingora::security |
value_locale_t.value_desc | dropdown label and short operator-facing description |
ref_value_t.display_order | stable dropdown order |
ref_value_t.active | retire a target without deleting the row |
The simplest page can load all active targets from /r/data?name=logging_target
and group them client-side by product. If product-specific filtering is needed
later, add a reference relation such as logging-target-product that links each
target to common, gtw, agt, api, dpl, or wf. Operators can still
type a custom target if the target is not present in the reference table.
Suggested seed data:
Common targets:
| Target | Use |
|---|---|
light_runtime | bootstrap, config loading, reload, controller registration |
light_client | outbound HTTP and OAuth client support |
portal_registry | control-plane websocket registration |
reqwest | outbound HTTP client internals |
hyper_util | connection and pooling internals |
rustls | TLS handshakes and certificates |
tungstenite | websocket handshake and frames |
Gateway targets:
| Target | Use |
|---|---|
light_gateway | gateway application and proxy glue |
light_pingora | shared Pingora framework code |
light_pingora::security | JWT validation and JWK loading |
light_pingora::unified_security | unified auth routing |
light_pingora::mcp | MCP router and backend MCP calls |
light_pingora::handler | handler duration diagnostics |
light_pingora::pii_tokenization | tokenization runtime warnings |
pingora_core | Pingora server and protocol lifecycle |
pingora_proxy | Pingora proxy request handling |
Agent targets:
| Target | Use |
|---|---|
light_agent | agent HTTP server and session handling |
model_provider | model-provider calls and fallback routing |
mcp_client | outbound MCP client requests |
API targets:
| Target | Use |
|---|---|
light_axum | HTTP transport and axum integration |
light_runtime | shared runtime modules |
| service crate target | API-specific handlers, using the crate name with hyphens converted to underscores |
Deployer targets:
| Target | Use |
|---|---|
light_deployer | deployment workflow and git/Kubernetes operations |
light_runtime | shared runtime modules |
Workflow targets:
| Target | Use |
|---|---|
light_workflow | workflow engine, consumers, and task executor |
workflow_core | workflow model and shared core logic |
light_rule | rule execution |
model_provider | model-provider calls |
mcp_client | MCP tool calls |
The UI can also learn targets from returned history and live rows. Any target
seen in logs can become a temporary suggestion for that browser session, but
the authoritative dropdown source is the logging_target reference table.
History Tab
The history tab fetches logs from the running application for a time range.
Controls:
- presets: last 5, 10, 30, and 60 minutes
- required start time
- optional end time
- minimum level
- optional target filter
- text search
- result limit
Request:
{
"runtimeInstanceId": "019...",
"startTime": "2026-06-17T21:30:00Z",
"endTime": "2026-06-17T21:45:00Z",
"loggerLevel": "debug",
"loggerName": "light_pingora::security",
"limit": 1000
}
For compatibility, loggerName maps to the Rust target and loggerLevel maps
to the minimum tracing level. The controller can keep the existing
get_log_content tool name.
Recommended normalized row shape:
{
"timestamp": "2026-06-17T21:37:43.147463Z",
"level": "DEBUG",
"logger": "light_pingora::security",
"target": "light_pingora::security",
"message": "JWT validation failed after JWKS refresh: InvalidSignature",
"fields": {
"error": "InvalidSignature"
}
}
The response can preserve the current grouped shape for compatibility:
{
"content": {
"light_pingora::security": {
"logs": [
{
"timestamp": "2026-06-17T21:37:43.147463Z",
"level": "DEBUG",
"message": "JWT validation failed after JWKS refresh: InvalidSignature"
}
]
}
}
}
Portal-view should flatten the grouped response into rows, as the current Java page already does.
History source selection:
- If a JSON log file is configured, parse that file first. This should be the preferred source because the same file can be collected by Splunk or another logging system.
- If no log file is configured, use Kubernetes pod logs or container logs when the controller/runtime environment can access them.
- If neither source is available, return an explicit unsupported response.
The browser must not read Kubernetes or container logs directly. The controller or runtime-side tool should own that platform access and return the normalized row shape above.
When reading a JSON log file, the reader should filter by timestamp, level,
target, and text search. If the file format is line-oriented JSON, each line
should contain at least timestamp, level, target, and message.
Live Stream Tab
The live stream tab starts and stops log streaming for the selected runtime instance.
Controls:
- full filter expression
- start
- stop
- clear
- auto-scroll toggle
- bounded client buffer
- stream status
Request:
{
"runtimeInstanceId": "019...",
"filter": "info,light_pingora::security=debug"
}
start_logs should accept the full Rust filter expression because this is the
syntax Rust operators already use. For backward compatibility, the controller
can still accept level and loggerName, then translate them into a filter
expression.
The stream filter controls which events are sent to that stream subscription.
It must not change the process-wide logging.filter; process-wide changes
still go through set_logging_filter. Because tracing filters can suppress
events before stream filtering sees them, the UI should warn when the stream
filter is more verbose than the current active runtime filter.
Notification:
{
"method": "notifications/log",
"params": {
"runtimeInstanceId": "019...",
"timestamp": "2026-06-17T21:37:43.147463Z",
"level": "DEBUG",
"logger": "light_pingora::security",
"target": "light_pingora::security",
"message": "JWT validation failed after JWKS refresh: InvalidSignature"
}
}
The portal-view live buffer should remain bounded. The current 1000-row FIFO buffer is a good default.
Each browser/controller session must have its own stream subscription. Starting a stream from one operator must not replace another operator’s stream for the same runtime instance.
Runtime Implementation
Add shared Rust logging support to light-runtime, not separately in every
product.
Recommended components:
LoggingControl: existing activeEnvFiltercontrol.JsonLogWriter: optional line-oriented JSON file writer for services that need historical lookup or Splunk ingestion.LogFileReader: reads and filters configured JSON log files.PlatformLogProvider: controller-side or runtime-side abstraction for Kubernetes pod logs and container logs when no log file is configured.LogStreamHub: per-client subscriptions for live streaming.LogRecord: normalized timestamp, level, target, message, fields, and optional span/correlation fields.
Recommended runtime MCP tools:
| Tool | Purpose |
|---|---|
get_logging_filter | Return current Rust filter and source. |
set_logging_filter | Validate and apply a live filter expression. |
get_log_content | Return log rows from JSON file or platform log provider by time range, level, and target. |
start_logs | Start live log notifications for one controller client with a full filter expression. |
stop_logs | Stop live log notifications for one controller client. |
reload_modules | Reset runtime/logging from resolved config values. |
The JSON log file should be configurable:
logging.file.enabled: true
logging.file.path: /var/log/light-gateway/app.log
logging.file.format: json
logging.file.maxBytes: 104857600
logging.file.maxFiles: 10
logging.stream.maxSubscribers: 20
Defaults should be conservative. If no JSON log file and no platform log
provider are available, get_log_content should return a clear unsupported
response instead of an empty success that looks like there were no logs.
Controller Changes
The controller should expose Rust logging tools through the same callTool
path used by the existing logger page.
Add or pass through these tool names:
get_logging_filterset_logging_filterreload_modulesget_log_contentstart_logsstop_logs
For Rust runtimes, get_loggers and set_loggers are not the primary control
surface. The UI should use get_logging_filter and set_logging_filter
instead. The controller may keep get_loggers and set_loggers for Java
compatibility.
The controller should route notifications/log back to the portal-view
websocket with the originating runtimeInstanceId so the page can ignore logs
from other selected services.
For history, the controller should resolve sources in this order:
- configured JSON log file
- Kubernetes or container log provider
- unsupported response with a clear reason
Portal-View Implementation
Recommended structure:
- keep
/app/controller/loggeras the route - keep the existing
Loggercomponent as the shell - split Java and Rust behavior into child panels:
JavaLoggerPanelRustLoggerPanel
- reuse the current history and live table rendering where possible
- add a Rust filter builder for
logging.filter
Rust filter builder state:
type RustFilterDraft = {
defaultLevel: "error" | "warn" | "info" | "debug" | "trace" | "off";
targets: Array<{ target: string; level: string }>;
advanced: string;
mode: "builder" | "advanced";
};
In builder mode, portal-view generates the expression:
<defaultLevel>,<target>=<level>,<target>=<level>
In advanced mode, portal-view sends the text exactly as entered and lets the runtime validate it.
The page should show a warning when the current source is
mcp:set_logging_filter, because that indicates a live override that can be
lost on restart or reset by reloading runtime/logging.
Baseline Configuration
Live debug changes should call set_logging_filter; they should not update
config server by default.
To persist a baseline filter, the operator should use the instance configuration page and update:
logging.filter: info,light_pingora::security=debug
After saving the instance configuration, the config update flow can call:
{
"name": "reload_modules",
"arguments": {
"modules": ["runtime/logging"]
}
}
This makes the saved config the active baseline. Alternatively, the operator
can return to the logger page and use Reset From Config to reload only
runtime/logging.
The Rust logger page can link to the selected instance configuration, but it should not write baseline config itself.
Security And Safety
- Gate filter changes and log access behind the same controller permissions as the Java logger page.
- Treat logs as sensitive operational data.
- Do not render raw ANSI escape sequences as HTML.
- Truncate very large messages and expose an expand action.
- Mask obvious token and secret fields in JSON log output, history responses, and live stream payloads.
- Rate-limit live streams per runtime instance and per controller client.
- Show a warning before enabling broad
tracefilters.
Rollout Plan
- Add controller pass-through for
get_logging_filterandset_logging_filter. - Add
RustLoggerPanelin portal-view with filter control only. - Add JSON file logging and a
get_log_contentreader for Rust services. - Add Kubernetes/container log fallback when no log file is configured.
- Add Rust
start_logsandstop_logsbacked by per-client stream subscriptions. - Seed the
logging_targetreference data and load dropdown options from/r/data?name=logging_target. - Enable product-specific target presets for
gtw,agt,api,dpl, andwf.
Resolved Decisions
- Historical logs are not kept in memory. Use a configured JSON log file first; if there is no file, fall back to Kubernetes or container logs when they are available.
start_logsaccepts a fullfilterexpression. Compatibility fields such aslevelandloggerNamecan be translated by the controller.- The module dropdown is backed by the
logging_targetreference table exposed through/r/data?name=logging_target. - The logger page does not save a baseline. Baseline changes belong in instance configuration.
Human Task UI
ask is the workflow task type that pauses execution for human input. The
runtime can now create task_asst_t and worklist_t rows when an ask task
waits, so portal-view needs a generic human-task interface that lets an
assigned user open the task, provide the requested answer, and resume the
workflow.
This document proposes the portal UI and service contracts for that interface.
Current State
The workflow engine persists waiting ask tasks in task_info_t. The ask
configuration is stored in task_info_t.task_output.ask, and the workflow
runtime context remains on process_info_t.context_data.
The assignment layer is separate:
worklist_trepresents a user/category worklist.task_asst_trepresents a concrete task assignment.- Role assignment is resolved by the workflow runtime into one task assignment per active user in the role.
The Worklist page can show assigned tasks, but it does not yet provide a generic input screen for the user to approve or enter data.
Goals
- Provide one generic page for all human-input workflow tasks.
- Render the input controls from the ask task definition, not from a workflow-specific page.
- Let users open tasks from the Worklist page.
- Keep assignment, claim, completion, and authorization checks on the service side.
- Support role-assigned tasks where multiple users may receive the same work.
- Resume the workflow through the existing
completeTaskcommand. - Keep the UI useful for approval tasks first while leaving room for richer object-input tasks.
Non-Goals
- Do not create a custom approval page for each workflow.
- Do not make every workflow task human-actionable; only
asktasks use this interface. - Do not expose raw database rows directly to the page.
- Do not overload the engine
lockedfield for human claims; that field is already used by the workflow executor as a worker lease. - Do not replace the existing Worklist administration page in the first phase.
User Flow
The primary flow is:
Worklist
-> open assigned task
-> Human Task detail
-> render prompt and input controls from ask metadata
-> submit answer
-> completeTask command
-> workflow executor resumes the process
For a simple approval workflow, the user sees the prompt and two action buttons derived from the ask options. For structured input, the same page renders a schema-driven form.
The runtime flow for a role-assigned ask task is:
- The workflow executor creates one
task_asst_trow per assignee and keeps the parenttask_info_trow waiting for input. - The assigned user opens the row from Worklist.
getHumanTaskloads the assignment, task state, workflow metadata, and process context into one stable page payload.- The user submits an answer through
completeTask. completeTaskvalidates assignment ownership, locks the parent task row, records the result, and deactivates or cancels sibling assignments in the same transaction.- The workflow executor observes the completed ask task and resumes the process with the submitted answer.
Route Design
Add a human task detail route:
/app/workflow/HumanTask
The route should accept taskAsstId and task context through query parameters
or router state:
/app/workflow/HumanTask?taskAsstId=...&taskId=...
The Worklist page should route to this detail page for actionable task rows. Worklist administration actions such as create, update, and delete worklists should remain separate from human task completion.
If a dedicated inbox page is needed later, add:
/app/workflow/HumanTasks
That page can list only actionable assigned tasks, while the existing Worklist page can remain the administrative view of worklist definitions.
Data Model Decisions
task_info_t remains the canonical workflow engine task state. Its locked
column must stay reserved for executor leasing. Human task claims must not set
task_info_t.locked = 'Y', because that would make the executor treat the row
as worker-owned runtime work.
Useful existing task_info_t fields for the human task page are:
status_code: parent task state. Waiting ask tasks should be open for input; completed ask tasks should be read-only.deadline_ts: optional due or expiry timestamp to show in the UI.locking_userandlocking_role: possible global claim metadata if claim is implemented, but not a replacement for assignment-level authorization.task_output: source of the ask metadata.result_code: submitted answer envelope after completion.
task_asst_t remains the assignment layer. The current active flag and
unassigned_reason can hide completed assignments from Worklist, but they are
too loose to represent claim, release, expiry, and reporting states cleanly.
Add an explicit assignment status early in development so the query and command
contracts are built on the final assignment state model:
ALTER TABLE task_asst_t
ADD COLUMN status_code VARCHAR(16) NOT NULL DEFAULT 'ASSIGNED',
ADD COLUMN claimed_by VARCHAR(126),
ADD COLUMN claimed_ts TIMESTAMP WITH TIME ZONE,
ADD COLUMN claim_expires_ts TIMESTAMP WITH TIME ZONE;
Recommended assignment statuses:
| Status | Meaning |
|---|---|
ASSIGNED | Visible and actionable for the assignee. |
CLAIMED | Claimed by one assignee and locked from sibling submissions. |
COMPLETED | Completed by this assignee. |
RELEASED | Previously claimed and returned to the pool. |
CANCELLED | No longer actionable because the parent task ended elsewhere. |
EXPIRED | No longer actionable because the task or claim timed out. |
Keep active as a fast visibility/backward-compatibility flag. Use
status_code for business state and audit/reporting semantics.
Query Contract
The UI should not assemble a human task by calling several generic table
queries. Add a normalized query action such as getHumanTask.
Request:
{
"hostId": "...",
"taskAsstId": "..."
}
Response:
{
"hostId": "...",
"taskAsstId": "...",
"taskId": "...",
"processId": "...",
"wfInstanceId": "...",
"wfTaskId": "requestApproval",
"assignedTs": "...",
"assigneeId": "...",
"assignmentStatusCode": "ASSIGNED",
"claimedBy": null,
"claimedTs": null,
"deadlineTs": "2026-05-23T14:30:00Z",
"categoryCode": "approval",
"reasonCode": "human-approval",
"taskStatusCode": "W",
"workflow": {
"wfDefId": "...",
"namespace": "light-portal",
"name": "human-approval",
"version": "1.0.0"
},
"ask": {
"prompt": "Review the workflow request and choose a decision.",
"mode": "approval",
"options": [
{
"label": "Approve",
"value": "APPROVED",
"description": "Continue the request."
},
{
"label": "Reject",
"value": "REJECTED",
"description": "Stop the request."
}
],
"required": true,
"allowComment": true,
"contextKeys": ["requestId", "summary"]
},
"contextSummary": {
"requestId": "REQ-001",
"summary": "..."
},
"context": {
"requestId": "REQ-001",
"summary": "..."
}
}
The service should read from task_asst_t, task_info_t, process_info_t,
and wf_definition_t, then return a stable task-detail view. The UI should
treat this response as the source of truth.
The query should return a curated contextSummary when the ask metadata
defines contextKeys. It may also include the raw context object for
administrator troubleshooting or for workflows that have not yet declared a
curated context shape. The default user view should prefer contextSummary.
For a list page, add getHumanTaskList later. It should return only active
assignments for the current user unless the caller has an administrative
permission.
Input Rendering
The page renders controls from ask.mode, ask.options, and ask.schema.
| Ask mode | Control |
|---|---|
approval | Primary action buttons from options, with an optional comment field. |
confirm | Yes/No control. |
choice | Radio group or select from options. |
multiChoice | Checkbox group from options. |
text | Text area. |
object | Schema-driven form from ask.schema. |
file | Future upload control. |
If ask.mode is missing, default to text. If approval has no options, the
UI may render default APPROVED and REJECTED actions.
Comments should be configurable per ask task. The recommended metadata is:
{
"allowComment": true,
"commentRequired": false
}
approval and confirm should default to allowing comments. Other modes can
opt in when the workflow author wants users to explain the submitted value.
Answer Shape
Use a consistent answer envelope for completeTask.
{
"value": "APPROVED",
"comment": "Looks good.",
"submittedAt": "2026-05-22T14:30:00Z"
}
For object input, value is the submitted object:
{
"value": {
"approvedLimit": 5000,
"expirationDate": "2026-06-30"
},
"comment": "Approved with a reduced limit.",
"submittedAt": "2026-05-22T14:30:00Z"
}
The workflow receives this object as the ask task output. A workflow that needs
only the selected value can export .output.value; a workflow that wants the
full audit envelope can export .output.
Completion Command
The detail page submits through completeTask:
{
"host": "lightapi.net",
"service": "workflow",
"action": "completeTask",
"version": "0.1.0",
"data": {
"hostId": "...",
"taskId": "...",
"taskAsstId": "...",
"statusCode": "C",
"completedTs": "2026-05-22T14:30:00Z",
"response": {
"value": "APPROVED",
"comment": "Looks good.",
"submittedAt": "2026-05-22T14:30:00Z"
}
}
}
The command should verify that:
- the assignment exists and is active
- the assignment status allows submission
- the current user is the assignee or has an administrative permission
- the task is an ask task
- the task is still waiting for input
- the submitted answer matches
ask.mode,ask.options, andask.schema
The browser may send taskAsstId, taskId, and the answer, but it must not be
trusted to identify the completing user. The command service should derive the
user id and roles from the authenticated token. A client-supplied
completedUser value should be ignored for normal human-task completion.
Completion must be atomic. In one database transaction:
- Load the
task_asst_trow and verify it belongs to the current user, unless the caller has an explicit administrative override permission. - Lock the parent
task_info_trow, for example withSELECT ... FOR UPDATE. - Reject the command if the parent task is already completed or no longer waiting for input.
- Validate the answer against the ask metadata and, for object mode, the JSON schema.
- Update
task_info_twith statusC,completed_ts,completed_user, and the answer envelope inresult_code. - Mark the selected assignment
COMPLETEDand inactive. - Mark sibling active assignments for the same
task_idasCANCELLED, inactive, andunassigned_reason = 'completed_by_other_user'.
If another user completes the same parent task first, return a stale-task
conflict response, preferably HTTP 409, and leave the duplicate submission
unapplied.
Claim And Concurrency
Role assignment can create several active assignments for the same task_id.
The first user-input page should use optimistic completion with a server-side
final check: only the first valid completion succeeds, and later submissions
receive a stale-task conflict response. This proves the core flow before adding
the operational complexity of explicit claim/release commands.
For a better user experience, add an optional claimHumanTask command.
Recommended claim behavior:
- claim records the current user on the human-task assignment path with
task_asst_t.status_code = 'CLAIMED',claimed_by, andclaimed_ts - claim does not set
task_info_t.locked = 'Y' - claim expires after a short timeout or can be released
- completion still performs the final status check
The engine locked column should remain reserved for executor leasing. Human
claims should use either assignment-specific fields added later or
locking_user/locking_role without changing the executor lease flag.
When claim is enabled for role-assigned tasks, sibling assignment rows should be visible as claimed or unavailable instead of letting users submit stale answers. Live refresh should use the existing portal notification channel if one is available. If workflow tasks need their own lightweight channel later, prefer server-sent events before adding a separate websocket service.
Assignment Cleanup
When a human task is completed:
- the selected assignment should no longer appear as actionable
- sibling active assignments for the same
task_idshould also disappear - the task completion result should remain on
task_info_t
With the current table shape, the minimal implementation can deactivate active
task_asst_t rows for the task and set unassigned_reason to completed or
completed_by_other_user. A later schema iteration can add explicit
assignment status fields if the UI needs richer assignment history.
With the recommended status column, cleanup should use structured states:
- selected assignment:
status_code = 'COMPLETED',active = false,unassigned_reason = 'completed' - sibling assignments:
status_code = 'CANCELLED',active = false,unassigned_reason = 'completed_by_other_user'
Authorization
Normal users should only query and complete assignments where
task_asst_t.assignee_id matches their user id. Administrative users may view
all assignments for the host if the workflow task endpoints allow it.
The browser should send taskAsstId, but the service should not trust the
browser to identify the assignee. It should resolve the current user from the
authenticated token and compare it to the assignment row.
Administrative completion on behalf of another user should require a distinct permission, not just the ability to query workflow tasks. The command should record both the authenticated actor and the effective completed user if override support is added.
Recommended authorization model:
- normal completion requires the endpoint write scope and
task_asst_t.assignee_id = authenticated user id - administrative override requires
workflow.task.override - a host or portal administrator, such as the configured
portal.admin, may be treated as satisfying the override permission if that is the established portal authorization convention
Use a broad scope such as workflow.write for access to the write endpoint if
the service defines workflow-specific scopes. If the current service only has a
portal-level write scope, keep the OAuth scope broad and enforce
workflow.task.override as the fine-grained application permission.
Page Layout
The detail page should be compact and task-oriented:
- header with workflow name, task name, status, and due date if
deadlineTsis present - assignment summary with assignee and category
- prompt panel
- context panel with selected workflow/process fields
- input area rendered from ask metadata
- sticky submit actions for long forms
- error or stale-task state
The context panel should show enough data for the user to decide, but it should
not dump the full context_data object by default. The first phase can show
common fields and provide a collapsible raw context view for administrators.
Timeout handling should be visible as read-only metadata as soon as
task_info_t.deadline_ts is available. The UI can show due date or expiry
status without implying that automatic runtime timeout processing has already
been implemented.
Error States
The page should handle these states explicitly:
- assignment not found
- assignment no longer active
- task already completed
- task is not an ask task
- ask metadata missing or invalid
- validation failed
- submit conflict because another user completed the task first
- workflow resume failed after completion
The submit conflict case should take the user back to the worklist after showing that the task is no longer available.
Implementation Phases
Phase 1:
- Add the
task_asst_t.status_codemigration before building the query and command handlers. - Add
getHumanTask. - Add
/app/workflow/HumanTask. - Link actionable Worklist task rows to the detail page.
- Render
approval,choice,multiChoice,confirm, andtext. - Submit through
completeTask. - Validate assignment ownership and ask metadata in the command layer.
- Complete the parent task and assignment cleanup in one transaction.
- Return stale-task conflicts for duplicate submissions.
- Hide completed and sibling-cancelled assignments from the worklist.
Phase 2:
- Add schema-driven
objectinput. - Add JSON schema validation on the command side.
- Add curated context metadata such as
ask.contextKeys.
Phase 3:
- Add optional
claimHumanTaskandreleaseHumanTask. - Add claim expiry handling.
- Add a dedicated human task inbox.
- Add assignment history and richer audit display.
- Add live Worklist refresh for claim/completion events through the existing portal notification channel, with server-sent events as the fallback.
- Add file input if workflow use cases require it.
Resolved Questions
task_asst_tshould gain explicit assignment status fields.activeremains useful for filtering but should not be the only state model.- The human task query should return curated context when workflow metadata defines it, with raw context available for administrative troubleshooting.
- Comments should be configurable. Approval and confirm modes should default to allowing comments.
- Timeout metadata should be visible as read-only UI state before automatic timeout processing is implemented.
- Administrative override should use the fine-grained permission
workflow.task.override, withportal.adminas the broad administrator path if the portal authorization layer already uses it. - Claim/release should remain Phase 3. Phase 1 should rely on optimistic completion and atomic duplicate-submit rejection.
- Live Worklist refresh should use the existing portal notification channel first. If there is no reusable channel, use server-sent events before adding a dedicated websocket service.
User Filter
As more portal users manage their own APIs, clients, instances, schedules, and
configuration records, giving every operator a broad admin role becomes too
coarse. A broad admin can see and modify records created by other admins on the
same host. This document proposes an incremental owner-scoped filtering model
for portal-view.
The first step is a UI-side filter based on the user recorded on each row, such
as update_user. This is not a complete security boundary. The same rule must
eventually be enforced in the query and command services with fine-grained
authorization from the rule engine. The UI implementation is still useful
because it improves day-to-day user experience and gives us a concrete policy
shape to move into the service layer.
Problem
Portal admin pages were originally designed for a small set of trusted operators. Many tables expose all host-scoped records once the user can access the admin page.
That model creates problems as adoption grows:
- application owners need to manage their own APIs, clients, and instances
- broad admin roles expose unrelated records from other teams
- users can accidentally edit or delete records owned by another user or team
- creating one role per page, such as
api-adminorinstance-admin, still does not solve row ownership - service-layer fine-grained authorization is not available everywhere yet
The immediate need is to let users use admin-like pages while limiting the rows they see and act on.
Current Experiment
Schedule.tsx is the first experimental page. The idea is:
- users can access the schedule admin surface
- normal users only see schedules where
updateUsermatches their user id - global admins or schedule admins can still see all schedules
- the
updateUsercolumn can be hidden for normal users - create/update/delete actions are available only on the visible set
One implementation detail matters: ownership filters must be added before the
request payload serializes the filters array.
const apiFilters = [];
if (ownedOnly && userId) {
apiFilters.push({ id: "updateUser", value: userId });
}
const cmdData = {
filters: JSON.stringify(apiFilters),
};
Adding the filter after cmdData.filters is built will not send it to the
backend.
Design Goals
- Allow regular users to manage records they created or updated.
- Avoid giving every self-service user broad all-record admin visibility.
- Keep the admin table implementation familiar and incremental.
- Centralize the owner filter logic instead of duplicating it page by page.
- Make the UI rule match the future service-layer rule as closely as possible.
- Preserve host scoping and existing role-based page visibility.
- Avoid presenting UI-side filtering as a security boundary.
Non-Goals
- Do not claim UI filtering is sufficient authorization.
- Do not replace service-layer rule-engine enforcement.
- Do not solve full team ownership in the first UI-only pass.
- Do not migrate every admin page in one large change.
- Do not overload
update_useras the permanent ownership model if a better owner field exists or can be added.
Ownership Model
There are several possible ownership signals. They should be treated in this order of preference.
| Field | Meaning | Recommendation |
|---|---|---|
owner_user_id | explicit individual owner | best long-term user ownership field |
owner_position_id | explicit position or org-unit owner | best long-term team/hierarchy ownership field |
create_user | original creator | good fallback if available |
update_user | last updater | useful interim fallback, but not true ownership |
domain-specific owner, such as operation_owner | business owner | useful when the field is reliable and normalized |
update_user is acceptable for the first UI experiment because many tables
already have it. However, it has an important semantic problem: ownership moves
to whoever last updated the row. If Alice creates an API and Bob updates it,
Bob becomes the owner under an update_user rule.
The long-term model should add explicit owner fields where needed:
owner_user_id
owner_position_id
owner_group_id is intentionally deferred. Groups are still useful for flat
team membership, but position ownership fits the portal authorization model
better when access should follow the organization hierarchy. owner_org_id is
also deferred because normal portal records are already scoped by host_id, and
host_t links back to org_t through the host domain. Add organization-level
ownership only if a future cross-host/global ownership use case requires it.
Do not add created_by and updated_by as authorization fields in Phase 4.
The existing update_user and update_ts columns remain the last-updater audit
trail. If creator audit becomes important, add create_user and create_ts as
audit fields later, not as substitutes for stable ownership.
Until explicit owner columns exist, each page should declare which field is used for interim UI owner filtering.
Role Model
Use one page per entity type, but separate page visibility from row scope.
| Role | Meaning | Page access | Row scope |
|---|---|---|---|
user | baseline signed-in portal user | only approved self-service admin pages | owned records only |
admin | global portal administrator, effectively super admin | all admin pages | all records |
<entity>-admin | administrator for one entity type, such as schedule-admin | that entity’s admin page | all records for that entity |
platform-admin | deployment platform administrator if this role is kept | platform/deployment platform pages only | not a global all-record role |
Do not give every user account access to every admin page. Only pages that are
safe for self-service ownership should be exposed to user, and each of those
pages must apply the owner filter and action guards.
The admin role can be repurposed as the global all-record role once the
sidebar stops using it as a broad menu marker. Role checks must use exact role
tokens. A role such as schedule-admin must not match admin through substring
checks.
Access Modes
The UI should support three access modes.
Owner-Scoped Admin
This is the default self-service mode. The user can open admin pages, but rows are filtered to records they own.
Example:
roles: user
scope: owned
filter: updateUser = current user id
All-Scope Admin
This is for operators who can see and manage every record on the current host.
Example roles:
admin
schedule-admin
The default all-scope role is admin. Page-specific roles such as
schedule-admin can opt a user into all-record visibility for one area. Do not
use platform-admin as a global all-scope role because the portal already has a
Platform Admin page for deployment platform management.
Read-Only or Support View
Some users may need to see records without modifying them. This can be added later with separate flags:
canReadAll = true
canWriteOwned = true
canWriteAll = false
Proposed UI Architecture
Add a small ownership-scope helper used by admin pages.
Example shape:
type OwnershipScopeOptions = {
roles?: string | null;
userId?: string | null;
ownerField: string;
allScopeRoles?: string[];
};
type OwnershipScope = {
ownedOnly: boolean;
ownerFilter: { id: string; value: string } | null;
canWriteAll: boolean;
};
Example usage:
import {
applyOwnershipFilter,
defaultAllScopeRoles,
ownershipScope,
} from "../utils/ownershipScope";
const ownership = ownershipScope({
roles,
userId,
ownerField: "updateUser",
allScopeRoles: [...defaultAllScopeRoles, "schedule-admin"],
});
const apiFilters = applyOwnershipFilter(columnFiltersWithoutActive, ownership);
This helper should live near other portal navigation/task utilities or in a small access utility module, for example:
src/utils/ownershipScope.ts
or:
src/tasks/accessScope.ts
The helper should not call the backend. It only computes the UI filter and UI capabilities from the current user state.
Sidebar Behavior
The sidebar should not use admin as a marker on every admin menu link. That
made the whole Administration group disappear for normal users and prevented
owner-scoped self-service pages from being reachable.
Recommended behavior:
adminusers see every Administration link.- non-admin users see only Administration links explicitly marked with
useror a matching entity role, such asrole: "user schedule-admin". - only add
userto a link after that page has owner-scoped filtering and action guards. - remove
role: "admin"from individual menu links. - use exact role-token matching instead of string
includes, soschedule-admindoes not accidentally grantadmin.
At the Phase 3 rollout point, the following Administration links are safe to
expose to user because the pages apply the shared owner-scope helper and
action guards:
- API Admin
- API Detail
- OAuth Auth Client and Client Token
- App Admin
- Instance Admin, Runtime Instance, and instance relationship pages
- Schedule Admin
- Workflow Definition
Configuration, platform admin, user/role admin, workflow process/task/audit pages, and lower-volume metadata pages should remain admin-only until they have the same owner-scope treatment or a separate support/read-only policy.
Admin Page Behavior
For an owner-scoped user:
- add the owner filter before the query payload is serialized
- hide the owner column if it does not add useful information
- show a small scope label such as “My records”
- keep create actions available
- allow update/delete only for rows matching the ownership rule
- preserve normal table sorting, pagination, and global filter behavior
For an all-scope admin:
- do not add the owner filter
- show a scope label such as “All host records”
- show the owner/update columns
- allow existing admin actions
For a user without enough context:
- if
userIdis missing, do not run an owner-scoped query - show a clear message that user context is required
- avoid falling back to all-record visibility
Action-Level Guard
List filtering is not enough for a good UI. Row actions should also check the same scope.
Example:
const canUpdateRow =
ownership.canWriteAll ||
row.original.updateUser === userId;
For rows the user cannot modify:
- hide destructive actions, or
- disable them with a tooltip explaining the scope
Even after service-layer authorization is implemented, the UI should keep these guards so users understand why an action is unavailable.
Phase 4 Ownership Columns
For high-value entity tables, add canonical owner columns directly on the entity row:
owner_user_id UUID NULL
owner_position_id VARCHAR(128) NULL
Recommended constraints where the table has host_id:
FOREIGN KEY (host_id, owner_user_id)
REFERENCES user_host_t(host_id, user_id)
FOREIGN KEY (host_id, owner_position_id)
REFERENCES position_t(host_id, position_id)
Both owner columns should be nullable during migration. New records should get
owner_user_id from the authenticated user on the service side by default. Do
not trust a browser-submitted owner user id unless the caller has permission to
assign ownership.
owner_position_id should be optional on create. The UI can show a host
position dropdown populated from the user’s allowed positions. If the user has
exactly one effective position and the page is configured for position
ownership, the UI can default to that position. If the user has multiple
positions, require an explicit choice when position ownership is desired.
For portal forms, the optional position owner field should be exposed as
ownerPositionId and backed by the existing position label dynaselect query.
The form action uses the position/getPositionLabel endpoint, which is backed
by the queryPositionLabel persistence method and returns the id/label pairs
needed by the select control.
Do not expose ownerUserId as a normal create/update form field. The command
path must derive owner_user_id from the authenticated user in the event
context. If an owner-transfer use case is needed later, implement it as a
separate command with explicit authorization and audit behavior.
Normal update forms may update owner_position_id when the page allows the
caller to choose or clear the owning position. update_user changes on every
update and remains audit metadata. owner_user_id should not change on normal
update; it changes only through an explicit owner-transfer action restricted to
the current owner, admin, or the relevant entity-admin role.
Existing rows should be migrated conservatively:
- if
update_usercan be resolved to a user in the host, it can be used as an initialowner_user_id - leave
owner_position_idnull unless there is a reliable source for the owning position - rows with no owner columns populated should be treated as unassigned legacy rows, visible only to all-scope admins until an owner is assigned
Service-Layer Target
The UI filter is an interim step. The durable solution belongs in the query and command services.
The service layer should eventually:
- derive user id, roles, host id, and scopes from JWT claims
- ignore client-supplied owner filters as an authorization source
- inject owner predicates into query handlers based on the authenticated user
- reject update/delete commands when the user does not own the row and lacks all-scope permission
- use rule-engine policies for exceptions and domain-specific ownership
Once service-side owner enforcement is implemented, the UI should no longer be the source of authorization predicates. The service should inject the ownership predicate from authenticated user context and rule-engine decisions.
The UI should still keep owner-aware behavior for usability:
- show “My records” or “Admin View” scope labels
- hide or show owner columns based on the user’s scope
- disable update/delete actions that the current user cannot take
- optionally send a simple view hint such as
scope=ownedorscope=all
The service must treat any UI-supplied scope or owner filter as a hint only. It must ignore, override, or reject filters that would expand the caller’s authorized scope.
For owner-scoped users, the service-side predicate should be an OR condition:
owner_user_id = current_user_id
OR owner_position_id IN current_user_effective_positions
For all-scope admins, such as admin or the relevant entity-admin role, the
service should omit this owner predicate and return all rows within the normal
host scope.
The UI and backend should share the same policy concepts:
host scope
entity type
owner field
owned-only permission
all-record permission
read vs write capability
Position hierarchy must be resolved by the service layer or rule engine. A JWT
claim such as pos=ai-engineer only grants exact-position access unless the
service expands it to effective positions from position_t and
user_position_t. If hierarchy is enabled, the effective position set should
include inherited positions according to the existing position inheritance
rules.
Rows with owner_position_id IS NULL are not position-owned. A user can still
see the row if owner_user_id matches their user id. Rows where both
owner_user_id and owner_position_id are null are unassigned legacy rows and
should not be visible to normal owner-scoped users by default.
Rule Engine Direction
The rule engine can express policies such as:
user can read API when api.owner_user_id == user.user_id
user can update API when api.owner_user_id == user.user_id
admin can read all APIs on host
admin can update all APIs on host
api-admin can read all APIs on host
api-admin can update all APIs on host
support can read all APIs but cannot update
For tables that do not yet have explicit ownership fields, the policy can
temporarily map ownership to update_user.
Rollout Plan
Phase 1: Fix Schedule Experiment
- Fix filter ordering so
updateUseris included in the request. - Use roles plus user id to decide owner-scoped vs all-scope mode.
- Add action-level guards for update/delete.
- Keep the current route behavior unchanged.
Phase 2: Add Reusable UI Helper
- Create a shared ownership-scope helper.
- Add unit-level coverage if the repo has a practical test pattern.
- Document default all-scope roles.
- Keep owner field configurable per page.
Phase 3: Apply To High-Value Admin Pages
Start with pages where users commonly manage their own records:
- API admin
- API detail/version admin
- OAuth clients
- client apps
- instances
- instance API links
- schedules
- workflow definitions
Then expand to lower-volume metadata pages.
Current implementation status:
src/utils/ownershipScope.tscentralizes exact role matching, owner-scope calculation, owner filter injection, and owner-column hiding.- Sidebar access now exposes only scoped links to
useror matching entity-admin roles, while exactadmincontinues to see all Administration links. - API pages use
adminandapi-adminfor all-record scope, withuserlimited byupdateUser. - OAuth client pages use
adminandoauth-client-adminfor all-record scope, withuserlimited byupdateUser. - Client app pages use
adminandapp-adminfor all-record scope, withuserlimited byupdateUser. - Instance pages use
adminandinstance-adminfor all-record scope, withuserlimited byupdateUser. - Schedule pages use
adminandschedule-adminfor all-record scope, withuserlimited byupdateUser. - Workflow Definition uses
adminandworkflow-adminfor all-record scope, withuserlimited byupdateUser. - Task/page search registries use exact role-token checks so
schedule-adminor another entity-admin role does not accidentally match globaladmin, while exactadminstill has global visibility.
Deferred from this phase:
- Workflow Process, Task, Worklist, Work, Audit, and Trace remain admin-only until their ownership rules are defined and implemented.
- Configuration and platform pages remain admin-only because their ownership model is not yet defined.
- User and role administration remain admin-only because exposing them to self-service users would require a separate delegated-administration model.
Phase 4: Add Explicit Ownership Fields
Where update_user is too weak, add proper owner fields through the database
and services.
Candidate fields:
owner_user_id
owner_position_id
Apply these first to the high-value tables that already have owner-scoped admin
pages. Keep the fields nullable during migration, default owner_user_id from
the authenticated user on create, and make owner transfer explicit.
Current implementation status:
portal-dbadds nullableowner_user_idandowner_position_idcolumns to the high-value portal tables used by the owner-scoped admin pages.- The migration backfills
owner_user_idfromupdate_useronly whenupdate_useris already a UUID. Non-UUID audit values remain unassigned instead of blocking the migration. - A database insert trigger defaults
owner_user_idfromupdate_userfor new rows when the command path writes the authenticated user id intoupdate_user. - Query projections for the scoped UI pages now return
ownerUserIdandownerPositionId, and UUID filtering recognizesownerUserId. portal-viewnow usesownerUserIdfor ownership checks on action controls. The UI no longer sends an owner filter for service-enforced pages because service-side scope must include both direct user ownership and position ownership.- Owner-aware create/update forms expose optional
ownerPositionIdwith a host-scoped position dynaselect backed byqueryPositionLabel. - Command schemas allow optional
ownerPositionIdfor the owner-aware create and update commands. They do not acceptownerUserId;owner_user_idcomes from the authenticated event user. light-portalpersistence writesowner_user_idfrom the event user on create and writesowner_position_idfromownerPositionIdon create/update.- Schedule query is the first service-enforced owner-scope path. Non all-scope
users are filtered by
owner_user_id = current_user_id OR owner_position_id IN effective positionsbased on authenticated audit context.
Remaining rollout work:
- Add explicit owner-transfer commands instead of changing ownership through normal update forms.
Phase 5: Enforce In Services
- Add query-side owner predicates.
- Add command-side ownership checks.
- Move policy decisions into rule-engine configuration.
- Keep the UI filters as usability hints, not authorization.
Current implementation status:
- Query-side owner predicates are implemented for Schedule, API, API Version, App, OAuth Client, Client Token, Instance, Instance API, Instance API Path Prefix, Instance App, Instance App API, Runtime Instance, and Workflow Definition.
- Query handlers derive scope from the authenticated audit attachment. Users
with the global
adminrole or the entity-specific all-scope role bypass the owner predicate; other users are scoped by user id or effective positions. - The UI keeps owner-aware action guards, but it does not send the owner filter
as a request filter for service-enforced pages. That keeps position-owned rows
visible when the service grants access by
owner_position_id. - The db-provider keeps backward-compatible query methods and adds owner-aware overloads so query services can roll forward independently.
Remaining service rollout work:
- Add command-side ownership checks before update/delete actions.
- Add explicit owner-transfer commands and audit events.
- Move the all-scope role and position hierarchy decisions from Java guards into rule-engine policy once the service-side rule context is ready.
Future Improvement: Entity Access Grants
Do not introduce a generic ownership table in Phase 4. It adds query joins, pagination complexity, and weaker referential integrity before we have a clear sharing use case.
A generic table can be added later for secondary grants, sharing, and delegated administration. It should supplement the canonical owner columns rather than replace them.
Possible future shape:
entity_access_t
host_id
entity_type
entity_id
principal_type -- user, position, group, role
principal_id
access_level -- owner, maintainer, viewer
Use this only when we need use cases such as:
- share one API with another position or group
- give support read-only access to a selected set of records
- delegate maintenance without transferring the canonical owner
- manage record-specific exceptions from an Access Admin page
Risks And Mitigations
| Risk | Mitigation |
|---|---|
| UI filter is bypassed | Treat it as interim only; enforce in services next |
update_user changes ownership unexpectedly | Prefer explicit owner fields; use update_user only as fallback |
| users lose access to records updated by operators | support owner transfer or explicit owner fields |
| inconsistent page behavior | centralize scope helper and rollout page by page |
| broad admins still need all records | define all-scope roles separately from self-service admin |
| query filters can be removed by browser tools | backend must inject authorization predicates from JWT claims |
Recommendation
Use owner-scoped filtering as the first UI step, but centralize it immediately.
Do not copy the Schedule.tsx logic into every page by hand.
The recommended path is:
- fix the schedule filter ordering
- introduce a reusable ownership-scope helper
- apply it to the most common self-service admin pages
- add explicit owner fields where
update_useris not good enough - enforce the same rules in query and command services through the rule engine
This gives users a safer admin experience now while creating a clear migration path to real fine-grained authorization.
Contextual Help Links
portal-view has many pages, generated forms, task flows, and admin tables.
Even with the task-oriented navigation work, users still need page-specific and
form-specific help when they are making a decision or filling a field. This
document proposes a contextual help-link model for pages and forms.
Problem
Users often need help at the exact point where they are working:
- what this page is for
- when to use this form
- what required fields mean
- which optional fields matter
- what permissions or ownership rules apply
- what happens after submit
- how this page fits into a larger task
Today, help is usually outside the UI context. Users must know where to look, which document applies, and which page or form name maps to the screen in front of them.
Design Goals
- Add a clear help entry point to every major page and generated form.
- Keep help content close to the product documentation source of truth.
- Avoid bloating the
portal-viewapplication bundle with documentation. - Allow documentation-only updates without rebuilding
portal-view. - Make help links declarative so page, form, and task metadata can drive them.
- Keep link identifiers stable even if routes or component names change.
- Support future documentation search, related topics, and task-specific help.
- Preserve the ability to run the app locally with a configurable docs base URL.
Non-Goals
- Do not build a full documentation authoring system inside
portal-view. - Do not duplicate long user guides in component source files.
- Do not block a page or form rollout because full documentation is missing.
- Do not use contextual help as a replacement for better labels, validation, or field-level error messages.
Documentation Location Decision
The help content should live in light-portal-doc. portal-view should store
only metadata that points to the relevant help page.
Recommended split:
light-portal-doc
src/help/portal-view/
pages/
forms/
tasks/
concepts/
portal-view
page registry, task registry, and form metadata with help ids or help paths
Why light-portal-doc
Pros:
- Keeps user-facing documentation in the documentation repo.
- Allows documentation changes without rebuilding or redeploying
portal-view. - Avoids increasing the app bundle with markdown content.
- Supports documentation search, navigation, publishing, and review workflows.
- Allows the same help content to be linked from support tickets, onboarding, release notes, and external docs.
- Fits the existing pattern where portal-view design docs already live in
light-portal-doc.
Cons:
- Requires stable published URLs.
- Requires a configurable docs base URL for local and deployed environments.
- Can drift from UI behavior unless we add link validation and ownership rules.
Why Not portal-view/docs
Pros:
- Easy to review UI and docs in one PR.
- Help content can be tightly coupled to the component version.
- Local development does not need a separate docs deployment.
Cons:
- Documentation-only changes require app rebuilds and deployments.
- Large markdown content can bloat the frontend repo and build context.
- It is harder to provide a proper documentation navigation/search experience.
- It encourages implementation notes and user help to mix in the same repo.
Recommendation: use light-portal-doc for content and keep portal-view
limited to stable link metadata.
Help Content Structure
Create a user-facing help tree separate from design docs:
src/help/portal-view/
pages/
api-admin.md
api-detail.md
instance-admin.md
schedule-admin.md
forms/
create-api.md
update-api.md
create-client.md
update-instance.md
tasks/
mcp-onboard-api.md
register-standalone-mcp-server.md
concepts/
ownership-and-positions.md
hosts-and-user-hosts.md
api-versioning.md
Use page-level help for screen orientation and form-level help for submission semantics. Use concept help for reusable explanations that should not be copied into many page/form documents.
URL Strategy
Help URLs should be stable and human-readable.
Recommended public URL shape:
/help/portal-view/pages/api-admin
/help/portal-view/forms/create-api
/help/portal-view/tasks/mcp-onboard-api
/help/portal-view/concepts/ownership-and-positions
Do not make the public URL depend on React route internals or component names.
If a route changes from /app/api to another route later, the help URL should
not need to change.
portal-view should build the absolute link from a runtime config value:
PORTAL_DOC_BASE_URL=https://doc.lightapi.net
or for Vite:
VITE_PORTAL_DOC_BASE_URL=https://doc.lightapi.net
Local development can point to a local docs server:
VITE_PORTAL_DOC_BASE_URL=http://localhost:3000
Metadata Contract
Use a stable help id or help path in the app metadata. A help path is more direct and easier to validate.
Page registry example:
{
id: "api-admin",
title: "API Admin",
route: "/app/apis",
helpPath: "/help/portal-view/pages/api-admin",
}
Task registry example:
{
id: "mcp-onboard-api",
title: "Onboard API to MCP Gateway",
helpPath: "/help/portal-view/tasks/mcp-onboard-api",
}
Form metadata example:
{
"formId": "createApi",
"helpPath": "/help/portal-view/forms/create-api",
"actions": []
}
If we need indirection later, we can change to helpId and resolve it through a
small registry:
{
helpId: "forms.create-api"
}
Start with helpPath because it is simple, transparent, and works well with
static documentation.
Portal UI Behavior
Each page and generated form should have a small help action in a predictable location.
Recommended behavior:
- open help in a new browser tab
- use an external-link icon or help icon with an accessible label
- keep the help action near the page title or form title
- if a form is opened inside a task shell, prefer form-specific help first and show task help as a secondary link
- if no specific help exists yet, fall back to the nearest page or concept help
Example resolution order for a form opened from a task:
- form
helpPath - current task
helpPath - current page
helpPath - generic portal help landing page
Do not render a broken link. If a help path is missing, hide the action or show the fallback help link.
Generated Forms
Generated forms should support a top-level helpPath field in Forms.json.
The renderer can read it and show a help action in the form header.
For example:
{
"formId": "createSchedule",
"helpPath": "/help/portal-view/forms/create-schedule",
"schema": {},
"form": []
}
Field-level help can be added later, but it should not be the first step. Many field descriptions can stay in the JSON schema title/description. Use field-level help only for fields where a short description is not enough, such as security, ownership, deployment, or advanced configuration fields.
Possible future field shape:
{
"key": "ownerPositionId",
"helpPath": "/help/portal-view/concepts/ownership-and-positions"
}
Task-Aware Help
The task-oriented navigation layer should support task help separately from page or form help. A user working on the same form may need different context depending on the task.
Example:
createApiopened from “Register a new API” links to create API form help.createApiopened from “Onboard API to MCP Gateway” can also link to MCP onboarding task help.
The UI should pass task context through existing task URL parameters and layout state, then render both links when useful:
Help: Create API
Related: Onboard API to MCP Gateway
Authoring Guidelines
Each page help document should include:
- what the page is used for
- who can access it
- what records are visible
- common actions
- links to related forms and tasks
Each form help document should include:
- when to use the form
- what happens after submit
- required fields
- important optional fields
- ownership and permission behavior
- validation or troubleshooting notes
Keep help content user-facing. Do not put implementation details, class names, or database internals in the main help body unless they are truly needed for an operator.
Validation
To prevent link drift, add a lightweight validation step once the first help docs exist.
Validation should check:
- every
helpPathinportal-viewpoints to a markdown source inlight-portal-doc - every high-value page has page help
- every high-value form has form help
- no help path uses a route-specific or component-specific unstable name
This can start as a script in light-portal-doc or a shared CI check that
accepts both repo paths.
Rollout Plan
Phase 1: Documentation Structure
- Create
src/help/portal-view/pages. - Create
src/help/portal-view/forms. - Create
src/help/portal-view/tasks. - Create
src/help/portal-view/concepts. - Add placeholder help pages for the high-value admin pages and forms.
Phase 2: App Metadata
- Add optional
helpPathtopageRegistry.ts. - Add optional
helpPathtotaskRegistry.ts. - Add optional top-level
helpPathto generated form metadata. - Add a docs base URL runtime config.
Phase 3: UI Components
- Add a reusable help-link component.
- Render page help near page titles.
- Render form help in the generated form header.
- Render task help in the task navigation shell.
- Add fallback behavior when a specific help link is missing.
Phase 4: Coverage And Validation
- Add help paths for all self-service owner-scoped admin pages.
- Add help paths for all high-value create/update forms.
- Add a validation script for help path coverage and broken links.
- Add missing docs over time as pages move into the task-oriented model.
Initial Scope
Start with the pages and forms most likely to be used by self-service users:
- API Admin and API Detail
- create/update API
- create/update API Version
- App Admin
- create/update App
- OAuth Client and Client Token
- create/update Client
- create Client Token
- Instance Admin and relationship pages
- create/update Instance
- create Instance API
- create/update Instance API Path Prefix
- create Instance App
- create Instance App API
- Schedule Admin
- create/update Schedule
- Workflow Definition
- create/update Workflow Definition
Then expand to admin-only pages after their ownership and access model is clear.
MVP Decisions
Use these decisions for the first implementation.
Missing Help Links
Do not hide the help action when a specific page, form, or task help path is missing. Fall back to the generic portal-view help landing page:
/help/portal-view/index
This keeps the UI consistent. A missing specific help page should degrade to general help instead of making the help affordance disappear.
Help Presentation
Open help in a new browser tab for the MVP. Do not build an embedded markdown viewer, side drawer, or iframe-based documentation panel in the first version.
This keeps portal-view small and avoids adding documentation rendering,
iframe, routing, and panel-state complexity to the app. A side panel can be
revisited later if users need in-page help while editing long forms.
JSON Schema Descriptions
Do not auto-generate full form help pages from JSON schema descriptions. Schema titles and descriptions are best used for inline labels, helper text, or field-level tooltips.
Form-level help should explain why the form exists, when to use it, what happens after submit, and how the form fits into a larger workflow. It should not simply repeat field types and required flags.
Documentation Versioning
Use latest documentation URLs for the MVP. Do not introduce release-versioned help URLs in the first implementation.
The portal will likely support both cloud SaaS deployments and enterprise on-premise deployments. SaaS users normally interact with the latest deployed portal, but enterprise customers may run older portal versions for a longer period. Versioned docs are therefore a good future requirement, but they should not block the first help-link rollout.
Keep helpPath values relative and version-neutral:
/help/portal-view/forms/create-api
Then versioning can be introduced later by changing only the configured docs base URL:
PORTAL_DOC_BASE_URL=https://doc.lightapi.net/v2.0
This keeps the app metadata stable while allowing SaaS to use latest docs and on-premise builds to point at version-specific documentation.
Future Enhancements
In-Page Help Drawer
Add an optional in-page help drawer after the helpPath metadata is stable and
the first new-tab implementation has proven useful.
The drawer should be opt-in, not the default for every form. Long or complex configuration forms can declare:
{
"helpPath": "/help/portal-view/forms/update-instance",
"inPageHelp": true
}
When enabled, the UI can render a right-side drawer that displays the help document through an iframe or a lightweight markdown renderer. This avoids constant tab switching for complex forms while keeping the MVP simple.
Field-Level Help Paths
Add field-level help paths sparingly for complex fields and architectural concepts. Standard fields should continue to use JSON schema titles, descriptions, helper text, or tooltips.
Example future field metadata:
{
"key": "ownerPositionId",
"helpPath": "/help/portal-view/concepts/ownership-and-positions"
}
The UI can render a small help icon next to the field label when a field-level
helpPath exists. Good candidates include ownership, security, OAuth token
exchange, deployment target, transport configuration, and workflow definition
fields.
Versioned Documentation
Add release-versioned documentation when multiple portal versions must be supported at the same time, especially for on-premise enterprise deployments.
The relative helpPath values should remain unchanged. The deployment or build
configuration should select the versioned docs base URL:
SaaS/latest:
PORTAL_DOC_BASE_URL=https://doc.lightapi.net
On-premise v2.0:
PORTAL_DOC_BASE_URL=https://doc.lightapi.net/v2.0
This gives cloud deployments a simple latest-docs experience and gives
enterprise deployments a path to version-matched help without changing
portal-view metadata.
Recommendation
Store user-facing help content in light-portal-doc and add declarative
helpPath metadata in portal-view. This keeps documentation maintainable and
publishable while allowing every page, form, and task to provide context-aware
help from the UI.
Event Processing Notifications
Portal commands are event driven. After a command is submitted, one or more
CloudEvents are written to event_store_t and outbox_message_t. The
hybrid-query event consumer later processes the outbox rows and updates the
projection tables used by portal-view.
The notification page in the user profile is intended to show the user the
recent processing result for those events. Today the table and read path exist,
but notification_t is not populated consistently, so the page cannot provide
meaningful status.
Current State
The command path already writes events through the common command handler:
- The command handler validates and enriches the request.
- It builds one or more CloudEvents.
- It inserts those events into
event_store_tandoutbox_message_t. - The command returns before the query-side projection has necessarily run.
The query side can run through either event-processing pipeline, selected by configuration:
- Pg-notify pipeline:
DbEventConsumerStartupHookpollsoutbox_message_t, uses the table’s gaplessc_offset, groups rows bytransaction_id, and writes failed transactions to the databasedead_letter_queue. - Kafka pipeline: a connector publishes rows from
outbox_message_tto Kafka.PortalEventConsumerStartupHookconsumes those records, groups records by the command-sidetransaction_id, and produces failed transactions to the Kafka DLQ topic when DLQ is enabled.
Both pipelines eventually call PortalDbProvider.handleEvent(conn, event).
handleEvent dispatches the event to the projection method for that event type.
Because both pipelines process the same outbox-backed events, they should share
the same user-facing notification status model.
The notification pieces are partially present:
notification_texists inportal-db.NotificationDataPersistenceImplcan querynotification_t.NotificationServiceImplcan insert a notification row.user-queryexposesgetNotification.portal-viewhas a notification table page.
The current gap is that notification rows are not created at the central event processing boundary.
There is also a separate UI error in MailMenu: it calls getPrivateMessage,
whose handler currently returns an empty response. That explains the browser
error Unexpected end of JSON input, but it is separate from the notification
status design.
Goals
- Show the current user the latest event processing results in the profile notification page.
- Record both successful and failed projection processing.
- Preserve event processing correctness even if notification insertion fails.
- Keep notification creation centralized instead of adding calls to every projection method.
- Support commands that emit multiple events.
- Make the read API filter by host and user by default.
- Keep enough diagnostic data to debug failed projections.
- Keep notification writes idempotent so event replay is safe.
Non-Goals
- Do not replace
event_store_t,outbox_message_t, ordead_letter_queue. - Do not use notifications as the source of truth for projection state.
- Do not build a real-time push channel in the first phase.
- Do not add notification logic manually to every projection method.
- Do not expose other users’ processing history to non-admin users.
Recommended Design
Use notification_t as an operational projection-status table. The command
side creates PENDING rows at the central event publication boundary, and the
hybrid-query event consumer updates those rows with the processing result.
The primary processing-result write point should be the centralized outbox
consumer path, around the call to PortalDbProvider.handleEvent(conn, event).
Recommended lifecycle:
command handler
-> event_store_t
-> outbox_message_t
-> notification_t PENDING row
-> response to caller
hybrid-query consumer
-> read outbox_message_t
-> handleEvent(conn, event)
-> projection table write
-> notification_t status row
For command-side publication, insert or update one notification row for each
CloudEvent with status PENDING in the same transaction that writes
event_store_t and outbox_message_t. Leave event_partition and
event_offset null for this first insert, because the consumer has not observed
the event position yet.
For successful projection processing, update the notification row for the
CloudEvent to status SUCCEEDED and populate event_partition and
event_offset from the active processor’s outbox position.
For failed projection processing, insert or update one notification row for each
failed CloudEvent with status FAILED or DLQ, and store the exception
message. Populate event_partition and event_offset when the processor has
that information.
Status Model
Use one explicit status field. Do not keep is_processed; this feature is
being implemented for the first time, and a boolean cannot distinguish pending,
success, retry, DLQ, and skipped outcomes.
Recommended statuses:
| Status | Meaning |
|---|---|
PENDING | Event accepted into event_store_t and outbox_message_t, but the active event consumer has not recorded a processing result yet. |
SUCCEEDED | Event was applied to projection tables and the projection transaction committed. |
FAILED | Event processing failed before the failed transaction was durably written to the configured DLQ, or the DLQ write itself failed. |
DLQ | Event transaction failed in fallback mode and was durably written to the configured DLQ. |
SKIPPED | Event was read by the active event consumer but intentionally ignored, such as an unhandled event type. |
The UI should show the status labels, not the underlying event pipeline. The same status meanings apply to both pg-notify and Kafka processing.
Schema
The existing table is close, but it is too small for operational status and has
nonce as INTEGER while event tables use BIGINT.
Recommended table shape:
CREATE TABLE notification_t (
id UUID NOT NULL,
host_id UUID NOT NULL,
user_id UUID NOT NULL,
nonce BIGINT NOT NULL,
event_class VARCHAR(255) NOT NULL,
event_json TEXT NOT NULL,
event_ts TIMESTAMP WITH TIME ZONE NULL,
process_ts TIMESTAMP WITH TIME ZONE NOT NULL,
status VARCHAR(16) NOT NULL,
error VARCHAR(2048) NULL,
aggregate_id VARCHAR(255) NULL,
aggregate_type VARCHAR(255) NULL,
aggregate_version BIGINT NULL,
event_partition INTEGER NULL,
event_offset BIGINT NULL,
transaction_id UUID NULL,
read_ts TIMESTAMP WITH TIME ZONE NULL,
PRIMARY KEY (host_id, id),
FOREIGN KEY (host_id) REFERENCES host_t(host_id) ON DELETE CASCADE
);
user_id is intentionally not a foreign key to user_t. PENDING rows are
inserted on the command side before projection tables are updated, so enforcing
that projection FK would break commands such as user creation before the
projection catches up.
Recommended indexes:
CREATE INDEX idx_notification_user_process_ts
ON notification_t (host_id, user_id, process_ts DESC);
CREATE INDEX idx_notification_status_process_ts
ON notification_t (host_id, status, process_ts DESC);
CREATE INDEX idx_notification_transaction
ON notification_t (host_id, transaction_id);
CREATE INDEX idx_notification_event_position
ON notification_t (host_id, event_partition, event_offset);
CREATE INDEX idx_notification_unread_failure
ON notification_t (host_id, user_id, process_ts DESC)
WHERE read_ts IS NULL AND status IN ('FAILED', 'DLQ');
event_partition and event_offset are intentionally generic processing
position fields. They are useful for operator diagnostics, but the UI should not
label them as pg-notify or Kafka details. In the pg-notify processor,
event_partition is the configured logical consumer partition and
event_offset is outbox_message_t.c_offset. In the Kafka processor,
event_partition and event_offset are the consumed Kafka record partition and
offset.
Both columns are nullable. PENDING rows should leave them empty at initial
insert time. They are filled later by the pg-notify or Kafka processor when the
processing result changes the row to SUCCEEDED, FAILED, DLQ, or SKIPPED.
transaction_id remains a UUID because it is generated by the command side and
used by both event processors.
Do not store pipeline name, source topic/channel name, or DLQ destination in
notification_t. Those are implementation details of the configured event
pipeline. Operators can use service configuration and logs when they need
pipeline-specific diagnostics.
For existing installations, ship this as a patch:
ALTER TABLE notification_t ALTER COLUMN nonce TYPE BIGINT;
ALTER TABLE notification_t ADD COLUMN IF NOT EXISTS status VARCHAR(16);
ALTER TABLE notification_t ADD COLUMN IF NOT EXISTS event_ts TIMESTAMP WITH TIME ZONE;
ALTER TABLE notification_t ADD COLUMN IF NOT EXISTS aggregate_id VARCHAR(255);
ALTER TABLE notification_t ADD COLUMN IF NOT EXISTS aggregate_type VARCHAR(255);
ALTER TABLE notification_t ADD COLUMN IF NOT EXISTS aggregate_version BIGINT;
ALTER TABLE notification_t ADD COLUMN IF NOT EXISTS event_partition INTEGER;
ALTER TABLE notification_t ADD COLUMN IF NOT EXISTS event_offset BIGINT;
ALTER TABLE notification_t ADD COLUMN IF NOT EXISTS transaction_id UUID;
ALTER TABLE notification_t ADD COLUMN IF NOT EXISTS read_ts TIMESTAMP WITH TIME ZONE;
ALTER TABLE notification_t DROP CONSTRAINT IF EXISTS notification_t_user_id_fkey;
ALTER TABLE notification_t DROP COLUMN IF EXISTS is_processed;
ALTER TABLE notification_t ALTER COLUMN status SET NOT NULL;
CREATE INDEX IF NOT EXISTS idx_notification_unread_failure
ON notification_t (host_id, user_id, process_ts DESC)
WHERE read_ts IS NULL AND status IN ('FAILED', 'DLQ');
Write Path
Notification writes need an explicit transaction policy. A single rule cannot cover every status:
- Failure and DLQ notifications must be durable even when projection writes are rolled back.
- Success notifications must not claim success until the projection write has committed.
- Notification write failures should not break projection processing.
Use a REQUIRES_NEW style helper for notification writes that must survive a
projection rollback. In plain JDBC, this means opening a separate connection
with its own commit/rollback boundary.
For success rows, there are two safe options:
- Commit the projection transaction first, then write
SUCCEEDEDin a separate notification transaction. - Write
SUCCEEDEDinside the projection transaction, but wrap it in a savepoint and treat notification insert failure as non-fatal.
The first option is the recommended default because notification failures cannot
roll back projection updates. The tradeoff is a small window where projection
has committed but the success notification is missing. That is acceptable
because event_store_t remains the source of truth and success notifications
are user feedback, not projection correctness.
Recommended service methods:
void recordPending(Map<String, Object> event, UUID transactionId);
void recordSuccess(Map<String, Object> event, EventMetadata metadata);
void recordFailure(Map<String, Object> event, EventMetadata metadata, String error, String status);
recordPending should participate in the command-side transaction that writes
event_store_t and outbox_message_t. It may store transaction_id, because
that value is generated by the command side, but it must leave
event_partition and event_offset null. recordSuccess and recordFailure
should use the event-processing transaction policy described below.
EventMetadata should carry only pipeline-neutral data that is not inside the
CloudEvent map:
eventPartition: the active processor’s partition value. For pg-notify this is the configured logical consumer partition; for Kafka this is the consumed Kafka record partition.eventOffset: the active processor’s offset value. For pg-notify this isoutbox_message_t.c_offset; for Kafka this is the consumed Kafka record offset.transactionId: the command-side transaction UUID used by both processors.
Both consumers should build this metadata before calling handleEvent, so the
failure path still has offset and transaction context after the projection
transaction is rolled back.
Use an idempotent upsert:
INSERT INTO notification_t (...)
VALUES (...)
ON CONFLICT (host_id, id) DO UPDATE SET
process_ts = EXCLUDED.process_ts,
status = EXCLUDED.status,
error = EXCLUDED.error,
event_partition = EXCLUDED.event_partition,
event_offset = EXCLUDED.event_offset,
transaction_id = EXCLUDED.transaction_id;
This makes replay and fallback processing safe.
Success Handling
In the normal batch path:
begin projection transaction
for each event from the active pipeline:
parse CloudEvent
handleEvent(conn, event)
commit projection transaction
for each successfully committed event:
recordSuccess(event, metadata) in separate notification transaction
Do not write SUCCEEDED before the projection transaction commits unless it is
part of the same transaction. If it is written in the same transaction, a
projection rollback must roll back the success row too.
The implementation can keep an in-memory list of successfully applied events while processing the batch. After commit, loop through that list and upsert the success notifications. If a success notification write fails, log it and continue; do not retry the projection.
Failure Handling
Failure rows must be written outside the failed projection transaction.
In fallback mode, processing is retried per transaction. For a failed transaction:
begin projection transaction
savepoint projection_attempt
process transaction events
on exception:
rollback to projection_attempt or rollback projection transaction
write failed events to database DLQ or Kafka DLQ topic
recordFailure(event, metadata, error, "DLQ") in separate notification transaction
For pg-notify, the DLQ destination is the database dead_letter_queue table.
For Kafka, the DLQ destination is the configured Kafka DLQ topic. The failure
notification can be committed with the database DLQ transaction for pg-notify,
or in a separate notification transaction immediately after the Kafka DLQ
produce request is accepted. The key requirement is that it must not be part of
the projection work that is being rolled back.
If the database connection enters an unrecoverable error state, close it and open a fresh connection for the DLQ and failure notification writes.
If the payload cannot be parsed as a CloudEvent, the consumer may not know the CloudEvent id or event type. In that case, the DLQ remains the primary failure record. If the consumer metadata still has host, user, partition, offset, and transaction id, the consumer can create a diagnostic notification with a generated id, but this should be treated as a best-effort operational row.
Pending Handling
PENDING is part of phase one. Add pending rows at the central command-side
publication boundary that writes event_store_t and outbox_message_t.
The pending notification should be written in the same command-side transaction as the event-store and outbox rows. If the command rolls back, the pending notification must roll back too. Do not add pending writes to individual command handlers.
At this stage, the notification row should contain command-known fields only:
CloudEvent id, host id, user id, nonce, event class, event JSON, event timestamp,
and transaction id. The processor-owned event_partition and event_offset
fields remain null until event processing updates the row.
Read API
Keep getNotification as the main query endpoint, but tighten its contract.
Recommended request fields:
{
"hostId": "uuid",
"userId": "uuid",
"offset": 0,
"limit": 25,
"status": "SUCCEEDED",
"eventClass": "ClientCreatedEvent",
"nonce": "123",
"fromTs": "2026-05-08T00:00:00Z",
"toTs": "2026-05-08T23:59:59Z",
"error": "duplicate key"
}
Recommended response:
{
"total": 1,
"notifications": [
{
"id": "uuid",
"hostId": "uuid",
"userId": "uuid",
"nonce": 123,
"eventClass": "ClientCreatedEvent",
"status": "SUCCEEDED",
"processTs": "2026-05-08T16:12:00Z",
"aggregateId": "host|client",
"aggregateType": "Client",
"aggregateVersion": 2,
"transactionId": "uuid",
"eventPartition": 0,
"eventOffset": 1001,
"error": null,
"eventJson": "{...}"
}
]
}
eventPartition and eventOffset are intentionally displayed as generic
position fields regardless of which event pipeline is configured. The main list
can hide them by default and show them in the detail view.
userId is a filter on getNotification, not a separate endpoint contract. The
profile notification page should always send the logged-in user’s userId. The
admin notification page can omit userId to request host-wide results, or pass a
specific userId to narrow the host-wide view to one user.
Authorization rules:
- Normal users can query only their own token
user_idwithin the selectedhostId. If the request omitsuserId, the backend should apply the tokenuser_id; if the request supplies anotheruserId, the backend should reject it or override it with the tokenuser_id. - Admin users can query all users for the host by omitting
userId, or filter to a specific user by providinguserId. - The backend should enforce this using token claims, not only UI filters.
Portal View
The profile notification page should become a processing-status view.
Recommended columns:
- Time
- Status
- Event
- Aggregate
- Nonce
- Error
- Details
Recommended default filters:
hostIdfrom the selected host.userIdfrom the logged-in user.- No default
statusfilter. - Most recent first.
- Last 25 rows.
The UI should display concise summaries and keep full eventJson behind an
expandable detail row or dialog.
Show all events associated with the user, including successful, failed, and derived events. Derived events should be visible as their own rows instead of being collapsed under the original command transaction.
The current processFlag filter should be replaced by status. No
is_processed compatibility mapping is needed because this feature has not yet
started populating notification_t.
The header MailMenu should not call getPrivateMessage unless that handler is
restored. For notification status, add a small notification badge endpoint or
reuse getNotification with limit = 5.
The header badge should count only unread failure notifications, such as
FAILED and DLQ, and display the count in red when the count is greater than
zero.
In the list, FAILED and DLQ status badges should also use red styling.
Phase 2 adds two narrow user-query RPCs:
getUnreadNotificationCount: returns unreadFAILEDandDLQnotifications for the currenthostIdanduserId.markFailureNotificationsRead: setsread_tson unreadFAILEDandDLQnotifications for the currenthostIdanduserId.
The header uses the count endpoint for its badge and marks failures read when the user opens the notification menu. The notification page also marks failures read when it is opened.
Admin Notification Page
Phase 3 should add a separate admin notification page instead of overloading the profile notification page. The recommended location is:
- Route:
/app/event/notifications - Menu:
Administration->Event Admin->Notifications
This page should reuse the same notification table and getNotification read
API, but with admin defaults:
hostIdfrom the selected host.- No default
userIdfilter, so admins see host-wide results. - Default status filter for
FAILEDandDLQ, with an option to show all statuses. - Filters for
userId,eventClass,status,transactionId,aggregateId, processing position, time range, and error text. - No unread badge behavior and no call to
markFailureNotificationsRead.
The page should clearly identify itself as an admin view, such as “Admin View: Host Notifications”. Host-wide access must still be enforced by the backend using token roles.
Operational Cleanup
Notifications are operational history. They should not grow forever.
Recommended retention:
- Keep successful notifications for 30 to 90 days.
- Keep failed and DLQ notifications longer, such as 180 days.
- Allow host-level configuration later if needed.
Cleanup should be implemented as a generic operational cleanup process, not as
notification-specific UI or command-handler logic. The first cleanup target is
notification_t, but the same framework should also support other operational
tables such as message_t for private messages.
Recommended implementation:
- Add an
OperationalCleanupStartupHookon the query side. - Run cleanup on a fixed interval, such as daily, with config-driven enablement, interval, batch size, and per-target retention days.
- Use a single cleanup coordinator that owns multiple cleanup targets. Each target defines its table, timestamp column, status/type conditions if needed, retention duration, and batch delete SQL.
- Use a database lock, such as a PostgreSQL advisory lock or a dedicated cleanup lock row, so only one service instance performs cleanup at a time.
- Delete in bounded batches to avoid long table locks and large transactions.
- Use a separate database connection and transaction for cleanup work.
- Log cleanup failures and continue service startup; cleanup failure must not block query APIs or event processing.
Do not use schedule_t directly for this cleanup. That scheduler is business
workflow infrastructure that emits events into event_store_t and
outbox_message_t. Operational cleanup is local maintenance and should stay out
of the event-processing path.
Example notification cleanup:
WITH doomed AS (
SELECT host_id, id
FROM notification_t
WHERE (status IN ('SUCCEEDED', 'SKIPPED') AND process_ts < ?)
OR (status IN ('FAILED', 'DLQ') AND process_ts < ?)
ORDER BY process_ts
LIMIT ?
)
DELETE FROM notification_t n
USING doomed d
WHERE n.host_id = d.host_id
AND n.id = d.id;
Private-message cleanup can be another target using message_t.send_time:
WITH doomed AS (
SELECT host_id, from_id, nonce
FROM message_t
WHERE send_time < ?
ORDER BY send_time
LIMIT ?
)
DELETE FROM message_t m
USING doomed d
WHERE m.host_id = d.host_id
AND m.from_id = d.from_id
AND m.nonce = d.nonce;
Recommended default cleanup targets:
| Target | Table | Retention |
|---|---|---|
| Successful notification history | notification_t where status IN ('SUCCEEDED', 'SKIPPED') | 90 days |
| Failed notification history | notification_t where status IN ('FAILED', 'DLQ') | 180 days |
| Private messages | message_t | 180 days |
Do not delete recent PENDING notifications. Old PENDING rows should be
treated as an operational signal first because they may indicate that the event
consumer is stopped or lagging. If a hard cap is needed later, make it a
separate, longer retention policy.
Snapshot and Promotion
notification_t should be treated as an operational table, not a promoted
projection table.
It should be excluded from global snapshot export and conversion alongside
event_store_t, outbox_message_t, dead_letter_queue, log_counter, and
consumer_offsets.
Rollout Plan
Phase 1: Make Notifications Useful
- Add
statusand diagnostic columns tonotification_t. - Add pipeline-neutral
event_partition,event_offset, andtransaction_idmetadata. - Change
NotificationServiceto support separate notification transactions. - Insert
PENDINGrows at the central command-side outbox publication boundary. - Insert
SUCCEEDEDrows after successfulhandleEvent. - Insert
DLQrows in fallback failure handling. - Update
getNotificationto supportstatusand correct timestamp fields. - Update
portal-viewto usestatus, default to the current user, and show all user-associated events including derived events.
Phase 2: Improve User Feedback
- Add an unread marker with
read_ts. - Add a small header badge query for unread
FAILEDandDLQnotifications and render the badge in red. - Mark unread failure notifications as read when the user opens the header menu or the notification page.
Phase 3: Operations
- Add a generic operational cleanup startup hook with retention targets for
notification_tandmessage_t. - Make cleanup configurable by enablement, interval, batch size, and per-target retention days.
- Add a database lock so only one service instance runs cleanup at a time.
- Add an admin notification page under Event Admin that uses
getNotificationwithout auserIdfilter for host-wide failures. - Add dashboards or alerts for repeated DLQ statuses.
Risks and Mitigations
| Risk | Mitigation |
|---|---|
| Notification write failure breaks event processing | Write notifications in a separate transaction after projection commit, or use savepoints for same-transaction success rows. |
| Failure notifications are rolled back with projection failures | Write FAILED and DLQ rows outside the failed projection transaction. |
| False success rows after projection rollback | Write SUCCEEDED only after projection commit, or keep same-transaction success rows rollback-safe. |
| Duplicate rows on replay | Use ON CONFLICT (host_id, id) DO UPDATE. |
| Users see other users’ events | Enforce token-based authorization in getNotification. |
| Operational tables grow without bound | Add generic operational cleanup targets and supporting indexes. |
| Cleanup runs concurrently on multiple instances | Use a database lock so only one instance runs cleanup at a time. |
| Cleanup failure blocks query service startup | Log cleanup failures and continue startup; cleanup is maintenance, not correctness-critical. |
| Status meaning stays ambiguous | Use status as the only outcome field for both pg-notify and Kafka processing. |
API Marketplace Catalog
Context
The portal already has a Marketplace navigation group and an api-marketplace
page registry entry. The current API administration page is table-oriented and
is useful for owners, but it is not a consumer catalog. A Marketplace API
catalog should let users discover APIs by business category, capability,
protocol, lifecycle status, and governance metadata.
API create and update forms already use the standardized taxonomy fields:
categoryIdsfor selected category identifiers.tagIdsfor selected tag identifiers.getCategoryLabelByTypewithentityType = "api"for category options.getTagLabelByTypewithentityType = "api"for tag options.
The service query layer also returns categoryIds, categories, tagIds, and
tags for API rows. The catalog should use those fields for display and
filtering instead of reintroducing the legacy apiTags string field.
Goals
- Add a Marketplace menu entry for an API catalog.
- Use database-backed categories and tags, not hard-coded UI lists.
- Keep categories and tags reusable across future catalog pages.
- Keep API create/update forms as the source of truth for taxonomy assignment.
- Give consumers a browse-first experience instead of an admin table.
- Support deep links from a catalog listing to API detail, versions, endpoints, runtime bindings, and owner actions.
- Preserve host scope and ownership rules already used by API administration.
Non-Goals
- Do not replace API administration pages with the catalog.
- Do not store display names in API rows when they can be resolved from
category_t,tag_t,entity_category_t, andentity_tag_t. - Do not use the old
apiTagsfield for catalog filtering. - Do not make taxonomy values static frontend constants.
- Do not expose private tenant APIs through a public catalog without an explicit visibility and authorization decision.
Current Building Blocks
| Area | Current shape | Catalog use |
|---|---|---|
| Portal navigation | Marketplace group already exists in the sidebar | Add an API Catalog child item under Marketplace |
| Page registry | api-marketplace points to /app/marketplace, while the app route still needs a real catalog page | Keep a registry entry for search, task links, and help links |
| API admin page | Service.tsx calls service/getApi and displays categories and tags | Reuse its query contract but present catalog cards/list views |
| API detail page | ApiDetail.tsx shows API versions and action links | Catalog detail can deep-link to this page |
| Forms | createApi and updateApi submit categoryIds and tagIds | Catalog reads the same assignments |
| Category labels | category/getCategoryLabelByType returns id and label | Use for category tabs, filters, and chips |
| Tag labels | tag/getTagLabelByType returns id, label, value, group code, group label, group sort order, and tag sort order | Use for grouped tag filters and grouped multi-select controls |
| Database | category_t, tag_t, entity_category_t, and entity_tag_t are entity-type scoped | Use entity_type = 'api' for API catalog taxonomy |
User Experience
The first screen under Marketplace should be the usable catalog, not a landing page. The recommended route is:
/app/marketplace/api
The sidebar can keep the existing Marketplace group, but its children should move from API-type-only links to intent-based entries:
- API Catalog
- API Clients
- Schema Catalog
- YAML Rule
- Schema Form
The API Catalog page should provide:
- Search across API id, name, description, business group, line of business, capability, platform, git repository, categories, and tags.
- Category tabs or a category rail based on
getCategoryLabelByType. - Grouped tag filters based on
getTagLabelByType. - Filter chips for active category and tag selections.
- A compact card or list row per API with name, description, status, categories, tags, owner, business group, and latest version summary.
- Actions to view details, review versions, create a new version, update the API metadata, and open related runtime or access-control pages when the user has permission.
The catalog should support an Uncategorized bucket for active APIs without
category assignments. This avoids hiding incomplete data and gives admins an
easy cleanup target.
Categories And Tags
Categories should be stable browse buckets. Tags should be flexible facets.
Both are stored with entityType = "api" so the same tag names can be reused
for other entity types without forcing cross-catalog semantics.
Recommended initial API categories:
| Category value | Label | Purpose |
|---|---|---|
public-api | Public API | External developer-facing APIs |
partner-api | Partner API | APIs shared with business partners |
internal-api | Internal API | Organization-internal service APIs |
platform-service | Platform Service | Shared platform or infrastructure APIs |
data-api | Data API | Data access, analytics, reporting, and query APIs |
ai-automation-api | AI / Automation API | Agent, workflow, automation, or AI-facing APIs |
security-compliance-api | Security / Compliance API | Identity, audit, policy, compliance, and control APIs |
developer-tooling-api | Developer Tooling API | Build, test, deployment, and developer-experience APIs |
legacy-modernization-api | Legacy / Modernization API | Legacy integration and modernization APIs |
The stored category_name must stay lower-case and URL-friendly. The display
labels above are UI labels derived from those values.
Recommended initial API tag groups:
| Group code | Group label | Example tag values |
|---|---|---|
protocol | Protocol | openapi, graphql, hybrid, mcp, rest, event-driven |
lifecycle | Lifecycle | draft, review, implemented, deprecated, beta, ga |
security | Security | oauth2, jwt, mtls, pii, hipaa, pci, read-only |
runtime | Runtime | gateway, sidecar, kubernetes, serverless, multi-region |
domain | Domain | customer, order, payment, inventory, tax, billing |
consumer | Consumer | public, partner, internal, agent-facing, mobile, web |
operations | Operations | high-traffic, low-latency, batch, streaming, critical |
integration | Integration | database, kafka, s3, third-party, mainframe, saas |
Stored tag names must stay lower-case and URL-friendly. If a display label needs capitalization, the UI should format it or the label endpoint should provide a separate display field later.
Tags without tag_group_code or tag_group_label should be shown under a
General filter group in the catalog UI. Configured groups should appear first
by group_sort_order; the General group should appear after configured
groups, matching the current label query behavior where null group sort values
sort last.
Data Flow
Catalog filter option loading:
portal-view
-> category/getCategoryLabelByType(hostId, entityType = "api")
-> tag/getTagLabelByType(hostId, entityType = "api")
Catalog result loading:
portal-view
-> service/getApi(hostId, offset, limit, active, filters, globalFilter, sorting)
-> api rows with categoryIds, categories, tagIds, tags
The catalog should prefer server-side pagination and filtering. Client-side filtering is acceptable only for a small first pass because it breaks as soon as the API count exceeds one fetched page.
Query Contract
The existing getApi contract already supports filters, globalFilter,
sorting, offset, limit, hostId, and active. To make the catalog work
well at scale, add first-class filter support for taxonomy fields:
{
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f",
"offset": 0,
"limit": 20,
"active": true,
"categoryIds": ["..."],
"tagIds": ["..."],
"tagMatch": "all",
"globalFilter": "payment"
}
Recommended semantics:
categoryIdsuses OR semantics by default. An API in any selected category is returned.tagIdsshould supporttagMatch = "all"andtagMatch = "any".- Category and tag filters should use
EXISTSagainstentity_category_tandentity_tag_twithentity_type = 'api'andactive = TRUE. - Display arrays should continue to be returned as
categoriesandtags. - Form update payloads should continue to submit identifiers only through
categoryIdsandtagIds.
Page Design
The API Catalog page can be implemented as a dedicated page rather than trying to stretch the current API admin table.
Proposed files:
src/pages/marketplace/ApiCatalog.tsx
src/pages/marketplace/components/ApiCatalogFilters.tsx
src/pages/marketplace/components/ApiCatalogCard.tsx
src/pages/marketplace/hooks/useApiCatalog.ts
Page state:
- search text
- selected category ids
- selected tag ids
- tag match mode
- active status
- pagination
- sorting
- view mode, either compact list or card grid
Catalog state should be URL-driven from Phase 1. Search text, selected categories, selected tags, tag match mode, active status, sorting, and pagination should be encoded in the query string so users can refresh the page, use browser navigation, and share filtered catalog URLs. Example:
/app/marketplace/api?q=payment&category=public-api&tag=oauth2&tag=mtls&tagMatch=all&page=1
The page should still reuse existing infrastructure:
fetchClientfor portal query calls.useUserStatefor host and user context.buildTaskAwareRoutefor deep links.- ownership utilities for update/delete action visibility.
TaskActionPanelfor publisher/admin next actions.pageRegistryand contextual help metadata.
Routing And Navigation
Add or update these portal-view entries:
| Location | Change |
|---|---|
Sidebar.tsx | Add API Catalog under Marketplace with route /app/marketplace/api |
App.tsx | Route /app/marketplace/api to ApiCatalog |
pageRegistry.ts | Add or update API Catalog metadata, keywords, and help path |
taskRegistry.ts | Update publish/review steps to point to /app/marketplace/api |
| Help docs | Add a user-facing help page after the UI settles |
The existing /app/marketplace route can redirect to /app/marketplace/api or
remain a broader Marketplace landing page later. For the first API catalog
implementation, redirecting keeps the behavior simple.
Backend Changes
The backend already persists API category and tag relationships. The main backend change is query filtering:
- Extend
service-queryspec for optionalcategoryIds,tagIds, andtagMatch. - Update
GetApito pass those optional fields to the DB provider. - Update
PortalDbProvider#getApiandApiServicePersistenceImpl#getApi. - Add SQL predicates over
entity_category_tandentity_tag_t. - Verify or add compound indexes for taxonomy filtering.
- Add tests for category-only, tag-any, tag-all, combined taxonomy filters, and APIs with no taxonomy assignments.
The existing join-table indexes are useful for entity lookups and label resolution, but catalog filtering also needs indexes that start with filter fields. Before implementing Phase 2, verify the query plan and add indexes if needed:
CREATE INDEX idx_entity_tag_filter
ON entity_tag_t (entity_type, tag_id, entity_id)
WHERE active = TRUE;
CREATE INDEX idx_entity_category_filter
ON entity_category_t (entity_type, category_id, entity_id)
WHERE active = TRUE;
For tagMatch = "all", prefer a single grouped subquery over generating one
EXISTS predicate per selected tag when the selected tag set can grow. A common
shape is to filter entity_tag_t by selected tag ids, group by entity_id, and
require COUNT(DISTINCT tag_id) = selectedTagCount.
The query response should continue to include both identifiers and labels:
{
"apiId": "0001",
"apiName": "Petstore",
"categoryIds": ["..."],
"categories": ["public-api"],
"tagIds": ["..."],
"tags": ["openapi", "oauth2"]
}
Implementation Phases
Phase 1: Catalog Page
- Add the API Catalog route and Marketplace menu entry.
- Load category and tag options from the existing label endpoints.
- Load APIs with
service/getApi. - Render search, category filter, grouped tag filter, and API list/card results.
- Store catalog filters, search text, sorting, and pagination in the URL query string.
- Use current query response labels for display.
- Deep-link to existing API detail and update forms.
Phase 2: Server-Side Taxonomy Filters
- Add
categoryIds,tagIds, andtagMatchtoservice-query. - Implement SQL filtering in
ApiServicePersistenceImpl. - Keep current table filtering support for admin use.
- Add DB provider and handler tests.
Phase 3: Catalog Polish
- Add API detail summary panels with versions, endpoint count, runtime exposure, and access-control hints.
- Add help docs and task links.
- Add optional counts per category and tag if the catalog needs faceted counts.
Open Questions
- Should Marketplace API Catalog show only active APIs by default? The recommendation is yes, with an admin-visible inactive filter.
- Should unauthenticated users ever see catalog data? The recommendation is no until a separate public visibility model is designed.
- Should category selection be single-select or multi-select? The recommendation is multi-select OR semantics for flexibility.
- Should tags use all-match or any-match by default? The recommendation is
allfor precision, with a visible toggle if users need broader searches. - Should OpenAPI tags imported from specs automatically create API catalog tags? The recommendation is no for the first pass. Spec tags are often endpoint-level groupings and should not automatically become curated catalog taxonomy.
AI Agent Registration In Task Center
Status
Initial Task Center implementation is available. The first version uses the existing API-version and agent-definition commands with backend validation guardrails. A dedicated composite registration command remains a later automation enhancement.
Context
Light Portal treats an AI agent as an API. The API record provides the stable catalog identity, ownership, display name, marketplace metadata, and lifecycle. The API version record provides the deployable version identity. The agent definition record is an agent-specific profile extension for the same API version.
The current data model already reflects this relationship:
api_towns the logical API and display name.api_version_towns the API version identity.agent_definition_t.agent_def_idstores the same UUID asapi_version_t.api_version_id.agent_definition_tstores model and runtime profile fields such asmodel_provider,model_name,api_key_ref,temperature, andmax_tokens.- Agent query paths join
agent_definition_ttoapi_version_tandapi_tto expose the effective agent metadata.
The registration UX should make this model explicit. Operators should not have to understand the table split. They should see one task: register an AI agent.
Goals
- Add a focused Task Center flow named
Register AI Agent. - Register the agent first as an API and API version.
- Create the agent definition profile using the same ID as the API version.
- Keep event sourcing and replay clean by using domain events instead of direct table writes.
- Avoid duplicating mutable display name fields between
api_tandagent_definition_t. - Allow skills, tools, memory, access control, and deployment links to be added after the base agent is registered.
Non-Goals
- Do not create a second standalone agent registry independent from APIs.
- Do not make
AgentDefinitionCreatedEventcreateapi_version_t. - Do not make
ApiVersionCreatedEventdirectly writeagent_definition_tunless the event schema is intentionally expanded later. - Do not require all skill and tool assignments during the initial registration.
- Do not replace the existing
Manage GenAI Assetstask. That task remains the broader maintenance flow.
Identity Model
The agent identity is the API version identity.
api_t
host_id
api_id
api_name # canonical agent display name
api_version_t
host_id
api_version_id # canonical agent definition id
api_id
api_version
api_type = "agt" # or accepted legacy value "agent"
agent_definition_t
host_id
agent_def_id # same value as api_version_t.api_version_id
model_provider
model_name
api_key_ref
temperature
max_tokens
agent_definition_t should remain a profile extension. It should not duplicate
the agent name. Reads can continue to expose agentName, but the value should
come from api_t.api_name.
API Type
Use agt as the canonical API type for AI agents if the reference data uses the
short code model. During migration, command handlers and queries can accept
both agt and agent to avoid breaking existing test data or early records.
The Portal UI should display this as Agent and submit the canonical value.
Database columns use snake case such as api_type; event payloads and command
requests use camel case such as apiType. The mapper must preserve this
translation and normalize agent type values consistently.
When registering an agent against an existing API, the backend must validate the
existing API-version family. A logical API should not mix unrelated version
types. If the selected api_t already has active versions, they must all be
agent versions before an agt version can be added. The reverse should also be
enforced: once an API has an active agent version, non-agent API versions should
not be added under the same api_id.
Event Model
The Task Center flow should produce two domain events for the required base registration:
ApiVersionCreatedEventAgentDefinitionCreatedEvent
The two-event design is preferred because these are two separate domain facts:
- an API version exists and can participate in the API catalog;
- that API version has an agent runtime profile.
This should not be modeled as two direct table writes from one handler. The event processor should continue to populate projection tables during normal processing and replay.
Event Order
ApiVersionCreatedEvent must be persisted and projected before
AgentDefinitionCreatedEvent, because agent_definition_t has a foreign key
to api_version_t.
Register AI Agent
-> ApiCreatedEvent, if the logical API does not already exist
-> ApiVersionCreatedEvent
-> AgentDefinitionCreatedEvent
-> optional AgentSkillCreatedEvent events
-> optional access-control events
The minimum required sequence for an existing API is:
ApiVersionCreatedEvent
AgentDefinitionCreatedEvent
Aggregate IDs
ApiVersionCreatedEvent keeps the API version aggregate identity:
{
"aggregateType": "ApiVersion",
"subject": "<apiVersionId>",
"data": {
"hostId": "<hostId>",
"apiId": "<apiId>",
"apiVersionId": "<apiVersionId>",
"apiVersion": "1.0.0",
"apiType": "agt"
}
}
AgentDefinitionCreatedEvent uses the same UUID for its aggregate identity:
{
"aggregateType": "AgentDefinition",
"subject": "<apiVersionId>",
"data": {
"hostId": "<hostId>",
"agentDefId": "<apiVersionId>",
"apiVersionId": "<apiVersionId>",
"modelProvider": "openai",
"modelName": "gpt-4.1",
"apiKeyRef": "secret://openai/default",
"temperature": 0.7,
"maxTokens": 4096
}
}
The event utility should continue to accept either agentDefId or
apiVersionId for AgentDefinition aggregate ID calculation, but the canonical
payload should include both during migration and treat them as equal.
Task Center Flow
Add a Task Center definition:
id: register-ai-agent
title: Register AI Agent
category: API Marketplace or Portal Administration
roles: user, admin
keywords: agent, ai, genai, model, skill, tool
The task should guide the operator through a narrow registration path. It is
different from Manage GenAI Assets, which is a broad maintenance task for
agents, skills, tools, memory, and session history.
Steps
| Step | Required | Route | Purpose |
|---|---|---|---|
| Create or select API | Yes | /app/form/createApi or API selector | Establish the logical API record and canonical agent name. |
| Create agent API version | Yes | /app/form/createApiVersion?apiType=agt | Create api_version_t with agent API type and return apiVersionId. |
| Configure agent profile | Yes | /app/form/createAgentDefinition or /app/genai/AgentDefinition | Create agent_definition_t with agentDefId = apiVersionId. |
| Assign skills | No | /app/genai/AgentSkill | Attach curated skills to the agent. |
| Review tools | No | /app/genai/Tool or /app/genai/SkillTool | Confirm agent-invokable tools through skill-tool assignments. |
| Configure access | No | /app/access/rolePermission | Restrict who can invoke or manage the agent. |
| Link runtime instance | No | /app/instance/InstanceApi | Attach the agent API version to a deployed runtime or gateway if needed. |
Task Context
The task context should carry IDs from one step to the next:
{
"hostId": "<hostId>",
"apiId": "<apiId>",
"apiVersionId": "<apiVersionId>",
"agentDefId": "<apiVersionId>",
"serviceId": "<serviceId>",
"providerId": "<modelProvider>",
"apiType": "agt"
}
When the API version step completes, apiVersionId should be copied to
agentDefId automatically before launching the agent definition step.
Incomplete Registration Handling
If the UI calls createApiVersion and then fails before createAgentDefinition
is processed, the system can contain an agent API version without an agent
definition. This is an incomplete registration, not a valid runnable agent.
The UI and query layer should treat these rows explicitly:
- Agent list views should be able to detect agent API versions missing matching
agent_definition_trows by left joiningapi_version_ttoagent_definition_t. - The row should be shown as
IncompleteorProfile missing, not as a ready agent. - The primary action should be
Complete profile, prefilled withagentDefId = apiVersionId. - A secondary action can delete or deactivate the orphaned API version if the operator abandons the registration.
- Runtime catalog reads should not expose incomplete agents as executable.
This requirement makes the UI-orchestrated implementation safe enough for the first Task Center version. The long-term backend command should still create the version and profile in one ordered command to reduce orphan creation.
Frontend Design
Phase 1: Task Registry Only
The first implementation can add a Task Center entry that reuses existing pages and forms:
createApicreateApiVersioncreateAgentDefinitionAgentSkillSkillToolrolePermissionInstanceApi
This is low risk and aligns with the current task-oriented navigation model.
The createApiVersion form should support prefilled apiType=agt from the
task route. The form completion handler should save returned apiVersionId into
the task context.
The createAgentDefinition form should accept apiVersionId or agentDefId
from task context and submit both values, with agentDefId equal to
apiVersionId.
Phase 2: Dedicated Registration Wizard
After the flow is validated, add a dedicated wizard route such as:
/app/genai/register-agent
The wizard can reduce clicks by combining API version and agent profile fields on one page while still submitting separate commands or a composite command.
Recommended sections:
- API identity: API name, API ID, status, owner.
- Version identity: version, service ID, environment tag, target host.
- Model profile: provider, model, API key reference, temperature, max tokens.
- Optional skills: selected skill IDs.
- Optional deployment: instance or gateway link.
Secret Reference Selection
apiKeyRef is a secret reference, not a secret value. The UI should not ask
operators to paste raw provider keys into the agent definition form.
The preferred control is a selector populated from the configured secret catalog, config-server reference data, or vault integration available to the current host. The selected value should be stored as a reference such as:
secret://openai/default
If manual entry is temporarily supported, it should be an advanced path with validation. The command should reject values that look like raw API keys and should accept only approved reference schemes.
Secure Default Access
The access-control step is optional for registration completeness, but runtime execution must be secure by default. A newly registered agent should not be publicly invokable just because the API version and profile exist.
Default behavior:
- management is limited to the creator, owner, or admin roles according to the existing ownership model;
- runtime invocation is denied until an explicit role, scope, policy, or runtime assignment grants access;
- skill and tool assignment does not override access control;
- if no access policy exists, the gateway or agent runtime should treat the effective execution policy as deny-all.
Backend Command Options
Option 1: UI-Orchestrated Existing Commands
The Task Center flow calls existing commands in sequence:
createApi, if a new API is needed.createApiVersion.createAgentDefinition.- Optional
createAgentSkillevents.
This is the recommended initial implementation. It avoids changing command handler infrastructure and uses existing event types.
This option must include incomplete-registration handling. Without that, a browser failure or second-command validation error can leave an agent API version without an agent definition. That state is repairable, but the UI must surface it clearly and runtime catalog reads must ignore it.
Option 2: Composite Register Command
Add a composite command such as:
lightapi.net/genai/registerAiAgent/0.1.0
The command would validate the combined request and emit ordered events:
ApiVersionCreatedEvent.AgentDefinitionCreatedEvent.- Optional
AgentSkillCreatedEventevents.
This improves user experience for automation and API consumers, but it requires the command layer to support a multi-event result in one request. The command must not bypass event processing or write projection tables directly.
The initial composite command should require an existing apiId. Keeping API
creation as a separate command keeps the backend contract smaller and preserves
the existing API ownership workflow. A later full registration command can add
ApiCreatedEvent if automation needs to create the logical API and agent
version in one request.
Recommendation
Start with Option 1 only if incomplete registrations are visible and repairable. Prioritize Option 2 before exposing a one-click production registration wizard, because it gives the backend one validation boundary for the API version and agent profile.
Validation Rules
Command handlers should enforce these rules server-side:
- Agent API versions must use
apiType = agtor an accepted compatible value. - New writes should use canonical
agt. Legacyagentshould be accepted only for migration, import, or replay compatibility. - A logical API should not mix active agent and non-agent API versions.
agentDefIdmust equalapiVersionIdwhen both are present.- The referenced API version must exist before creating the agent definition.
- The referenced API version must belong to the same
hostId. - The referenced API version must have agent API type.
modelProviderandmodelNameare required for creation.apiKeyRef, when present, must be a secret reference and not a raw provider key.temperature, when provided, must be in the supported provider range.maxTokens, when provided, must be positive.- Optional skill IDs must reference active skills in the same host scope.
The UI should guide the user, but the command and persistence layers should remain authoritative.
Query And Display
Agent list and detail views should display a joined projection:
| Field | Source |
|---|---|
agentDefId | agent_definition_t.agent_def_id |
apiVersionId | same value as agentDefId |
agentName | api_t.api_name |
apiId | api_version_t.api_id |
apiVersion | api_version_t.api_version |
apiType | api_version_t.api_type |
serviceId | api_version_t.service_id |
envTag | api_version_t.env_tag |
targetHost | api_version_t.target_host |
modelProvider | agent_definition_t.model_provider |
modelName | agent_definition_t.model_name |
apiKeyRef | agent_definition_t.api_key_ref |
The Agent Definition page should make the API identity read-only once selected.
Mutable profile fields should remain editable through
AgentDefinitionUpdatedEvent.
Delete And Update Semantics
Updating the API name should update the visible agent name because the display
name comes from api_t.api_name.
Updating the API version should not implicitly update model settings. Model
profile changes should use AgentDefinitionUpdatedEvent.
Deleting or deactivating the API version should cascade or hide the agent
definition through the existing API-version relationship. Explicit
AgentDefinitionDeletedEvent remains useful when the operator wants to disable
the agent profile while keeping the API version.
Migration Notes
- Existing rows that use
api_type = agentcan remain readable while the UI moves toward canonicalagt. - Projection builders can normalize legacy
agentevents toagtinapi_version_tafter the migration window. Event streams remain immutable, but new command writes should use onlyagt. - Existing task contexts may carry either
apiVersionIdoragentDefId. Task utilities should normalize both values to the same ID. - Documentation and form labels should say
Agent API version idwhere the ID is exposed. - Import/export and event replay should preserve event order for agent registration bundles.
Implementation Plan
- Add
Register AI Agenttoportal-view/src/tasks/taskRegistry.ts. - Add help content under
src/help/portal-view/tasks/register-ai-agent.md. - Ensure
createApiVersioncan be launched withapiType=agt. - Ensure form completion stores
apiVersionIdinto task context. - Ensure
createAgentDefinitioncan prefillagentDefIdfromapiVersionId. - Add server-side validation that
agentDefId == apiVersionId. - Add compatibility handling for
agtandagentAPI type values. - Add incomplete-registration detection and repair actions for agent API versions that do not have a matching agent definition.
- Add secure-by-default invocation checks for agents with no explicit access policy.
- Add integration tests for the two-event registration sequence.
- Add a composite
registerAiAgentcommand for API-version plus profile creation.
Resolved Recommendations
- Persist
agtas the canonical API type after migration. Keepagentreadable for replay, import, and old data, but reject new command writes usingagentafter the migration window. - Put
Register AI AgentunderAPI Marketplaceinitially because the agent is registered as an API and should be discoverable through the API catalog. If a dedicatedGenAI Assetscategory is added later, the task can move there without changing the backend model. - Keep skill assignment optional. An agent can be useful as an LLM-only worker, and required skill assignment would block simple conversational agents.
- The first composite command should require an existing API and emit
ApiVersionCreatedEventplusAgentDefinitionCreatedEvent. KeepApiCreatedEventseparate until automation needs a full create-everything command.
Decision Summary
Register AI agents through a Task Center flow that starts from API and API
version registration. Create api_version_t first, then create
agent_definition_t with agentDefId equal to apiVersionId. Use two domain
events for the two required facts, keep projection writes behind event
processing, reject mixed API-type families, treat incomplete version-only
registrations as repairable but non-runnable, default runtime invocation to
deny-all, and make the broader skill/tool/access setup optional follow-up steps.
OAuth Kafka
Token Exchange
This document outlines the design decisions and implementation details for supporting multiple token exchange flows in the oauth-kafka module.
Comparison of Detection Methods
When implementing token exchange (RFC 8693), the server must determine which identity provider (IdP) issued the subject_token to verify it correctly and map claims.
| Method | Explanation | Pros | Cons | Recommended For |
|---|---|---|---|---|
JWT Peek (iss) | Server decodes the token header/body without verification to read the iss claim. | Zero client configuration; Uses standard parameters. | Token is parsed twice; Sensitive to malformed tokens. | Public OIDC providers (Azure, Okta, Google). |
| Custom URNs | Client sends a specific requested_token_type (e.g. urn:networknt:msal). | Explicit and unambiguous; Follows standard extensibility. | Clients must know the specific URNs for each flow. | Mixed heterogeneous token types (SAML vs JWT). |
subject_issuer | Client passes an extra subject_issuer parameter in the request. | Clean API; Works with “opaque” (non-JWT) tokens. | Non-standard parameter; Redundant for self-describing JWTs. | Opaque tokens or overlapping issuers. |
| Client Context | Server maps the client_id of the caller to a specific flow. | Highly secure; Enforces strict per-client policy. | High management overhead; Inflexible for multi-source clients. | Rigid, security-conscious B2B integrations. |
Implementation Strategy
Our implementation in ProviderIdTokenPostHandler uses Option 4: Client Context as the primary strategy:
- Database-Driven Configuration: A new column
token_ex_typehas been added to theauth_client_ttable to specify the supported exchange type for each client.ALTER TABLE auth_client_t ADD COLUMN token_ex_type VARCHAR(64); - Supported Exchange Types:
msal: Microsoft Authentication Library based exchange.ccac: Client Credentials to Authorization Code exchange.
- Flow Determination: Instead of relying on client-supplied parameters like
requested_token_type, the server retrieves thetoken_ex_typefrom the client context in the database to decide which handler to use. This ensures that only authorized exchange types are performed for each specific client.
Recommendation
For the light-portal ecosystem:
- Option 4: Client Context is the selected method. It provides the highest level of security by ensuring that token exchange flows are explicitly configured and restricted on a per-client basis in the database.
token_ex_typeshould be populated for any client that requires token exchange functionality. Clients without this configuration will not be allowed to perform token exchange.
Future Considerations
- Implement automated issuer discovery if the number of external providers grows.
- Support “opaque” token exchange by integrating with introspection endpoints of external IdPs.
- Extend the
auth_client_tconfiguration to support multiple allowed exchange types per client if needed.
Light OAuth
Light OAuth IPv6 Support
Problem
The Rust light-oauth service binds its HTTPS listener to 0.0.0.0.
That is correct for IPv4, but it does not accept connections sent to an IPv6
address.
In a dual-stack container network, Docker DNS can return the IPv6 address for
light-oauth before the IPv4 address. A client that does not retry the next
address can fail even though the service is healthy on IPv4. One observed
failure is the gateway proxying /oauth2/{providerId}/code to
https://light-oauth:6881 and receiving ECONNREFUSED on the IPv6 address.
Goals
- Allow
light-oauthto bind IPv4, IPv6, or a specific interface from config. - Keep the current default behavior as IPv4 wildcard binding.
- Avoid breaking existing deployments whose
server.ymldoes not contain the new property. - Build the listener address with
SocketAddrso IPv6 addresses are parsed correctly.
Non-Goals
- Do not enable IPv6 for every deployment by default.
- Do not change TLS, OIDC, token, or database behavior.
- Do not change gateway upstream retry behavior in this change.
Configuration
light-oauth adds a server bind IP property:
ip: ${server_ip:0.0.0.0}
The default value remains:
server_ip: "0.0.0.0"
To listen on IPv6 wildcard:
server_ip: "::"
To listen on a specific IPv4 or IPv6 address:
server_ip: "172.16.1.3"
server_ip: "fdd0:0:0:1::3"
Implementation
The Rust config model includes an ip field with a default of 0.0.0.0.
The default keeps old external server.yml files working.
The listener address is built as:
#![allow(unused)]
fn main() {
let ip = config.ip.parse::<IpAddr>()?;
let addr = SocketAddr::new(ip, config.port);
}This avoids string formatting problems with IPv6 addresses. For example,
:: plus port 6881 must become [::]:6881, not :::6881.
Deployment Guidance
Use IPv6 binding only when the runtime network is intentionally dual-stack and other services can reach the IPv6 address. In a container environment, confirm that:
- the container network has IPv6 enabled;
- the service has an IPv6 address;
- clients resolve or connect to the same address family;
- health checks cover the chosen address family.
For local or single-stack deployments, keep the default IPv4 binding.
Verification
For IPv4 default:
curl -k https://light-oauth:6881/oauth2/<providerId>/keys
For IPv6 wildcard binding in a dual-stack network, verify from another container:
curl -k -g https://[<light-oauth-ipv6>]:6881/oauth2/<providerId>/keys
If the client uses service DNS, verify that the first returned address family is reachable:
getent ahosts light-oauth
curl -k -v https://light-oauth:6881/oauth2/<providerId>/keys
Light Controller
Light Controller IPv6 Support
Problem
The Rust controller-rs service is the control-plane endpoint for runtime
registration, discovery, MCP admin traffic, and portal event streams. In
dual-stack deployments, clients can resolve the controller hostname to either
IPv4 or IPv6. The controller listener and its TLS configuration must therefore
support IPv6 without changing the existing IPv4 deployment defaults.
The important distinction is between socket addresses and service metadata:
- the controller listener uses a socket address such as
0.0.0.0:8438or[::]:8438; - registered runtime instances publish a host address string plus a separate
port, such as
fdd0:0:0:1::3and8443.
Current Behavior
controller-rs already stores its bind address as a Rust SocketAddr.
The default remains IPv4 wildcard binding:
0.0.0.0:8438
The listener address can be overridden with CONTROLLER_ADDR.
For IPv6, the value must use bracketed socket-address syntax:
CONTROLLER_ADDR='[::]:8438'
This value is used directly by both server modes:
- HTTPS/WSS mode uses
axum_server::bind(settings.listen_addr). - HTTP/WS mode uses
tokio::net::TcpListener::bind(settings.listen_addr).
There is no string concatenation of IP and port in the controller listener
path, so the common IPv6 failure form :::8438 is avoided.
Goals
- Support IPv4, IPv6, and dual-stack controller listener binding.
- Keep the current default as IPv4 wildcard binding.
- Keep the existing
CONTROLLER_ADDRconfiguration contract. - Accept runtime registration metadata that uses IPv4 literals, IPv6 literals, or DNS hostnames.
- Reject unspecified runtime registration addresses such as
0.0.0.0and::, because those are bind addresses, not reachable service addresses.
Non-Goals
- Do not enable IPv6 by default.
- Do not change controller WebSocket paths or JSON-RPC contracts.
- Do not change the runtime registration metadata shape.
- Do not add client-side IPv4 fallback in this change.
Listener Configuration
Default IPv4 listener:
CONTROLLER_ADDR='0.0.0.0:8438'
IPv6 wildcard listener:
CONTROLLER_ADDR='[::]:8438'
Specific IPv6 interface:
CONTROLLER_ADDR='[fdd0:0:0:1::10]:8438'
Specific IPv4 interface:
CONTROLLER_ADDR='172.16.1.10:8438'
The brackets are required only because CONTROLLER_ADDR is a full socket
address. They separate the IPv6 literal from the port.
TLS Configuration
The controller starts with TLS enabled by default. IPv6 listener support does not remove the normal TLS hostname requirements.
For production, provide a certificate whose Subject Alternative Name covers the DNS name or IP address clients use to reach the controller:
CONTROLLER_TLS_CERT_PATH=/config/server.pem
CONTROLLER_TLS_KEY_PATH=/config/server.key
CONTROLLER_TLS_TRUST_CERT_PATH=/config/ca.pem
For generated local self-signed certificates, include any IPv6 literal that clients will use:
CONTROLLER_TLS_SERVER_NAME=localhost
CONTROLLER_TLS_ALT_NAMES='localhost,127.0.0.1,::1'
If clients connect by DNS name, prefer adding that DNS name to the certificate SAN and keep clients using the name instead of a raw IP literal.
Runtime Registration Metadata
Runtime services connect outbound to Light Controller and send
service/register metadata. The registration address is not a socket address;
the address and port are separate fields.
IPv6 registration metadata should use the raw IPv6 literal:
{
"serviceId": "com.networknt.light-gateway-1.0.0",
"protocol": "https",
"address": "fdd0:0:0:1::3",
"port": 8443
}
Do not use brackets in the address field:
{
"address": "[fdd0:0:0:1::3]"
}
Brackets are only used when constructing URL authorities or socket addresses.
The controller validates registration addresses as IP literals or DNS hostnames
and rejects unspecified bind addresses such as 0.0.0.0 and ::.
Discovery Behavior
Discovery returns the registered address and port separately. Downstream
clients, such as light-gateway, are responsible for building a reachable
upstream authority. For IPv6 literals, clients must bracket the address when
they construct a URL or host:port authority:
address = fdd0:0:0:1::3
port = 8443
target = [fdd0:0:0:1::3]:8443
Deployment Guidance
Only configure the controller with CONTROLLER_ADDR='[::]:8438' when the host,
container network, Kubernetes Service, and ingress path are intended to accept
IPv6 traffic.
In a dual-stack environment, verify all of these:
- the controller process is listening on IPv6;
- DNS returns the expected address family;
- TLS SANs cover the hostname or IP clients use;
- runtime services can open outbound WebSocket connections to the controller;
- registered service metadata publishes reachable addresses, not wildcard bind addresses.
Verification
From a peer in the same network:
getent ahosts <controller-host>
curl -k -g https://[<controller-ipv6>]:8438/health
curl -k -v https://<controller-host>:8438/health
For WebSocket clients, verify the same address family through the real endpoint:
wss://<controller-host>:8438/ws/microservice
wss://<controller-host>:8438/ws/discovery
wss://<controller-host>:8438/ctrl/mcp
If a TLS client connects by IPv6 literal and fails certificate validation, check the certificate SANs before changing the controller listener.
Agent Skill And API Endpoint Discovery
Problem
The GenAI chat flow has two separate concepts that are easy to confuse:
- The
light-gatewayMCP endpoint is the runtime server that lists and executes tools. An agent should call the gateway fortools/listandtools/call. A listed tool may be backed by a downstream MCP server or by a gateway-routed HTTP/OpenAPI endpoint. - Portal-query is the catalog service for skills, tools, and agent
assignments. The agent should read this catalog through the
genai-queryAPI, cache it locally, and search it during chat. - The controller registry remains a runtime control-plane service for registration, discovery, and cache-management commands. It should not own the portal skill/tool catalog and should not execute downstream MCP or REST calls.
During chat, light-agent should use its local catalog cache to find relevant
skills, then call tools/list on the gateway to verify executable tools. Tool
execution still goes through the gateway. If the catalog cache is empty or
stale, the agent should refresh it from portal-query. If portal-query is
temporarily unavailable, the agent should still be able to use the gateway tool
list directly.
The missing piece is a portal-managed catalog that explains which API endpoints exist, which endpoint projections are invokable by agents, which skills they belong to, and which agents are allowed or expected to use those skills. Without that catalog, the agent can list executable gateway tools, but it has no domain guidance beyond each tool description.
Goals
- Keep the gateway as the runtime source of truth for MCP tool execution.
- Keep direct gateway
tools/listandtools/callworking even when no skills have been authored. - Treat API endpoints as the generic capability unit. MCP tools, OpenAPI operations, JSON-RPC methods, and future protocol operations should all become endpoint-level capabilities before they are exposed to agents.
- Populate a portal endpoint and tool catalog from API version parsing,
LightAPI descriptions, gateway-discovered MCP tools, manually pasted MCP
tools/listpayloads, and gateway-routed REST tools. - Let portal users create skills that contain instructions and curated tool selections.
- Let portal users assign skills to agent definitions.
- Use the
genai-queryAPI and spec as the portal-query access surface for skills, tools, and agent assignments. - Let the agent cache the effective catalog locally and reload it when controller cache-management invalidation is triggered.
- Make skills useful for progressive disclosure without requiring every MCP tool to be wrapped before it can be called.
- Store semantic routing metadata for endpoint capabilities so the agent or portal-query can perform macro-filtering, keyword search, vector ranking, context viability checks, and safety filtering.
Non-Goals
- Do not move MCP request routing or downstream REST calls into the controller.
- Do not implement
skill/searchin controller-rs. Controller-rs can invalidate the agent cache, but portal-query owns catalog reads. - Do not use config-server as the first delivery path for the skills/tools catalog. The agent can fetch from portal-query and cache locally.
- Do not require every gateway tool to have a skill before it is executable.
- Do not replace the existing MCP Gateway registry design. This design extends it with agent-facing skill curation.
- Do not implement embeddings in the first phase. Keyword search is enough for the initial local catalog search.
- Do not limit the catalog to MCP tools. The UI may use “tool” when referring to LLM tool-calling, but the persistent capability model should be endpoint first.
- Do not use skill assignments as the only authorization control. Gateway policy and downstream authorization still apply at execution time.
Concepts
| Concept | Responsibility | Example |
|---|---|---|
| API Endpoint | Canonical endpoint-level capability stored by API version. It may come from OpenAPI, MCP tools/list, LightAPI, JSON-RPC, or another protocol. | /v1/accounts@get, getRandomNumber@call |
| Tool | Agent-facing projection of an endpoint as an executable LLM function. The runtime call is made by name through the gateway. | getAccounts calling GET /v1/accounts |
| Skill | Domain guidance plus a curated set of tools. It helps an agent decide what to expose and how to reason. | “Account Management” using account read and create tools |
| Agent | Runtime worker that receives a user prompt, discovers skills and tools, calls the LLM, then executes requested tools through the gateway. | account-agent |
| Gateway | MCP server and router. It owns runtime tools/list and tools/call behavior. | light-gateway /mcp |
| Portal Query | Catalog API service for reading skills, tools, tool params, skill-tool mappings, and agent-skill assignments. | genai-query API |
| Controller Registry | Runtime control-plane service for service metadata, discovery, and cache invalidation. | cache-management MCP tool |
| Portal | Authoring UI and persistence layer for tools, skills, and agent assignments. | Tool Catalog, Skill Editor, Agent Skill Assignment |
Target Architecture
The target flow keeps runtime execution and control-plane metadata separate.
Portal UI
-> writes api_endpoint_t, tool_t, tool_param_t, skill_t, skill_tool_t, skill_workflow_t, agent_skill_t
light-gateway /mcp
-> lists executable tools from mcp-router.tools and downstream MCP servers
-> executes tools/call against downstream MCP or REST services
light-workflow
-> owns deterministic multi-step workflow execution, task state, and audit events
portal-query genai-query API
-> serves skill/tool/agent-skill catalog reads from portal data
controller-rs portal registry
-> registers agents and sends cache-management invalidation commands
light-agent
-> loads assigned skills and mapped tools from portal-query
-> caches the effective catalog locally
-> searches cached skills during chat
-> lists executable tools from light-gateway
-> calls selected tools through light-gateway
For the account-agent example:
- The gateway exposes account tools such as
getAccountsandgetAccountByNo. - Portal stores the canonical endpoint rows in
api_endpoint_t. - Portal publishes selected endpoint rows into
tool_tas agent-invokable capabilities. - An operator creates an “Account Management” skill in
skill_t. - Portal links that skill to the account tools through
skill_tool_t. - Portal assigns the skill to the account agent through
agent_skill_t. - At startup or cache reload, the agent reads the assigned catalog through
genai-queryand caches it locally. - At chat time, the agent searches its local catalog cache.
- The agent combines matched skill instructions with the gateway tool definitions.
- Any tool call still goes to
light-gatewaytools/call.
Source Of Truth
The gateway is the runtime source of truth for executable tools. If a tool is not available from the gateway, the agent should not be able to execute it just because it exists in the portal database.
api_endpoint_t is the canonical portal endpoint catalog. It stores the
endpoint identity, protocol method, path, logical tool schema, endpoint
description, and raw tool metadata for one API version.
tool_t is the agent-facing projection of an endpoint. It stores the tool name,
agent description, implementation type, optional endpoint reference, response
schema, active flag, semantic routing fields, and semantic embedding. The full
metadata object should still be preserved in api_endpoint_t.tool_metadata for
import/export and agent cache payloads.
The portal database is the control-plane catalog. It stores:
- operator-friendly descriptions,
- skill instructions,
- agent assignments,
- governance metadata,
- cached or imported tool schemas.
Tool sync should be idempotent. The recommended unique identity is:
host_id + api_version_id + endpoint
Gateway exposure is a separate deployment selection. The catalog should sync all endpoint rows for an API version, then let the user choose which endpoint/tool projections are deployed to a specific gateway instance.
For runtime-executable projections, the gateway identity is:
hostId + serviceId + envTag
The access token used for portal catalog or gateway deployment APIs should carry
matching host, sid, and env claims. Portal-query must verify those claims
against the requested hostId, serviceId, and envTag before returning or
changing catalog data.
Runtime verification means checking whether an endpoint projection is actually
listed by a deployed gateway through tools/list. This should be done against
the selected gateway instance when an operator is preparing or reviewing a
gateway deployment. A later host-wide diagnostics view can aggregate all
registered gateways, but phase 2 does not need host-wide verification as the
default.
Runtime verification is not part of the persistence projection. The persistence
layer should store catalog state, endpoint/tool metadata, and inactive drift
state, but it should not call a live gateway. The portal UI, deployment review
flow, or a diagnostics endpoint should call the selected gateway’s tools/list
with the operator or service credential, compare the returned tool names and
schemas with the catalog, and surface the result as deployment drift.
If a previously imported endpoint or tool disappears from the gateway, the sync process should mark the catalog projection inactive instead of deleting it immediately. This preserves skill mappings and gives operators a clear drift signal.
Current Data Model
The database already has the main tables needed for this design:
skill_t: skill name, description,content_markdown, embedding placeholder, version, and active flag.tool_t: agent-facing tool catalog with name, description, implementation metadata, endpoint reference, and response schema.tool_param_t: parameter-level metadata and validation schema.agent_skill_t: maps agent definitions to skills.skill_tool_t: maps skills to tools for progressive disclosure.api_endpoint_t: MCP or REST endpoint metadata, includingtool_schemaandtool_metadata.wf_definition_t: stores workflow definitions as YAML for thelight-workflowruntime.
Phase 3.5 should add a skill-to-workflow mapping table rather than storing
workflow YAML inside skill_t. The recommended table is:
| Column | Purpose |
|---|---|
host_id | Tenant and ownership boundary. |
skill_id | Skill that can use or expose the workflow. |
wf_def_id | Workflow definition stored in wf_definition_t. |
workflow_role | Relationship type such as primary, validation, remediation, or test. |
start_mode | How the workflow can be started, such as manual, agent, scheduled, or portal. |
config | JSONB overrides for workflow input defaults, disclosure settings, or skill-specific runtime hints. |
aggregate_version | Event-sourced concurrency/version field. |
active | Soft delete and publication flag. |
The current phase 2 persistence path can preserve semantic metadata in
api_endpoint_t.tool_metadata before dedicated routing columns exist. That is
acceptable for import/export compatibility and for small catalogs searched from
the agent’s local cache. It should not be treated as the final indexed search
shape. Before portal-query performs database-side macro-filtering over large
catalogs or before vector ranking becomes a production dependency, promote the
high-use routing fields to first-class columns or indexed relationships and
backfill them from tool_metadata.
The existing MCP Registry design already maps MCP tools into api_endpoint_t.
OpenAPI parsing also creates endpoint rows. This design uses tool_t as the
agent-facing catalog row and links it back to api_endpoint_t when the tool
originates from an API endpoint.
Recommended mapping for gateway-imported tools:
| Gateway tool field | Portal storage |
|---|---|
name | tool_t.name and api_endpoint_t.endpoint_name |
description | tool_t.description and api_endpoint_t.endpoint_desc |
inputSchema | api_endpoint_t.tool_schema and generated tool_param_t rows |
| Gateway route metadata | gateway exposure metadata keyed by hostId, serviceId, and envTag |
| Downstream REST path | tool_t.api_endpoint and api_endpoint_t.endpoint_path |
| Downstream method | tool_t.api_method and api_endpoint_t.http_method |
| Safety flags | indexed tool metadata plus api_endpoint_t.tool_metadata.safety |
tool_t.implementation_type should be a standardized enum aligned with the
LightAPI Description execution model. Endpoint-backed tools should use a
LightAPI endpoint implementation type rather than preserving every downstream
transport as a different tool implementation. The downstream protocol remains
in the endpoint and LightAPI request metadata.
Recommended first enum values:
| Implementation type | Use |
|---|---|
lightapi_endpoint | Any agent-invokable API endpoint described by api_endpoint_t and LightAPI metadata. |
java | In-process Java implementation. |
python | Script-backed Python implementation. |
javascript | Script-backed JavaScript implementation. |
For lightapi_endpoint, execution still goes through gateway tools/call when
the endpoint is exposed to a gateway. The source protocol, such as MCP,
OpenAPI, JSON-RPC, OpenRPC, or gRPC, belongs in api_endpoint_t,
tool_metadata, and the LightAPI request description.
Endpoint-First Capability Model
Agents and skills should operate over endpoint capabilities, not only over MCP tools. MCP remains the runtime protocol for tool-calling through the gateway, but the catalog should support any endpoint that can be represented as an agent-invokable capability.
Recommended capability layers:
api_endpoint_t: canonical endpoint row for the API version.tool_t: agent-facing executable projection of the endpoint.tool_param_t: normalized top-level input parameters derived from the endpoint’s JSON Schema.skill_tool_t: curated relationship between a skill and a tool projection, including per-skill overrides such as priority, examples, or approval notes.agent_skill_t: assignment of skills to agent definitions.
This model supports these source types:
| Source | Endpoint identity | Tool projection |
|---|---|---|
MCP tools/list | <toolName>@call | Tool name is the MCP tool name; method is call. |
| OpenAPI | <path>@<method> | Tool name comes from operation id or generated endpoint name. |
| LightAPI Description | operation.endpointId or <operationId>@<method> | Tool name comes from operation id or curated agent metadata. |
| JSON-RPC/OpenRPC | <method>@call | Tool name is the method or curated operation name. |
| gRPC | <service>/<method>@call | Tool name is the curated operation name. |
tool_param_t should be generated from the logical input schema, not from wire
transport details alone. For OpenAPI, the logical input schema should merge
path parameters, query parameters, and request body into one object. For MCP,
the logical input schema is the MCP inputSchema. For JSON-RPC, it is the
logical params schema.
Semantic Routing Metadata
The customer-required semantic routing fields should be first-class indexed catalog data, not only JSON metadata. They are used for macro-filtering before expensive keyword, vector, or LLM ranking, so the common filter fields must be queryable through normal portal-query indexes.
Recommended indexed fields or relationships:
- domain and semantic namespace,
- sensitivity tier,
- semantic weight,
- target personas,
- active state,
- source protocol and implementation type,
- portal category and tag relationships.
Recommended phase 2 column names for endpoint and tool projections:
| Field | Suggested column or relationship | Source fallback |
|---|---|---|
| Domain | routing_domain | tool_metadata.routing.domain, LightAPI capability group, OpenAPI tag. |
| Semantic namespace | semantic_namespace | tool_metadata.routing.semanticNamespace, LightAPI info.namespace. |
| Sensitivity tier | sensitivity_tier | tool_metadata.routing.sensitivityTier, LightAPI visibility or safety metadata. |
| Semantic weight | semantic_weight | tool_metadata.routing.semanticWeight, default 1.0. |
| Source protocol | source_protocol | LightAPI operation protocol, OpenAPI, MCP, JSON-RPC, gRPC. |
| Target personas | join table or indexed array | tool_metadata.routing.targetPersonas, LightAPI agent metadata. |
The full structured payload should still be preserved in
api_endpoint_t.tool_metadata so LightAPI import/export, gateway config
generation, and agent cache payloads have one portable metadata object.
Recommended api_endpoint_t.tool_metadata shape:
{
"routing": {
"domain": "finance.accounts",
"category": "account-management",
"semanticNamespace": "prod.accounts.core",
"targetPersonas": ["account-agent", "customer-support-agent"],
"semanticDescription": "Retrieves account profile and status information when a user asks about an existing account.",
"semanticKeywords": ["account lookup", "customer account", "balance", "status"],
"contextRequirements": {
"requiredInputs": ["accountNo"],
"requiredContext": ["host_id"]
},
"dependencies": [
{
"endpoint": "/v1/accounts/{accountNo}@get",
"relation": "frequently_chained_after"
}
],
"semanticWeight": 0.75,
"sensitivityTier": "Internal-Only",
"fallbackEndpoint": "/v1/accounts@get",
"embedding": {
"model": "tool-description-embedding",
"source": "semanticDescription"
}
},
"safety": {
"read_only": true,
"destructive": false,
"humanApprovalRequired": false
}
}
Recommended ownership:
| Metadata | Primary storage | Notes |
|---|---|---|
| Domain and namespace | Indexed endpoint/tool columns plus tool_metadata.routing | Used for macro-filtering before vector ranking. |
| Categories and tags | Existing portal tag/category tables plus tool_metadata.routing | Reuse the portal taxonomy instead of creating a separate endpoint taxonomy. |
| Target personas | Indexed mapping or array plus tool_metadata.routing.targetPersonas | Used to filter the effective catalog for the current agent. |
| Rich capability description | tool_t.description plus tool_metadata.routing.semanticDescription | tool_t.description should be the concise LLM-facing description. |
| Synonyms and keywords | tool_metadata.routing.semanticKeywords | Used by keyword search and embedding source text. |
| Embedding vector | tool_t.description_embedding | The embedding provider must produce the configured vector dimension, currently 384, or the column must be migrated. |
| Required state/context locks | tool_metadata.routing.contextRequirements | The router should exclude non-viable tools before LLM tool injection. |
| Dependency mappings | tool_metadata.routing.dependencies | Used for chain suggestions, prefetch, or warm-up. |
| Priority score | Indexed column plus tool_metadata.routing.semanticWeight | Numeric multiplier for ranking ties. |
| Sensitivity tier | Indexed column plus tool_metadata.routing.sensitivityTier | Used before disclosure and before execution. |
| Fallback target | tool_metadata.routing.fallbackEndpoint | Runtime fallback should still respect gateway policy. |
| Destructive/read-only flags | tool_metadata.safety and existing gateway toolMetadata | Runtime enforcement belongs in gateway or policy, not only in prompts. |
The first semantic search implementation can work from the agent’s local cache:
- Filter by host, active flag, assigned skill, domain, namespace, target persona, and sensitivity tier.
- Exclude endpoints whose required context is not available in the current workflow or chat state.
- Rank by keyword matches over skill text, endpoint name, tool name, description, semantic keywords, and LightAPI capability text.
- When embeddings are populated, combine vector similarity with the keyword
score and multiply by
semanticWeight. - Call gateway
tools/listand intersect the ranked set with currently executable tools before exposing schemas to the LLM.
Embedding Recommendation
Keep the first production embedding dimension at 384 because the current
Postgres vector column is already VECTOR(384) and the first catalog use case
is routing over short endpoint descriptions, not long document retrieval.
Recommended model strategy:
- Use a provider abstraction with configured
embedding_model,embedding_dimension, andembedding_source. - For OpenAI-hosted embeddings, use
text-embedding-3-smallwith the dimensions parameter set to 384. - For on-prem or firewall-restricted deployments, use a local embedding service that is configured to emit 384-dimensional vectors.
- Store enough metadata to know how a vector was created: model, dimension, source text hash, source field, and generated timestamp.
- Re-embed when the semantic description, keywords, domain, or model config changes.
The portal catalog write path should remain in the portal service layer that
owns api_endpoint_t and tool_t persistence. Because the current portal
command/query services are Java, the Java side should own transactions,
versioning, and persistence of embedding results. A Rust service or worker can
still generate embeddings behind an internal API or queue consumer, especially
if local model performance is better there. In that model, Java requests or
consumes the vector and writes it through the normal portal persistence path.
LightAPI Description Enrichment
LightAPI Description should be the preferred enrichment source for endpoint
capabilities. OpenAPI and MCP tools/list are good at initial extraction, but
LightAPI adds the agent-oriented context needed for high-accuracy routing:
- endpoint identity and stable
endpointId - domain, tags, lifecycle, visibility, and capability group
- logical input schema and request mapping
- result schema and result cases
- examples and behavior notes
- progressive disclosure metadata
- agent-facing descriptions, personas, keywords, context requirements, and guardrails
Recommended merge priority for endpoint metadata:
- Portal operator overrides.
- Endpoint-level LightAPI Description.
- API-level inherited LightAPI Description context.
- OpenAPI/OpenRPC/protobuf/MCP source extraction.
- Gateway runtime
tools/listdiscovery.
This keeps runtime discovery useful while letting curated LightAPI descriptions provide richer semantic routing without hand-authoring every endpoint as an independent skill.
Phase 2 persistence should be treated as the receiver for this metadata, not as the extractor. The openapi-parser, a LightAPI Description parser, or a dedicated ingestion worker must emit the enriched endpoint payload on the API version event. At minimum, the event payload for each endpoint should include:
endpointId, endpoint identity, protocol, method, path, name, and description,- logical
toolSchemagenerated from the LightAPI operation input contract, toolMetadata.routingwith namespace, domain, capability group, personas, keywords, context requirements, sensitivity tier, and semantic weight where present,toolMetadata.safetyfrom LightAPI safety, visibility, idempotency, and destructive-operation hints,- response schema or result metadata when it is available for the tool projection.
If the parser only emits the base OpenAPI or MCP fields, the catalog remains valid but only has low-enrichment metadata. The phase 2 implementation should record that as an ingestion gap, not as a persistence defect.
Portal Catalog Contract
The agent should read skills and tools through the genai-query API in
portal-query. The source spec is:
genai-query/src/main/resources/spec.yaml
The current spec already includes catalog endpoints for the main entities:
getAgentSkillandgetFreshAgentSkillgetSkillandgetFreshSkillgetSkillToolandgetFreshSkillToolgetSkillDependencyandgetFreshSkillDependencygetToolandgetFreshToolgetToolParamandgetFreshToolParam
Phase 2 should add a dedicated effective catalog endpoint instead of forcing the
agent to compose many generic query endpoints. The endpoint should still live in
genai-query, not controller-rs.
Recommended endpoint behavior:
- verify the caller’s token claims before reading catalog rows,
- require request
host_id,service_id, andenv_tag, - match token
host,sid, andenvclaims to those request values, - return only endpoint/tool projections valid for that host, service, and environment,
- include active endpoint metadata, tool schemas, safety metadata, routing metadata, and skill mappings relevant to the agent,
- support a freshness or version field so the agent can cache the result.
The agent should cache the returned structure locally:
{
"host_id": "00000000-0000-0000-0000-000000000000",
"agent_def_id": "00000000-0000-0000-0000-000000000000",
"catalog_version": 42,
"skills": [
{
"skill_id": "00000000-0000-0000-0000-000000000000",
"name": "Account Management",
"description": "Use account tools to inspect and manage customer accounts.",
"content_markdown": "Prefer read-only tools before create or update tools.",
"tools": [
{
"tool_id": "00000000-0000-0000-0000-000000000000",
"endpoint_id": "00000000-0000-0000-0000-000000000000",
"name": "getAccounts",
"endpoint": "/v1/accounts@get",
"api_type": "openapi",
"description": "List account summaries.",
"input_schema": {
"type": "object",
"properties": {}
},
"routing_metadata": {
"domain": "finance.accounts",
"semanticNamespace": "prod.accounts",
"semanticKeywords": ["account list", "customer accounts"],
"sensitivityTier": "Internal-Only"
},
"safety": {
"read_only": true,
"destructive": false
}
}
]
}
]
}
For phase 2, the agent definition identity is the agent API version identity.
agent_definition_t.agent_def_id stores the same UUID as
api_version_t.api_version_id; the table is an agent-specific profile extension
for model and runtime settings, not a second standalone agent registry. The
agent display name comes from api_t.api_name, so agent_definition_t does not
duplicate the API name. API Admin continues to own the API/API-version
lifecycle, Instance Admin continues to own deployed instances, and the Agent
Definition page edits the profile for that API version.
The previous registry skill/search response shape was:
{
"skills": [
{
"skill_id": "00000000-0000-0000-0000-000000000000",
"name": "Account Management",
"description": "Use account tools to inspect and manage customer accounts.",
"tool_name": "getAccounts",
"input_schema": {
"type": "object",
"properties": {}
}
}
]
}
That flattened shape can remain as an internal compatibility DTO while the agent is migrated, but it should not be the long-term external contract. The target cache shape should support a skill with multiple tools:
{
"skills": [
{
"skill_id": "00000000-0000-0000-0000-000000000000",
"name": "Account Management",
"description": "Use account tools to inspect and manage customer accounts.",
"content_markdown": "Prefer read-only tools before create or update tools.",
"tools": [
{
"name": "getAccounts",
"description": "List account summaries.",
"input_schema": {
"type": "object",
"properties": {}
}
}
]
}
]
}
Migration rule:
- Remove the controller-rs
skill/searchplaceholder. - The agent can temporarily accept both the flattened shape and the nested
toolsshape while its portal-query client is being migrated. - After migration, the nested effective catalog shape becomes the preferred internal cache contract.
Agent identity can come from token claims, configured agent definition, or request fields. If inference is not enough, pass explicit fields to the portal-query catalog call:
{
"agent_def_id": "00000000-0000-0000-0000-000000000000",
"host_id": "00000000-0000-0000-0000-000000000000",
"service_id": "com.networknt.account-agent-1.0.0",
"env_tag": "dev"
}
Runtime Behavior
The agent should treat the portal catalog as helpful guidance, not as a hard dependency for basic tool use.
Recommended behavior:
- At startup, call the
genai-queryAPI to load the effective agent catalog. - Cache the catalog locally under
host_id, agent identity, and catalog version. - During chat, search the local catalog with the user prompt.
- If matched skills are returned, add skill instructions to the prompt context.
- If matched skills include tool mappings, prefer those tools for the LLM tool list.
- Call gateway
tools/listto verify executable tools and obtain the current runtime schemas. - Intersect skill-selected tool names with gateway-listed tools.
- If no skills match, or the local catalog is unavailable, fall back to gateway
tools/list. - Execute all LLM tool calls through gateway
tools/call.
When portal data changes, controller cache management can invalidate the agent’s local catalog cache. Reload behavior should match the agent’s initial loading strategy:
- if the agent loads the catalog during startup, invalidation should trigger an eager reload so the next chat request sees current metadata;
- if the agent loads the catalog on the first request, invalidation can clear the cache and let the next request reload lazily.
This keeps the account-agent usable before the portal skill catalog is fully populated and avoids making controller-rs part of the catalog query or execution path.
Portal UI
Endpoint Catalog And Tool Projection
The catalog UI should be endpoint-first but still show the tool projection that agents will see. It should let operators:
- browse
api_endpoint_trows by API, API version, endpoint, method, source, and active state, - import or resync endpoint capabilities from OpenAPI, MCP
tools/list, manually pasted MCP tools payloads, LightAPI descriptions, and selected gateway runtime surfaces, - publish selected endpoint rows into
tool_tas agent-invokable tools, - generate or refresh
tool_param_trows from the logical input schema, - see tool name, description, input schema, downstream endpoint, API type, semantic namespace, domain, personas, sensitivity tier, and runtime executable state,
- compare catalog metadata against source specs and current gateway
tools/list, - mark missing endpoint projections inactive,
- override operator-facing descriptions without changing gateway config,
- review and edit semantic routing metadata such as keywords, context requirements, fallback endpoint, priority weight, read-only, destructive, sensitive, or human-approval-required.
The first implementation should not depend only on live gateway access. It can
import from the endpoint rows produced by API version parsing, including manual
MCP tools/list JSON pasted into the API version spec field. Gateway
tools/list should then be used to verify which imported projections are
currently executable by a deployed gateway.
Skill Editor
The Skill Editor should let operators:
- create and update
skill_trows, - write
content_markdowninstructions, - link tools through
skill_tool_t, - set tool access level and per-skill config,
- preview which tools the skill would expose for a sample prompt,
- optionally link the skill to one or more workflow definitions,
- activate or deactivate skills.
Skill content should be short and operational. It should describe when to use the skill, how to interpret the tools, and any sequencing rules. It should not contain secrets.
Workflow-backed Skills
Some skills are only guidance plus a curated tool set. Other skills need a
repeatable process that calls several tools, branches on results, waits for
human input, runs assertions, or leaves an audit trail. Those skills should use
light-workflow as the orchestration layer.
The boundary is:
| Layer | Responsibility |
|---|---|
| Skill | Discovery metadata, instructions, taxonomy, allowed tools, and agent guidance. |
| Workflow | Ordered execution, branching, retries, assertions, human tasks, durable state, and audit events. |
| Gateway | Runtime tool execution through tools/list and tools/call. |
Workflow-backed skills should be optional. Use a workflow when the skill represents a durable or regulated process, such as API onboarding, approval, validation, remediation, scheduled live testing, or a multi-step operation with clear checkpoints. Do not require workflow backing for simple skills that only guide an agent toward one tool call or open-ended exploration.
The workflow definition remains canonical in wf_definition_t.definition as
YAML. The skill workspace should link to the definition through
skill_workflow_t and should reuse the generic workflow editor described in
Workflow Editor. The skill workspace can constrain the
editor with skill context, but it should not implement its own workflow
runtime.
For workflow-backed skills, skill_tool_t becomes the allowed tool set. A
save-time validator should reject workflow steps that reference a gateway tool
not linked to the skill, unless the step is explicitly marked as a future or
external dependency. This keeps progressive disclosure, operator review, and
workflow execution aligned.
Recommended Skill Workspace tabs:
| Tab | Purpose |
|---|---|
| Overview | Edit name, description, Markdown instructions, active state, tags, and categories. |
| Tools | Link tools, configure skill_tool_t.config, inspect schemas, sensitivity, and gateway availability. |
| Workflow | Select or create workflow definitions, edit YAML, inspect the step outline, and link workflows through skill_workflow_t. |
| Preview | Show the effective prompt, allowed tool set, linked workflow graph, and disclosure payload. |
| Test | Start a workflow with JSON input, watch instance events, complete waiting tasks, and inspect assertions or failures. |
Agent Skill Assignment
The Agent Skill Assignment UI should let operators:
- select an agent definition,
- assign one or more active skills through
agent_skill_t, - set priority and sequence,
- preview the final skill list for that agent,
- verify that each assigned skill still has at least one executable gateway tool.
Portal-query And Agent Cache Implementation
Catalog lookup should be implemented through the genai-query API. The agent
should fetch the assigned active catalog, cache it locally, and run progressive
disclosure search against the cache.
Phase 5 implements this for the Rust light-agent only. Other agent runtimes
can adopt the same genai-query contract later, but they are not part of the
Phase 5 implementation scope.
Initial algorithm:
- Resolve
host_idfrom the agent runtime configuration and the catalog request token. Resolveagent_def_idfromLIGHT_AGENT_AGENT_DEF_IDorLIGHT_AGENT_API_VERSION_ID. Resolveservice_idandenv_tagfrom the registered Rust agent service config. - Call
genai-querygetEffectiveAgentCatalog. - The endpoint loads active
agent_skill_trows and linked activeskill_t,skill_tool_t,tool_t,tool_param_t, andskill_workflow_trows. - Build a nested effective catalog grouped by skill, with each skill carrying its mapped tools, schemas, endpoint identity, safety flags, and routing metadata.
- Cache the effective catalog locally with
catalogVersionandcatalogHash. - During chat, macro-filter cached entries by agent persona, domain, namespace, sensitivity tier, active state, and available workflow context.
- Rank cached entries by simple text matching over
skill_t.name,skill_t.description,skill_t.content_markdown,tool_t.name,tool_t.description, endpoint name, endpoint description, and semantic keywords. - Intersect the final candidate list with gateway
tools/listbefore exposing tool schemas to the LLM.
Controller cache management should invalidate this local cache when portal catalog data changes. After invalidation, the agent reloads from portal-query.
Later algorithm:
- Add vector search over
skill_t.description_embeddingandtool_t.description_embedding. - Add vector search over endpoint semantic descriptions and LightAPI capability text.
- Include skill dependency expansion from
skill_dependency_t. - Use dependency mappings and fallback endpoints for chain planning, prefetch, and failure repair.
- Include inactive or missing-tool diagnostics for portal admin views, not for normal agent search.
Gateway Implementation
The gateway should keep the MCP data-plane contract stable:
tools/listreturns the executable tool set for the caller.tools/callroutes by tool name to downstream MCP servers or REST services.- Gateway policy remains authoritative at execution time.
- Gateway does not depend on
skill_toragent_skill_tto execute tools.
The gateway can expose an administrative sync endpoint later, but the first
portal sync can call the existing MCP tools/list endpoint with an operator or
service credential.
mcp-router.tools in values.yml should stay a runtime execution projection,
not the full semantic registry. It should include the fields the gateway needs
to list and call tools, plus safety metadata that must be enforced at runtime.
Richer semantic routing metadata should stay in portal-query and the agent
cache unless the gateway needs it for a concrete runtime policy decision.
Security Rules
- Skill assignment narrows what the agent should offer to the LLM, but it does not grant runtime authorization by itself.
- Gateway access control, endpoint scopes, OAuth token claims, and downstream service authorization still decide whether a tool call is allowed.
- Tool schemas and descriptions are not trusted input. They should be validated before storing and escaped when rendered.
- Skill content must not contain secrets, tokens, private keys, or passwords.
- A stale catalog row must not make a removed gateway tool executable.
- A stale local agent cache must be intersected with gateway
tools/listbefore exposing tools to the LLM. - Controller cache invalidation only forces reload; it does not grant access to catalog rows or executable tools.
- Sensitive or destructive tool metadata should be enforced by the gateway or a policy layer, not only by prompt instructions.
- Sensitivity tier must be checked before catalog disclosure. An agent without
clearance for
Restricted-PIIshould not receive the endpoint description or schema even if a skill references it. - Context requirements are not only prompt hints. If required context is missing, the endpoint should be excluded or routed to an ask/workflow step that obtains the missing value.
Failure Handling
| Failure | Expected behavior |
|---|---|
| Portal-query catalog load fails at startup | Start with an empty catalog cache and fall back to gateway tools/list. |
| Portal-query catalog reload fails after invalidation | Keep the previous cache if available, mark it stale, retry with backoff, and still verify tools through gateway tools/list. |
Gateway tools/list fails | Continue chat without tools or return a clear tool-unavailable response. |
| Skill references missing tool | Omit the missing tool from the runtime tool list and surface drift in portal admin UI. |
Gateway rejects tools/call | Return the tool error to the LLM loop and log the gateway response. |
| Catalog sync sees changed schema | Update catalog schema, mark the tool as changed, and preserve operator metadata. |
| LightAPI enrichment conflicts with source spec | Preserve the source invocation contract, mark the semantic metadata conflict for review, and do not overwrite operator overrides. |
Phased Implementation
Phase 1: Preserve Direct MCP Baseline
- Keep agent tool execution through gateway
tools/call. - Remove the controller-rs
skill/searchplaceholder before it becomes a dependency. - Ensure agent falls back to gateway
tools/listwhen no catalog cache is available. - Keep direct gateway
tools/listandtools/callworking without portal skills.
Phase 2: API Endpoint Catalog Sync
- Add portal UI for endpoint-first import and resync.
- Use existing API version parsing to populate
api_endpoint_tfor OpenAPI and MCP tools, including manual MCPtools/listpayloads accepted in the API version spec field. - Sync all endpoint rows for the API version into the endpoint catalog. Do not limit the catalog to the endpoints currently selected for one gateway instance.
- Import or refresh LightAPI Description metadata for endpoint enrichment.
- Publish selected endpoint rows into
tool_tas agent-facing tool projections. - Generate
tool_param_tfrom each endpoint’s logical input schema. - Link every API-origin tool projection back to
api_endpoint_t.endpoint_id. - Store semantic routing metadata in indexed endpoint/tool fields and preserve
the full metadata payload in
api_endpoint_t.tool_metadata. - If the first code slice only writes
tool_metadata, keep that as a compatibility step and add the indexed routing-column migration before database-side macro-filtering or production vector ranking is enabled. - Let users select which endpoint projections should be exposed to a specific gateway instance. This deployment selection is separate from endpoint catalog sync.
- Verify runtime executability outside persistence with gateway
tools/listfor the selected gateway instance when a gateway is reachable. - Mark disappeared or non-executable projections inactive instead of deleting them.
- Add drift indicators for schema, description, safety metadata, and semantic routing metadata changes.
Phase 3: Skill Authoring
- Keep the existing
skill_tCRUD page as the phase 3 authoring surface. - Add skill-scoped category and tag assignment to the create/update skill
forms. The UI should use dropdowns populated from the existing portal
taxonomy where
entity_type = 'skill'. - Persist skill categories through
entity_category_tand skill tags throughentity_tag_t; do not addtagsorcategoriescolumns toskill_t. - Implement skill save as a composite command: one event updates the skill row and one taxonomy event replaces the selected category/tag associations for the same skill.
- Keep
content_markdownas the instruction body. YAML or JSON skill files are import/export envelopes; if full structured skill authoring is introduced later, add a nullable JSONB skill-spec column besidecontent_markdowninstead of replacing it. - Keep embeddings optional.
Phase 3.5: Skill Workspace And Structured Authoring
- Add a richer Skill Workspace with Overview, Tools, Workflow, Preview, and Test tabs.
- Add tool linking workflows for
skill_tool_tand formalizeskill_tool_t.configfor per-skill tool overrides. - Add workflow-backed skill support through
skill_workflow_t, withwf_definition_t.definitionkept as the canonical workflow YAML. - Reuse the generic Workflow Editor in the Workflow tab for YAML editing, step preview, validation, and test runs.
- Add validation that workflow tool-call steps reference tools linked to the
skill through
skill_tool_t. - Add “create skill from LightAPI/tool” flows that can generate a draft skill, link relevant tools, and optionally create a starter workflow definition.
- Add YAML/JSON import/export for structured skill documents. Normalize YAML to
JSON for storage when a persisted structured payload is needed, while keeping
Markdown instructions in
content_markdown.
Phase 4: Agent Assignment
- Add portal UI for
agent_skill_t. - Let operators assign active skills to agent definitions.
- Add an Agent Definition assignment entry point in addition to the existing
agent_skill_ttable page, so operators can manage assigned skills from the agent context. - Add a batch assignment composite command that emits one
AgentSkillCreatedEventper selected skill. - Add validation that assigned skills have at least one active direct
skill_tool_tlink. A workflow-backed skill does not satisfy this by having onlyskill_workflow_t; the workflow must use the skill’s linked tools. - Enforce assignment validation in command handlers and mirror the same checks as UI preflight feedback.
- Treat
sequence_idas the deterministic effective prompt/display order andpriorityas a ranking weight for later catalog/search behavior.
Phase 5: Real Skill Search
- Add the dedicated
genai-querygetEffectiveAgentCatalogendpoint with token verification againsthost,sid, andenvclaims. - The endpoint returns the active nested catalog for one
hostId + agentDefId + serviceId + envTag: agent metadata, assigned skills, tags, categories, skill config, mapped tools, tool params, routing/safety fields, workflow references,catalogVersion, andcatalogHash. - Implement the Rust
light-agentportal-query client using that endpoint. - Build and cache the nested effective catalog inside the Rust agent.
- Start with local macro-filtering and keyword matching over cached skills, endpoint metadata, and tool projections.
- Intersect selected catalog tool names with gateway
tools/list; execute only through gatewaytools/call. - Wire controller cache-management invalidation to clear the Rust agent catalog cache. The next chat request lazily reloads from portal-query.
- If portal-query is unavailable or no agent definition ID is configured, the
Rust agent falls back to direct gateway
tools/listwithout portal catalog filtering. - Add vector ranking after 384-dimensional embeddings are populated and combine
it with
semanticWeight.
Phase 6: Semantic Routing And Governance
- Support the Rust
light-agentonly. Other agent runtimes can adopt the same catalog and diagnostics contracts later. - Use the normalized sensitivity tiers
public,internal,confidential, andrestricted. Treat missing or unknown tool tiers asinternal. - Enforce sensitivity-tier disclosure before portal-query returns the effective
catalog to the agent. Tools blocked by policy are omitted from the returned
toolslist and surfaced as diagnostics for admin review. - Block destructive or approval-required tools unless the skill/tool policy
names an approval workflow. Until workflow-owned approval state exists, the
current
activerow plus aggregate version remains the catalog versioning authority. - Keep gateway
tools/listandtools/callas the runtime source of truth. The Rust agent must still intersect catalog-selected tools with live gatewaytools/list. - Add Rust-agent diagnostics that compare the effective catalog against gateway
tools/listat/diagnostics/tools, showing catalog tools missing from the gateway, gateway tools outside the catalog, and policy-blocked catalog tools. - Enforce the same destructive, approval-required, and sensitivity metadata at
the gateway before
tools/callexecution. A blocked call should includeauditInfofields and gateway debug/warn logs with the tool name, endpoint, tier, policy reason, and approval state. - Do not write catalog-disclosure audit records into
audit_log_t; it is reserved for workflow. Phase 6 usesauditInfoso the existing audit log file path captures blocked gateway decisions. A generic audit table can be added in a later governance phase if file logging is not enough.
Resolved Phase 2 Decisions
- Phase 2 endpoint catalog sync covers all endpoint rows for an API version. Gateway exposure is a separate step where users select which endpoint/tool projections to deploy to a specific gateway instance.
- Runtime verification means checking the selected gateway instance’s
tools/listresponse to confirm that a deployed endpoint projection is executable there. It is not the same as endpoint catalog sync and should be implemented in the portal UI, deployment review flow, or diagnostics layer, not inside the persistence projection. - Gateway exposure identity is
hostId + serviceId + envTag. The token used for portal APIs must carry matchinghost,sid, andenvclaims. tool_t.implementation_typeshould be standardized and aligned with the LightAPI Description execution model. Endpoint-backed tools should use the standardized endpoint implementation type, with downstream protocol stored in endpoint and LightAPI metadata.- High-use semantic routing fields should be indexed columns or indexed
relationships, with the full structured payload preserved in
api_endpoint_t.tool_metadata. JSON-only persistence is only an interim import/export-compatible shape for small catalogs or local-cache search. - LightAPI Description enrichment requires an upstream parser or ingestion
worker to emit enriched endpoint payloads. The persistence layer can store
tool_schema,tool_metadata.routing, andtool_metadata.safety, but it does not derive those fields from the raw LightAPI document by itself. - Endpoint category and tag classification should reuse the existing portal tag and category system.
- Embeddings should start at 384 dimensions to match the current
VECTOR(384)schema. Use a provider abstraction so hosted OpenAI embeddings or local embedding services can be swapped without changing the catalog schema. genai-queryshould expose a dedicated effective catalog endpoint. Its token verification must match requesthost_id,service_id, andenv_tagagainst tokenhost,sid, andenvclaims.- Cache reload behavior depends on the loading strategy. Startup-loaded catalogs should eagerly reload after invalidation. First-request-loaded catalogs can reload lazily on the next request.
- Phase 2 focuses on tool and endpoint metadata. Skill-specific metadata and per-skill tool config should be designed later with the skill authoring phase.
- Phase 3 uses the existing taxonomy join tables for skill tags and
categories. Skill files may be YAML or JSON, but the database should keep
content_markdownfor the instruction body; a structured JSONB skill-spec column belongs in a later full authoring/import phase if it becomes needed.
Resolved Phase 3.5 Decisions
- Use
light-workflowfor workflow-backed skills that need durable multi-tool orchestration, approvals, assertions, retries, scheduled tests, or audit history. - Do not force every skill into a workflow. Skills remain the discovery and guidance layer, and simple skills can stay instruction-and-tool based.
- Keep
light-gatewayas the runtime tool execution path. Workflow tasks that call tools should still use gateway-visible tool identities and should not bypass gateway policy. - Keep workflow definitions in
wf_definition_t.definitionas YAML. Link skills to workflow definitions throughskill_workflow_tinstead of embedding workflow definitions inskill_t. - Treat
skill_tool_tas the allowed tool set for workflow-backed skills. Save-time validation should flag workflow tool calls that are not linked to the skill. - Build the workflow authoring UI as a generic reusable editor first, then embed it inside the Skill Workspace with skill-aware reference filtering and validation.
Resolved Phase 4 Decisions
- An assignable skill must be active and must have at least one active direct
tool link through
skill_tool_t. Activeskill_workflow_trows are useful orchestration metadata, but they do not replace the direct allowed-tool set. - Workflow-backed skill assignment should also rely on the Phase 3.5 validator:
workflow tool-call references must resolve to tools linked through
skill_tool_t. - Validation must be enforced server-side by
createAgentSkill,updateAgentSkill, and the batch assignment composite command. The Portal UI should run the same checks as preflight feedback, but UI checks are not authoritative. - Keep the existing
AgentSkilltable page and add an Agent Definition assignment context so operators can assign and inspect skills from the agent they are configuring. - Batch assignment should be a composite command that creates multiple
AgentSkillCreatedEventevents from one request. sequence_idcontrols deterministic ordering when building the agent’s effective skill prompt/catalog.priorityis reserved as a ranking weight for later effective-catalog and search behavior.- Live gateway runtime executability checks are not part of Phase 4
persistence validation. Keep them as a diagnostics or governance item that
compares cataloged/assigned tools with the selected gateway instance’s
tools/listresponse before deployment or runtime enablement.
Recommendation
Implement this as a progressive control-plane enhancement. The gateway remains
the execution path, and portal-authored skills become the agent guidance layer
served by portal-query. The agent should cache the effective catalog locally and
reload it after controller cache-management invalidation. This lets MCP tools
work immediately through tools/list and tools/call, while still giving
portal operators a clean path to organize tools into skills, assign those
skills to agents, and improve retrieval over time.
Agent API Compose And Multi-Agent Workflow
Problem
portal-config-loc and portal-config-dev are being updated so local Docker
Compose stacks can run light-agent beside the portal services, demo APIs, and
gateway. The first implementation adds one light-agent directly to the main
compose file and points the gateway direct registry at http://light-agent:8083.
That works for a single account agent, but it does not scale cleanly for the next phase:
- the base portal stack should remain usable without demo APIs or agents,
- demo APIs and agents should be startable as an optional local package,
- all services must still share the same Docker network,
- multiple
light-agentinstances need unique runtime identities, - each agent needs a different effective skill/tool/workflow catalog,
- workflows need to orchestrate API access across multiple specialized agents.
The design goal is to split deployment concerns without splitting the runtime network or the control-plane model.
Goals
- Move the two demo APIs and local
light-agentservices into a separate Docker Compose overlay file. - Keep the overlay on the same Docker network as the portal stack, gateway, controller, config-server, Postgres, and hybrid services.
- Support multiple
light-agentcontainers from the same image with different service ids, advertised addresses, ports, model settings, agent definitions, skills, tools, and workflows. - Keep
light-gatewayas the MCP runtime path fortools/listandtools/call. - Keep portal-query as the source for the effective agent catalog.
- Use
skill_workflow_tandwf_definition_tto connect skills to executable workflows. - Use
light-workflowfor deterministic orchestration, retries, human tasks, assertions, audit, and multi-agent coordination.
Non-Goals
- Do not move the demo APIs or agent services into a different Compose project by default.
- Do not create a second Docker network for the demo APIs and agents.
- Do not make one agent container host multiple unrelated agent definitions.
- Do not move MCP tool execution into controller-rs or portal-query.
- Do not require every gateway tool to be wrapped by a skill before baseline gateway tool execution works.
- Do not store workflow definitions inside
skill_t.
Compose File Split
Use the main compose files for platform services and a separate overlay for demo APIs plus agents.
Recommended files:
| Repo | Base files | Agent/API overlay |
|---|---|---|
portal-config-dev | docker-compose.yml | docker-compose.agent-api.yml |
portal-config-loc/all-in-pg | docker-compose.yml, docker-compose-rust.yml | docker-compose.agent-api.yml |
portal-config-loc/all-in-lt | docker-compose.yml, docker-compose-rust.yml | docker-compose.agent-api.yml |
The base stack should own shared infrastructure:
- Postgres,
- config-server,
- controller,
- hybrid-query,
- hybrid-command,
- light-gateway,
- light-workflow,
- OAuth and other platform services.
The overlay should own optional local workloads:
demo-customer-profile-api,demo-offer-decision-api,light-agent-account,light-agent-offer,- future specialized agents.
The overlay is intended to be started with the base files in the same Compose command. In that mode Docker Compose creates or reuses one project default network, and every service can resolve every other service by service name.
Example for portal-config-dev:
docker compose \
-f docker-compose.yml \
-f docker-compose.agent-api.yml \
up -d
Example for portal-config-loc/all-in-pg:
docker compose \
-f docker-compose.yml \
-f docker-compose-rust.yml \
-f docker-compose.agent-api.yml \
up -d
If the overlay must be started separately, it must still use the same Compose project name as the base stack. Otherwise Docker will create a second default network and the gateway will not resolve the agent and demo API service names.
Network Contract
The preferred local contract is the Compose default network for the active project. Do not declare a separate network in the overlay when the overlay is run with the base stack.
Service-to-service URLs should use Compose service DNS names:
http://light-agent-account:8083
http://light-agent-offer:8083
http://demo-customer-profile-api:8080
http://demo-offer-decision-api:8080
Host port mappings are only for browser or curl access from the developer machine. They should not be used by gateway, agents, workflows, or demo APIs to call each other.
For agent containers, use a stable service name and advertised address:
server.advertisedAddress: ${LIGHT_AGENT_ADVERTISED_ADDRESS:light-agent-account}
server.httpPort: ${LIGHT_AGENT_HTTP_PORT:8083}
The internal port can stay 8083 for every agent because each agent is a
different container. Only host-published ports must be unique.
Agent Service Identity
Each agent instance needs a unique runtime identity. The identity is not just the Docker service name.
Recommended identity fields:
| Field | Purpose | Example |
|---|---|---|
| Compose service | Docker DNS name and local lifecycle unit. | light-agent-account |
server.serviceId | Runtime service id registered with controller and gateway. | com.networknt.agent.account-1.0.0 |
server.environment | Runtime environment tag. | dev |
server.advertisedAddress | Address other services use for this agent. | light-agent-account |
LIGHT_AGENT_HOST_ID | Host or tenant boundary for portal catalog and memory. | 01964b05-552a-7c4b-9184-6857e7f3dc5f |
LIGHT_AGENT_AGENT_DEF_ID | Agent definition id, currently aligned with API version id. | account agent API version id |
| Model provider config | Runtime model settings for the agent instance. | codex, gpt-5.5 |
The same image can run multiple agents. Compose injects different environment variables and config-server startup values into each service.
Example overlay shape:
services:
light-agent-account:
image: ${LIGHT_AGENT_IMAGE:-networknt/light-agent:latest}
ports:
- ${ACCOUNT_AGENT_PORT:-8083}:8083
volumes:
- ./light-agent-rust/config:/config:ro
- ./light-controller-rust/ca.pem:/keystore/ca.pem:ro
environment:
LIGHT_RS_CONFIG_DIR: /config
DATABASE_URL: postgres://postgres:secret@postgres:5432/configserver
LIGHT_PORTAL_AUTHORIZATION: "${LIGHT_AGENT_LIGHT_PORTAL_AUTHORIZATION:-}"
LIGHT_AGENT_HOST_ID: "${LIGHT_AGENT_HOST_ID:-01964b05-552a-7c4b-9184-6857e7f3dc5f}"
LIGHT_AGENT_AGENT_DEF_ID: "${ACCOUNT_AGENT_DEF_ID:-}"
LIGHT_AGENT_SERVICE_ID: com.networknt.agent.account-1.0.0
LIGHT_AGENT_ADVERTISED_ADDRESS: light-agent-account
LIGHT_AGENT_MODEL: "${ACCOUNT_AGENT_MODEL:-gpt-5.5}"
CODEX_API_KEY: "${ACCOUNT_AGENT_CODEX_API_KEY:-}"
CODEX_ACCOUNT_ID: "${ACCOUNT_AGENT_CODEX_ACCOUNT_ID:-}"
CODEX_REASONING_EFFORT: "${ACCOUNT_AGENT_CODEX_REASONING_EFFORT:-low}"
RUST_LOG: "${ACCOUNT_AGENT_RUST_LOG:-info}"
AGENT_LOG_ANSI: "false"
light-agent-offer:
image: ${LIGHT_AGENT_IMAGE:-networknt/light-agent:latest}
ports:
- ${OFFER_AGENT_PORT:-8084}:8083
volumes:
- ./light-agent-rust/config:/config:ro
- ./light-controller-rust/ca.pem:/keystore/ca.pem:ro
environment:
LIGHT_RS_CONFIG_DIR: /config
DATABASE_URL: postgres://postgres:secret@postgres:5432/configserver
LIGHT_PORTAL_AUTHORIZATION: "${LIGHT_AGENT_LIGHT_PORTAL_AUTHORIZATION:-}"
LIGHT_AGENT_HOST_ID: "${LIGHT_AGENT_HOST_ID:-01964b05-552a-7c4b-9184-6857e7f3dc5f}"
LIGHT_AGENT_AGENT_DEF_ID: "${OFFER_AGENT_DEF_ID:-}"
LIGHT_AGENT_SERVICE_ID: com.networknt.agent.offer-1.0.0
LIGHT_AGENT_ADVERTISED_ADDRESS: light-agent-offer
LIGHT_AGENT_MODEL: "${OFFER_AGENT_MODEL:-gpt-5.5}"
CODEX_API_KEY: "${OFFER_AGENT_CODEX_API_KEY:-}"
CODEX_ACCOUNT_ID: "${OFFER_AGENT_CODEX_ACCOUNT_ID:-}"
CODEX_REASONING_EFFORT: "${OFFER_AGENT_CODEX_REASONING_EFFORT:-low}"
RUST_LOG: "${OFFER_AGENT_RUST_LOG:-info}"
AGENT_LOG_ANSI: "false"
The example deliberately avoids container_name. Compose service names already
provide stable DNS on the project network, and omitting container_name avoids
cross-project name collisions.
Gateway Registry
The gateway should route to agent services through Docker DNS names, not host addresses. For the local direct registry:
direct-registry.directUrls:
com.networknt.agent.account-1.0.0: http://light-agent-account:8083
com.networknt.agent.offer-1.0.0: http://light-agent-offer:8083
The same rule applies to demo APIs. Gateway route targets should be service names on the shared Compose network.
When an agent is registered through controller, its runtime identity should match the config-server tuple used by the container:
host + serviceId + envTag
The agent should keep server.enableRegistry: true so controller can discover
it and send catalog cache invalidation notifications.
Effective Agent Catalog
Each agent loads its effective catalog from portal-query with:
hostId + agentDefId + serviceId + envTag
The effective catalog includes:
- the agent definition,
- assigned skills from
agent_skill_t, - tool projections from
skill_tool_tandtool_t, - tool parameters from
tool_param_t, - workflow mappings from
skill_workflow_t, - workflow definitions from
wf_definition_t, - policy diagnostics for tools that should not be exposed.
The agent caches the effective catalog locally. Controller cache-management messages should clear that cache when skills, tools, workflows, or assignments change. On the next chat turn, the agent refreshes the catalog from portal-query.
Gateway execution stays separate from catalog reads:
portal-query
-> effective catalog, skills, tools, workflows, policies
light-gateway
-> tools/list
-> tools/call
If portal-query is temporarily unavailable, the direct gateway tool list can
remain usable for baseline tool execution. If a tool is in the catalog but is
not returned by gateway tools/list, the agent must not execute it.
Capability Model
Agents should be specialized by catalog assignment rather than by image build.
Recommended specialization:
| Agent | Service id | Skills | Typical tools | Workflows |
|---|---|---|---|---|
| Account agent | com.networknt.agent.account-1.0.0 | Account lookup, profile enrichment | customer profile API tools | profile lookup, profile validation |
| Offer agent | com.networknt.agent.offer-1.0.0 | Offer eligibility, decision explanation | offer decision API tools | offer decision, approval check |
| Advisor agent | com.networknt.agent.advisor-1.0.0 | Cross-domain recommendation | account and offer read tools | customer advisory orchestration |
| Coordinator agent | com.networknt.agent.coordinator-1.0.0 | Routing and task planning | agent invocation tools, workflow tools | multi-agent workflow start |
The capability boundary is the effective catalog:
agent_skill_tassigns skills to the agent,skill_tool_tcontrols which tools a skill can expose,skill_workflow_tcontrols which workflows a skill can start or reference,- workflow and gateway policy still enforce runtime access.
This keeps the runtime image generic while making each agent instance purpose-built.
Workflow Orchestration
light-workflow should orchestrate multi-step API and agent flows. Agents
provide reasoning and tool selection inside their assigned domain, while
workflow provides deterministic control flow.
Recommended orchestration responsibilities:
| Component | Responsibility |
|---|---|
| Portal | Author skills, tools, workflow mappings, and agent assignments. |
| portal-query | Serve the effective catalog to each agent. |
| controller | Register agents and invalidate agent catalog caches. |
| light-gateway | Execute MCP tools and route API calls. |
| light-agent | Reason over assigned skills and call allowed gateway tools. |
| light-workflow | Run multi-agent plans, API sequences, assertions, retries, and human tasks. |
Example advisory flow:
- A user starts an advisory request.
- The coordinator agent or portal UI starts a workflow in
light-workflow. - The workflow calls the account agent with the
customer-profileskill. - The account agent reads its effective catalog and calls customer profile
tools through
light-gateway. - The workflow validates the profile response with an
asserttask. - The workflow calls the offer agent with the
offer-decisionskill. - The offer agent calls offer decision tools through
light-gateway. - The workflow applies policy checks, optional human approval, and final response shaping.
The workflow is the durable orchestration record. Agent chat history and memory can support reasoning, but they should not be the only source of orchestration state.
Skill To Workflow Mapping
Use skill_workflow_t to link a skill to one or more workflow definitions:
| Column | Use |
|---|---|
host_id | Tenant boundary. |
skill_id | Skill that can use the workflow. |
wf_def_id | Workflow definition in wf_definition_t. |
workflow_role | primary, validation, remediation, approval, or test. |
start_mode | manual, agent, portal, or scheduled. |
config | Skill-specific workflow input defaults and safety hints. |
active | Publication flag. |
The effective catalog should include these mappings so the agent can decide whether a user request should be answered directly, routed to a tool, or handed to a workflow.
For destructive or externally visible operations, the skill should prefer a workflow mapping over direct tool execution. The workflow can add approval, assertions, idempotency keys, retries, and audit events.
API Access Pattern
Agents should not call downstream business APIs directly. They should use the gateway data plane:
light-agent
-> light-gateway /mcp tools/list
-> light-gateway /mcp tools/call
-> downstream MCP server or REST/OpenAPI-backed tool
Workflows should also use gateway-backed calls when invoking API operations:
do:
- get-profile:
call: mcp
with:
session: gateway
tool: customer_profile_get
arguments:
customerId: "${ .customerId }"
When workflow needs reasoning, it should call an agent task:
do:
- review-offer:
call: agent
with:
agent: com.networknt.agent.offer-1.0.0
skill: offer-decision
input:
customerId: "${ .customerId }"
profile: "${ .profile }"
The exact agent invocation transport can evolve, but the logical contract is stable: workflow names the agent and skill, and the called agent uses its effective catalog to constrain tools and workflow options.
Local Configuration Layout
Use one shared config template when agents differ only by environment variables:
light-agent-rust/
config/
startup.yml
client.yml
values.yml
Use per-agent config folders only when the bootstrap or runtime config needs to diverge beyond service id, advertised address, model, or agent definition:
light-agent-rust/
account/config/
offer/config/
advisor/config/
The recommended first phase is the shared template plus per-service Compose environment overrides. This avoids copying the same config files for every agent.
Keep secrets outside git:
- portal bearer token,
- provider API keys,
- provider account ids,
- customer CA material,
- database credentials outside local defaults.
Rollout Plan
Phase 1: Compose Overlay
- Add
docker-compose.agent-api.ymlbeside the current base compose files. - Move demo APIs and local
light-agentservices into the overlay. - Rename the first agent service to
light-agent-account. - Remove
container_namefrom agent services. - Update gateway direct registry entries to service DNS names.
- Verify the rendered compose model with the base and overlay files together.
Phase 2: Multiple Agent Instances
- Add one overlay service per specialized agent.
- Assign unique service ids and host ports.
- Add portal agent definitions for each service id and env tag.
- Assign skills through
agent_skill_t. - Assign tools through
skill_tool_t. - Assign workflows through
skill_workflow_t. - Verify each agent can load a distinct effective catalog.
Phase 3: Workflow Orchestration
- Create workflow definitions for cross-agent API access.
- Add workflow mappings to skills.
- Let coordinator or portal UI start workflows for multi-step tasks.
- Use gateway MCP calls for API operations.
- Use agent tasks only where domain reasoning is required.
- Add policy checks for destructive tools and approval-required workflows.
Phase 4: Operational Hardening
- Add health checks for every agent and demo API.
- Add startup validation that each agent has a non-empty effective catalog when
LIGHT_AGENT_AGENT_DEF_IDis configured. - Add gateway drift diagnostics comparing catalog tools with gateway
tools/list. - Add cache invalidation verification after skill, tool, or workflow changes.
- Add docs for common local run commands and expected service URLs.
Design Decisions
- Overlay Scope: The first overlay will include both the account and offer agents, together with the two demo APIs.
- Port Publishing: Every agent will publish its own UI port and register with the control plane independently. Chat clients will discover agents via controller registration, and
light-gatewaywill discover them via explicitdirect-registryentries. - Workflow Triggers: Workflow start requests will go through a dedicated workflow command API for the first implementation.
- Agent Orchestration: Agent-to-agent calls will not be exposed as direct gateway tools. Multi-agent flows are orchestrated exclusively via
light-workflow. Currently,call: agenttasks are native, catalog-backed model calls executed directly by the workflow engine (bypassing the containerizedlight-agenttool loops). The containerized agents are primarily used by chat clients. Future implementations may choose to invoke the containerized agent services from workflow.
Agent Memory Event Refactor
Problem
GlobalSnapshotPersistenceImpl currently skips these Hindsight memory tables
for both snapshot export and snapshot-to-event conversion:
agent_memory_bank_t
agent_memory_doc_t
agent_memory_unit_t
agent_memory_entity_t
agent_memory_unit_entity_t
agent_memory_entity_cooccur_t
agent_memory_link_t
agent_memory_directive_t
agent_memory_reflection_t
agent_session_history_t
The skip is intentional for the current implementation. These tables are not
currently populated from portal events as the source of truth. They are runtime
state written directly by light-agent or memory client code, so exporting them
as portable portal domain state or converting them into generic created events
would be unsafe.
The current implementation also has a schema drift risk:
light-agentwrites directly to the current Hindsight tables:agent_memory_bank_t,agent_session_history_t, andagent_memory_unit_t.light-fabric/crates/hindsight-clientwrites directly toagent_memory_unit_t.light-portalJava db-provider has event replay methods forAgentSessionHistoryandAgentMemory, but those methods do not cover the current Hindsight table family.AgentMemorywritesagent_memory_t, andAgentSessionHistoryexpects the oldersession_history_id,process_id,role, andcontentshape rather than the current(host_id, bank_id, session_id, messages)schema.- The Rust importer also skips the same
agent_memory_*andagent_session_history_ttables, so the Java and Rust conversion paths are aligned around the current non-event-backed behavior.
Goal
Refactor the agent memory persistence path so that memory state has a clear owner:
command/event path -> event_store_t -> db-provider replay -> Hindsight tables
Once that contract is in place, snapshot export and conversion can safely include the event-backed memory state where appropriate.
Non-Goals
- Do not promote existing direct-write memory rows into snapshots before a backfill/migration event strategy exists.
- Do not convert derived caches into authoritative state unless a product decision requires exact cache promotion.
- Do not require every chat token or partial model response to become an event.
- Do not remove the current direct PostgreSQL path until
light-agenthas a stable command-backed memory store and operational validation.
Current State
Snapshot Export And Conversion
GlobalSnapshotPersistenceImpl excludes the memory tables from export and
conversion. This prevents two bad outcomes:
- exporting user/session memory into another environment without an explicit promotion contract
- converting rows into events that no replay handler can faithfully apply
The Rust importer has the same conversion skip list. Any future change must update both Java and Rust paths.
light-agent
light-agent currently owns some memory writes directly:
ensure_session_memory_bank
INSERT INTO agent_memory_bank_t
session history persistence
INSERT INTO agent_session_history_t ... ON CONFLICT DO UPDATE
hindsight retain
INSERT INTO agent_memory_unit_t
This is operationally simple and gives the agent read-your-writes behavior, but it bypasses portal command validation, event persistence, replay, and snapshot conversion.
Java db-provider
The Java db-provider already has event handler plumbing for many GenAI tables. For memory, however, the existing methods are not aligned with the Hindsight schema:
AgentMemoryCreatedEvent -> agent_memory_t
AgentSessionHistoryCreatedEvent -> old session-history row shape
There are no current event handlers for:
agent_memory_bank_t
agent_memory_doc_t
agent_memory_unit_t
agent_memory_entity_t
agent_memory_unit_entity_t
agent_memory_entity_cooccur_t
agent_memory_link_t
agent_memory_directive_t
agent_memory_reflection_t
Recommended Design
Use events for durable memory state, and treat pure caches as rebuildable projection state.
Recommended ownership:
| Table | Ownership |
|---|---|
agent_memory_bank_t | Event-backed aggregate |
agent_memory_doc_t | Event-backed aggregate |
agent_memory_unit_t | Event-backed aggregate |
agent_memory_entity_t | Event-backed aggregate |
agent_memory_unit_entity_t | Event-backed association |
agent_memory_link_t | Event-backed association |
agent_memory_directive_t | Event-backed aggregate |
agent_memory_reflection_t | Event-backed aggregate |
agent_session_history_t | Event-backed aggregate or explicit operational table |
agent_memory_entity_cooccur_t | Derived projection cache by default |
agent_memory_entity_cooccur_t should stay projection-owned unless exact
co-occurrence counts are considered business state. It can be rebuilt from
memory units and unit-entity links during replay.
agent_session_history_t needs an explicit decision. It contains conversation
content and may be high volume. The recommended first phase is to make it
event-backed for correctness, but keep snapshot export opt-in because it can
contain sensitive user text.
Event Model
Add explicit event constants and aggregate constants for the Hindsight schema. Use aggregate ids that include enough context to avoid cross-bank collisions.
Suggested aggregate ids:
AgentMemoryBank: hostId|bankId
AgentMemoryDoc: hostId|bankId|docId
AgentMemoryUnit: hostId|bankId|unitId
AgentMemoryEntity: hostId|bankId|entityId
AgentMemoryUnitEntity: hostId|bankId|unitId|entityId
AgentMemoryLink: hostId|bankId|fromUnitId|toUnitId|linkType
AgentMemoryDirective: hostId|bankId|directiveId
AgentMemoryReflection: hostId|bankId|reflectionId
AgentSessionHistory: hostId|bankId|sessionId
Suggested events:
AgentMemoryBankCreatedEvent
AgentMemoryBankUpdatedEvent
AgentMemoryBankDeletedEvent
AgentMemoryDocCreatedEvent
AgentMemoryDocUpdatedEvent
AgentMemoryDocDeletedEvent
AgentMemoryUnitRetainedEvent
AgentMemoryUnitUpdatedEvent
AgentMemoryUnitDeletedEvent
AgentMemoryEntityCreatedEvent
AgentMemoryEntityUpdatedEvent
AgentMemoryEntityDeletedEvent
AgentMemoryUnitEntityLinkedEvent
AgentMemoryUnitEntityUnlinkedEvent
AgentMemoryLinkCreatedEvent
AgentMemoryLinkUpdatedEvent
AgentMemoryLinkDeletedEvent
AgentMemoryDirectiveCreatedEvent
AgentMemoryDirectiveUpdatedEvent
AgentMemoryDirectiveDeletedEvent
AgentMemoryReflectionCreatedEvent
AgentMemoryReflectionUpdatedEvent
AgentMemoryReflectionDeletedEvent
AgentSessionHistoryCreatedEvent
AgentSessionHistoryAppendedEvent
AgentSessionHistoryCompactedEvent
AgentSessionHistoryDeletedEvent
Do not reuse the current AgentMemoryCreatedEvent name for
agent_memory_unit_t. That name already maps to legacy agent_memory_t and
would create ambiguity. Either deprecate the legacy event family or keep it
separate with a clear LegacyAgentMemory name in documentation and tests.
For session history, avoid Upserted as the long-term event name. The
underlying table may use INSERT ... ON CONFLICT DO UPDATE, but the event log
should express intent. Use AgentSessionHistoryCreatedEvent to start a
session, AgentSessionHistoryAppendedEvent to add one or more messages, and
AgentSessionHistoryCompactedEvent only when the retained JSON history is
summarized or truncated.
db-provider Refactor
Add a dedicated Hindsight persistence component, for example:
HindsightMemoryPersistence
HindsightMemoryPersistenceImpl
Responsibilities:
- replay Hindsight memory events into the current tables
- preserve
aggregate_versionordering on every mutable table - handle
JSONB,vector(384), andUUID[]fields explicitly - maintain foreign-key order during replay
- rebuild or incrementally update derived
agent_memory_entity_cooccur_t
Update:
PortalConstants
EventTypeUtil
PortalDbProvider.handleEvent
PortalDbProviderImpl
GlobalSnapshotPersistenceImpl table-to-event overrides
GlobalSnapshotPersistenceImpl skip lists
importer/src/snapshot/table_rules.rs
The replay order must satisfy foreign keys:
agent_memory_bank_t
agent_memory_doc_t
agent_memory_unit_t
agent_memory_entity_t
agent_memory_unit_entity_t
agent_memory_link_t
agent_memory_directive_t
agent_memory_reflection_t
agent_session_history_t
If agent_memory_entity_cooccur_t remains derived, rebuild it after replay or
update it from AgentMemoryUnitEntityLinkedEvent.
light-agent Refactor
Introduce a memory persistence abstraction:
MemoryStore
DirectPgMemoryStore
PortalCommandMemoryStore
DirectPgMemoryStore preserves the current local behavior during migration. It
should be marked as a local/runtime compatibility mode and should not be
considered portable event state.
PortalCommandMemoryStore should be the enterprise/default target once the
command path is stable. It sends memory commands through the portal command API
using the agent’s service token. This gives memory writes the same validation,
event persistence, replay, and audit behavior as the rest of the portal.
Configuration:
memory:
writeMode: portal-command # portal-command | direct-pg
retainSessionHistory: true
exportableMemory: false
Initial implementation uses environment variables in light-agent:
LIGHT_AGENT_MEMORY_WRITE_MODE=portal-command # portal-command | direct-pg
LIGHT_AGENT_PORTAL_COMMAND_URL=https://... # optional; defaults from portal config
exportableMemory should default to false until privacy and environment
promotion rules are finalized.
DirectPgMemoryStore should be phased out after PortalCommandMemoryStore is
stable. Keeping two permanent write paths would reintroduce schema drift and
make local development behave differently from production.
Read-Your-Writes
The agent currently reads directly from PostgreSQL after direct writes. Moving
writes behind command/event processing creates a read-your-writes requirement.
For Phase 1, the command endpoint should apply the projection synchronously
before returning. This keeps light-agent simple and avoids session-local
buffer race conditions.
Other options can be evaluated later if latency requires them:
- agent keeps a small session-local memory buffer until replay catches up
- agent reads through a query endpoint that can merge persisted memory with the session-local buffer
Snapshot Policy
After the event-backed path is implemented:
- Remove event-backed Hindsight tables from
CONVERSION_SKIP_TABLES. - Keep export opt-in for memory tables because they may contain private user content.
- Keep
agent_memory_entity_cooccur_tskipped if it remains derived. - Add explicit table-to-event overrides for each event-backed Hindsight table.
- Keep Java
GlobalSnapshotPersistenceImpland Rust importer skip lists in sync.
Suggested export behavior:
default snapshot export: skip memory content
entityTypes=agent_memory: include event-backed memory tables
entityTypes=agent_session_history: include session history only when explicitly requested
Production session history export should be blocked by default even when the entity type is requested. Allow production export only with an explicit administrative override and a masking/scrubbing step. Lower environments may allow opt-in export for debugging, but the export response should record that memory/session content was included.
Migration Plan
Phase 1: Align db-provider With Current Schema
- Add
HindsightMemoryPersistenceImpl. - Add constants and event dispatch for the current Hindsight schema.
- Deprecate or rename legacy
AgentMemoryand oldAgentSessionHistorymethods that do not match the current tables. - Add db-provider tests for replaying bank, unit, session history, and one association table.
Phase 2: Add Command APIs
- Add command schemas for Hindsight memory operations.
- Validate
hostId,bankId, and optionalagentDefIdownership. - Generate events through the normal command path.
- Add authorization checks so an agent can only write memory for its host and allowed bank.
Phase 3: Refactor light-agent
- Introduce
MemoryStore. - Move direct SQL writes behind
DirectPgMemoryStore. - Add
PortalCommandMemoryStore. - Default local development to direct mode if needed, but document it as non-portable.
- Deprecate direct mode after the command path is stable and make
PortalCommandMemoryStorethe only supported production write path. - Validate service-token
host,sid, andenvbefore writing through command APIs.
Phase 4: Snapshot And Import
- Add table-to-event overrides and conversion tests.
- Remove event-backed tables from conversion skip lists.
- Keep export of memory content opt-in.
- Update Rust importer table rules and dependency graph.
- Add replay-order tests for the FK chain.
Phase 5: Backfill Existing Rows
- Build a one-time backfill tool that reads existing direct-write rows and emits synthetic Hindsight events in dependency order.
- Preserve
aggregate_versionwhere possible. - Mark backfilled events with metadata such as:
{
"source": "agent-memory-backfill",
"backfilled": true
}
Do not remove skip rules for production exports until backfill has been run or the deployment has no legacy direct-write rows.
Testing
Add focused tests:
GlobalSnapshotPersistenceImplTest: memory tables remain skipped before event support; event-backed tables are included after the event-backed path is enabled.- db-provider replay tests for each Hindsight event family.
EventTypeUtilaggregate-id tests.- Rust importer table-rule parity tests.
- light-agent
MemoryStoretests using a mock command client. - end-to-end test:
light-agentretain memory -> command event -> replay -> recall reads the memory.
Resolved Decisions
agent_session_history_tis exportable only as an explicit opt-in. Production export is blocked unless an administrative override and data masking/scrubbing step are provided.agent_memory_entity_cooccur_tremains derived. Store the underlying facts as events and rebuild or update co-occurrence counts as projection state.- Direct PostgreSQL writes are a migration bridge only. They should be removed after the command-backed memory path is stable.
- Memory vectors should not be stored in events. Events store source text, metadata, and embedding model metadata when needed. Projection rebuilds should generate vectors, preferably through the embedding task pipeline, so the platform can re-embed after model upgrades.
Tool Description Embedding Population
Problem
The GenAI Tool page lets users update tool_t.description through the
updateTool form. Endpoint-backed tools are also projected into tool_t when
api_endpoint_t is populated from OpenAPI, MCP tools/list, or LightAPI
Description input.
The schema already has tool_t.description_embedding VECTOR(384), but the
current write paths only populate the plain text description:
ApiServicePersistenceImpl.syncEndpointToolProjections(...)inserts or updates endpoint-backedtool_trows fromapi_endpoint_t.GenAIPersistenceImpl.createTool(...)inserts manually authored tools.GenAIPersistenceImpl.updateTool(...)updates the Tool page edit form.genai-commandcreate/update tool contracts do not accept an embedding field, and the Portal UI should not expose raw vectors to users.
As a result, new endpoint-backed tool rows start with a null
description_embedding, and user edits can leave any future vector stale unless
the write path marks it for regeneration.
Goals
- Populate
tool_t.description_embeddingfor endpoint-backed and manually authored tools. - Regenerate the embedding whenever the effective embedding source text changes.
- Keep Tool create/update latency independent from external embedding provider latency.
- Avoid trusting browser-submitted vectors.
- Preserve keyword search and normal CRUD behavior when embedding generation is disabled or temporarily failing.
- Keep the first implementation aligned with the existing
VECTOR(384)schema.
Non-Goals
- Do not require every tool to have an embedding before it can be listed, edited, linked to a skill, or executed through the gateway.
- Do not move MCP execution into portal-query or the controller.
- Do not store API keys or provider secrets in tool metadata.
- Do not expose raw embedding vectors in the Tool page by default.
Recommended Design
Use asynchronous server-side embedding generation. Tool writes should save the
description immediately, mark the embedding stale or pending, and record the
embedding task in the same database transaction as the tool_t update. A worker
then picks up committed tasks, generates a 384-dimensional vector from a
normalized source string, and updates tool_t.description_embedding only if the
tool row still matches the source that was embedded.
For phase 1, this should use a transactional work table or transactional outbox pattern. Do not call the external embedding provider inside the command transaction, but do insert or update the work item before that transaction commits. If a later implementation publishes tasks to Kafka or another queue, the database transaction should still write an outbox row first, and a dispatcher should publish after commit. This avoids a failure mode where the tool row commits successfully but the embedding task is never queued.
This keeps command handling reliable and makes the embedding field a derived read-model value, not user-authored command input.
API version import/update
-> api_endpoint_t rows
-> endpoint-backed tool_t projection
-> upsert embedding_task_t in the same transaction
Tool create/update form
-> ToolCreatedEvent or ToolUpdatedEvent
-> tool_t row update
-> upsert embedding_task_t in the same transaction
embedding worker
-> poll committed pending tasks
-> load current tool row
-> build source text
-> call configured embedding provider
-> update tool_t.description_embedding with compare-and-set guard
Embedding Source Text
The vector should be generated from stable semantic fields, not audit fields or IDs. The default source can be:
name: <tool_t.name>
description: <tool_t.description>
endpoint: <tool_t.api_method> <tool_t.api_endpoint>
domain: <tool_t.routing_domain>
namespace: <tool_t.semantic_namespace>
protocol: <tool_t.source_protocol>
personas: <tool_t.target_personas>
For endpoint-backed tools, the projection can enrich the source with
api_endpoint_t.endpoint_desc and semantic keywords from
api_endpoint_t.tool_metadata.routing.semanticKeywords when available. The
LLM-facing description remains tool_t.description; enrichment only improves
semantic retrieval.
Staleness Tracking
The current table only has the vector. To make regeneration safe and auditable, add lightweight metadata beside it:
| Column | Purpose |
|---|---|
description_embedding_model | Provider/model that produced the vector. |
description_embedding_dimension | Expected to be 384 for the current schema. |
description_embedding_source_hash | SHA-256 of the normalized source text. |
description_embedding_ts | Generation timestamp. |
description_embedding_status | pending, ready, failed, disabled, or blank. |
description_embedding_error | Short last error for diagnostics. |
If the first implementation avoids schema expansion, it should at least set
description_embedding = NULL whenever the description or semantic routing
fields change. That prevents stale vector search, but it gives weaker
operational visibility than explicit status and source-hash columns.
The metadata can live in tool_t beside the vector for simple read-heavy
queries. If row width becomes a concern, move the vector and metadata to a
1:1 table such as tool_embedding_t or a generic entity_embedding_t; keep the
same source-hash and status contract either way. The work table should not be
the only durable location for ready-state metadata because completed work rows
may be retried, compacted, or purged.
Write Path Hooks
The persistence hooks should be narrow:
- When
syncEndpointToolProjections(...)inserts or updates a tool row, compute the source hash from the projected values. If it differs from the stored hash, store the newdescription_embedding_source_hash, mark embedding statuspending, and upsert an embedding task in the same transaction. - When
createTool(...)writes a new row, store the source hash, mark the embeddingpending, and upsert an embedding task in the same transaction unless the normalized source text is blank. For blank source text, clear the vector and mark the statusblankwithout creating a task. - When
updateTool(...)changes description, name, endpoint, routing domain, namespace, source protocol, target personas, endpoint description, or semantic keywords, store the new source hash, mark the embeddingpending, and upsert an embedding task in the same transaction. - When a tool is deactivated, no embedding work is needed. Existing vectors can
remain stored, but vector queries must filter
active = TRUE.
The command contract should not add a descriptionEmbedding property. If a
future admin API needs a manual vector load, it should be a separate privileged
maintenance action, not part of the normal Tool form.
Embedding writes are read-model maintenance, not user-authored tool changes. The
preferred implementation should not emit a normal ToolUpdatedEvent and should
not advance the business aggregate version used for user edits. If the local
persistence framework requires a row-level version for every physical update,
store it separately on the embedding row or task row so embedding maintenance
does not interfere with Tool form optimistic concurrency.
Endpoint Sync And Manual Overrides
Endpoint-backed tools need an explicit description ownership contract. Without
one, a user can improve the Tool page description and later lose the edit when
the API version is synced again from OpenAPI, MCP tools/list, or LightAPI
Description input.
Recommended behavior:
api_endpoint_tremains the source of imported endpoint metadata.tool_t.descriptionis the user-facing LLM description.- When endpoint projection first creates a tool, copy the endpoint description
into
tool_t.description. - When a user edits
tool_t.descriptionfor an endpoint-backed tool, mark the tool description as a manual override. - Later endpoint syncs should update generated endpoint fields and
api_endpoint_t.endpoint_desc, but should not overwritetool_t.descriptionwhile the manual override is active. - Provide a later admin action to reset the description to the imported source.
Suggested columns:
| Column | Purpose |
|---|---|
description_source | endpoint_sync, manual, or another source label. |
description_manual_override | Boolean guard used by endpoint sync. |
description_override_ts | When the manual override was created. |
description_override_user | Who last changed the description manually. |
If a deployment wants endpoint sync to be the absolute source of truth, the Tool page must make that clear before allowing edits, because later syncs will overwrite user-authored descriptions. The default portal behavior should favor manual overrides to avoid surprising users.
Work Queue Options
Three implementation options are viable:
| Option | Pros | Cons |
|---|---|---|
| Polling backfill job | Smallest first step; scans active tools with null or stale embeddings. | Embeddings are eventually populated but not immediately after each edit. |
| Database work table | Reliable retries, status, and batching without depending on Kafka. | Adds one table and worker lifecycle. |
| Event-driven worker | Fits event-driven portal architecture and reacts immediately to tool events. | Requires one more event/consumer contract and careful replay behavior. |
Recommended phase 1 is a database work table or polling worker. It is simpler than putting provider calls inside the command request and safer than calling an external model from inside a database transaction.
Use a generic work table from the start so the same worker can later populate
skill_t.description_embedding and other platform embeddings without adding one
queue per entity type. The table can be named embedding_task_t.
| Column | Purpose |
|---|---|
host_id | Tenant boundary. |
task_id | Task identity for retry and diagnostics. |
entity_type | tool, skill, agent, or another supported embedding target. |
entity_id | Target row ID, such as tool_id or skill_id. |
source_table | Optional source table hint, such as tool_t. |
source_hash | Hash of the source text to embed. |
source_version | Optional row version observed when queued; useful for diagnostics but not required for the final CAS guard. |
status | pending, running, ready, failed. |
attempt_count | Retry count. |
next_attempt_ts | Backoff control. |
last_error | Short diagnostic text. |
update_ts | Queue row update time. |
Use a unique key such as (host_id, entity_type, entity_id, source_hash) so the
transactional upsert is idempotent.
The worker should claim tasks with row locking, for example
FOR UPDATE SKIP LOCKED, so multiple workers can run safely. The final tool
update should use the source hash as the primary compare-and-set guard:
UPDATE tool_t
SET description_embedding = ?,
description_embedding_model = ?,
description_embedding_dimension = 384,
description_embedding_ts = CURRENT_TIMESTAMP,
description_embedding_status = 'ready',
description_embedding_error = NULL
WHERE host_id = ?
AND tool_id = ?
AND active = TRUE
AND description_embedding_source_hash = ?;
If the row no longer matches, the worker should drop that result and let the newer pending job win. This prevents stale vectors from overwriting a newer description.
Avoid using aggregate_version as a hard CAS requirement unless it is truly
needed for local event-sourcing rules. The version may change because of fields
that are not part of the embedding source, causing spurious worker failures even
when the source hash is still valid. If aggregate_version must be checked, a
CAS failure should reload the row; if the stored source hash is unchanged, retry
the embedding update using the current version. If the source hash changed, drop
the stale result.
Embedding Provider
Add a small server-side provider abstraction:
EmbeddingProvider.embed(model, dimension, inputText) -> float[384]
Configuration should include:
| Setting | Purpose |
|---|---|
embedding.provider | openai-compatible, local-http, or disabled. |
embedding.model | Provider model name. |
embedding.dimension | Must match 384 until the schema is migrated. |
embedding.batchSize | Worker batch size. |
embedding.timeoutMs | Provider call timeout. |
embedding.maxRetries | Retry limit before failed. |
For hosted providers, configure a model that can emit 384 dimensions, such as an OpenAI-compatible embedding endpoint with an explicit dimensions parameter. For restricted deployments, use a local embedding service that emits the same dimension.
Search And Indexing
Vector search should only use ready embeddings:
WHERE host_id = ?
AND active = TRUE
AND description_embedding IS NOT NULL
AND description_embedding_status = 'ready'
ORDER BY description_embedding <=> ?
Add a pgvector index when catalog size makes sequential vector scans too slow:
CREATE INDEX idx_tool_description_embedding
ON tool_t USING hnsw (description_embedding vector_cosine_ops)
WHERE active = TRUE
AND description_embedding IS NOT NULL
AND description_embedding_status = 'ready';
genai-query can continue keyword search while embeddings are being populated.
When vector ranking is enabled, combine vector distance with existing macro
filters such as host, active flag, assigned skill, routing domain, semantic
namespace, sensitivity tier, source protocol, and semantic_weight.
Vector nearest-neighbor search should run in genai-query against PostgreSQL
with pgvector, not inside the agent’s local catalog cache. Database-side search
scales better because it can apply tenant, active-state, RBAC, assigned-skill,
domain, and sensitivity filters before returning a small top-K result. The agent
can still keep a lightweight local cache for fallback keyword matching and
gateway intersection, but it should not need to download every catalog vector to
rank tools.
Backfill
Existing rows need a one-time backfill:
- Scan active tools with a non-blank description and null or stale embedding.
- Queue embedding work in batches per host.
- Generate and persist vectors with retry/backoff.
- Report counts: total tools, ready, pending, failed, disabled, blank source.
Backfill should be restartable and idempotent. It should not block portal startup or the Tool page.
Portal UI
The first UI change should be optional diagnostics, not vector editing:
- Do not show
description_embeddingin create/update forms. - Optionally show read-only status columns on the Tool page:
Embedding Status,Embedding Model, andEmbedding Updated. - After a user updates the description, show the saved description immediately.
The embedding can move from
pendingtoreadyasynchronously. - Add an admin action later for “Refresh Embedding” if operators need manual repair.
Failure Behavior
- If embedding is disabled, save descriptions normally and mark status
disabled. - If provider calls fail, keep the tool active and searchable by keyword.
- Failed rows should retry with backoff and surface diagnostics.
- A stale worker result must not overwrite a newer description’s embedding.
- If the source text is blank, clear the embedding and mark the status
disabledorblank.
Implementation Phases
Phase 1: Safe Population
- Add embedding metadata columns to
tool_t, or add a 1:1 embedding table, and add a genericembedding_task_tfor queued work. - Add description manual-override metadata for endpoint-backed tools.
- Add write-path hooks in endpoint projection and Tool create/update persistence. The hooks must upsert embedding work in the same database transaction as the tool row change.
- Add a polling or queue-backed embedding worker.
- Add a backfill command for existing active tools.
- Add focused tests that endpoint projection and
updateToolmark embeddings pending when descriptions change.
Phase 2: Diagnostics
- Expose read-only embedding status through
getToolandgetFreshTool. - Add Tool page status columns or a diagnostics view.
- Add retry and refresh operations for failed rows.
Phase 3: Retrieval
- Add the pgvector index.
- Add vector ranking to
genai-queryor the effective catalog path. - Combine vector score with keyword score, macro filters, and
semantic_weight. - Keep gateway
tools/listintersection as the runtime executability check.
Design Decisions
- Use a transactional work table or outbox for phase 1. The provider call is asynchronous, but task creation must be committed atomically with the tool row change.
- Use source hash as the primary stale-result guard. Treat
aggregate_versionas diagnostic or optional unless local persistence rules require it. - Make the task table generic with
entity_typeandentity_id, so skills and future entities can share the same worker. - Preserve manual Tool page description edits with a manual override flag for endpoint-backed tools.
- Reuse the same worker for
skill_t.description_embeddingwhen skill semantic search is enabled. The task shape should already supportentity_type = 'skill'. - Run vector ranking in
genai-querywith pgvector and return top-K results to the agent. Keep local agent ranking as a fallback or small-cache optimization, not the primary scalable path.
Workflow Editor
Purpose
The Workflow Editor is the generic Portal authoring surface for
light-workflow definitions. It should replace the raw textarea-only workflow
definition experience with a structured editor that still preserves YAML as the
canonical workflow definition stored in wf_definition_t.definition.
The editor is reusable. It can be opened from the Workflow Definition page, embedded in the Skill Workspace, or used by future task-specific authoring flows such as API onboarding, scheduled live tests, and remediation playbooks.
Design Boundary
light-workflow owns workflow execution, task state, retries, waiting human
tasks, and audit events. The Portal editor authors definitions and starts test
runs, but it must not implement its own workflow runtime.
The gateway remains the runtime tool execution path. Workflow steps that invoke tools should reference gateway-visible tools or endpoint descriptions and then execute through the same runtime path used by agents.
The editor should not duplicate endpoint contracts. API, MCP, JSON-RPC, gRPC, and other endpoint details belong in LightAPI descriptions, OpenAPI/OpenRPC documents, protobuf metadata, or the portal endpoint catalog. Workflow tasks reference those descriptions and provide step-level wiring, guards, exports, and error handling.
Current State
The current Portal implementation already has the persistence and generic CRUD surface needed for a first editor:
wf_definition_tstoresnamespace,name,version, anddefinition.workflow-commandexposes create, update, delete, and start workflow commands.workflow-queryexposes workflow definition reads.portal-viewhas a Workflow Definition table and generic create/update forms whosedefinitionfield is a YAML textarea.
The first Workflow Editor can therefore be an incremental UI improvement over the existing definition CRUD and start workflow command.
Goals
- Keep workflow YAML as the canonical persisted artifact.
- Provide a readable step outline or graph next to the YAML editor.
- Validate definitions before save and before test runs.
- Let users discover and reference endpoint descriptions, gateway tools, skills, rules, and human task types from a side panel.
- Support workflow definition create, update, import, export, and start-test flows.
- Make the editor embeddable so skill authoring can use the same workflow authoring component with skill-specific constraints.
- Preserve owner scoping and existing Portal command/query conventions.
Non-Goals
- Do not execute workflow logic in Portal View.
- Do not make skills the workflow runtime.
- Do not store workflow YAML in
skill_t. - Do not require a visual drag-and-drop graph before the editor is useful.
- Do not copy full API contracts into workflow steps when endpoint descriptions can be referenced.
- Do not fork or embed the Apache KIE Serverless Logic Web Tools as the first implementation path. They are useful reference material for CNCF Serverless Workflow concepts, but they are tightly coupled to the strict upstream spec and would be expensive to adapt for Light-Fabric agentic extensions.
Authoring Model
The editor should maintain two synchronized representations:
| Representation | Purpose |
|---|---|
| YAML source | Canonical text saved to wf_definition_t.definition. |
| Parsed view model | UI-only representation used for step outline, validation, references, and property panels. |
All saves should serialize from the YAML source or from a parsed model that round-trips to the same specification format. If the visual editor changes a step, it should update the YAML and keep the YAML visible.
The editor should support progressive enhancement:
- YAML editor plus parsed step outline.
- Step palette and property panel that edit YAML safely.
- Read-only graph preview.
- Drag-and-drop graph editing once round-trip behavior is reliable.
Implementation Architecture
The recommended implementation is a custom React editor built from focused building blocks:
| Component | Recommended library | Responsibility |
|---|---|---|
| Source editor | CodeMirror 6 with JSON/YAML extensions | Edit YAML/JSON, validate against the Light-Fabric workflow schema, provide autocomplete, lint markers, folding, and hover help. |
| Visual graph | React Flow / xyflow | Render workflow states as nodes and transitions as edges, with custom node components for agentic task types. |
| Property panels | Schema-backed React forms, optionally JSONForms | Edit selected node/task properties without forcing users to hand-edit every YAML field. |
| State manager | Existing portal state pattern or Zustand if a local editor store is needed | Hold the canonical workflow document, parsed model, diagnostics, selected node, dirty state, and test run state. |
The workflow YAML or JSON document remains the source of truth. CodeMirror edits parse into the editor store. The parsed workflow model is then projected into React Flow nodes and edges. React Flow edits update the same model and then serialize back to the YAML document.
This avoids adding a second large browser editor runtime to portal-view,
which already uses CodeMirror for Markdown and OpenAPI JSON/YAML editing. It
also avoids fighting a visualizer that only understands the strict CNCF
Serverless Workflow schema, while still letting Portal define first-class
visual treatments for Light-Fabric task types such as agent, mcp, ask,
assert, rule, switch, and future LLM or approval-oriented steps.
CodeMirror should use a custom JSON Schema derived from the CNCF Serverless
Workflow schema plus Light-Fabric agentic extensions. For JSON definitions,
use a CodeMirror 6 JSON Schema integration such as codemirror-json-schema to
provide linting, autocomplete, and hover details. For YAML definitions, reuse
the existing portal-view CodeMirror YAML setup where possible and add schema
validation through a YAML language-server bridge or equivalent worker-backed
integration. The goal is Monaco-like schema assistance without Monaco’s bundle
cost.
React Flow should not own the persisted shape. It owns layout, selection, edge creation, and node interaction. The persisted workflow definition should remain independent of the canvas library so a future editor or CLI can read the same definitions.
Recommended sync behavior:
- Parse CodeMirror content into a typed workflow model when the YAML is valid.
- Preserve text edits and show problems when YAML is invalid; do not destroy the user’s in-progress text.
- Project valid workflow models to React Flow nodes and edges.
- Let graph edge changes update transition targets in the model.
- Let property-panel changes update the model through schema-aware controls.
- Serialize model changes back into the YAML document using stable formatting.
- Keep conflict handling explicit when source edits and graph edits race.
Mermaid can be used for documentation or a lightweight read-only preview, but it is not the long-term authoring surface. JSONForms can be useful inside property panels, but it should not replace the graph/source editor combination.
Layout
Recommended first layout:
| Region | Contents |
|---|---|
| Header | Namespace, name, version, owner, active state, save, validate, import, export, and test actions. |
| Left panel | Step outline, problems, references, and search. |
| Main panel | YAML editor with syntax highlighting and parse markers. |
| Right panel | Selected step properties, input/output/export preview, and endpoint/tool metadata. |
| Bottom panel | Test input, validation results, workflow events, waiting tasks, and output. |
The generic Workflow Definition page can use the full layout. The Skill Workspace can embed the same editor with a narrower reference scope and a skill-aware validation profile.
Step Palette
The editor should understand the task types defined by the Light-Fabric agentic workflow design:
| Step type | Use |
|---|---|
ask | Pause for human input, approval, or missing values. |
assert | Validate context, API results, or business rules. |
http / openapi | Invoke HTTP endpoints directly or through cataloged descriptions. |
jsonrpc / openrpc | Invoke JSON-RPC methods directly or through OpenRPC descriptions. |
grpc | Invoke cataloged gRPC methods. |
mcp | Invoke gateway-visible MCP tools, resources, or prompts. |
rule | Delegate complex checks to Light-Rule. |
agent | Delegate a bounded task to an agent worker. |
switch / condition | Branch based on workflow context or task output. |
set / export | Move task results into workflow context. |
wait | Represent a durable wait, timeout, or externally completed task. |
The palette should create minimal valid YAML fragments. Users can then edit the full YAML when advanced options are needed.
Reference Panel
The editor should help authors reference existing catalog objects instead of typing fragile identifiers by hand:
- workflow definitions and versions,
- LightAPI endpoint descriptions,
- API endpoints and tool projections,
- gateway-visible MCP tools,
- rule definitions,
- agent definitions,
- skills and skill-linked tools when the editor is embedded in the Skill Workspace.
For generic workflow authoring, the reference panel can show all objects the current user is allowed to read. For skill authoring, it should filter tools to the skill’s linked tools and flag references outside that set.
Validation
Validation should run in layers:
| Layer | Checks |
|---|---|
| Syntax | YAML parses, document shape is valid, and duplicate keys are rejected when possible. |
| Specification | Required workflow fields, step IDs, task type structure, branch targets, exports, and inputs are valid. |
| Catalog references | Referenced endpoint descriptions, tools, rules, agents, and child workflows exist and are active. |
| Security | Sensitive or destructive steps have required approval, visibility, and ownership metadata. |
| Skill embedding | Workflow tool calls are linked through skill_tool_t when editing a workflow-backed skill. |
| Runtime diagnostics | Optional gateway tools/list checks compare cataloged tool names with deployed gateway availability. |
Runtime diagnostics should be separate from persistence validation. A workflow definition can be saved before a gateway is reachable, but the editor should make missing runtime executability visible before test or deployment.
Test Runner
The editor should support a test panel that starts a workflow instance through the existing workflow start command and then reads instance events and task state through the workflow query APIs.
The test panel should support:
- JSON workflow input,
- start run,
- event stream or polling view,
- current context and output preview,
- waiting task completion for
askor approval steps, - assertion and rule failure display,
- gateway or endpoint call failure display,
- rerun with the same input.
The test runner is a client of light-workflow; it does not execute workflow
steps in the browser.
Skill Workspace Integration
Phase 3.5 skill authoring should embed the Workflow Editor rather than create a second skill-specific workflow UI.
Recommended integration:
- The Skill Workspace has a Workflow tab.
- The tab lets the user choose
noneorworkflow-backed. - In workflow-backed mode, the user can select an existing workflow definition or create a draft definition.
- The link is stored in
skill_workflow_t. - The editor reference panel filters tool references to the tools linked by
skill_tool_t. - Validation rejects or warns on workflow tool calls not present in the skill’s allowed tool set.
- The Test tab starts the linked workflow with sample JSON input and displays the same workflow events used by the generic editor.
This keeps the skill as a discovery and guidance artifact while light-workflow
owns deterministic orchestration.
Data And API Changes
The first generic editor can reuse existing workflow definition APIs. Later phases should add editor-friendly endpoints only when they remove real UI complexity.
Phase B adds the validation endpoint and keeps the reference catalog composed from existing read models. A single combined catalog endpoint remains optional if the multiple list queries become noisy or slow.
| API or table | Purpose |
|---|---|
validateWfDefinition | Server-side validation using the workflow query service parser and, later, the same schema as light-workflow. |
formatWfDefinition | Optional canonical formatting if the workflow parser supports round-trip formatting. |
| Existing catalog queries | Fetch endpoint, tool, rule, agent, and workflow labels for the reference panel. |
getWorkflowReferenceCatalog | Optional future consolidation into one reference-panel query. |
startWorkflow | Start an editor test run for the saved workflow definition with sample JSON input. |
| Workflow runtime read models | Refresh process, task, task assignment, worklist, and audit-log projections for the current workflow instance. |
completeTask | Complete a waiting ask or human task from the editor test panel by emitting a TaskInfoUpdatedEvent. |
skill_workflow_t | Link skills to workflow definitions without embedding workflow YAML in skills. |
saveSkillWorkspace | Composite command that saves skill metadata, taxonomy, tool links, workflow links, and optional draft workflow updates from one workspace action. |
Server-side validation should be authoritative. Client-side validation is useful for responsiveness but should not be the only guard before saving or testing a workflow definition.
Phased Implementation
Phase A: Structured YAML Editor
- Add a generic Workflow Editor component and route.
- Replace create/update workflow definition textarea navigation with the editor where practical.
- Keep YAML visible and canonical.
- Reuse the existing portal-view CodeMirror editor stack with the Light-Fabric workflow schema for YAML/JSON validation, autocomplete, hover help, folding, and parse markers.
- Parse YAML client-side to render a step outline and problems panel.
- Add import/export and basic validation before save.
Phase B: Catalog-Aware Authoring
- Add a reference panel for endpoint descriptions, tools, rules, agents, and workflow definitions.
- Add a step palette that inserts valid YAML snippets.
- Add schema-backed property panels for selected steps. Use dropdowns for catalog references and constrained enums instead of free-text fields where Portal already has authoritative labels.
- Add server-side validation through
validateWfDefinition. - Add runtime diagnostics that compare MCP tool references with gateway
tools/listor the Rust agent/diagnostics/toolsendpoint when a gateway target is selected.
Phase C: Test And Worklist Integration
- Add a test runner panel backed by
light-workflowstart and query APIs. - Show workflow events, current task state, waiting human tasks, assertions, and final output.
- Let users complete
asktasks from the test panel. - Link failed test runs to remediation tasks or worklist entries.
Phase C uses the existing Portal workflow command/query boundary. The editor
starts a test run through workflow/startWorkflow, then refreshes
getProcessInfo, getTaskInfo, getTaskAsst, getWorklist, and
getAuditLog for the returned wfInstanceId. The test panel completes a
waiting human task through workflow/completeTask, which preserves the
structured response in the event data and materializes the task as completed
through the existing TaskInfoUpdatedEvent projection.
The panel should expose remediation links instead of silently creating production work. Failed process or task rows can open a prefilled remediation task form, and task assignments can jump to the workflow worklist with the current workflow instance context.
Phase D: Visual Graph Editing
- Add a React Flow graph preview after the outline is stable.
- Represent Light-Fabric task types with custom React Flow nodes and explicit transition edges.
- Add drag-and-drop graph editing only after YAML/model round-trip behavior is reliable.
- Keep YAML as the source of truth even when visual editing is enabled.
Phase D adds the graph as a projection of the parsed YAML model, not a separate
persisted representation. The graph reads steps, tasks, states, or do
containers and renders one custom React Flow node per detected step. Node
styling reflects the Light-Fabric task type, and the graph can overlay runtime
task status from the Phase C test-run read models when the workflow task id
matches a graph step id.
Explicit transition fields such as next, then, to, and transition
become solid graph edges. Ordered fallback edges are shown as dashed edges so
authors can distinguish model transitions from inferred sequence. Creating an
edge in React Flow updates the source step’s transition in YAML, and deleting an
explicit edge removes that transition target from YAML. Dragging nodes changes
only the authoring layout in the browser session; it does not mutate the saved
workflow definition.
The graph must continue to tolerate partial or invalid authoring states. If the YAML cannot be parsed into a known workflow container, the editor keeps the source editor and validation panels usable and shows an empty graph state rather than blocking authoring.
Recommendation
Build the generic Workflow Editor before the Skill Workspace embeds workflow authoring. The skill UI should provide context and constraints, while the workflow editor provides YAML editing, step preview, validation, and test runs for every workflow authoring use case in Portal.
Portal Catalog Scope
Problem
Light Portal supports multiple tenants through host_id and can also host
multiple runtime environments in one portal instance. A common deployment shape
is:
| Portal instance | Runtime environments |
|---|---|
| Instance A | dev, sit |
| Instance B | stg, prd |
Within an organization or a cloud deployment, operators need a catalog for APIs, API endpoints, tools, skills, schemas, rules, workflows, categories, and tags. Some catalog entries are reusable platform knowledge. Other entries are tenant-owned, environment-bound, or tied to a concrete gateway deployment.
The main design question is whether Light Portal should clone catalog rows into every host/tenant, or maintain one shared catalog per portal instance and expose it through a separate single page application and virtual host.
The recommended answer is neither full cloning nor a UI-only split. The portal should model catalog scope explicitly:
- shared catalog definitions use global scope,
- tenant-specific definitions and overrides use host scope,
- environment-specific runtime bindings use host plus environment scope,
- a separate SPA may expose the same backend catalog, but it should not become the catalog authority.
Goals
- Avoid duplicating the full catalog for every tenant.
- Prevent catalog drift between tenants and between portal instances.
- Preserve tenant isolation for private APIs, private skills, secrets, access control, and runtime bindings.
- Let dev and sit share one portal instance while still keeping their runtime endpoint targets separate.
- Let stg and prd share another portal instance while keeping production controls stricter.
- Support an effective catalog query that combines global definitions with host-specific rows and environment-specific bindings.
- Reuse existing portal-query APIs and the
genai-querycatalog direction for agent-facing skills and tools. - Keep
light-gatewayas the runtime MCP execution path fortools/listandtools/call. - Support promotion or import/export between portal instances instead of relying on ad hoc row copies.
Non-Goals
- Do not clone every global catalog row into every tenant by default.
- Do not make a separate SPA the source of truth for catalog data.
- Do not bypass host-scoped authorization just because a catalog item is global.
- Do not put secrets, client credentials, runtime tokens, or deployment state in global catalog rows.
- Do not move MCP tool execution from
light-gatewayinto portal-query, controller-rs, or the catalog UI. - Do not require every MCP or API endpoint to be wrapped in a skill before the gateway can expose it as a runtime tool.
Current Model
The database already contains both global-capable and host-scoped patterns.
category_t and tag_t have nullable host_id. A null host_id means the
category or tag is global. A non-null host_id means the row belongs to one
host. Their unique indexes already separate global uniqueness from host-specific
uniqueness.
The query behavior for category and tag labels returns both host-specific rows and global rows for a host. This is the right shape for taxonomy and catalog organization metadata.
Other catalog entities are currently host-scoped:
api_tapi_version_tapi_endpoint_tagent_definition_tskill_ttool_ttool_param_tagent_skill_tskill_tool_tskill_dependency_t
Those tables use host_id NOT NULL and most query paths filter by
host_id = ?. This is correct for private tenant data and runtime-bound data,
but it is too narrow for reusable platform catalog definitions if the only
sharing mechanism is row replication.
Design Decision
Use a scoped catalog inside Light Portal.
The portal backend remains the source of truth. The catalog UI can be part of the existing portal SPA or exposed through another SPA/virtual host, but both UI surfaces must read and write through the same portal-query and command APIs.
The durable model is:
global catalog definition
-> host enablement or host override
-> environment runtime binding
This model allows one shared definition for reusable knowledge and separate tenant or environment controls where isolation matters.
Scope Types
| Scope | Storage meaning | Typical data |
|---|---|---|
| Global | host_id IS NULL or a dedicated global definition row | Shared categories, tags, reusable schemas, rule templates, workflow templates, public tool definitions, shared skill templates |
| Host | host_id = ? | Tenant-owned APIs, private schemas, tenant skills, tenant tools, host-level enablement, access rules |
| Environment | host_id = ? plus env_tag, service id, target host, instance, or deployment binding | dev/sit/stg/prd endpoint targets, gateway exposure, runtime service bindings, deployment state |
| Instance | Separate portal database or portal deployment | Promotion boundary between dev/sit instance and stg/prd instance |
Global rows are reusable definitions. Host rows are ownership and isolation. Environment rows are runtime selection.
Catalog Entity Guidance
| Entity | Recommended scope | Reason |
|---|---|---|
| Category | Global by default, host-specific when private taxonomy is needed | Existing schema already supports nullable host_id |
| Tag | Global by default, host-specific when private taxonomy is needed | Existing schema already supports nullable host_id |
| API | Host-scoped, with optional shared template support later | API ownership, lifecycle, and visibility are usually tenant-specific |
| API version | Host-scoped | Carries env_tag, target_host, service id, spec, and runtime-facing version metadata |
| API endpoint | Host-scoped for concrete API versions; may be generated from shared templates | Endpoint availability depends on the owning API version and runtime |
| Tool | Shared definition when generic; host-scoped projection when executable for a tenant | Runtime execution still depends on gateway, endpoint, policy, and service binding |
| Skill | Shared template when reusable; host-scoped copy or override when edited by a tenant | Skills contain prompt guidance that tenants may customize |
| Schema | Global when it is a reusable contract; host-scoped when it contains tenant-private fields or lifecycle | Avoid cloning standard contracts but protect tenant-specific schemas |
| Rule | Global template or host-specific rule | A reusable rule definition is different from enabling that rule for a host |
| Workflow | Global template or host-specific workflow | Templates can be shared, execution bindings should be host or environment scoped |
Effective Catalog
Consumers should not need to manually merge global and host rows. Portal-query should expose an effective catalog read model for each host and runtime context.
The effective catalog request should include:
hostIdserviceIdwhen the catalog is for a gateway, agent, or runtime serviceenvTagwhen the result is environment-specific- optional
agentDefIdwhen the result is for an agent - optional filters for entity type, category, tag, protocol, routing domain, or capability
The effective catalog response should include:
- global definitions visible to the caller,
- host-specific definitions visible to the caller,
- host overrides that shadow global defaults,
- environment bindings for the requested
envTag, - active state and catalog version or freshness metadata,
- category and tag labels from both global and host-specific taxonomy rows,
- enough provenance to show whether a row came from global scope, host scope, or an environment binding.
Recommended precedence:
environment binding > host override > global definition
This keeps shared definitions stable while allowing host and environment customization.
Data Model Direction
For tables that already support nullable host_id, keep the current pattern:
host_id IS NULL -> global/shared row
host_id = ? -> host-specific row
For strictly host-scoped catalog tables, do not simply make every host_id
nullable without checking foreign keys and runtime assumptions. Some tables are
correctly host-scoped because they point to tenant-owned APIs, credentials,
gateway endpoints, or agent assignments.
Use one of these patterns per entity:
- Nullable
host_idon the definition table when the entity can safely be global and all references can resolve global plus host rows. - Separate template and binding tables when the definition is global but enablement is tenant-specific.
- Keep the current host-scoped table when the entity is inherently tenant or runtime bound.
For reusable skills and tools, the safest long-term shape is template plus binding:
catalog_skill_template_t
-> host_skill_t or skill_t host override
-> agent_skill_t assignment
catalog_tool_template_t
-> host tool projection
-> skill_tool_t mapping
-> gateway runtime tools/list verification
If the implementation starts smaller, it can add nullable global scope to selected catalog definition tables first, but the query contract must still return the effective catalog and indicate scope provenance.
Separate SPA Or Virtual Host
A separate SPA deployed with LightAPI and sign-in as another BFF virtual host is useful as a catalog presentation surface. It can provide a marketplace-style view for shared APIs, tools, skills, schemas, rules, and workflows.
It should not own separate catalog state.
Recommended use:
- browse global catalog definitions,
- request enablement for a host,
- compare host overrides with global definitions,
- review environment bindings,
- publish or promote catalog versions between portal instances.
Avoid using the separate SPA to bypass tenant-aware portal APIs. The BFF should still pass authenticated requests to portal-query or command APIs, and those APIs must enforce host, service, environment, and role checks.
Environment Handling
Within one portal instance, environments should be runtime bindings, not cloned catalog universes.
For a dev/sit instance:
- one shared catalog can describe a capability,
- dev and sit get separate
env_tagbindings, - runtime endpoints can differ through
target_host,service_id, instance, deployment, or gateway registration, - a tool can be visible in both environments but executable only where the gateway lists it.
For a stg/prd instance:
- stg and prd can share approved global definitions,
- production enablement should require stricter workflow or authorization,
- secrets, tokens, OAuth clients, runtime instances, and deployment state remain environment-specific,
- catalog promotion into prd should preserve stable IDs and versions.
Promotion Between Portal Instances
The boundary between dev/sit and stg/prd is an instance boundary. Treat it as a promotion boundary, not as live replication between tenants.
Recommended promotion flow:
- Author or import catalog definitions in the lower portal instance.
- Review and approve the global or host-scoped definitions.
- Export selected catalog rows with their versions and dependencies.
- Import into the target portal instance.
- Resolve environment bindings for stg or prd.
- Verify runtime exposure through the selected
light-gatewaytools/list. - Activate the target bindings.
Promotion should be idempotent. A repeated import of the same catalog version should update or confirm the same target definition instead of creating duplicates.
Security And Authorization
Global catalog visibility does not mean global execution permission.
Authorization must be checked at these layers:
- portal UI and BFF authentication,
- portal-query read authorization,
- command API write authorization,
- host and environment claim matching,
- category/tag visibility when private taxonomy is used,
- gateway
tools/listavailability, - gateway
tools/callpolicy, - downstream service authorization.
For runtime catalog reads used by gateways and agents, the token should include
host, sid, and, when environment-specific data is requested, env. The
query handler should compare those claims with the requested hostId,
serviceId, and envTag.
UI Guidance
The portal UI should show catalog scope explicitly:
GlobalHostEnvironment
For list pages, include filters for scope, environment, category, tag, active state, and source protocol. For detail pages, show whether a host row inherits from a global definition, overrides it, or is private to the host.
For destructive changes, make the target scope clear. Updating a global catalog definition can affect many hosts, while updating a host override should affect only that host.
Migration Approach
- Keep the existing category and tag nullable
host_idbehavior. - Add effective catalog read APIs before broad schema changes so callers have a stable contract.
- Identify which catalog entities need global definitions versus host-only rows.
- Add template or nullable-scope tables for reusable definitions.
- Add host enablement or override tables for tenant-specific activation.
- Add environment binding views or APIs for dev, sit, stg, and prd.
- Add import/export or snapshot support for promotion between portal instances.
- Update portal-view to expose scope and provenance.
- Keep existing host-scoped APIs working during the migration.
Open Questions
- Should global reusable skills and tools use nullable
host_idin the existing tables, or separate template tables with host bindings? - Which catalog entities require approval workflow before production activation?
- Should category and tag assignment tables store additional scope metadata, or is scope fully inherited from the referenced category or tag?
- What stable external identity should be used during cross-instance catalog promotion when UUIDs differ between portal databases?
- Should portal-query expose one broad effective catalog endpoint or multiple entity-specific effective endpoints?
OAuth Audit
The OAuth services keep authorization codes and refresh tokens as operational state. These rows are short lived and are now written directly to auth_code_t and auth_refresh_token_t instead of being created through the general event store. This avoids high-volume login and refresh-token churn in event_store_t and outbox_message_t.
Audit and login history are recorded separately in append-oriented OAuth audit tables.
Goals
- Show administrators who is currently online.
- Show a user the last login time and session history.
- Track refresh-token rotation and rejected refresh attempts.
- Preserve enough history for support and security review without storing raw secrets.
- Keep the hot login and token-refresh path simple and transactional.
Tables
auth_session_t stores one row per login session. It is the current and historical session summary.
session_ididentifies the browser/device session.login_ts,last_refresh_ts,logout_ts, andexpires_tsdescribe the session lifetime.statusisACTIVE,LOGGED_OUT,EXPIRED, orREVOKED.refresh_countis incremented on each successful refresh-token rotation.ip_address,user_agent, anddevice_idare optional request context fields.
auth_session_audit_t stores append-only auth audit entries.
LOGIN_SUCCEEDEDLOGIN_FAILEDAUTH_CODE_ISSUEDAUTH_CODE_CONSUMEDREFRESH_TOKEN_ISSUEDREFRESH_TOKEN_ROTATEDREFRESH_TOKEN_REJECTEDLOGOUTSESSION_EXPIREDSESSION_REVOKED
auth_refresh_token_t.session_id links the currently valid refresh token to the session that owns it. This removes ambiguity when the same user is logged in from multiple browsers or devices.
Audit rows keep session_id as data, but do not use a hard foreign key to auth_session_t. Audit history must remain groupable by session even if operational session rows are later archived or removed.
Login Flow
When /oauth2/{providerId}/code authenticates the user:
- Insert the authorization code into
auth_code_t. - Insert an
ACTIVEsession intoauth_session_t. - Insert
LOGIN_SUCCEEDEDandAUTH_CODE_ISSUEDaudit rows. - Include the
session_idin the auth code row so the token exchange can attach the refresh token to the same session.
Failed logins write LOGIN_FAILED with the available host, provider, client, request metadata, and failure reason.
Authorization Code Exchange
When grant_type=authorization_code succeeds:
- Delete the consumed auth code from
auth_code_t. - Insert the refresh token into
auth_refresh_token_twith the auth code’ssession_id. - Insert
AUTH_CODE_CONSUMEDandREFRESH_TOKEN_ISSUEDaudit rows.
Refresh Token Rotation
When grant_type=refresh_token succeeds, the service performs one transaction:
- Insert the replacement refresh token.
- Delete the previous refresh token with its expected aggregate version.
- Update
auth_session_t.last_refresh_tsand incrementrefresh_count. - Insert
REFRESH_TOKEN_ROTATEDwith the old and new token ids.
If a refresh token is missing, invalid, or belongs to the wrong client, the service writes REFRESH_TOKEN_REJECTED when enough context is available. Raw refresh-token values must not be stored in audit metadata.
Admin Revocation
Administrators can kick out a user by revoking the user’s current refresh token. Operationally, deleting the refresh token is enough to stop the session from renewing once the current access token expires. The audit/session model adds explicit session state to that behavior.
The revocation operation must run as one transaction:
- Find the refresh token row and its
session_id. - Delete the refresh token from
auth_refresh_token_t. - Update
auth_session_t:status = 'REVOKED'logout_ts = CURRENT_TIMESTAMPend_reason = 'ADMIN_REVOKED'
- Insert
SESSION_REVOKEDintoauth_session_audit_t.
The database patch provides revoke_auth_session_by_refresh_token(host_id, refresh_token, admin_user, reason) for this workflow. Admin screens should call the revoke operation instead of issuing a plain refresh-token delete when the intent is to kick out a logged-in user.
If the refresh token has no session_id, the operation still deletes the token and returns NULL. This preserves backward compatibility with refresh-token rows created before session tracking.
Admin Queries
Current online users:
SELECT *
FROM auth_session_t
WHERE status = 'ACTIVE'
AND (expires_ts IS NULL OR expires_ts > CURRENT_TIMESTAMP);
User login history:
SELECT *
FROM auth_session_t
WHERE host_id = $1
AND user_id = $2
ORDER BY login_ts DESC;
Session duration:
SELECT
login_ts,
COALESCE(logout_ts, last_refresh_ts, CURRENT_TIMESTAMP) - login_ts AS duration
FROM auth_session_t
WHERE host_id = $1
AND session_id = $2;
Retention
auth_session_t can be retained longer than operational token tables. auth_session_audit_t should use a retention policy appropriate for the deployment, for example 90 days or one year. Retention jobs should delete audit rows by event_ts and optionally archive them before deletion.
Multi-Tenant
Database Schema
Adding a host_id to every table is one approach, but it does lead to composite primary keys and can impact performance. Using UUIDs as primary keys, even in a multi-tenant environment, is another viable option with its own set of trade-offs. Let’s examine both strategies:
- Host ID on Every Table (Composite Primary Keys)
Schema: Each table would have a host_id column, and the primary key would be a combination of host_id and another unique identifier (e.g., user_id, endpoint_id).
CREATE TABLE user_t (
host_id UUID NOT NULL, -- References hosts table
user_id INT NOT NULL,
-- ... other columns
PRIMARY KEY (host_id, user_id),
FOREIGN KEY (host_id) REFERENCES hosts_t(host_id)
);
Pros:
-
Data Isolation: Clear separation of data at the database level. Easy to query data for a specific tenant.
-
Backup/Restore: Simplified backup and restore procedures for individual tenants.
Cons:
-
Composite Primary Keys: Can lead to more complex queries, especially joins, as you always need to include the host_id. Can affect query optimizer performance.
-
Storage Overhead: host_id is repeated in every row of every table, adding storage overhead.
-
Index Impact: Composite indexes can sometimes be less efficient than single-column indexes.
- UUIDs as Primary Keys (Shared Tables)
Schema: Tables use UUIDs as primary keys. A separate table (tenant_resources_t) maps UUIDs to tenants.
CREATE TABLE user_t (
user_id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
-- ... other columns
);
CREATE TABLE tenant_resource_t(
host_id UUID NOT NULL,
resource_type varchar(255) NOT NULL, --e.g., 'user', 'api_endpoint'
resource_id UUID NOT NULL,
PRIMARY KEY(host_id, resource_type, resource_id),
FOREIGN KEY (host_id) REFERENCES hosts_t(host_id)
);
Pros:
-
Simplified Primary Keys: Easier to manage single-column UUID primary keys. Simpler joins.
-
Reduced Storage Overhead: No need to repeat host_id in every table.
-
Application Logic: Multi-tenancy is handled mostly in the application logic by querying tenant_resources_t to ensure a user belongs to the correct tenant, adding a layer of flexibility. (This is also a con if not carefully implemented.)
Cons:
-
Data Isolation (slightly reduced): Data is logically separated but resides in shared tables. Robust application logic is essential to prevent data leakage between tenants.
-
Backup/Restore (more complex): Backing up/restoring for a single tenant requires filtering based on the tenant_resources_t table.
-
Query Performance (potential issue): Queries might require joining with tenant_resources_t table which will add a bit overhead. Proper indexing and query optimization become crucial.
- Hybrid Approach (Recommended in many cases)
-
Combine the strengths of both approaches.
-
Use UUIDs as primary keys for most tables for simplicity.
-
Add host_id to tables where data isolation is paramount (e.g., tables containing sensitive financial or personal data) or where frequent tenant-specific queries are performed. This provides a more granular level of control and allows for optimized queries when needed.
-
Use the tenant_resources_t table to maintain an overview of which resources belong to which tenant, supporting the application logic’s multi-tenancy enforcement.
Choosing the Right Strategy:
-
Small Number of Tenants, Low Data Volume: UUIDs might be sufficient.
-
Strict Data Isolation Requirements, Frequent Tenant-Specific Queries, High Data Volume: host_id on every relevant table or a hybrid approach is often preferable.
-
Flexibility in Multi-Tenancy Implementation: Favors the UUID approach or Hybrid approach, with logic predominantly handled in the application layer.
Additional Considerations:
-
Database Support: Check if database (PostgreSQL) has specific features for multi-tenancy.
-
Indexing: Carefully plan indexes for optimal performance in any multi-tenant scenario.
-
Schema Design: Consider creating views for tenant-specific data access to simplify queries in the application layer.
-
Security: Implement robust security measures to prevent data leakage between tenants, regardless of the chosen approach.
The hybrid approach usually provides the best balance between performance, data isolation, and development complexity in real-world multi-tenant applications. You have more direct control where strict isolation is required and can maintain the simplicity of UUIDs where it’s beneficial. Using tenant_resources_t for application logic enforcement offers flexibility and a central point of management for tenant resource association. This approach also prepares the application for potential future expansion and different multi-tenancy demands as the application grows.
Should host_id part of the PK
This is a classic multi-tenancy design question. Both approaches have implications. Let’s analyze them:
Option 1: Current Approach - PK (host_id, instance_id)
- Pros:
- Excellent for Tenant-Specific Queries: This is the biggest advantage. Queries like
SELECT ... FROM instance_t WHERE host_id = ? AND ...orSELECT ... FROM instance_t WHERE host_id = ? ORDER BY instance_idcan directly and efficiently use the primary key index. The index is naturally ordered by tenant first, then by instance within that tenant. This improves data locality for a specific tenant’s data. - Clear Logical Grouping: The primary key explicitly represents the concept that an instance belongs to a specific host (tenant).
- Enforces Uniqueness Per Tenant: Guarantees that
instance_idis unique within a givenhost_id. (Although UUIDv7 makes global collisions highly unlikely anyway).
- Excellent for Tenant-Specific Queries: This is the biggest advantage. Queries like
- Cons:
- Wider Primary Key: The PK is 32 bytes (16+16).
- Wider Foreign Keys: Any table referencing
instance_twould need bothhost_idandinstance_idas its foreign key columns. - Slightly Larger Secondary Indexes: Other indexes on
instance_twill implicitly include both PK columns, making them slightly larger than if the PK was just 16 bytes.
Option 2: Alternative - PK (instance_id)
- Pre-requisite: This only works if your application guarantees that
instance_idis globally unique across all hosts/tenants. Given you’re using UUIDv7, this is a safe assumption in practice, but the schema wouldn’t enforce uniqueness per host explicitly via the PK itself. - Pros:
- Narrower Primary Key: The PK is only 16 bytes.
- Simpler Foreign Keys: Tables referencing
instance_tonly need a singleinstance_idcolumn for the foreign key. - Slightly Smaller Secondary Indexes: Other indexes on the table will be marginally smaller.
- Cons:
- Requires Separate Index for Tenant Queries: You would absolutely need a separate index on
(host_id, instance_id)(or at least(host_id)) for efficient tenant-specific queries (WHERE host_id = ?). Without it, querying for a specific tenant’s data would require less efficient scans. This index would likely be aUNIQUEindex anyway to enforce the logical relationship:CREATE UNIQUE INDEX instance_t_host_instance_idx ON instance_t (host_id, instance_id); - Potential Reduced Locality: While the separate index helps, the primary key index itself (based only on
instance_id) might interleave data from different tenants physically, potentially slightly reducing cache efficiency for queries scanning many instances for a single tenant compared to the composite PK approach.
- Requires Separate Index for Tenant Queries: You would absolutely need a separate index on
Recommendation:
Stick with the composite primary key: PRIMARY KEY(host_id, instance_id).
Reasoning:
- Performance for Core Use Case: In multi-tenant systems, filtering by the tenant identifier (
host_id) is almost always the primary access pattern. Havinghost_idas the leading column in the PK index directly optimizes this critical path. - Index Necessity: Even if you chose
instance_idas the sole PK, you would still need to create an index on(host_id, instance_id)for performance. Making this essential index the primary key index is often the most straightforward and efficient approach. - Clarity: The composite key clearly reflects the logical relationship and ownership.
- Cost: The “cost” of a 32-byte PK vs. a 16-byte PK is often negligible compared to the performance gains achieved by aligning the PK index with the dominant query patterns in a multi-tenant architecture. The impact on FKs and secondary indexes is real but usually acceptable.
Using just instance_id as the PK prioritizes global uniqueness and FK simplicity over optimizing tenant-specific queries directly via the PK index. In most multi-tenant scenarios, optimizing tenant queries is more important.
Citus PostgreSQL Extension
Citus, now fully integrated into PostgreSQL as a distributed database extension, can be very helpful in scaling your multi-tenant application, especially if you anticipate significant data growth and high query loads. Here’s how Citus can fit into your use case and the factors to consider:
How Citus Helps:
-
Horizontal Scalability: Citus allows you to distribute the data across multiple PostgreSQL nodes (servers), enabling horizontal scaling. This is crucial for handling increasing data volumes and query loads in a multi-tenant environment.
-
Improved Query Performance: By distributing data and queries, Citus can significantly improve the performance of many types of queries, especially analytical queries that operate on large datasets. This is particularly beneficial if we have tenants with substantially different data volumes or query patterns.
-
Shard Placement by Tenant: One of the most effective ways to use Citus for multi-tenancy is to shard the data by host_id (or a tenant ID). This means that all data for a given tenant resides on the same shard (a subset of the distributed database). This allows for efficient tenant isolation and simplifies queries for tenant-specific data.
-
Simplified Multi-Tenant Queries: When sharding by tenant, queries that filter by host_id become very efficient because Citus can route them directly to the appropriate shard. This eliminates the need for expensive scans across the entire database.
-
Flexibility: Citus supports various sharding strategies, allowing you to choose the best approach for the data and query patterns. You can even use a hybrid approach, distributing some tables while keeping others replicated across all nodes for faster access to shared data.
Example (Sharding by Tenant):
Create a distributed table: When creating tables (e.g., user_t, api_endpoint_t, etc.), we would declare them as distributed tables in Citus, using the host_id as the distribution column:
CREATE TABLE user_t (
host_id UUID NOT NULL,
user_id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
-- ... other columns
) DISTRIBUTE BY HASH (host_id);
Querying: When querying data for a specific tenant, include the host_id in the WHERE clause:
SELECT * FROM users_t WHERE host_id = 'your-tenant-id';
Citus will automatically route this query to the shard containing the data for that tenant, resulting in much faster query execution.
Citus Cost:
-
Citus Open Source: The Citus open-source extension is free to use and is included in the PostgreSQL distribution. We can self-host and manage it.
-
Azure CosmosDB for PostgreSQL (Managed Citus): Microsoft offers a fully managed cloud service called Azure CosmosDB for PostgreSQL, which is built on Citus. This service has usage-based pricing, and the cost depends on factors like the number of nodes, storage, and compute resources used. This managed option reduces the operational overhead of managing Citus yourself.
Recommendation:
Don’t automatically add host_id to every table just because we are using Citus. Carefully analyze the data model, query patterns, and multi-tenancy requirements.
-
Distribute tables by host_id (tenant ID) when data locality and isolation are paramount, and we want to optimize tenant-specific queries.
-
Consider replicating smaller, frequently joined tables to avoid unnecessary joins and host_id overhead.
-
Use a central mapping table (tenant_resources_t) to manage tenant-resource associations and enforce multi-tenancy rules in the application logic where appropriate.
This more nuanced approach provides a balance between the benefits of distributed data with Citus and avoiding unnecessary complexity or performance overhead from overusing host_id. Choose the Citus deployment model (self-hosted open source or managed cloud service) that best suits our needs and budget.
Primary Key Considerations in a Distributed Citus Environment
When a table includes host_id (due to sharding requirements), it is important to include host_id as part of the primary key. This ensures proper functioning and optimization within the Citus distributed database.
-
Distribution Column Requirement
In Citus, the distribution column (e.g.,host_id) must be part of the primary key. This is essential for routing queries and distributing data correctly across shards. -
Uniqueness Enforcement
- The primary key enforces uniqueness across the entire distributed database.
- For example, if
user_idis unique only within a tenant (host), then(host_id, user_id)is required as the primary key to ensure uniqueness across all shards.
-
Data Locality and Co-location
Includinghost_idin the primary key ensures that all rows for the same tenant (identified by the samehost_id) are stored together on a single shard. This provides:- Efficient Joins: Joins between tables related to the same tenant can be performed locally on a single shard, avoiding expensive cross-shard data transfers.
- Optimized Queries: Queries filtering by
host_idare efficiently routed to the appropriate shard.
-
Referential Integrity
If other tables reference theusers_ttable and are also distributed byhost_id, includinghost_idin the primary key ofusers_tis essential to maintain referential integrity across shards.
Multi-Host User Session Management
In a multi-host environment where multiple hosts reside on the same server, users must associate with one host at a time. The session management is handled as follows:
-
Host Association on Login:
- Once a user logs in, a host cookie is returned, derived from the JWT token.
- The user’s session defaults to the associated host in the cookie.
-
Switching Hosts:
- If a user wishes to switch to another host, they can:
- Access the User Menu to select a different host.
- Log out of the current session.
- During the next login, the session will be tied to the newly selected host.
- If a user wishes to switch to another host, they can:
-
Host in API Requests:
- For all API requests sent to the server, the host is typically included as part of the request payload.
- For login users, the host is in the JWT token as a custom claim.
- For guest users, the default host is used until the user is signed in.
- This ensures proper routing and handling of requests in a multi-host environment.
By associating users to a specific host for each session, this approach ensures clear separation of data and responsibilities across hosts, while providing users the flexibility to switch hosts as needed.
Event Header
As the portal is based on the event sorucing, all events will be responsible for populating the database. So, they need to be separated by host_id as well. In the event header, we have one unique id which is generated when event is created. Also, it has host_id and user_id in the EventId which is included in every events.
Reference and Shared Tables
In an application there are some data that is shared by all tenants. For example, the dropdown options on the UI and business validation. We call them reference data and have defined several tables to manage them centrally. For each reference data type, there is a logical table defined in the ref_table_t and marked as common or not. Common means the table can be shared with other tenants. Otherwise, it is only private for the owner tenant.
Some other entities are very similar but they cannot be fit into the reference tables. For example, category_t table contains all the category definitions for different entities. These tables are designed with an optional host_id. Here is an exmaple.
CREATE TABLE category_t (
category_id VARCHAR(22) NOT NULL, -- unique id to identify the category
host_id VARCHAR(22), -- null mean global category
entity_type VARCHAR(50) NOT NULL, -- the version of the schema
category_name VARCHAR(126) NOT NULL, -- category name, must be url friendly.
category_desc VARCHAR(1024) NOT NULL, -- decription
parent_category_id VARCHAR(22) REFERENCES category_t(category_id) ON DELETE SET NULL, -- parent category id, null if there is no parent.
sort_order INT DEFAULT 0, -- sort order on the UI
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (category_id)
);
-- 1. Unique index for GLOBAL categories (where host_id IS NULL)
-- Ensures uniqueness of (entity_type, category_name, parent_category_id) ONLY when host_id is NULL
CREATE UNIQUE INDEX idx_category_unique_global
ON category_t (entity_type, category_name, parent_category_id)
NULLS NOT DISTINCT -- Handles NULLs in parent_category_id correctly
WHERE host_id IS NULL;
-- 2. Unique index for TENANT-SPECIFIC categories (where host_id IS NOT NULL)
-- Ensures uniqueness of (host_id, entity_type, category_name, parent_category_id)
-- for rows that belong to a specific host.
CREATE UNIQUE INDEX idx_category_unique_tenant
ON category_t (host_id, entity_type, category_name, parent_category_id)
NULLS NOT DISTINCT -- Handles NULLs in parent_category_id correctly
WHERE host_id IS NOT NULL;
CREATE INDEX idx_category_entity_type ON category_t (entity_type);
CREATE INDEX idx_category_parent ON category_t (parent_category_id);
CREATE INDEX idx_category_name ON category_t (category_name);
CREATE INDEX idx_category_host_id ON category_t (host_id);
On the UI, the host_id will be auto populated according to the associated host_id by the user in readonly mode. There is a checkbox “Is Global Category” in the form. If checked, the backend service will have an FGA rule to ensure that the user is admin and the host_id will be removed in the event. This works for both create and update.
When viewing categories, the super admin might see all categories by default, possibly with a column or indicator showing the host_id (or “Global”). Filters should allow viewing global only, or a specific tenant’s categories.
Tenant Admin / Host Owner:
When a tenant admin accesses the category management UI, their context is fixed to their own host_id.
They should only be able to create/edit categories associated with their specific host_id.
The UI should not offer them the option to create/edit global categories or categories for other hosts. The host_id is implicitly set or displayed as read-only based on their logged-in context.
When viewing categories, they should see their own tenant-specific categories plus all applicable global categories. The UI should clearly differentiate between these (e.g., using grouping, labels, icons).
System Integration
System integrations must preserve the same identity and tenant boundaries as interactive portal workflows. The integration token is not only an access credential; it is also the source of audit metadata, event metadata, row filtering, and host scoping.
Command Side
The command side uses event sourcing. Every accepted command writes one or more domain events, and those events are later projected into query-side tables. Because events become the durable system of record, command calls need a stable user identity and host identity.
For command APIs, use an authorization code token whenever possible. The token
must contain the real portal user id so command handlers can derive the correct
userId, host, nonce, and CloudEvent metadata. This is the preferred path for
browser flows, operator tools, and integrations that can act on behalf of a
known user.
If the integration has no user session in the request context, do not submit anonymous command events. First onboard a real user in the system for the integration actor or service account. That user becomes the durable audit principal for the commands emitted by the integration.
After the user is onboarded, create an auth client for the integration and set custom claims that carry the command identity:
{
"host": "<host-id>",
"elm": "<integration-user-email>",
"uid": "<integration-user-id>",
"uty": "<user-type>"
}
The uid claim must reference the onboarded user. The host claim must match
the tenant boundary where commands are allowed to run. The elm and uty
claims should match the onboarded user’s email and user type so downstream
authorization, audit, and support workflows can identify the actor without
guessing.
For an integration auth client whose type is trusted, the client application can
call Light OAuth with the client_credentials grant type when the auth client
has these custom claims configured. Light OAuth issues a token that carries the
custom claims, allowing the token to act as an id-token-like access token for
command APIs, similar to the user-bearing token produced by the authorization
code grant. This path is only acceptable for trusted client types because the
client, not an interactive browser session, is asserting the user and host
identity through the auth client configuration.
Command-side integration rules:
- Prefer an authorization code token tied to the real interactive user.
- Use a dedicated onboarded integration user only when no user session exists.
- For non-session integrations, use a trusted auth client with custom claims and
request the token from Light OAuth with
grant_type=client_credentials. - Do not use a token that lacks a usable
userId/uidfor event-sourced commands. - Do not allow non-trusted clients to mint user-bearing command tokens from client credentials.
- Keep host ownership explicit; never infer host scope from the client id alone.
- Treat the auth client and custom claims as deployment configuration, not as a substitute for user onboarding.
Query Side
The query side serves read models built from command-side events and operational tables. Query APIs do not create domain events, do not allocate command nonces, and should not mutate event-sourced state.
Query integrations still need authorization and tenant scoping. The request token must provide enough identity to determine the host and the effective user or service account. For user-scoped reads, use the same authorization code token or integration-user token described for the command side so row and column filters can apply consistently.
If authorization code flow is not available for a query integration, the
client_credentials flow is acceptable only for auth clients whose type is
trusted. The token must carry host, sid, and, when environment-specific data
is requested, env. Here sid is the service id for the gateway, agent, or
other Light-Fabric runtime calling portal-query. Query handlers must compare
these claims with the requested hostId, serviceId, and optional envTag
before returning service-scoped data.
Light-Fabric ecosystem components such as gateways and agents may use a
long-lived token for query-side access when the token was issued through this
trusted client_credentials path. That access is not general portal read
access. It is limited to query endpoints built for those runtime components,
such as gateway, agent, discovery, or catalog endpoints, and those endpoints
must enforce the claim match before returning data.
For host-scoped or service-level reads, a client token can be used only when the auth client type is trusted and the token carries the required host, service, and environment claims. The query service should apply the same host boundary as the command side and return only data visible to that actor. A missing user session may reduce the allowed result set, but it must not broaden access.
Query-side integration rules:
- Read from projected/query tables; do not write command events from query handlers.
- Resolve host scope from the validated token claims and request parameters.
- When authorization code flow is unavailable, accept
client_credentialsonly from auth clients whose type is trusted. - Require
hostandsidtoken claims; requireenvwhen the endpoint or request is environment-scoped. - Match token
host,sid, and optionalenvto requestedhostId,serviceId, and optionalenvTag. - Allow long-lived Light-Fabric runtime tokens only on endpoints designed for gateways, agents, and similar ecosystem components.
- Do not use long-lived runtime tokens for broad user-facing query access.
- Apply user, role, position, group, attribute, and fine-grained filters when the endpoint requires them.
- Use the onboarded integration user for auditability when a human user is not present.
- Keep query tokens least-privileged; read-only integrations should not receive command scopes.
Portal Event
Light Portal is using event sourcing and CQRS. Any update to the system will generate an event and there are hundreds of event types.
All events are in Avro format and will be pushed to a Kafka cluster for stream processing. Each event has an EventId that contains common info for events and it is reside in light-kafka repo.
Here is one of the events in the light-portal.
{
"type": "record",
"name": "ApiRuleCreatedEvent",
"namespace": "net.lightapi.portal.market",
"fields": [
{
"name": "EventId",
"type": {
"type": "record",
"name": "EventId",
"namespace": "com.networknt.kafka.common",
"fields": [
{
"name": "id",
"type": "string",
"doc": "a unique identifier"
},
{
"name": "nonce",
"type": "long",
"doc": "the number of the transactions for the user"
},
{
"name": "timestamp",
"type": "long",
"default": 0,
"doc": "time the event is recorded"
},
{
"name": "derived",
"type": "boolean",
"default": false,
"doc": "indicate if the event is derived from event processor"
}
]
}
},
{
"name": "hostId",
"type": "string",
"doc": "host id"
},
{
"name": "apiId",
"type": "string",
"doc": "api id"
},
{
"name": "ruleIds",
"type": {
"type": "array",
"items": "string"
},
"doc": "one or many rule ids that link to the apiId"
}
]
}
Kafka Key
When pushing events into a Kafka topic, the record key will be used to distribute record between different Kafka partitions. Here is the key selection for the system.
- multi-tenent
The key will be the hostId
- single-tenent
The key will be the userId
Promotion or Replay
Promotion approaches
- When promote from dev to sit, we can export all event from dev and update the event json file and then replay to the sit.
- We can import the original event json from dev to sit and then update some on the sit host.
Promotable Event Type
There are two type of events: configurable event vs transactional event. We should only promote the configurable events from dev to sit. Not the deployment logs from dev to sit. We need a table to define the promotable event types.
Reference Table
When building a web application, there would be a lot of dropdown selects in forms. The form itself only cares about the id and label list to render the form and only the id will be submitted to the backend API for single select and several ids for multiple select.
To save the effort to create many similar tables, we can craete a set of tables for all dropdowns. For some of the reference tables, dropdown should be the same across all hosts and we can set common flag to ‘Y’ so that they are shared by all hosts. If the dropdown values might be different between hosts, we can create a reference table per host and link the reference table with host in a separate table that support sharding.
Reference Schema
CREATE TABLE ref_host_t (
table_id VARCHAR(22) NOT NULL,
host_id VARCHAR(22) NOT NULL,
PRIMARY KEY (table_id, host_id),
FOREIGN KEY (table_id) REFERENCES ref_table_t (table_id) ON DELETE CASCADE,
FOREIGN KEY (host_id) REFERENCES host (host_id) ON DELETE CASCADE
);
CREATE TABLE ref_table_t (
table_id VARCHAR(22) NOT NULL, -- UUID genereated by Util
table_name VARCHAR(80) NOT NULL, -- Name of the ref table for lookup.
table_desc VARCHAR(1024) NULL,
active CHAR(1) NOT NULL DEFAULT 'Y', -- Only active table returns values
editable CHAR(1) NOT NULL DEFAULT 'Y', -- Table value and locale can be updated via ref admin
common CHAR(1) NOT NULL DEFAULT 'Y', -- The drop down shared across hosts
PRIMARY KEY(table_id)
);
CREATE TABLE ref_value_t (
value_id VARCHAR(22) NOT NULL,
table_id VARCHAR(22) NOT NULL,
value_code VARCHAR(80) NOT NULL, -- The dropdown value
start_time TIMESTAMP NULL,
end_time TIMESTAMP NULL,
display_order INT, -- for editor and dropdown list.
active VARCHAR(1) NOT NULL DEFAULT 'Y',
PRIMARY KEY(value_id),
FOREIGN KEY table_id REFERENCES ref_table_t (table_id) ON DELETE CASCADE
);
CREATE TABLE value_locale_t (
value_id VARCHAR(22) NOT NULL,
language VARCHAR(2) NOT NULL,
value_desc VARCHAR(256) NULL, -- The drop label in language.
PRIMARY KEY(value_id,language),
FOREIGN KEY value_id REFERENCES ref_value_t (value_id) ON DELETE CASCADE
);
CREATE TABLE relation_type_t (
relation_id VARCHAR(22) NOT NULL,
relation_name VARCHAR(32) NOT NULL, -- The lookup keyword for the relation.
relation_desc VARCHAR(1024) NOT NULL,
PRIMARY KEY(relation_id)
);
CREATE TABLE relation_t (
relation_id VARCHAR(22) NOT NULL,
value_id_from VARCHAR(22) NOT NULL,
value_id_to VARCHAR(22) NOT NULL,
active VARCHAR(1) NOT NULL DEFAULT 'Y',
PRIMARY KEY(relation_id, value_id_from, value_id_to)
FOREIGN KEY relation_id REFERENCES relation_type_t (relation_id) ON DELETE CASCADE,
FOREIGN KEY value_id_from REFERENCES ref_value_t (value_id) ON DELETE CASCADE,
FOREIGN KEY value_id_to REFERENCES ref_table_t (value_id) ON DELETE CASCADE
);
Authentication & Authorization
Light-Portal is a single-page application (SPA) that utilizes both the OAuth 2.0 Authorization Code and Client Credentials flows.
The following pattern illustrates the end-to-end process recommended by the Light Platform for an SPA interacting with downstream APIs.
Sequence Diagram
sequenceDiagram
participant PortalView as Portal View
participant LoginView as Login View
participant Gateway as Light Gateway
participant OAuthKafka as OAuth-Kafka
participant AuthService as Auth Service
participant ProxySidecar as Proxy Sidecar
participant BackendAPI as Backend API
PortalView ->> LoginView: 1. Signin redirect
LoginView ->> OAuthKafka: 2. Authenticate user
OAuthKafka ->> AuthService: 3. Authenticate User<br/>(Active Directory<br/>for Employees)<br/>(CIF System<br/>for Customers)
AuthService ->> OAuthKafka: 4. Authenticated
OAuthKafka ->> OAuthKafka: 5. Generate auth code
OAuthKafka ->> PortalView: 6. Redirect with code
PortalView ->> Gateway: 7. Authorization URL<br/>with code param
Gateway ->> OAuthKafka: 8. Create JWT access<br/>token with code
OAuthKafka ->> OAuthKafka: 9. Generate JWT<br/>access token<br/>with user claims
OAuthKafka ->> Gateway: 10. Token returns<br/>to Gateway
Gateway ->> PortalView: 11. Token returns<br/>to Portal View<br/>in Secure Cookie
PortalView ->> Gateway: 12. Call Backend API
Gateway ->> Gateway: 13. Verify the token
Gateway ->> OAuthKafka: 14. Create Client<br/>Credentials token
OAuthKafka ->> OAuthKafka: 15. Generate Token<br/>with Scopes
OAuthKafka ->> Gateway: 16. Return the<br/>scope token
Gateway ->> Gateway: 17. Add scope<br/>token to<br/>X-Scope-Token<br/>Header
Gateway ->> ProxySidecar: 18. Invoke API
ProxySidecar ->> ProxySidecar: 19. Verify<br/>Authorization<br/>token
ProxySidecar ->> ProxySidecar: 20. Verify<br/>X-Scope-Token
ProxySidecar ->> ProxySidecar: 21. Fine-Grained<br/>Authorization
ProxySidecar ->> BackendAPI: 22. Invoke<br/>business API
BackendAPI ->> ProxySidecar: 23. Business API<br/>response
ProxySidecar ->> ProxySidecar: 24. Fine-Grained<br/>response filter
ProxySidecar ->> Gateway: 25. Return response
Gateway ->> PortalView: 26. Return response
-
When a user visits the website to access the single-page application (SPA), the Light Gateway serves the SPA to the user’s browser. Each single page application will have a dedicated Light Gateway instance acts as a BFF. By default, the user is not logged in and can only access limited site features. To unlock additional features, the user can click the
Userbutton in the header and select theSign Inmenu. This action redirects the browser from the Portal View to the Login View, both served by the same Light Gateway instance. -
On the Login View page, the user can either input a username and password or choose Google/Facebook for authentication. When the login form is submitted, the request is sent to the Light Gateway with the user’s credentials. The Gateway forwards this request to the OAuth Kafka service.
-
OAuth Kafka supports multiple authenticator implementations to verify user credentials. Examples include authenticating via the Light Portal user database, Active Directory for employees, or CIF service for customers.
-
Once authentication is successfully completed, the OAuth Kafka responds with the authentication result.
-
Upon successful authentication, OAuth Kafka generates an authorization code (a UUID associated with the user’s profile).
-
OAuth Kafka redirects the authorization code back to the browser at the Portal View via the Gateway.
-
Since the Portal View SPA lacks a dedicated redirect route for the authorization code, the browser sends the code as a query parameter in a request to the Gateway.
-
The
StatelessAuthHandlerin the Gateway processes this request, initiating a token request to OAuth Kafka to obtain a JWT access token. -
OAuth Kafka generates an access token containing user claims in its custom JWT claims. The authorization code is then invalidated, as it is single-use.
-
The access token is returned to the Gateway.
-
The
StatelessAuthHandlerin the Gateway stores the access token in a secure cookie and sends it back to the Portal View. -
When the Portal View SPA makes requests to backend APIs, it includes the secure cookie in the API request sent to the Gateway.
-
The
StatelessAuthHandlerin the Gateway validates the token in the secure cookie and places it in theAuthorizationheader of the outgoing request. -
If the token is successfully validated, the
TokenHandlerin the Gateway makes a request to OAuth Kafka for a client credentials token, using the path prefix of the API endpoint. -
OAuth Kafka generates a client credentials token with the appropriate scope for accessing the downstream service.
-
The client credentials token is returned to the Gateway.
-
The
TokenHandlerin the Gateway inserts this token into theX-Scope-Tokenheader of the original request. -
The Gateway routes the original request, now containing both tokens, to the downstream
proxy sidecarof the backend API. -
The proxy sidecar validates the
Authorizationtoken, verifying its signature, expiration, and other attributes. -
The proxy sidecar also validates the
X-Scope-Token, ensuring its signature, expiration, and scope are correct. -
Once both tokens are successfully validated, the proxy sidecar enforces fine-grained authorization rules based on the user’s custom security profile contained in the
Authorizationtoken. -
If the fine-grained authorization checks are passed, the proxy sidecar forwards the request to the backend API.
-
The backend API processes the request and sends the full response back to the
proxy sidecar. -
The proxy sidecar applies fine-grained filters to the response, reducing the number of rows and/or columns based on the user’s security profile or other policies.
-
The proxy sidecar returns the filtered response to the Gateway.
-
The Gateway forwards the response to the Portal View, allowing the SPA to render the page.
Fine-Grained Authorization
What is Fine-Grained Authorization?
Fine-grained authorization (FGA) refers to a detailed and precise control mechanism that governs access to resources based on specific attributes, roles, or rules. It’s also known as fine-grained access control (FGAC). Unlike coarse-grained authorization, which applies broader access policies (e.g., “Admins can access everything”), fine-grained authorization allows for more specific policies (e.g., “Admins can access user data only if they belong to the same department and the access request is during business hours”).
Key Features
- Granular Control: Policies are defined at a detailed level, considering attributes like user role, resource type, action, time, location, etc.
- Context-Aware: Takes into account dynamic conditions such as the time of request, user’s location, or other contextual factors.
- Flexible Policies: Allows the creation of complex, conditional rules tailored to the organization’s needs.
Why Do We Need Fine-Grained Authorization?
1. Enhanced Security
By limiting access based on detailed criteria, fine-grained authorization minimizes the risk of unauthorized access or data breaches.
2. Regulatory Compliance
It helps organizations comply with legal and industry-specific regulations (e.g., GDPR, HIPAA) by ensuring sensitive data is only accessible under strict conditions.
3. Minimized Attack Surface
By restricting access to only the required resources and operations, fine-grained authorization reduces the potential impact of insider threats or compromised accounts.
4. Improved User Experience
Enables personalized access based on roles and permissions, ensuring users see only what they need, which reduces confusion and improves productivity.
5. Auditing and Accountability
Detailed access logs and policy enforcement make it easier to track and audit who accessed what, when, and why, fostering better accountability.
Examples of Use Cases
- Healthcare: A doctor can only view records of patients they are treating.
- Government: A government employee can access to data and documents based on security clearance levels and job roles.
- Finance: A teller can only access transactions related to their assigned branch.
- Enterprise Software: Employees can edit documents only if they own them or have been granted editing permissions.
Fine-Grained Authorization in API Access Control
In API access control, fine-grained authorization governs how users or systems interact with specific API endpoints, actions, and data. This approach ensures that access permissions are precisely tailored to attributes, roles, and contextual factors, enabling a secure and customized API experience. As the Light Portal is a platform centered on APIs, the remainder of the design will focus on the API access control context.
Early Approaches to Fine Grained Authorization
Early approaches to fine grained authorization primarily involved Access Control Lists (ACLs) and Role-Based Access Control (RBAC). These methods laid the foundation for more sophisticated access control mechanisms that followed. Here’s an overview of these primary approaches:
Access Control Lists (ACLs):
-
ACLs were one of the earliest forms of fine grained authorization, allowing administrators to specify access permissions on individual resources for each user or group of users.
-
In ACLs, permissions are directly assigned to users or groups, granting or denying access to specific resources based on their identities.
-
While effective for small-scale environments with limited resources and users, ACLs became cumbersome as organizations grew. Maintenance issues arose, such as the time required to manage access to an increasing number of resources for numerous users.
Role-Based Access Control (RBAC):
-
RBAC emerged as a solution to the scalability and maintenance challenges posed by ACLs. It introduced the concept of roles, which represent sets of permissions associated with particular job functions or responsibilities.
-
Users are assigned one or more roles, and their access permissions are determined by the roles they possess rather than their individual identities.
-
RBAC can be implemented with varying degrees of granularity. Roles can be coarse-grained, providing broad access privileges, or fine-grained, offering more specific and nuanced permissions based on organizational needs.
-
Initially, RBAC appeared to address the limitations of ACLs by providing a more scalable and manageable approach to access control.
Both ACLs and RBAC have their shortcomings:
-
Maintenance Challenges: While RBAC offered improved scalability compared to ACLs, it still faced challenges with role management as organizations expanded. The proliferation of roles, especially fine grained ones, led to a phenomenon known as role explosion where the number of roles grew rapidly, making them difficult to manage effectively.
-
Security Risks: RBAC’s flexibility also posed security risks. Over time, users might accumulate permissions beyond what they need for their current roles, leading to a phenomenon known as permission creep. This weakened overall security controls and increased the risk of unauthorized access or privilege misuse.
Following the discussion of early approaches to fine grained authorization, it’s crucial to acknowledge that different applications have varying needs for authorization.
Whether to use fine grained or coarse-grained controls depends on the specific project. Controlling access becomes trickier due to the spread-out nature of resources and differing levels of detail needed across components. Let’s delve into the differentiating factors:
Standard Models for Implementing FGA
There are several standard models for implementing FGA:
-
Attribute-Based Access Control (ABAC): In ABAC, access control decisions are made by evaluating attributes such as user roles, resource attributes (e.g., type, size, status), requested action, current date and time, and any other relevant contextual information. ABAC allows for very granular control over access based on a wide range of attributes. -
Policy-Based Access Control (PBAC): PBAC is similar to ABAC but focuses more on defining policies than directly evaluating attributes. Policies in PBAC typically consist of rules or logic that dictate access control decisions based on various contextual factors. While ABAC relies heavily on data (attributes), PBAC emphasizes using logic to determine access. -
Relationship-Based Access Control (ReBAC): ReBAC emphasizes the relationships between users and resources, as well as relationships between different resources. By considering these relationships, ReBAC provides a powerful and expressive model for describing complex authorization contexts. This can involve the attributes of users and resources and their interactions and dependencies.
Each of these models offers different strengths and may be more suitable for different scenarios. FGA allows for fine grained control over access, enabling organizations to enforce highly specific access policies tailored to their requirements.
Streamlining FGA by Implementing Rule-Based Access Control:
ABAC (Attribute-Based Access Control) focuses on data attributes, PBAC (Policy-Based Access Control) centers on logic, and ReBAC (Relationship-Based Access Control) emphasizes relationships between users and resources. But what if we combined all three to leverage the strengths of each? This is the idea behind Rule-Based Access Control (RuBAC).
By embedding a lightweight rule engine, we can integrate multiple rules and actions to achieve the following:
-
Optimize ABAC: Reduce the number of required attributes since not all rules depend on them. For example, a standard rule like “Customer data can only be accessed during working hours” can be shared across policies.
-
Flexible Policy Enforcement: Using a rule engine makes access policies more dynamic and simpler to manage.
-
Infer Relationships: Automatically deduce relationships between entities. For instance, the rule engine could grant a user access to a file if they already have permission for the containing folder.
Principle of Least Privilege
The principle of least privilege access control widely referred to as least privilege, and PoLP is the security concept in which user(s) (employee(s)) are granted the minimum level of access/permissions to the app, data, or system that is required to perform his/her job functions.
To ensure PoLP is effectively enforced, we’ve compiled a list of best practices:
-
Conduct a thorough privilege audit: As we know, visibility is critical in an access environment, so conducting regular or periodic access audits of all privileged accounts can help your team gain complete visibility. This audit includes reviewing privileged accounts and credentials held by employees, contractors, and third-party vendors, whether on-premises, accessible remotely, or in the cloud. However, your team must also focus on default and hard-coded credentials, which IT teams often overlook.
-
Establish the least privilege as the default: Start by granting new accounts the minimum privileges required for their tasks and eliminate or reconfigure default permissions on new systems or applications. Further, use role-based access control to help your team determine the necessary privileges for a new account by providing general guidelines based on roles and responsibilities. Also, your team needs to update and adjust access level permissions when the user’s role changes; this will help prevent privilege creep.
-
Enforce separation of privileges: Your team can prevent over-provisioning by limiting administrator privileges. Firstly, segregate administrative accounts from standard accounts, even if they belong to the same user, and isolate privileged user sessions. Then, grant administrative privileges (such as read, write, and execute permissions) only to the extent necessary for the user to perform their specific administrative tasks. This will help your team prevent granting users unnecessary or excessive control over critical systems, which could lead to security vulnerabilities or misconfigurations.
-
Provide just-in-time, limited access: To maintain least-privilege access without hindering employee workflows, combine role-based access control with time-limited privileges. Further, replace hard-coded credentials with dynamic secrets or use one-time-use/temporary credentials. This will help your team grant temporary elevated access permissions when users need it, for instance, to complete specific tasks or short-term projects.
-
Keep track and evaluate privileged access: Continuously monitor authentications and authorizations across your API platform and ensure all the individual actions are traceable. Additionally, record all authentication and authorizaiton sessions comprehensively, and use automated tools to swiftly identify any unusual activity or potential issues. These best practices are designed to enhance the security of your privileged accounts, data, and assets while ensuring compliance adherence and improving operational security without disrupting user workflows.
OpenAPI Specification Extensions
OpenAPI uses the term security scheme for authentication and authorization schemes. OpenAPI 3.0 lets you describe APIs protected using the following security schemes. The fine-grained authorization is just another layer of security and it is natural to define the fine-grained authorization in the same specification. It can be done with OpenAPI specification extensions.
Extensions (also referred to as specification extensions or vendor extensions) are custom properties that start with x-, such as x-logo. They can be used to describe extra functionality that is not covered by the standard OpenAPI Specification. Many API-related products that support OpenAPI make use of extensions to document their own attributes, such as Amazon API Gateway, ReDoc, APIMatic and others.
As OpenAPI specification openapi.yaml is loaded during the light-4j startup, the extensions will be available at runtime in cache for each endpoint just like the scopes definition. The API owner can define the following two extensions for each endpoint:
-
x-request-access: This section allows designer to specify one or more rules as well as one or more security attributes for the input of the rules. For example, roles, location etc. The rule result will decide if the user has access to the endpoint based on the security attributes from the JWT token in the request chain.
-
x-response-filter: This section is similar to the above; however, it works on the response chain. The rule result will decide which row or column of the response JSON will return to the user based on the security profile from the JWT token.
Example of OpenAPI specification with fine-grained authorization.
paths:
/accounts:
get:
summary: "List all accounts"
operationId: "listAccounts"
x-request-access:
rule: "account-cc-group-role-auth"
roles: "manager teller customer"
x-response-filter:
rule: "account-row-filter"
teller:
status: open
customer:
status: open
owner: @user_id
rule: "account-col-filter"
teller: ["num","owner","type","firstName","lastName","status"]
customer: ["num","owner","type","firstName","lastName"]
security:
- account_auth:
- "account.r"
FGA Rules for AccessControlHandler
With the above specification loaded during the runtime, the rules will be loaded during the server startup for the service as well. In the Rule Registry on the light-portal, we have a set of built-in rules that can be picked as fine-grained policies for each API. Here is an example of rule for the above specification in the x-request-access.
account-cc-group-role-auth:
ruleId: account-cc-group-role-auth
host: lightapi.net
description: Role-based authorization rule for account service and allow cc token and transform group to role.
conditions:
- conditionId: allow-cc
variableName: auditInfo
propertyPath: subject_claims.ClaimsMap.user_id
operatorCode: NIL
joinCode: OR
index: 1
- conditionId: manager
variableName: auditInfo
propertyPath: subject_claims.ClaimsMap.groups
operatorCode: CS
joinCode: OR
index: 2
conditionValues:
- conditionValueId: manager
conditionValue: admin
- conditionId: teller
variableName: auditInfo
propertyPath: subject_claims.ClaimsMap.groups
operatorCode: CS
joinCode: OR
index: 3
conditionValues:
- conditionValueId: teller
conditionValue: frontOffice
- conditionId: allow-role-jwt
variableName: auditInfo
propertyPath: subject_claims.ClaimsMap.roles
operatorCode: NNIL
joinCode: OR
index: 4
actions:
- actionId: match-role
actionClassName: com.networknt.rule.FineGrainedAuthAction
actionValues:
- actionValueId: roles
value: $roles
All rules are managed by the light-portal and shared by all the services. In addition, developers can create their customized rules for their own services.
Response Filter
There are two type of filters. Row and Column.
Row
For row filter, we need to check the condition defined for some of the properties in order to make the filter decision. In database, for each endpoint, we have colName, operator and colValue defined for the condition.
The operator supports the following enum: [“=”,“!=”,“<”,“>”,“<=”,“>=”,“in”,“not in”, “range”]
For the colValue, we do support variables from the jwt token with @. For example, @eid will be replaced with the eid claim from the jwt token.
Col
For column filter, we need to include a list of columns or exclude a list of columns in json format.
[“accountNo”,“firstName”,“lastName”]
or
![“status”]
Light Portal Fine-Grained Authorization
Overview
The existing fine-grained authorization model describes how Light Portal manages access control for APIs and MCP tools owned by customers. This document applies the same ideas to Light Portal itself.
Light Portal has two different authorization surfaces:
- the browser application, where menus, routes, tasks, and action buttons decide what the user can discover and click
- the backend portal handlers, where query and command services read or mutate tenant data
The browser must improve usability by hiding irrelevant admin menus, but it must not be the security boundary. The security boundary must be enforced by the gateway and by the portal query and command handlers.
Goals
- Limit admin menus based on the user’s roles, positions, groups, and attributes.
- Let
adminaccess all eligible admin pages for data within all hosts. - Let a
host-adminaccess all eligible admin pages for data within the current tenant host only. - Keep global platform administration separate from tenant administration.
- Enable request access control (
req-acc) and response filtering (res-fil) for Light Portal hybrid handlers. - Use
owner_user_idandowner_position_idas the primary row ownership model for self-service admin pages. - Keep authorization rules declarative enough that they can be managed from the existing rule and access-control pages.
Non-Goals
- Do not rely on menu hiding as authorization.
- Do not make
host-admina global portal super admin. - Do not replace existing host scoping with ownership scoping. Host scoping remains mandatory.
- Do not require every portal table to be migrated before the model can be rolled out.
- Do not duplicate every rule in React. React should consume an effective menu and capability model from the backend over time.
Recommended Model
Use three layers.
| Layer | Purpose | Enforcement |
|---|---|---|
| Menu and route visibility | Usability and discoverability | portal-view hides menus and blocks client routes |
| Handler request access | Decide whether a user may call a query or command service/action | light-gateway req-acc for /portal/query and /portal/command |
| Data scope and response filtering | Decide which tenant rows and fields the user may see or mutate | service-side owner predicates and gateway/service res-fil |
This keeps the user experience responsive without trusting the browser.
Roles And Scopes
Separate page access from row scope.
| Role or claim | Meaning | Page access | Data scope |
|---|---|---|---|
admin | global portal administrator | all portal admin pages | all hosts, only for global administration |
host-admin | tenant administrator | tenant-safe admin pages | current hostId only |
access-admin | tenant access-control administrator | access-control administration pages | current hostId only |
<entity>-admin | entity-specific administrator, such as api-admin or instance-admin | pages for that entity | current hostId, all rows for that entity |
user | self-service user | approved self-service pages | owned rows only |
| positions claim | team or org-unit membership | does not grant pages by itself unless mapped by rule | rows owned by matching effective positions |
| groups and attributes | additional authorization dimensions | rule-dependent | rule-dependent |
The important distinction is that host-admin is powerful inside one tenant but
must not bypass host ownership. If the current session host is
01964b05-..., every query and command still needs that hostId enforced.
Host Admin
host-admin should be the standard tenant administrator role.
A host-admin can:
- see tenant administration menus that are safe within the current host
- query all records whose
host_idis the current session host - create and update tenant-scoped records for the current host
- assign ownership inside the current host when the command supports it
A host-admin cannot:
- access another
hostIdby changing a request payload - manage global reference data unless explicitly granted a global role
- manage platform deployment records that are not tenant scoped
- manage access-control policy unless explicitly granted
access-admininside the current host - bypass command-specific invariants, such as optimistic concurrency checks
Backend handlers must treat hostId from the request as untrusted. The trusted
tenant comes from the authenticated audit context or from a verified user-host
membership lookup.
Access Administration
Access-control administration is separate from general tenant administration.
Changing role, group, position, attribute, row-filter, or column-filter policy
can change who may read or mutate tenant data, so it should require
access-admin within the current host instead of being implied by host-admin.
An access-admin can manage policy for tenant-owned APIs, apps, clients,
instances, workflows, schemas, schedules, and other tenant-scoped assets in the
current host. An access-admin cannot manage global platform policy unless the
user also has the global admin role.
This keeps host-admin useful for normal tenant operations while preserving
separation of duties for security policy changes.
Platform And Tenant Deployment Pages
Deployment administration should be split into tenant deployment pages and global platform pages.
Tenant deployment pages can be visible to host-admin when every operation is
scoped to the current hostId, such as deploying tenant APIs, checking route
health, or managing tenant client registrations.
Global platform pages must require admin. These pages manage shared
infrastructure, gateway clusters, physical deployment targets, shared database
configuration, or cross-host platform state. They must not be exposed through a
tenant-scoped host-admin rule.
Menu Authorization
The current sidebar already supports role-based visibility with exact role
tokens and treats admin and host-admin as broad admin roles. The design
should evolve this into a backend-driven capability model.
Phase 1: Local Menu Policy
Keep a local page registry in portal-view, but normalize it around page
capabilities.
{
id: "api-admin",
route: "/app/service/admin",
requiredAny: ["admin", "host-admin", "api-admin", "user"],
scope: "owner-or-host",
entity: "api"
}
The UI can show:
- all admin menus for
admin - tenant-safe admin menus for
host-admin - entity menus for
<entity>-admin - approved self-service menus for
user
Menus with no explicit rule inside the Administration group should not be shown to normal users.
Phase 2: Backend Menu Policy
Add a backend query such as:
lightapi.net/portal/getEffectiveMenu/0.1.0
or:
lightapi.net/portal/getEffectiveCapabilities/0.1.0
The response should contain route-level capabilities, not raw policy internals.
{
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f",
"pages": [
{
"pageId": "api-admin",
"route": "/app/service/admin",
"visible": true,
"readScope": "owned",
"writeScope": "owned"
},
{
"pageId": "instance-admin",
"route": "/app/instance/InstanceAdmin",
"visible": true,
"readScope": "host",
"writeScope": "host"
}
]
}
The sidebar, task launcher, command palette, and route guards should consume the same capability response.
Request Access For Portal Handlers
Light Portal uses hybrid RPC-style endpoints:
POST /portal/query
POST /portal/command
The request body identifies the logical handler:
{
"host": "lightapi.net",
"service": "service",
"action": "getApi",
"version": "0.1.0",
"data": {
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f"
}
}
For req-acc, the gateway must authorize the logical service id, not only the
HTTP path. The effective route key should be derived as:
lightapi.net/{service}/{action}/{version}
Example:
lightapi.net/service/getApi/0.1.0
lightapi.net/service/createApi/0.1.0
lightapi.net/role/createRolePermission/0.1.0
This lets the access-control registry treat portal handlers exactly like API operations.
Request Context
The req-acc rule context should include:
{
"serviceId": "lightapi.net/service/createApi/0.1.0",
"transport": "hybrid",
"portal": true,
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f",
"entity": "api",
"action": "create",
"jwt": {
"userId": "01964b05-5532-7c79-8cde-191dcbd421b8",
"roles": ["user", "api-admin"],
"positions": ["team-api"],
"groups": ["engineering"],
"attributes": {
"department": "platform"
}
},
"requestData": {
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f"
}
}
Recommended built-in request rules:
| Rule | Purpose |
|---|---|
portal-admin-global | allow admin for global admin handlers |
portal-host-admin | allow host-admin only when requestData.hostId matches the session host |
portal-access-admin | allow access-admin for tenant access-control handlers in the current host |
portal-entity-admin | allow <entity>-admin for entity handlers in the current host |
portal-owner-read | allow user to call approved read handlers; row scope is applied later |
portal-owner-write | allow user to call approved write handlers only when ownership can be verified |
Response Filtering For Portal Handlers
Response filtering has two jobs:
- remove rows that are outside the caller’s authorized scope
- optionally remove columns the caller should not see
For list queries, service-side SQL filtering is preferred over gateway-only
filtering because it protects pagination, counts, and performance. The gateway
or common service layer can still apply res-fil as a defense-in-depth step.
Recommended order:
req-accdecides whether the user may call the logical handler.- Query handler injects host and owner predicates into SQL.
- Query handler returns only authorized rows and an authorized total.
- Shared query serialization or service-side
res-filremoves rows only when it can also preserve authorized pagination totals. - Gateway
res-filremoves sensitive fields and can perform defense-in-depth row removal for non-paginated responses. - Portal-view renders the already-authorized result.
Gateway-only row filtering must not be the primary implementation for paginated
lists. If rows are removed after the backend has already computed total,
offset, or limit, the grid metadata becomes inaccurate. Row predicates
belong in SQL or in shared query serialization that controls both the returned
rows and the total count. Column filtering can run in the gateway because it
does not change pagination.
For command handlers, response filtering is less important than request authorization and command-side ownership checks. A command must verify that the target aggregate belongs to the current host and that the caller can mutate it.
Owner Position
The owner model should prefer explicit owner fields:
owner_user_id
owner_position_id
owner_user_id is assigned from the authenticated user on create. Normal forms
should not submit it.
owner_position_id lets a team or org unit own a record. Users with an
effective matching position can see or manage the record when the page rule
allows owner-scoped access.
Owner assignments must always remain inside the current host. When a command
sets or transfers owner_user_id or owner_position_id, the command handler
must verify that the target user or position belongs to the trusted session
hostId. The browser-supplied owner value is not enough. Cross-host owner
assignment must be rejected even when the caller has host-admin for the
current host.
Owner changes are security-sensitive events. Create, transfer, and clear
operations for owner_user_id or owner_position_id must be written to the
audit log with the old owner, new owner, entity id, trusted host, acting user,
and logical portal service id.
For owner-scoped reads, the service predicate should be:
AND (
owner_user_id = :currentUserId
OR owner_position_id = ANY(:effectivePositions)
)
If the database dialect does not support array binding, use an IN list with
validated position ids. Owner-scoped tables should index host and owner columns
together, such as (host_id, owner_user_id) and
(host_id, owner_position_id), so owner predicates remain efficient.
Rows with both owner fields null are unassigned legacy rows. They should be
visible only to all-scope roles such as admin, host-admin, or an applicable
<entity>-admin until ownership is assigned.
Effective Positions
The JWT may contain direct positions, but direct positions are not always enough. The service should resolve effective positions from:
- direct position claims in the token
user_position_t- position inheritance rules when enabled
The effective set should be computed in one shared utility and reused by query
and command handlers. Existing OwnerScopeUtil is the right direction for query
handlers; it should become the standard path rather than a page-specific helper.
Position inheritance should not be recursively expanded inside every portal
query. Materialize the transitive closure in a table such as
position_closure_t and refresh it when position relationships change, or cache
the user’s flat effective-position set in session state and invalidate it when
membership changes. The query layer should receive a bounded, validated list of
effective positions.
Command Authorization
Commands need stronger checks than queries because they mutate state.
Every tenant-scoped command should verify:
- the requested
hostIdis the authenticated session host, unless the caller is a globaladmin - the target aggregate exists in that host for update/delete commands
- owner-scoped users own the target through
owner_user_idorowner_position_id - entity admins and host admins are still limited by host
- owner transfer is explicit and restricted
- target owners for
owner_user_idandowner_position_idbelong to the trusted session host - owner transfer is audit logged with old and new owner values
Recommended command scopes:
| Scope | Meaning |
|---|---|
own:create | user can create records owned by self and optional owner position |
own:update | user can update records they own |
own:delete | user can delete records they own if the entity allows it |
host:read | user can read all rows in the current host |
host:write | user can mutate all rows in the current host |
global:admin | user can operate across hosts for platform administration |
Portal Access-Control Registry
The access-control registry should support portal handlers as first-class endpoints.
Proposed endpoint identity:
| Field | Value |
|---|---|
apiId | PORTAL or light-portal |
apiVersion | portal release version or 1.0.0 for the logical control plane |
endpoint | lightapi.net/{service}/{action}/{version} |
httpMethod | POST |
endpointPath | /portal/query or /portal/command |
sourceProtocol | hybrid |
This allows the existing Role Permission, Group Permission, Position Permission, Attribute Permission, Row Filter, and Column Filter pages to manage portal handler access without a separate policy store.
The portal-handler catalog should be generated from service annotations and
spec.yaml metadata during build or deployment. Manual registration may be used
only as an override for descriptions, classifications, or temporary exclusions.
Generation prevents drift when handlers are added, renamed, or removed.
Example Policies
Host Admin Can Manage Tenant APIs
Request rule:
ruleId: portal-host-admin-current-host
ruleType: req-acc
description: Allow host-admin to call tenant handlers for the current host.
conditions:
- conditionId: role-host-admin
variableName: jwt
propertyPath: roles
operatorCode: CS
conditionValues:
- conditionValue: host-admin
- conditionId: same-host
variableName: requestData
propertyPath: hostId
operatorCode: EQ
conditionValues:
- conditionValue: "@host_id"
actions:
- actionClassName: com.networknt.rule.FineGrainedAuthAction
The @host_id placeholder means the trusted host from the authenticated
context, not a host id supplied by the browser.
User Can See Owned APIs
Request rule allows the list handler:
endpoint: lightapi.net/service/getApi/0.1.0
ruleType: req-acc
roles:
- user
- api-admin
- host-admin
- admin
The data rule is applied in SQL:
WHERE host_id = :hostId
AND (
:allScope = TRUE
OR owner_user_id = :currentUserId
OR owner_position_id IN (:effectivePositions)
)
Owner Position Can Manage Team Client Apps
If a client app has:
owner_position_id = api-platform-team
and the user has effective position:
api-platform-team
then the user can see and update the app when the page grants owner-scoped
access. The user does not need a broad app-admin role.
Handler Enablement Plan
Phase 1: Inventory
- Register every portal query and command handler as a logical access-control
endpoint from service annotations and
spec.yaml. - Classify each handler by entity, operation, and scope:
- global admin
- host admin
- entity admin
- owner scoped
- public authenticated
- Identify handlers that cannot yet be owner scoped because the table lacks owner fields.
Implementation path:
service-commandparsesapiType: hybridspec.yamlfiles inSpecUtil.parseSpec.- Hybrid handlers are stored as logical endpoints such as
lightapi.net/service/getApi/0.1.0, withhttpMethod: postandendpointPathset to/portal/queryor/portal/command. - Handler name, request schema, transport path, action, version, scope,
operation classification, and
skipAuthare captured in endpoint metadata. - Existing legacy hybrid endpoint ids keyed by
logicalEndpoint@postare reused during migration so policy assignments can keep the sameendpointId.
Phase 2: Menu And Capability Cleanup
- Normalize sidebar and task page registry roles around exact tokens.
- Treat
host-adminas tenant admin, not global admin. - Add route guards that use the same page capability model as the menu.
- Keep React-side hiding as usability only.
Phase 3: Query Enforcement
- Standardize
OwnerScopeUtilfor all owner-aware query handlers. - Pass
ownerUserId,ownerPositions, andownerScopedinto db-provider query methods. - Ensure counts and pagination are computed after host and owner predicates.
- Return owner fields only when the caller has a reason to see them.
Phase 4: Command Enforcement
- Add common command guard helpers:
- resolve trusted host
- verify target aggregate host ownership
- verify owner or all-scope access
- enforce owner-transfer rules
- verify transferred owner user or position belongs to the trusted host
- audit owner changes
- Add explicit owner-transfer commands for records that need ownership changes.
- Reject requests where browser-supplied
hostIdconflicts with the trusted session host.
Phase 5: Gateway req-acc And res-fil
- Update light-gateway access-control extraction for hybrid portal requests.
- Derive logical service id from
host,service,action, andversion. - Build the CEL/rule context with JWT claims, trusted host, request data, and handler metadata.
- Run
req-accbefore forwarding to the portal handler. - Run gateway
res-filfor column filtering and defense-in-depth response filtering where endpoint filters are configured.
Phase 6: Policy Management UI
- Reuse existing access-control pages to assign portal handler permissions.
- Add a portal-handler catalog view that lists logical handlers and their current permission configuration.
- Add an overview page for effective menu and data access per role or user.
- Make access-control pages require
access-adminfor tenant policy changes andadminfor global policy changes.
Recommendations
- Use
host-adminas the tenant administrator role and keepadminas global super admin. - Make every backend handler validate host scope, even when the UI already selected the host.
- Prefer service-side row filtering over response-only filtering for list queries.
- Use
owner_position_idfor team ownership instead of adding group ownership to every table. - Keep
owner_user_idserver-assigned and make ownership transfer explicit. - Validate transferred owners against the trusted host and audit all ownership changes.
- Materialize or cache effective positions before query execution instead of recursively resolving position inheritance on every request.
- Register portal handlers in the same access-control registry used for
customer APIs so
req-accandres-filare managed consistently. - Generate the portal-handler catalog from service annotations and
spec.yaml, with manual metadata overrides only where needed. - Split tenant deployment pages from global platform pages.
- Require
access-adminfor tenant access-control administration instead of granting it implicitly tohost-admin. - Roll out one entity family at a time, starting with API, client app, instance, workflow, schema, and schedule pages because they already have the clearest ownership model.
Design Decisions
| Question | Decision |
|---|---|
| Access-control administration | Require access-admin inside the host; do not grant it implicitly to host-admin. |
| Deployment pages | Split tenant deployment pages from global platform pages. Tenant pages can use host-admin; global platform pages require admin. |
| Position inheritance | Materialize position_closure_t or cache the effective-position set; do not recursively compute inheritance in every query. |
| Portal handler registration | Generate the catalog from service annotations and spec.yaml, with manual metadata overrides only. |
| Portal response filtering | Apply row filtering in SQL or shared query serialization so pagination totals remain exact. Use gateway res-fil mainly for column filtering and defense-in-depth checks. |
Claim Org Role Bootstrap
Problem
The Claim Org action lets a signed-in user create an organization and its default host from the profile menu. The createOrg form captures the organization owner, default subdomain, host description, and host owner. The backend create-org flow then creates the organization, the default host, and user-host membership rows in one transaction.
That transaction is not sufficient for a usable tenant. A new host membership without role assignments can leave the owner unable to authorize after switching to the newly claimed host. The user profile/login query joins roles through role_user_t by the current user_host_t.host_id; if the current host has no active role rows for that user, role-dependent reads can return no user context.
The Claim Org bootstrap must create the minimum administration roles and assignments for the default host at the same time as the organization and host.
Current Flow
The current UI entry point is the Claim Org menu in portal-view/src/components/Header/ProfileMenu.tsx, which routes to /app/form/createOrg through portal-view/src/contexts/UserContext.tsx.
The createOrg form is defined in portal-view/src/data/Forms.json. It posts the host/createOrg action and includes:
domainorgNameorgDescorgOwnersubDomainhostDeschostOwner
The form help text already says that creating the default host assigns the host owner the host-admin role. Existing UI comments also assume that the organization owner can update and delete the organization because the user has the org-admin role.
On the projection side, HostOrgPersistenceImpl has separate handlers for:
createOrg, which writesorg_tcreateHost, which writeshost_tcreateUserHost, which writesuser_host_t
Access control data is projected by AccessControlPersistenceImpl into:
role_trole_user_trole_permission_t
The role_user_t table has a foreign key to (host_id, role_id) in role_t, so role rows must exist before the user-role assignments are inserted.
Goals
- A claimed organization must be immediately usable by the selected organization owner and host owner.
- The default host must receive deterministic administrative roles.
- The role assignments must be created in the same command transaction as the organization, host, and user-host membership.
- The event stream and projections must remain replayable and idempotent.
- The implementation must use the canonical role IDs already used by the portal data:
org-adminandhost-admin.
Non-Goals
This design does not introduce a new global organization-role table. Existing roles are host-scoped through role_t.host_id, so the organization administrator role for a claimed organization is represented as a role on the default host.
This design also does not merge organization and host administration into one broad role. Organization ownership and host ownership are separate responsibilities, and the system should grant both roles only when the same user is selected for both owner fields.
Role Model
For the default host created during Claim Org:
| Role ID | Assigned To | Purpose |
|---|---|---|
org-admin | orgOwner | Manage organization metadata, billing, and owner transfer for the claimed domain. |
host-admin | hostOwner | Manage the default host, membership, infrastructure, and host-level API deployment setup. |
If orgOwner and hostOwner are the same user, that user receives both roles.
The two roles should stay separate. org-admin should not implicitly include all host administration permissions. If an organization owner also needs to administer the default host, the command should grant that user both org-admin and host-admin explicitly.
The implementation should not use the current Java constant value HOST_ADMIN_ROLE = "hostAdmin" for this bootstrap. The canonical role ID in portal role data and UI task IDs is host-admin. The constant should be corrected or a new canonical constant should be introduced before it is used by bootstrap code.
Command Transaction
The Claim Org command should validate and persist these facts atomically:
- Create
org_tfordomain. - Create the default
host_tfor(domain, subDomain). - Create
user_host_trows for the selected owners on the default host. - Switch the selected
hostOwnerto the new host by emittingUserHostSwitchedEvent. - Create or reactivate
role_trows fororg-adminandhost-adminon the default host. - Assign
org-admintoorgOwnerinrole_user_t. - Assign
host-admintohostOwnerinrole_user_t. - Seed the required
role_permission_trows for these roles when endpoint-based authorization is enforced for the target admin APIs.
All rows should share the command’s audit fields where possible: update_user, update_ts, and the event aggregate version metadata. Inserts should use the same idempotent create/reactivate pattern already used by role and role-user projections.
Event Shape
The preferred event-sourcing shape is a single command producing multiple atomic events in one transaction:
OrgCreatedEventHostCreatedEventUserHostCreatedEventfororgOwner, if neededUserHostCreatedEventforhostOwner, if differentUserHostSwitchedEventforhostOwnerRoleCreatedEventfororg-adminRoleCreatedEventforhost-adminRoleUserCreatedEventfororgOwnerandorg-adminRoleUserCreatedEventforhostOwnerandhost-adminRolePermissionCreatedEventevents for the required endpoint permissions, if endpoint permission seeding is part of the command
The events must be written atomically by the command side. Each emitted event must reserve and carry its own user nonce because event_store_t enforces uniqueness on (user_id, nonce). Projection replay can then use the existing individual projection handlers. This matches the existing atomic-event design direction while keeping the Claim Org user gesture transactional.
Claim Org emits UserHostSwitchedEvent for the host owner after creating the selected host owner’s user_host_t membership. The master OAuth host tenant login boundary allows this safely: light-oauth validates the portal client under the configured OAuth host, then stores auth_session_t, auth_code_t, and auth_refresh_token_t rows with tenant host_id plus master auth_host_id.
The target login/session design is documented in Master OAuth Host Tenant Login. It keeps OAuth provider/client rows on the master host while storing tenant-host claims and sessions for the user’s current host.
If the current command service still emits one composite createOrg event, the projection may temporarily perform the role bootstrap as part of that composite handler. That should be treated as a compatibility step, not the long-term event model.
Permission Bootstrap
Creating role_t and role_user_t rows gives the user role identity on the new host. It does not automatically grant endpoint access if the request path is protected by role_permission_t.
The authoritative role-permission catalog should live with the command service as static, versioned metadata, for example default-role-permissions.yml. The Claim Org command reads that catalog and emits the required RolePermissionCreatedEvent events. This keeps the authorization bootstrap in the event stream, so projection replay produces the same state without depending on seed SQL.
The chosen source must be deterministic and replayable. It must also account for the fact that role_permission_t references api_endpoint_t through (host_id, endpoint_id). Permission rows can only be inserted after the target host has the corresponding endpoint rows.
Event importer assets such as events.json can mirror the same catalog for environment bootstrap and repair, but they should not be the only source of truth for permissions created by an interactive Claim Org command.
Initial SQL seed files should not own the final role-permission state. Seed SQL is useful for bootstrapping a local database, but event-sourced permission state must be represented by events so replay and promotion remain deterministic.
If endpoint rows are not available during Claim Org, the command should still create the roles and role-user assignments, then schedule or trigger a follow-up permission bootstrap once the endpoint catalog exists. That follow-up must emit the same RolePermissionCreatedEvent facts that would have been emitted synchronously.
UI Contract
The createOrg form should require both owners:
orgOwnerhostOwner
The current form requires hostOwner but not orgOwner. Since the backend persistence expects orgOwner, the form schema and command service request schema should mark both owner fields required and reject blank values through static schema validation.
The Claim Org command creates the selected host owner’s membership for the new default host and switches that owner’s current host in the same transaction. The portal must not bootstrap duplicate OAuth provider/client rows on every tenant host.
When automatic switching is enabled, the UI success path should tell the host owner to log out and log in again so the browser session receives the new tenant-host and role claims.
Owner Transfer
Owner transfer role behavior is intentionally deferred. Claim Org bootstrap grants the initial org-admin and host-admin assignments, but later changes to org_t.org_owner or host_t.host_owner should not automatically remove or transfer those roles until the access policy is defined.
There are valid cases where more than one user should keep the same administrative role. For example, a new organization owner may need org-admin while the previous owner remains an administrator during handoff, support, or shared ownership. Automatically deleting the old owner’s RoleUser assignment can remove access that was granted intentionally through another path.
When this policy is revisited, the implementation should decide separately:
- Whether changing
orgOwnershould grantorg-adminto the new owner. - Whether changing
hostOwnershould granthost-adminto the new owner. - Whether the old owner should retain the role, lose it, or require an explicit UI choice.
- How to distinguish a bootstrap-created role assignment from an independently granted role assignment.
Until then, UpdateOrg and UpdateHost should remain metadata updates only. Any role changes after Claim Org should use the existing role-user administration flow.
Backfill
Existing claimed organizations may already have a default host and user_host_t rows without the corresponding admin role bootstrap.
A one-time repair should:
- Find active hosts whose organization and host owner users exist.
- Ensure
org-adminandhost-adminexist inrole_tfor each host. - Ensure the organization owner has
org-admin. - Ensure the host owner has
host-admin. - Seed required role permissions if the endpoint catalog is present.
The repair must be idempotent and should only activate missing or soft-deleted bootstrap rows. It should not remove custom roles or overwrite existing role assignments.
Validation
A focused validation set should cover:
- Claim Org creates
org_t,host_t, anduser_host_trows. - Claim Org creates
org-adminandhost-adminrows inrole_tfor the default host. - Claim Org assigns
org-admintoorgOwner. - Claim Org assigns
host-admintohostOwner. - The same user can receive both roles when
orgOwner == hostOwner. - After Claim Org switches the host owner to the claimed host, the current-host user query returns the claimed user with active roles on the next login.
- Replaying the events does not duplicate rows or downgrade active rows.
- Permission bootstrap either creates the expected
role_permission_trows or records a deterministic follow-up when endpoint rows are not present. - Claim Org switches the selected host owner’s current host during creation after the master OAuth host login boundary is implemented.
- The UI tells the host owner to log out and log in again after Claim Org switches the current host.
Resolved Decisions
- Claim Org creates the selected host owner’s user-host membership and switches that owner to the new host during the same command transaction.
org-adminandhost-adminshould remain separate roles. A user who needs both capabilities should receive both roles explicitly.- The authoritative role-permission catalog should live as command-side static metadata, with importer assets kept in sync for bootstrap and repair.
Remaining Follow-up
The implementation still needs to define the exact org-admin and host-admin endpoint permission sets. That catalog should be reviewed with the host and organization command/query API surface before implementation starts.
The owner-transfer role policy also remains open. The system should decide whether owner changes imply role grants, role revokes, both, or neither before adding role side effects to UpdateOrg or UpdateHost.
Master OAuth Host Tenant Login
Problem
In a deployed portal instance, dev.lightapi.net is the master host for the instance. Its host ID is:
01964b05-552a-7c4b-9184-6857e7f3dc5f
The master host owns the OAuth provider and portal client configuration:
auth_provider_tauth_client_tauth_provider_client_t
Tenant hosts own user membership, roles, groups, positions, attributes, and host-scoped portal data. A user can belong to many hosts, and user_host_t.current = TRUE identifies which tenant host should be used for the user’s login roles and JWT host claim.
The current light-oauth authorization code flow mixes these two meanings of host:
- It validates the portal client against the configured master host.
- It loads the user by the current tenant host.
- It writes
auth_session_tandauth_code_tusing the user’s current tenant host.
That fails after Claim Org switches the user to the newly created tenant host, because auth_session_t, auth_code_t, and auth_refresh_token_t currently enforce this foreign key:
FOREIGN KEY (host_id, client_id, provider_id)
REFERENCES auth_provider_client_t(host_id, client_id, provider_id)
The new tenant host does not and should not have duplicate OAuth provider/client rows. The FK therefore rejects login with:
auth_session_t_host_id_client_id_provider_id_fkey
Goals
- Keep
dev.lightapi.netas the single master OAuth host for the instance. - Allow users whose current host is a tenant host to log in through the master host’s provider/client.
- Preserve tenant-scoped JWT claims, especially the
hostclaim and role claims. - Avoid duplicating
auth_provider_t,auth_client_t, orauth_provider_client_trows per tenant host. - Allow Claim Org to switch the host owner to the new host and require logout/login for fresh claims.
- Keep session, auth-code, refresh-token, and audit lifecycle behavior deterministic and queryable.
Non-Goals
This design does not introduce tenant-specific OAuth provider IDs, client IDs, redirect URIs, or BFF configuration.
This design does not change the portal UI or BFF to select a different OAuth provider per tenant host.
This design does not remove database referential integrity. The provider-client relationship should remain enforced, but it should be enforced against the master OAuth host instead of the tenant host.
Terminology
| Term | Meaning |
|---|---|
| Master OAuth host | The host that owns OAuth provider/client configuration for the portal instance. In local/dev this is 01964b05-552a-7c4b-9184-6857e7f3dc5f. |
| Tenant host | The user’s current business host from user_host_t.current; this drives roles and tenant data access. |
auth_host_id | The host ID used to validate OAuth provider/client configuration. |
host_id | The tenant host ID used for session ownership, user roles, and JWT host claim. |
Decision
Separate OAuth configuration host from tenant host in the OAuth runtime tables.
Keep host_id in auth_session_t, auth_code_t, and auth_refresh_token_t as the tenant/current host. Add auth_host_id to those tables to point to the master OAuth host that owns the provider-client mapping.
The provider-client foreign key should move from host_id to auth_host_id:
FOREIGN KEY (auth_host_id, client_id, provider_id)
REFERENCES auth_provider_client_t(host_id, client_id, provider_id)
Session and token lifecycle keys should remain tenant-host scoped:
auth_session_t.host_id
auth_code_t.host_id
auth_refresh_token_t.host_id
This preserves the current meaning of host_id for tenant access while allowing all OAuth configuration to live on the master host.
Data Model
auth_session_t
Add:
auth_host_id UUID NOT NULL
Keep:
PRIMARY KEY (host_id, session_id)
FOREIGN KEY (host_id) REFERENCES host_t(host_id)
Replace:
FOREIGN KEY (host_id, client_id, provider_id)
REFERENCES auth_provider_client_t(host_id, client_id, provider_id)
With:
FOREIGN KEY (auth_host_id, client_id, provider_id)
REFERENCES auth_provider_client_t(host_id, client_id, provider_id)
auth_code_t
Add:
auth_host_id UUID NOT NULL
Keep:
PRIMARY KEY (host_id, auth_code)
FOREIGN KEY (host_id, session_id)
REFERENCES auth_session_t(host_id, session_id)
Replace the provider-client FK with:
FOREIGN KEY (auth_host_id, client_id, provider_id)
REFERENCES auth_provider_client_t(host_id, client_id, provider_id)
auth_refresh_token_t
Add:
auth_host_id UUID NOT NULL
Keep:
PRIMARY KEY (host_id, refresh_token)
FOREIGN KEY (host_id, session_id)
REFERENCES auth_session_t(host_id, session_id)
Replace the provider-client FK with:
FOREIGN KEY (auth_host_id, client_id, provider_id)
REFERENCES auth_provider_client_t(host_id, client_id, provider_id)
auth_session_audit_t
auth_session_audit_t.host_id should remain the tenant host for session and user queries.
Add:
auth_host_id UUID NOT NULL
Audit rows must distinguish the authorization server host from the tenant host from the first migration. This is required for security and compliance trails because a single database can contain multiple master hosts, and operators need to answer both questions:
- Which OAuth host authenticated the user?
- Which tenant host did the user access?
auth_host_id should be populated from the same value used by the session, auth code, or refresh token involved in the audit event.
Token Endpoint Lookup Indexes
The token endpoint receives an authorization code or refresh token string. It does not receive tenant host_id in the standard OAuth request, so it cannot use the (host_id, auth_code) or (host_id, refresh_token) primary keys as the first lookup.
Add unique secondary indexes:
CREATE UNIQUE INDEX idx_auth_code_t_auth_code
ON auth_code_t(auth_code);
CREATE UNIQUE INDEX idx_auth_refresh_token_t_refresh_token
ON auth_refresh_token_t(refresh_token);
The token endpoint should load the row by the code or refresh token string, then validate the tenant and OAuth boundaries with the row values. This keeps the external OAuth token format unchanged and avoids embedding tenant host IDs into authorization code or refresh token strings.
Migration
The migration should be backward compatible for existing rows.
- Add nullable
auth_host_idcolumns.
ALTER TABLE auth_session_t ADD COLUMN auth_host_id UUID;
ALTER TABLE auth_code_t ADD COLUMN auth_host_id UUID;
ALTER TABLE auth_refresh_token_t ADD COLUMN auth_host_id UUID;
ALTER TABLE auth_session_audit_t ADD COLUMN auth_host_id UUID;
- Backfill existing rows. Existing valid rows used
host_idfor both meanings, so the safe default is:
UPDATE auth_session_t SET auth_host_id = host_id WHERE auth_host_id IS NULL;
UPDATE auth_code_t SET auth_host_id = host_id WHERE auth_host_id IS NULL;
UPDATE auth_refresh_token_t SET auth_host_id = host_id WHERE auth_host_id IS NULL;
UPDATE auth_session_audit_t SET auth_host_id = host_id WHERE auth_host_id IS NULL;
- Set the new columns to not null.
ALTER TABLE auth_session_t ALTER COLUMN auth_host_id SET NOT NULL;
ALTER TABLE auth_code_t ALTER COLUMN auth_host_id SET NOT NULL;
ALTER TABLE auth_refresh_token_t ALTER COLUMN auth_host_id SET NOT NULL;
ALTER TABLE auth_session_audit_t ALTER COLUMN auth_host_id SET NOT NULL;
- Drop the current provider-client FKs.
The exact constraint names vary by schema version. The migration should drop the existing provider-client constraints on:
auth_session_tauth_code_tauth_refresh_token_t
- Add new provider-client FKs through
auth_host_id.
ALTER TABLE auth_session_t
ADD CONSTRAINT auth_session_t_auth_provider_client_fk
FOREIGN KEY (auth_host_id, client_id, provider_id)
REFERENCES auth_provider_client_t(host_id, client_id, provider_id)
ON DELETE CASCADE;
ALTER TABLE auth_code_t
ADD CONSTRAINT auth_code_t_auth_provider_client_fk
FOREIGN KEY (auth_host_id, client_id, provider_id)
REFERENCES auth_provider_client_t(host_id, client_id, provider_id)
ON DELETE CASCADE;
ALTER TABLE auth_refresh_token_t
ADD CONSTRAINT auth_refresh_token_t_auth_provider_client_fk
FOREIGN KEY (auth_host_id, client_id, provider_id)
REFERENCES auth_provider_client_t(host_id, client_id, provider_id)
ON DELETE CASCADE;
- Add supporting indexes.
CREATE INDEX idx_auth_session_t_auth_host_client_provider
ON auth_session_t(auth_host_id, client_id, provider_id);
CREATE INDEX idx_auth_code_t_auth_host_client_provider
ON auth_code_t(auth_host_id, client_id, provider_id);
CREATE INDEX idx_auth_refresh_token_t_auth_host_client_provider
ON auth_refresh_token_t(auth_host_id, client_id, provider_id);
CREATE UNIQUE INDEX idx_auth_code_t_auth_code
ON auth_code_t(auth_code);
CREATE UNIQUE INDEX idx_auth_refresh_token_t_refresh_token
ON auth_refresh_token_t(refresh_token);
CREATE INDEX idx_auth_session_audit_t_auth_refresh_rotation
ON auth_session_audit_t(auth_host_id, old_refresh_token_id, client_id, provider_id, event_type, event_ts DESC);
light-oauth Changes
Authorization Code Login
In post_code, keep using state.host_id to validate the configured portal client:
#![allow(unused)]
fn main() {
let client = get_client_by_provider_client_id(state.host_id, provider_id, client_id);
}After password verification, use two host IDs:
#![allow(unused)]
fn main() {
let auth_host_id = client.host_id; // master OAuth host
let tenant_host_id = user.host_id; // current user host
}Persist:
#![allow(unused)]
fn main() {
AuthCode {
host_id: tenant_host_id,
auth_host_id,
...
}
AuthSession {
host_id: tenant_host_id,
auth_host_id,
...
}
}Authorization Code Token Exchange
When exchanging the code:
- Load the auth code by the unique
auth_codevalue. - Authenticate the client against the master OAuth host.
- Verify:
#![allow(unused)]
fn main() {
code.provider_id == provider_id
code.client_id == client.client_id
code.auth_host_id == client.host_id
}The lookup can remain by authorization code only because auth_code_t(auth_code) is unique. The endpoint must still validate the row after retrieval so a code issued to one client or master host cannot be exchanged by another client.
Generate access token claims from tenant data:
#![allow(unused)]
fn main() {
("host", Some(code.host_id.to_string()))
}Create refresh tokens with:
#![allow(unused)]
fn main() {
AuthRefreshToken {
host_id: code.host_id,
auth_host_id: code.auth_host_id,
...
}
}Refresh Token Flow
The token endpoint should load refresh tokens by the unique refresh_token value. After the row is loaded, all mutation and session lifecycle operations should use the tenant host_id from the row.
The refresh flow must also verify that the authenticated client belongs to the same master OAuth host stored on the refresh token:
#![allow(unused)]
fn main() {
token.auth_host_id == client.host_id
token.client_id == client.client_id
token.provider_id == provider_id
}Rotated refresh tokens must carry forward auth_host_id.
The JWT host claim must continue to come from token.host_id, not token.auth_host_id.
Refresh-token deletion and rotation should use:
#![allow(unused)]
fn main() {
host_id = token.host_id
refresh_token = token.refresh_token
}This preserves tenant-host session ownership while allowing the token endpoint to find the row without the caller providing tenant host_id.
Logout And Revocation
Logout and administrative revocation should use the tenant host from the provided token or loaded refresh-token row.
For refresh-token based logout:
- Load the refresh token by the unique
refresh_tokenvalue. - Validate
token.auth_host_id == client.host_idwhen client context is present. - Revoke the session with
token.host_idandtoken.session_id. - Delete refresh tokens and outstanding auth codes with the same tenant
host_idandsession_id. - Write audit rows with both tenant
host_idand masterauth_host_id.
For access-token based logout, the host claim represents the tenant host. The logout handler should use that tenant host to locate the session or refresh token state, and should not treat the master OAuth host as the tenant context.
Password Grant
The password grant has the same host split:
#![allow(unused)]
fn main() {
let auth_host_id = client.host_id;
let tenant_host_id = user.host_id;
}Sessions and refresh tokens should store both values.
Client Authenticated User Grant
This grant already accepts an optional tenant host in the request. That host should remain the tenant host_id.
The authenticated client’s host should become auth_host_id.
Client Authentication
authenticate_client should become host-aware. The token endpoint should not load a client only by client_id, because auth_client_t is keyed by (host_id, client_id).
Preferred behavior:
#![allow(unused)]
fn main() {
get_client_by_provider_client_id(state.host_id, provider_id, client_id)
}This keeps token endpoint client authentication aligned with the authorization endpoint.
Provider And Key Lookup
Provider and signing-key lookup should also be scoped by the configured master OAuth host.
Current provider IDs are short and not globally guaranteed across every possible master host in a shared database. Therefore the light-oauth lookup shape should be:
#![allow(unused)]
fn main() {
query_provider_by_id(state.host_id, provider_id)
query_current_provider_key(state.host_id, provider_id)
query_long_live_provider_key(state.host_id, provider_id)
}The SQL should include host_id = $1 as well as provider_id = $2. This prevents accidental cross-master-host key or provider resolution if another portal instance later stores the same provider ID in the same database cluster.
JWT Claims
The access token must continue to identify the tenant host:
{
"host": "<tenant-host-id>",
"role": "host-admin org-admin"
}
The master OAuth host should not replace the JWT host claim. It is an implementation detail for OAuth provider/client validation.
If operational diagnostics need visibility into the authorization host, a separate claim could be introduced later, but this is not required for the current flow and should not be added unless there is a clear consumer.
Claim Org Behavior
With this design implemented, Claim Org can safely emit UserHostSwitchedEvent for the selected host owner during the same command transaction that creates:
OrgCreatedEventHostCreatedEventUserHostCreatedEventUserHostSwitchedEventRoleCreatedEventfororg-adminRoleCreatedEventforhost-adminRoleUserCreatedEventfororgOwnerandorg-adminRoleUserCreatedEventforhostOwnerandhost-admin
The user’s current browser session still has the old host claim. The UI should tell the host owner to log out and log in again after Claim Org. The next login will:
- Authenticate through the master OAuth host.
- Load roles from the new current tenant host.
- Store session/code/refresh rows with tenant
host_idand masterauth_host_id. - Issue a token whose
hostclaim is the new tenant host.
Backfill And Repair
For existing databases, the schema migration backfills auth_host_id = host_id for existing valid OAuth rows.
For users already switched to a tenant host by an earlier Claim Org deployment, no OAuth provider/client rows should be created on the tenant host. After this design is deployed, those users should be able to log in because new session rows will reference:
host_id = tenant host
auth_host_id = master OAuth host
If an earlier failed login left partial session artifacts, they should be removed through existing session cleanup paths or targeted SQL cleanup before retesting.
Validation
A focused validation set should cover:
- Existing master-host login still succeeds after migration.
- Claim Org switches the selected host owner to the new tenant host.
- The host owner can log out and log in again after Claim Org.
- New
auth_session_trows use tenanthost_idand masterauth_host_id. - New
auth_code_trows use tenanthost_idand masterauth_host_id. - New
auth_refresh_token_trows use tenanthost_idand masterauth_host_id. - The JWT
hostclaim is the tenant host, not the master OAuth host. - Role claims come from the tenant host after
user_host_t.currentis switched. - No
auth_provider_t,auth_client_t, orauth_provider_client_trows are created for the tenant host. - Refresh token rotation preserves
auth_host_id. - Revoking a session or refresh token still works with tenant-host keys.
- Logout uses the tenant host from the token/session row and writes audit rows with
auth_host_id. - Existing rows migrated with
auth_host_id = host_idstill support token refresh and audit queries. - Auth code lookup uses
auth_code_t(auth_code)and still rejects mismatched client/provider/auth host. - Refresh token lookup uses
auth_refresh_token_t(refresh_token)and still rejects mismatched client/provider/auth host. - Provider and provider-key lookup is scoped by the configured master OAuth host.
Resolved Decisions
auth_session_audit_tmust addauth_host_idin the first migration.- Provider and provider-key lookup must require the configured master OAuth host ID.
auth_code_tlookup remains by uniqueauth_code, followed by strict client, provider, andauth_host_idvalidation.auth_refresh_token_tlookup remains by uniquerefresh_token, followed by strict client, provider, andauth_host_idvalidation.- Authorization code and refresh token string formats should not embed tenant host IDs in this design.
Schema Registry
The schema registry is the portal-owned catalog for reusable schema contracts.
The first release should focus on JSON Schema documents for UI form generation,
backend validation, external schema discovery, and operational auditability. The
model should remain extensible enough to add Protobuf later if
gRPC-over-WebSocket contract discovery becomes a real requirement, but Protobuf
support is not required for the initial hardening pass. This design focuses on
hardening the current schema-query, schema-command, and schema_t
implementation so it can safely validate configuration property values and
support future schema reuse across portal features.
Current State
The portal already has the core pieces of a schema registry:
schema_tstores schema metadata and the schema body.schema-queryexposes read actions such asgetSchema,getSchemaLabel,getSchemaById, andgetFreshSchema.schema-commandexposes create, update, and delete actions.schema_t.host_idsupports tenant-specific rows, withNULLrepresenting a global schema.schema_t.schema_statustracks draft, published, and retired states.schema_t.spec_versionrecords the schema language version, such as a JSON Schema draft.
The implementation is not ready to be treated as an authoritative validation service yet. The main gaps are:
- schema lookup is not consistently tenant-aware
- version lookup semantics are not explicit enough for config validation
- schema bodies are not clearly validated before being stored
- published schema immutability is not defined
- schema type and body validation rules are not explicit
- schema rows do not have a stable URL-friendly public alias
- config properties do not currently reference schemas
- backend config command handlers do not validate values against schemas
- tests for schema CRUD, tenant/global lookup, versioning, and config validation are incomplete
Goals
- Store JSON Schema documents with clear tenant/global ownership.
- Support immutable published schema versions.
- Let config properties reference an exact schema id and version.
- Validate structured config property values on both frontend and backend.
- Preserve existing schema registry CRUD pages and generated forms.
- Add a Marketplace Schema Catalog entry for browse-first schema discovery.
- Add URL-friendly schema aliases so external applications can retrieve
published schemas through
portal-service. - Keep schema lookup cheap for list pages by returning schema metadata first and loading schema bodies lazily.
- Support schema status transitions: draft, published, retired.
- Make validation errors specific enough for editors to highlight the failing JSON path.
- Categorize and tag schemas for easier discovery and filtering.
Non-Goals
- Do not build a full schema compatibility engine in the first release.
- Do not require every config property to have a schema.
- Do not replace OpenAPI schemas or the existing API spec registry.
- Do not implement Protobuf parsing, compatibility, config form generation, or runtime validation in the first release.
- Do not make the config update page depend on schema registry completion for basic scalar and raw JSON/YAML editing.
- Do not allow unpublished schemas to validate production config overrides.
Data Model
The existing schema_t table is a reasonable starting point. It already has:
schema_idhost_idschema_versionschema_typespec_versionschema_bodyschema_status- ownership, active, audit, and aggregate-version fields
Before production validation depends on this table, the versioning model should be made explicit. The recommended model is:
schema_idis the stable, lower-case, URL-friendly logical schema id.schema_versionidentifies an immutable schema version.host_id IS NULLmeans a global schema.host_id IS NOT NULLmeans a tenant-specific schema.- a published schema body is immutable
- changing a published schema creates a new version
- retiring a schema version marks it unavailable for new bindings but keeps it readable for historical audit and existing references
The current table uses schema_id as the primary key while also defining
unique indexes on (schema_id, schema_version) and
(host_id, schema_id, schema_version). That conflicts with a true immutable
version-row model. The preferred correction is to introduce a surrogate row key
such as schema_uid UUID and keep uniqueness on the logical reference:
schema_uid UUID primary key
schema_lineage_id UUID not null
host_id UUID nullable
schema_id VARCHAR(126)
schema_alias VARCHAR(126) nullable
schema_version VARCHAR(12)
schema_type VARCHAR(16)
spec_version VARCHAR(12)
schema_body TEXT
schema_status CHAR(1)
external_visible BOOLEAN
aggregate_version BIGINT
...
The registry should keep unique constraints for:
- global schema versions:
schema_id + schema_versionwherehost_id IS NULL - tenant schema versions:
host_id + schema_id + schema_versionwherehost_id IS NOT NULL - version rows within one logical lineage:
schema_lineage_id + schema_version
schema_lineage_id is the stable identity for a logical schema within a scope.
All immutable versions of the same global schema share one lineage id. All
immutable versions of the same tenant schema share a different lineage id. This
prevents category and tag assignments from colliding when a global schema and a
tenant schema use the same schema_id.
schema_alias is an optional URL-friendly external identifier for a schema
lineage. It should use the same lower-case, URL-friendly character policy as
schema_id, and it should be stable across immutable versions of the same
lineage. schema_alias is allowed to differ from schema_id so operators can
rename an external contract URL without changing internal schema ids.
Because alias and taxonomy are lineage-level metadata, the clean target is a small lineage table:
schema_lineage_t
schema_lineage_id UUID primary key
host_id UUID nullable
schema_id VARCHAR(126)
schema_alias VARCHAR(126) nullable
external_visible BOOLEAN not null default false
...
schema_t
schema_uid UUID primary key
schema_lineage_id UUID references schema_lineage_t(schema_lineage_id)
schema_version VARCHAR(12)
schema_body TEXT
...
If a separate lineage table is too large for the first pass, schema_alias and
external_visible can be stored on schema_t with command-side enforcement that
all versions in one lineage share the same alias and visibility. The migration
should still move them to schema_lineage_t when the immutable version-row model
is introduced.
Alias uniqueness should be scoped the same way as schemas:
- global aliases: unique
schema_aliaswherehost_id IS NULL - tenant aliases: unique
host_id + schema_aliaswherehost_id IS NOT NULL
If a surrogate key migration is too disruptive for the first hardening pass, the
minimum acceptable interim model is to keep the current row shape but document
that schema_id represents the current mutable aggregate. That is weaker for
config validation because a schema body can drift under an existing config
property reference. The immutable version-row model should be the target.
Schema Types
schema_type should be treated as a controlled value. The first supported value
is:
schema_type | schema_body meaning | spec_version examples | First-release use |
|---|---|---|---|
json | JSON Schema document | draft-07, 2019-09, 2020-12 | Config form generation, frontend validation, backend config command validation, catalog discovery |
For json schemas, schema-command must parse schema_body as JSON and
validate it as a JSON Schema document before the schema can be published.
protobuf should remain a reserved future schema_type, not an MVP
requirement. If future gRPC-over-WebSocket support needs Protobuf contracts, add
Protobuf parsing and either a schema artifact table or a schema bundle table for
multi-file imports and compiled descriptors. Do not overload the JSON Schema
validation path to make Protobuf fit.
Classification and Discovery
Schemas must support categorization and tagging using the portal’s common
category_t, tag_t, entity_category_t, and entity_tag_t infrastructure,
similar to APIs, workflows, agents, and skills.
entity_typewill be'schema'.entity_idshould beschema_lineage_id::text, not rawschema_id. This lets tags and categories apply to the logical schema lineage rather than a specific immutable version, while still separating global and tenant schemas that use the sameschema_id.entity_category_tconnects schemas to categories.entity_tag_tconnects schemas to tags.schema-commandcreate/update payloads should usecategoryIdsandtagIdsto match the existing taxonomy contract used by API, workflow, and skill forms.- When
categoryIdsortagIdsare present on update, the command should replace that assignment set. An empty array clears assignments. An omitted field leaves the current assignment set unchanged.
These mappings enable discovery across the portal using category and tag
filters. Query paths must join through category_t and tag_t, enforce
active = TRUE on mapping rows and taxonomy rows, and resolve global plus
host-specific taxonomy labels for the selected host.
Marketplace Schema Catalog
Add a Schema Catalog entry under Marketplace alongside API Catalog and Workflow
Catalog. If the navigation uses short labels, the menu label can be Schema,
but the page title should be Schema Catalog.
Recommended route:
/app/marketplace/schema
Visible records should include:
- published global schemas visible to the caller
- published tenant schemas for the selected host
- draft or retired schemas only when the caller owns or administers the schema
jsonschemas in the first release
Common filters:
- search text for schema id, name, description, source, and owner metadata
- schema type, starting with
json - schema status, such as draft, published, and retired
- categories from
getCategoryLabelByType(entityType = "schema") - grouped tags from
getTagLabelByType(entityType = "schema") - active or inactive state
- sort and card/list view options
Catalog cards should show a compact contract summary:
- schema id, name, latest published version, and type
- spec version, source, status, and scope provenance
- schema alias and external URL when external access is enabled
- categories and grouped tags
- whether a schema body is available for preview
- whether a JSON Schema can be used for config-backed form generation
Common actions:
- open a read-only schema details drawer
- preview JSON Schema source
- copy a schema reference, including
schemaId,schemaVersion, andschemaType - copy an external schema URL when
schema_aliasandexternal_visibleare set - create a new version when the user has schema write permission
- edit draft metadata and taxonomy assignments when permitted
- open the schema administration page for table-based management
External Schema Access
External applications should be able to retrieve published schemas through
portal-service/apps/portal-service, similar to the existing /r/data
reference-data endpoint. The recommended route is:
GET /r/schema/{schemaAlias}
Query parameters:
hostis optional. When present, the service first resolves a tenant schema forhost + schemaAlias, then falls back to a global schema with the same alias. When omitted, only global schemas are considered.versionis optional. When omitted, the service returns the latest published active version for the resolved alias. When present, the service returns that exact published or retired active version if it is still externally visible.envelopeis optional. The default should return the schema body directly for external validators.envelope=trueshould return metadata plusschemaBody.
Default response for schema_type = "json" should be the JSON Schema document
itself with Content-Type: application/schema+json where possible. The response
should include headers such as:
X-Schema-Id: security-jwt-claim-mapping
X-Schema-Alias: jwt-claim-mapping
X-Schema-Version: 1.0.0
X-Schema-Type: json
X-Schema-Source: global|tenant
Envelope response:
{
"schemaAlias": "jwt-claim-mapping",
"schemaId": "security-jwt-claim-mapping",
"schemaVersion": "1.0.0",
"schemaType": "json",
"specVersion": "2020-12",
"schemaStatus": "P",
"source": "global",
"schemaBody": { }
}
The external route must only serve schemas that are:
- active
- published, or retired when an exact
versionis requested external_visible = TRUE- visible in the requested host scope
Draft schemas must never be returned by /r/schema/{schemaAlias}. A missing,
inactive, private, or unauthorized alias should return 404 instead of leaking
that the schema exists.
portal-service should add a lightweight schema lookup service and cache,
separate from the /r/data reference cache. Suggested cache key:
host + schemaAlias + version + envelope
The cache should be invalidated when a schema is published, retired, deleted, or when alias/external visibility changes.
Config Property Binding
Config property validation needs an explicit link from a config property to a schema. The simplest useful binding is to add these nullable fields to the base config property definition:
config_property_t.schema_id
config_property_t.schema_version
This works because a config property has at most one schema for its value shape.
The selected hostId is still used during lookup so tenants can override the
global schema with the same schemaId + schemaVersion when needed.
The binding should be optional:
- scalar properties can continue to use
valueTypevalidation only mapandlistproperties can attach JSON Schema for structured validationFileandCertproperties should keep using their existing generated forms until file-specific schema handling is designed
The registry lookup for config validation should resolve in this order:
- tenant-specific schema for
hostId + schemaId + schemaVersion - global schema for
schemaId + schemaVersion - no schema found, which disables schema-backed validation for that row
Only published schemas should be used to validate active config override commands.
API Changes
The existing schema-query actions can remain, but config validation needs a
tenant-aware versioned lookup. Add or evolve an action such as
getSchemaByRef:
{
"hostId": "host uuid",
"schemaId": "security-jwt-claim-mapping",
"schemaVersion": "1.0.0",
"active": true
}
Response:
{
"schemaId": "security-jwt-claim-mapping",
"schemaAlias": "jwt-claim-mapping",
"schemaVersion": "1.0.0",
"schemaType": "json",
"specVersion": "v2020-12",
"schemaStatus": "P",
"schemaBody": "{...}",
"source": "tenant"
}
getSchema should remain a metadata list query. It should not return
schemaBody by default because schema bodies can be large and are usually not
needed for table rendering.
querySchemaCatalog or an evolved getSchema should support server-side
catalog filtering:
{
"hostId": "host uuid",
"offset": 0,
"limit": 20,
"active": true,
"schemaTypes": ["json"],
"schemaStatus": "P",
"categoryIds": ["..."],
"tagIds": ["..."],
"tagMatch": "all",
"globalFilter": "jwt"
}
Category filters should use OR semantics. Tag filters should support
tagMatch = "all" and tagMatch = "any". The response should return
categoryIds, categories, tagIds, and tags, but omit schemaBody unless a
details action explicitly asks for it. It should also return schemaAlias,
externalVisible, and the derived external URL when alias-based access is
enabled.
schema-command should validate schemaBody before create or update. It
should reject invalid JSON Schema documents for schema_type = "json". It
should also enforce the status rules:
- draft schemas can be edited
- publishing validates the schema body and makes that version available
- published schema bodies are immutable
- retired schemas remain readable but cannot be newly bound to config properties
schema-command should also support schemaAlias and externalVisible.
schemaAlias must be lower-case and URL-friendly, unique in the selected
global/host scope, and stable across versions of the same lineage.
externalVisible controls whether the alias can be served by
portal-service /r/schema/{schemaAlias}. A draft schema may carry an alias, but
the external route must not serve it until a published version exists.
Schema delete should remain a soft delete or retire operation for schemas that may be referenced by config properties or historical overrides.
schema-command should support linking categoryIds and tagIds during schema
creation and update. schema-query already has getSchemaByCategoryId and
getSchemaByTagId; those actions should be hardened rather than reintroduced.
They must honor hostId, offset, limit, active, active taxonomy mapping
rows, active taxonomy labels, and active schema rows. They should return schema
metadata for catalog browsing and filtering, not full schema bodies by default.
Config Update Page Integration
getConfigUpdateProperties should include schema metadata but not schema body:
{
"configId": "config uuid",
"propertyId": "property uuid",
"propertyName": "jwt.claimMapping",
"valueType": "map",
"schemaId": "security-jwt-claim-mapping",
"schemaVersion": "1.0.0",
"schemaType": "json",
"schemaStatus": "P",
"hasSchema": true
}
When the user opens a map or list editor, the frontend calls the
tenant-aware schema lookup and caches the result by:
hostId + schemaId + schemaVersion
The structured editor should always provide raw JSON and YAML tabs. The Form tab is enabled only when a published compatible schema is available. YAML input is normalized to compact JSON before it is sent to the existing config command API, because config property values are stored as strings.
Validation Flow
Validation runs in two layers.
Frontend validation:
- parse scalar values according to
valueType - parse
listvalues as JSON arrays - parse
mapvalues as JSON objects - run JSON Schema validation when a schema is available
- show validation errors next to the row or field that failed
- keep the draft dirty until the value is valid
Backend validation:
- load the config property metadata by
configId + propertyId - parse
propertyValueaccording tovalueType - resolve the published schema for
hostId + schemaId + schemaVersion - validate the parsed value against the schema
- reject the command before event persistence when validation fails
Backend validation is authoritative. Frontend validation improves usability but cannot replace command-side enforcement.
Validation errors should include enough detail for row-level UI feedback:
{
"code": "CONFIG_PROPERTY_SCHEMA_VALIDATION_FAILED",
"configId": "config uuid",
"propertyId": "property uuid",
"schemaId": "security-jwt-claim-mapping",
"schemaVersion": "1.0.0",
"errors": [
{
"path": "$.issuer",
"keyword": "required",
"message": "issuer is required"
}
]
}
Security And RBAC
Schema registry access should follow the same tenant ownership model used by other portal resources:
- global schemas are readable by authorized portal users
- tenant schemas are readable only within the selected host context
- schema create/update/delete requires write permission
- config command validation may read a schema internally even when the end user only has config update permission
- command authorization remains separate from schema validation
The frontend should not expose tenant-specific schema bodies from another host.
The backend lookup must enforce this even if the UI sends a forged hostId.
External schema access has a stricter rule: /r/schema/{schemaAlias} should
only return active schemas that are explicitly marked external_visible = TRUE.
It should return 404 for missing, private, draft, inactive, or unauthorized
aliases so external callers cannot enumerate private schema names.
Testing
The first hardening pass should include tests for:
- create draft schema
- reject invalid
schemaBody - publish schema
- reject edits to published schema body
- retire schema
- tenant-specific lookup
- global fallback lookup
- schema metadata list excluding body
- schema body lookup by
hostId + schemaId + schemaVersion - schema alias validation and global/tenant uniqueness
- external visibility enforcement
/r/schema/{schemaAlias}latest published lookup/r/schema/{schemaAlias}?version=...exact version lookup/r/schema/{schemaAlias}host-specific lookup with global fallback/r/schema/{schemaAlias}direct body and envelope response shapes- create/update schema with
categoryIdsandtagIds - replace and clear schema taxonomy assignments on update
- schema category and tag catalog filters, including active mapping rows
- tenant/global taxonomy collision prevention through
schema_lineage_id - JSON Schema
schema_typevalidation - Schema Catalog visibility, filters, and body-lazy result shape
- config property binding
- valid map/list config property override
- invalid map/list config property override
- scalar validation still works when no schema is attached
- version mismatch and
getFreshSchema
Implementation Order
Implement the schema registry foundation before enabling schema-backed validation in the config update page. The registry work does not need to block the entire config update page, but it must block the Form tab and backend schema enforcement.
Recommended order:
- Harden schema registry data model, lookup, and command validation.
- Add schema alias and external visibility support.
- Add taxonomy linkage through
categoryIds,tagIds, andschema_lineage_id. - Add the Marketplace Schema Catalog entry and body-lazy catalog query.
- Add
/r/schema/{schemaAlias}inportal-service/apps/portal-service. - Add config-property-to-schema binding.
- Add backend config property value validation in config command handlers.
- Extend
getConfigUpdatePropertiesto return schema metadata. - Add lazy schema lookup and typed Form tab in
portal-view. - Add end-to-end tests for schema-backed config updates and catalog discovery.
The config update page can still ship a useful MVP with scalar validation and raw JSON/YAML editors while the registry is being hardened. Once the registry foundation is complete, the same page can enable schema-backed forms and command validation without changing the operator workflow.
Recommendation
Use the schema registry as the authoritative source for structured config
property schemas. Do not implement a separate local schema convention in
portal-view. Stabilize the registry enough for versioned, tenant-aware,
published-schema lookup, then use it to validate map and list config
property values in both the frontend editor and the backend command path.
YAML Rule Registry
React Schema Form
React Schema Form is a form generator based on JSON Schema and form definitions from Light Portal. It renders UI forms to manipulate database entities, and form submissions are automatically hooked into an API endpoint.
Debugging a Component
Encountering a bug in a react-schema-form component can be challenging since the source code may not be directly visible. To debug:
- Set up the Light Portal server if dropdowns are loaded from the server.
- Use the example app in the same project to debug.
Use a Local Alias with Vite
Vite allows creating an alias to point to your library’s src folder. Update the vite.config.ts in your example app:
import { defineConfig } from 'vite';
import react from '@vitejs/plugin-react';
import path from 'path';
export default defineConfig({
plugins: [react()],
resolve: {
alias: {
'react-schema-form': path.resolve(__dirname, '../src'), // Adjust the path to point to the library's `src` folder
},
},
});
Use a Link Script in package.json
Update the example app’s package.json file. In the dependencies section, replace the library’s version with a local path:
{
"dependencies": {
"react-schema-form": "file:../src"
}
}
Library Entry Point
Vite requires an entry point file, typically named index.js or index.ts, in your library’s src folder. Ensure that your library’s src folder includes a properly configured index.js file, like this:
export { default as SchemaForm } from './SchemaForm'
export { default as ComposedComponent } from './ComposedComponent'
export { default as utils } from './utils'
export { default as Array } from './Array'
Without a correctly named and configured entry file, components like SchemaForm may not be imported properly.
Update index.html
If you change the entry point file from main.js to index.js, ensure you update the reference in the index.html file located in the root folder. For example:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/vite.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Vite + React</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="/src/index.js"></script>
</body>
</html>
Sync devDependencies from peerDependencies
When the source code in src is used directly by the example app, the peerDependencies in the example app won’t work for react-schema-form components. To address this, copy the peerDependencies into the devDependencies section of react-schema-form’s package.json. For example:
"devDependencies": {
"@babel/runtime": "^7.26.0",
"@codemirror/autocomplete": "^6.18.2",
"@codemirror/language": "^6.10.6",
"@codemirror/lint": "^6.8.2",
"@codemirror/search": "^6.5.7",
"@codemirror/state": "^6.4.1",
"@codemirror/theme-one-dark": "^6.1.2",
"@codemirror/view": "^6.34.2",
"@emotion/react": "^11.13.5",
"@emotion/styled": "^11.13.5",
"@eslint/js": "^9.13.0",
"@lezer/common": "^1.2.3",
"@mui/icons-material": "^6.1.6",
"@mui/material": "^6.1.6",
"@mui/styles": "^6.1.6",
"@types/react": "^18.3.1",
"@uiw/react-markdown-editor": "^6.1.2",
"@vitejs/plugin-react": "^4.3.3",
"codemirror": "^6.0.1",
"eslint": "^9.13.0",
"eslint-plugin-react": "^7.37.2",
"eslint-plugin-react-hooks": "^5.0.0",
"eslint-plugin-react-refresh": "^0.4.14",
"gh-pages": "^6.2.0",
"globals": "^15.11.0",
"react": "^18.3.1",
"react-dom": "^18.3.1",
"vite": "^6.0.3"
},
"peerDependencies": {
"@babel/runtime": "^7.26.0",
"@codemirror/autocomplete": "^6.18.2",
"@codemirror/language": "^6.10.6",
"@codemirror/lint": "^6.8.2",
"@codemirror/search": "^6.5.7",
"@codemirror/state": "^6.4.1",
"@codemirror/theme-one-dark": "^6.1.2",
"@codemirror/view": "^6.34.2",
"@emotion/react": "^11.13.5",
"@emotion/styled": "^11.13.5",
"@lezer/common": "^1.2.3",
"@mui/icons-material": "^6.1.6",
"@mui/material": "^6.1.6",
"@mui/styles": "^6.1.6",
"@types/react": "^18.3.1",
"@uiw/react-markdown-editor": "^6.1.2",
"codemirror": "^6.0.1",
"react": "^18.3.1",
"react-dom": "^18.3.1"
},
Additionally, ensure the peerDependencies are also synced with the dependencies section of the example app’s package.json. This step allows react-schema-form components to load independently and work seamlessly during development.
Update Source Code
After completing all the updates, perform a clean install for both react-schema-form and the example app. Then, start the server from the example folder using the following command:
yarn dev
Whenever you modify a react-schema-form component, simply refresh the browser to reload the example application and see the updated component in action.
Debug with Visual Studio Code
You can debug the component using Visual Studio Code. There are many tutorials available online that explain how to debug React applications built with Vite, which can help you set up breakpoints, inspect components, and track down issues effectively.
Component dynaselect
dynaselect is a component that renders a dropdown select, either from static options or options loaded dynamically from a server via an API endpoint. It is a wrapper of material ui Autocomplete component. Below is an example form from the example app that demonstrates how to use this component.
{
"schema": {
"type": "object",
"title": "React Component Autocomplete Demo Static Single",
"properties": {
"name": {
"title": "Name",
"type": "string",
"default": "Steve"
},
"host": {
"title": "Host",
"type": "string"
},
"environment": {
"type": "string",
"title": "Environment",
"default": "LOCAL",
"enum": [
"LOCAL",
"SIT1",
"SIT2",
"SIT3",
"UAT1",
"UAT2"
]
},
"stringarraysingle": {
"type": "array",
"title": "Single String Array",
"items": {
"type": "string"
}
},
"stringcat": {
"type": "string",
"title": "Joined Strings"
},
"stringarraymultiple": {
"type": "array",
"title": "Multiple String Array",
"items": {
"type": "string"
}
}
},
"required": [
"name",
"environment"
]
},
"form": [
"name",
{
"key": "host",
"type": "dynaselect",
"multiple": false,
"action": {
"url": "https://localhost/portal/query?cmd=%7B%22host%22%3A%22lightapi.net%22%2C%22service%22%3A%22user%22%2C%22action%22%3A%22listHost%22%2C%22version%22%3A%220.1.0%22%7D"
}
},
{
"key": "environment",
"type": "dynaselect",
"multiple": false,
"options": [
{
"id": "LOCAL",
"label": "Local"
},
{
"id": "SIT1",
"label": "SIT1"
},
{
"id": "SIT2",
"label": "SIT2"
},
{
"id": "SIT3",
"label": "SIT3"
},
{
"id": "UAT1",
"label": "UAT1"
},
{
"id": "UAT2",
"label": "UAT2"
}
]
},
{
"key": "stringarraysingle",
"type": "dynaselect",
"multiple": false,
"options": [
{
"id": "id1",
"label": "label1"
},
{
"id": "id2",
"label": "label2"
},
{
"id": "id3",
"label": "label3"
},
{
"id": "id4",
"label": "label4"
},
{
"id": "id5",
"label": "label5"
},
{
"id": "id6",
"label": "label6"
}
]
},
{
"key": "stringcat",
"type": "dynaselect",
"multiple": true,
"options": [
{
"id": "id1",
"label": "label1"
},
{
"id": "id2",
"label": "label2"
},
{
"id": "id3",
"label": "label3"
},
{
"id": "id4",
"label": "label4"
},
{
"id": "id5",
"label": "label5"
},
{
"id": "id6",
"label": "label6"
}
]
},
{
"key": "stringarraymultiple",
"type": "dynaselect",
"multiple": true,
"options": [
{
"id": "id1",
"label": "label1"
},
{
"id": "id2",
"label": "label2"
},
{
"id": "id3",
"label": "label3"
},
{
"id": "id4",
"label": "label4"
},
{
"id": "id5",
"label": "label5"
},
{
"id": "id6",
"label": "label6"
}
]
}
]
}
Dynamic Options from APIs
The host is a string type field rendered as a dynaselect with multiple set to false. The options for the select are loaded via an API endpoint, with the action URL provided. Note that the cmd query parameter value is encoded because it contains curly brackets {}.
To encode and decode the query parameter value, you can use the following tool:
Encoded:
%7B%22host%22%3A%22lightapi.net%22%2C%22service%22%3A%22user%22%2C%22action%22%3A%22listHost%22%2C%22version%22%3A%220.1.0%22%7D
Decoded:
{"host":"lightapi.net","service":"user","action":"listHost","version":"0.1.0"}
When using the example app to test the react-schema-form with APIs, you need to configure CORS on the light-gateway. Ensure that CORS is enabled only on the light-gateway and not on the backend API, such as hybrid-query.
Here is the example in values.yml for the light-gateway.
# cors.yml
cors.enabled: true
cors.allowedOrigins:
- https://devsignin.lightapi.net
- https://dev.lightapi.net
- https://localhost:3000
- http://localhost:5173
cors.allowedMethods:
- GET
- POST
- PUT
- DELETE
Single string type
For the environment field, the schema defines the type as string, and the form definition specifies multiple: false to indicate it is a single select.
The select result in the model looks like the following:
{
"environment": "SIT1",
}
Single string array type
For the stringarraysingle field, the schema defines the type as a string array, and the form definition specifies multiple: false to indicate it is a single select.
The select result in the model looks like the following:
{
"stringarraysingle": [
"id3"
],
}
Multiple string type
For the stringcat field, the schema defines the type as a string, and the form definition specifies multiple: true to indicate it is a multiple select.
The select result in the model looks like the following:
{
"stringcat": "id2,id4"
}
Multiple string array type
For the stringarraymultiple field, the schema defines the type as a string array, and the form definition specifies multiple: true to indicate it is a multiple select.
The select result in the model looks like the following:
{
"stringarraymultiple": [
"id2",
"id5",
"id3"
],
}
User Management
User Type
The user_type field is a critical part of the user security profile in the JWT token and can be leveraged for fine-grained authorization. In a multi-tenant environment, user_type is presented as a dropdown populated from the reference table configured for the organization. It can be dynamically selected based on the host chosen during the user registration process.
Supported Standard Dropdown Models
-
Employee and Customer
- Dropdown values:
E(Employee),C(Customer) - Default model for
lightapi.nethost. - Suitable for most organizations.
- Dropdown values:
-
Employee, Personal, and Business
- Dropdown values:
E(Employee)P(Personal)B(Business)
- Commonly used for banks where personal and business banking are separated.
- Dropdown values:
Database Configuration
- The
user_typefield is nullable in theuser_ttable by default. - However, you can enforce this field as mandatory in your application via the schema and UI configuration.
On-Prem Deployment
In on-premise environments, the user_type can determine the authentication method:
- Employees: Authenticated via Active Directory.
- Customers: Authenticated via a customer database.
This flexibility allows organizations to tailor the authentication process based on their specific needs and user classifications.
Handling Users with Multi-Host Access
There are two primary ways to handle users who belong to multiple hosts:
- User-Host Mapping Table:
user_t: This table would not have a host_id and would store core user information that is host-independent. The user_id would be unique across all hosts.
user_host_t (or user_tenant_t): This would be a mapping table to represent the many-to-many relationship between users and hosts.
-- user_t (no host_id, globally unique user_id)
CREATE TABLE user_t (
user_id UUID PRIMARY KEY DEFAULT uuid_generate_v4(), -- UUID is recommended
-- ... other user attributes (e.g., name, email)
);
-- user_host_t (mapping table)
CREATE TABLE user_host_t (
user_id UUID NOT NULL,
host_id UUID NOT NULL,
-- ... other relationship-specific attributes (e.g., roles within the host)
PRIMARY KEY (user_id, host_id),
FOREIGN KEY (user_id) REFERENCES user_t (user_id) ON DELETE CASCADE,
FOREIGN KEY (host_id) REFERENCES host_t (host_id) ON DELETE CASCADE -- Assuming you have a hosts_t
);
- Duplicating User Records (Less Recommended):
user_t: You would keep host_id in this table, and the primary key would be (host_id, user_id).
User Duplication: If a user needs access to multiple hosts, you would duplicate their user record in users_t for each host they belong to, each with a different host_id.
Why User-Host Mapping is Generally Preferred:
-
Data Integrity: Avoids data duplication and the potential for inconsistencies that come with it. If a user’s core information (e.g., name, email) changes, you only need to update it in one place in user_t.
-
Flexibility: Easier to add or remove a user’s access to hosts without affecting their core user data.
-
Querying: While you’ll need joins to get a user’s hosts or a host’s users, these joins are straightforward using the mapping table.
-
Scalability: Better scalability as your user base and the number of hosts they can access grow.
Distributing Tables in a Multi-Host User Scenario:
With the user-host mapping approach:
-
user_t: This table would likely be a reference table in Citus (replicated to all nodes) since it does not have a host_id for distribution.
-
user_host_t: This table would be distributed by host_id.
-
Other tables (e.g., employees_t, api_endpoints_t, etc.): These would be distributed by host_id as before.
When querying, you would typically:
-
Start with the user_hosts_t table to find the hosts a user has access to.
-
Join with other tables (distributed by host_id) based on the host_id to retrieve tenant-specific data.
Choosing the Right user_id Primary Key:
Here’s a comparison of the options for the user_id primary key in user_t:
1. UUID (user_id)
- Pros:
- Globally Unique: Avoids collisions across hosts or when scaling beyond the current setup.
- Security: Difficult to guess or enumerate.
- Scalability: Well-suited for distributed environments like Citus.
- Cons:
- Storage: Slightly larger storage size compared to integers.
- Readability: Not human-readable, which can be inconvenient for debugging.
- Recommendation:
This is generally the best option for auser_idin a multi-tenant, distributed environment.
2. Email (email)
- Pros:
- Human-Readable: Easy to identify and manage.
- Login Identifier: Often used as a natural login credential.
- Cons:
- Uniqueness Challenges: Enforcing global uniqueness across all hosts may require complex constraints or application logic.
- Changeability: If emails change, cascading updates can complicate the database.
- Security: Using emails as primary keys can expose sensitive user data if not handled securely.
- Performance: String comparisons are slower than those for integers or UUIDs.
- Recommendation:
Not recommended as a primary key, especially in a multi-tenant or distributed setup.
3. User-Chosen Unique ID (e.g., username)
- Pros:
- Human-Readable: Intuitive and user-friendly.
- Cons:
- Uniqueness Challenges: Enforcing global uniqueness is challenging and may require complex constraints.
- Changeability: Users may request username changes, causing cascading update issues.
- Security: Usernames are easier to guess or enumerate compared to UUIDs.
- Recommendation:
Not recommended as a primary key in a multi-tenant, distributed environment.
In Conclusion:
-
Use a User-Host Mapping Table:
This is the best approach to handle users who belong to multiple hosts in a multi-tenant Citus environment. -
Use UUID for
user_id:
UUIDs are the most suitable option for theuser_idprimary key inuser_tdue to their global uniqueness, security, and scalability. -
Distribute by
host_id:
Distribute tables that need sharding byhost_id, and ensure that foreign keys to distributed tables includehost_id. -
Use Reference Tables:
For tables likeuser_tthat don’t have ahost_id, designate them as reference tables in Citus.
This approach provides a flexible and scalable foundation for managing users with multi-host access in your Citus-based multi-tenant application.
User Tables
Using a single user_t table with a user_type discriminator is a good approach for managing both employees and customers in a unified way. Adding optional referral relationships for customers adds a nice dimension as well. Here’s a suggested table schema in PostgreSQL, along with explanations and some considerations:
user_t (User Table): This table will store basic information common to both employees and customers.
CREATE TABLE user_t (
user_id VARCHAR(24) NOT NULL,
email VARCHAR(255) NOT NULL,
password VARCHAR(1024) NOT NULL,
language CHAR(2) NOT NULL,
first_name VARCHAR(32) NULL,
last_name VARCHAR(32) NULL,
user_type CHAR(1) NULL, -- E employee C customer or E employee P personal B business
phone_number VARCHAR(20) NULL,
gender CHAR(1) NULL,
birthday DATE NULL,
country VARCHAR(3) NULL,
province VARCHAR(32) NULL,
city VARCHAR(32) NULL,
address VARCHAR(128) NULL,
post_code VARCHAR(16) NULL,
verified BOOLEAN NOT NULL DEFAULT false,
token VARCHAR(64) NULL,
locked BOOLEAN NOT NULL DEFAULT false,
nonce BIGINT NOT NULL DEFAULT 0,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL
);
ALTER TABLE user_t ADD CONSTRAINT user_pk PRIMARY KEY ( user_id );
ALTER TABLE user_t ADD CONSTRAINT user_email_uk UNIQUE ( email );
user_host_t (User to host relationship or mapping):
CREATE TABLE user_host_t (
host_id VARCHAR(24) NOT NULL,
user_id VARCHAR(24) NOT NULL,
-- other relationship-specific attributes (e.g., roles within the host)
PRIMARY KEY (host_id, user_id),
FOREIGN KEY (user_id) REFERENCES user_t (user_id) ON DELETE CASCADE,
FOREIGN KEY (host_id) REFERENCES host_t (host_id) ON DELETE CASCADE
);
employee_t (Employee Table): This table will store employee-specific attributes.
CREATE TABLE employee_t (
host_id VARCHAR(22) NOT NULL,
employee_id VARCHAR(50) NOT NULL, -- Employee ID or number or ACF2 ID. Unique within the host.
user_id VARCHAR(22) NOT NULL,
title VARCHAR(255) NOT NULL,
manager_id VARCHAR(50), -- manager's employee_id if there is one.
hire_date DATE,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, employee_id),
FOREIGN KEY (host_id, user_id) REFERENCES user_host_t(host_id, user_id) ON DELETE CASCADE,
FOREIGN KEY (host_id, manager_id) REFERENCES employee_t(host_id, employee_id) ON DELETE CASCADE
);
customer_t (Customer Table): This table will store customer-specific attributes.
CREATE TABLE customer_t (
host_id VARCHAR(24) NOT NULL,
customer_id VARCHAR(50) NOT NULL,
user_id VARCHAR(24) NOT NULL,
-- Other customer-specific attributes
referral_id VARCHAR(22), -- the customer_id who refers this customer.
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, customer_id),
FOREIGN KEY (host_id, user_id) REFERENCES user_host_t(host_id, user_id) ON DELETE CASCADE,
FOREIGN KEY (host_id, referral_id) REFERENCES customer_t(host_id, customer_id) ON DELETE CASCADE
);
position_t (Position Table): Defines different positions within the organization for employees.
CREATE TABLE position_t (
host_id VARCHAR(22) NOT NULL,
position_id VARCHAR(22) NOT NULL,
position_name VARCHAR(255) UNIQUE NOT NULL,
description TEXT,
inherit_to_ancestor BOOLEAN DEFAULT FALSE,
inherit_to_sibling BOOLEAN DEFAULT FALSE,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, position_id)
);
user_position_t (Employee Position Table): Links employees to their positions with effective dates.
CREATE TABLE employee_position_t (
host_id VARCHAR(22) NOT NULL,
employee_id VARCHAR(50) NOT NULL,
position_id VARCHAR(22) NOT NULL,
position_type CHAR(1) NOT NULL, -- P position of own, D inherited from a decendant, S inherited from a sibling.
start_date DATE NOT NULL,
end_date DATE,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, employee_id, position_id),
FOREIGN KEY (host_id, position_id) REFERENCES position_t(host_id, position_id) ON DELETE CASCADE
);
Authorization Strategies
In order to link users to API endpoints for authorization, we will adpot the following approaches with a rule engine to enforce the policies in the sidecar of the API with access-control middleware handler.
A. Role-Based Access Control (RBAC)
This is a common and relatively simple approach. You define roles (e.g., “admin,” “editor,” “viewer”) and assign permissions to those roles. Users are then assigned to one or more roles.
Role Table:
CREATE TABLE role_t (
host_id VARCHAR(22) NOT NULL,
role_id VARCHAR(22) NOT NULL,
role_name VARCHAR(255) UNIQUE NOT NULL,
description TEXT,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, role_id)
);
Role-Endpoint Permission Table:
CREATE TABLE role_permission_t (
host_id VARCHAR(32) NOT NULL,
role_id VARCHAR(32) NOT NULL,
endpoint_id VARCHAR(64) NOT NULL,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, role_id, endpoint_id),
FOREIGN KEY (host_id, role_id) REFERENCES role_t(host_id, role_id) ON DELETE CASCADE,
FOREIGN KEY (endpoint_id) REFERENCES api_endpoint_t(endpoint_id) ON DELETE CASCADE
);
Role-User Assignment Table:
CREATE TABLE role_user_t (
host_id VARCHAR(22) NOT NULL,
role_id VARCHAR(22) NOT NULL,
user_id VARCHAR(22) NOT NULL,
start_date DATE NOT NULL DEFAULT CURRENT_DATE,
end_date DATE,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, role_id, user_id, start_date),
FOREIGN KEY (user_id) REFERENCES user_t(user_id) ON DELETE CASCADE,
FOREIGN KEY (host_id, role_id) REFERENCES role_t(host_id, role_id) ON DELETE CASCADE
);
B. User-Based Access Control (UBAC)
This approach assigns permissions directly to users, allowing for very fine-grained control. It’s more flexible but can become complex to manage if you have a lot of users and endpoints. It should only be used for temporary access.
User-Endpoint Permissions Table:
CREATE TABLE user_permission_t (
user_id VARCHAR(22) NOT NULL,
host_id VARCHAR(22) NOT NULL,
endpoint_id VARCHAR(22) NOT NULL,
start_date DATE NOT NULL DEFAULT CURRENT_DATE,
end_date DATE,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (user_id, host_id, endpoint_id),
FOREIGN KEY (user_id) REFERENCES user_t(user_id) ON DELETE CASCADE,
FOREIGN KEY (endpoint_id) REFERENCES api_endpoint_t(endpoint_id) ON DELETE CASCADE
);
C. Group-Based Access Control (GBAC)
You can group users into teams or departments and assign permissions to those groups. This is useful when you want to manage permissions for sets of users with similar access needs.
Groups Table:
CREATE TABLE group_t (
host_id VARCHAR(32) NOT NULL,
group_id VARCHAR(32) NOT NULL,
group_name VARCHAR(255) UNIQUE NOT NULL,
description TEXT,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, group_id)
);
Group-Endpoint Permission Table:
CREATE TABLE group_permission_t (
host_id VARCHAR(32) NOT NULL,
group_id VARCHAR(32) NOT NULL,
endpoint_id VARCHAR(32) NOT NULL,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, group_id, endpoint_id),
FOREIGN KEY (host_id, group_id) REFERENCES group_t(host_id, group_id) ON DELETE CASCADE,
FOREIGN KEY (endpoint_id) REFERENCES api_endpoint_t(endpoint_id) ON DELETE CASCADE
);
Group-User Membership Table:
CREATE TABLE group_user_t (
host_id VARCHAR(22) NOT NULL,
group_id VARCHAR(22) NOT NULL,
user_id VARCHAR(22) NOT NULL,
start_date DATE NOT NULL DEFAULT CURRENT_DATE,
end_date DATE,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, group_id, user_id, start_date),
FOREIGN KEY (user_id) REFERENCES user_t(user_id) ON DELETE CASCADE,
FOREIGN KEY (host_id, group_id) REFERENCES group_t(host_id, group_id) ON DELETE CASCADE
);
D. Attribute-Based Access Control (ABAC)
Attribute Table:
CREATE TABLE attribute_t (
host_id VARCHAR(22) NOT NULL,
attribute_id VARCHAR(22) NOT NULL,
attribute_name VARCHAR(255) UNIQUE NOT NULL, -- The name of the attribute (e.g., "department," "job_title," "project," "clearance_level," "location").
attribute_type VARCHAR(50) CHECK (attribute_type IN ('string', 'integer', 'boolean', 'date', 'float', 'list')), -- Define allowed data types
description TEXT,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, attribute_id)
);
- Attribute User Table:
CREATE TABLE attribute_user_t (
host_id VARCHAR(22) NOT NULL,
attribute_id VARCHAR(22) NOT NULL,
user_id VARCHAR(22) NOT NULL, -- References users_t
attribute_value TEXT, -- Store values as strings; you can cast later
start_date DATE NOT NULL DEFAULT CURRENT_DATE,
end_date DATE,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, attribute_id, user_id, start_date),
FOREIGN KEY (user_id) REFERENCES user_t(user_id) ON DELETE CASCADE,
FOREIGN KEY (host_id, attribute_id) REFERENCES attribute_t(host_id, attribute_id) ON DELETE CASCADE
);
- Attribute Permission Table:
CREATE TABLE attribute_permission_t (
host_id VARCHAR(32) NOT NULL,
attribute_id VARCHAR(32) NOT NULL,
endpoint_id VARCHAR(32) NOT NULL, -- References api_endpoints_t
attribute_value TEXT,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (host_id, attribute_id, endpoint_id),
FOREIGN KEY (endpoint_id) REFERENCES api_endpoint_t(endpoint_id) ON DELETE CASCADE,
FOREIGN KEY (host_id, attribute_id) REFERENCES attribute_t(host_id, attribute_id) ON DELETE CASCADE
);
How it Works:
-
Define Attributes: Define all relevant attributes in attribute_t. Think about all the properties of your users, resources, and environment that might be used in access control decisions.
-
Assign Attributes to Users: Populate attribute_user_t to associate attribute values with users.
-
Assign Attributes to Endpoints: Populate attribute_permission_t to associate attribute values with API endpoints.
-
Write Policies: Create policy rules in rule engine. These rules should use the attribute names defined in attribute_t.
-
Policy Evaluation (at runtime):
-
The policy engine receives the subject (user), resource (API endpoint), and action (HTTP method) of the request.
-
The engine retrieves the relevant attributes from the user_attribute_t and attribute_permission_t tables.
-
The engine evaluates the policy rule from the relevant policies against the attributes.
-
Based on the policy evaluation result, access is either granted or denied.
Key Advantages of ABAC:
-
Fine-Grained Control: Express very specific access rules.
-
Centralized Policy Management: Policies are stored centrally and can be easily updated.
-
Flexibility and Scalability: Adapts easily to changing requirements.
-
Auditing and Compliance: Easier to audit and demonstrate compliance.
Format of attributes in JWT token:
Unlike roles, groups and positions that can be concatanated as a string, an attribut is a key/value pair. We need to format multiple attributes into a string and put it into a token.
Challenges
-
Spaces: The primary issue is that simple key-value pairs like key1:value1 key2:value2 will not work when value contain spaces.
-
Escaping: We need a way to escape characters that may confuse the parser, for example if the value also contains a :.
-
Readability: The format should be reasonably readable for debugging and human consumption.
-
Parsing: The format should be easy to parse on the application side.
Options
- Comma-Separated Key-Value Pairs with Escaping:
-
Format: key1=value1,key2=value2_with_spaces,key3=value3,with,commas
-
Escaping: Use backslash \ to escape commas and backslashes within the values. You can also escape spaces to make it more clear \
-
Pros: Simple to implement, relatively easy to parse using splitting by comma and then by =.
-
Cons: Can become hard to read with complex values, requires proper escaping, will become unreadable if \ need to be escaped.
- Custom Delimiter and Escaping:
-
Format: key1^=^value1~key2^=^value2 with spaces~key3^=^value3~
-
Delimiter: Use ^=^ as delimiter for key and value and use ~ for different attributes.
-
Pros: You can avoid many escaping issues and keep spaces, easier to read than comma separated values.
-
Cons: Need to choose delimiter carefully to make sure it is unique.
- URL-Encoded Key-Value Pairs:
-
Format: key1=value1&key2=value+with+spaces&key3=value3%2Cwith%2Ccommas
-
Pros: Well-established standard, handles spaces and special characters well.
-
Cons: Requires URL encoding and decoding, slightly more overhead, can be less readable.
-
Recommended Approach: Custom Delimiter with Simple Escaping
We recommend the Custom Delimiter with Simple Escaping approach for your use case. It’s a good balance between simplicity, readability, and the ability to handle spaces within values. It avoids the need to rely on complex URL encoding and also avoids the unreadability issue of using comma with backslash escaping.
JWT Security Claims
Using the tables defined above, follow these steps to create an authorization code token with user security claims:
-
uid
Theentity_id(e.g.,employee_idfor employees andcustomer_idfor customers) should be assigned to theuidclaim in the JWT. Thisuidwill be used by the response transformer to filter the response for the user and must represent a business identifier.Examples:
- Employee: Use the ACF2 ID as the
uid. - Customer: Use the CIF ID as the
uid(e.g., in a banking context).
- Employee: Use the ACF2 ID as the
-
role
Include a list of roles associated with the user. -
grp
Add a list of groups the user belongs to. -
att
Include a list of key-value pairs representing user attributes. -
posInclude a list of positions for the user. -
hostThe host of the user.
Example Token
eyJraWQiOiJUal9sX3RJQlRnaW5PdFFiTDBQdjV3IiwiYWxnIjoiUlMyNTYifQ.eyJpc3MiOiJ1cm46Y29tOm5ldHdvcmtudDpvYXV0aDI6djEiLCJhdWQiOiJ1cm46Y29tLm5ldHdvcmtudCIsImV4cCI6MTczNDA2NDU5NSwianRpIjoicEs4WEtDZkU1aVFSdWdlQThJWXBwZyIsImlhdCI6MTczNDA2Mzk5NSwibmJmIjoxNzM0MDYzODc1LCJ2ZXIiOiIxLjAiLCJ1aWQiOiJzaDM1IiwidXR5IjoiRSIsImNpZCI6ImY3ZDQyMzQ4LWM2NDctNGVmYi1hNTJkLTRjNTc4NzQyMWU3MiIsImNzcmYiOiItTUN4OGhZRlF1bVZ3NFZkRDVHbEd3Iiwic2NwIjpbInBvcnRhbC5yIiwicG9ydGFsLnciLCJyZWYuciIsInJlZi53Il0sInJvbGUiOiJhZG1pbiB1c2VyIiwiYzEiOiIzNjEiLCJjMiI6IjY3IiwiZ3JwIjoiZGVsZXRlIGluc2VydCBzZWxlY3QgdXBkYXRlIiwiYXR0IjoiY291bnRyeV49XkNBTn5wZXJhbmVudCBlbXBsb3llZV49XnRydWV-c2VjdXJpdHlfY2xlYXJhbmNlX2xldmVsXj1eMiIsInBvcyI6IkFQSVBsYXRmb3JtRGVsaXZlcnkiLCJob3N0IjoiTjJDTXcwSEdRWGVMdkMxd0JmbG4yQSJ9.Gky_rR9hreP04GZm-0H_HBBAeDIPhQ9tsNuZclUzTdkMrYay40kcNk4jWkPdMcxfIfIbGj2eqSQgNhkBuym2yc6HsRF0nukZhYSGklVNXFe3R-0DdKwxxWyqvXyWDvrQtme0ttT2tYGTRRCZXnHDRMUFeDSz7kVjjIj3WymjFyxWBnWnBOjYqDL34652Fb8c7hWME0nSxbWO0ZvPRDhRM-l0nDGNm2ojq-3sjaU_pRywYahXP-wtnNSLwvctFgONPWSM9Ie6FqwRmYBFVo8OE0VdTRvUfnO4mL1O2UbTfxzbNJFv4HP1mSZG_SSB5j3t_RuZLfUMIajFi105ze2PUg
And the payload:
{
"iss": "urn:com:networknt:oauth2:v1",
"aud": "urn:com.networknt",
"exp": 1734064595,
"jti": "pK8XKCfE5iQRugeA8IYppg",
"iat": 1734063995,
"nbf": 1734063875,
"ver": "1.0",
"uid": "sh35",
"uty": "E",
"cid": "f7d42348-c647-4efb-a52d-4c5787421e72",
"csrf": "-MCx8hYFQumVw4VdD5GlGw",
"scp": [
"portal.r",
"portal.w"
],
"role": "admin user",
"c1": "361",
"c2": "67",
"grp": "delete insert select update",
"att": "country^=^CAN~peranent employee^=^true~security_clearance_level^=^2",
"pos": "APIPlatformDelivery",
"host": "N2CMw0HGQXeLvC1wBfln2A"
}
Group and Position Management
Define Groups Related to User Category
You can create groups that align with teams, departments, or other organizational units. These groups are relatively static and reflect the overall organizational structure. Use a separate table, group_t, as described earlier, to store these groups. Groups can be applied to all users regardless of their user type.
Use the Employee Reporting Structure to Manage Positions
Positions are similar to groups in managing user permissions, but they leverage the organizational reporting structure to propagate permissions between team members and their direct manager.
-
Position Flags
Each position in the
position_ttable has two flags:
inherit_to_ancestor: Determines if the position is inherited by a subordinate.inherit_to_sibling: Determines if the position is inherited by team members (siblings) under the same manager.
-
Responsibilities
The application is responsible for propagating positions:
- Between Siblings: Assigning inherited positions to team members under the same manager.
- To the Manager: Assigning inherited positions to the direct manager.
-
User Interface for Position Management
A user interface (UI) can be implemented to simplify position management:
- Feature: List all potential inherited positions for selection when adding a new user or changing a manager.
- Functionality: Allow administrators to choose specific positions to inherit for users and managers dynamically.
Use Both Groups and Positions
You can choose to use both groups and positions for your organization. However, you need to ensure that groups and positions categorize users across different dimensions. In general, groups should be used for customers, while positions should be used for employees.
User Login Query
Here is the query to run against the database tables upon a user login request:
SELECT
u.user_id,
u.user_type,
CASE
WHEN u.user_type = 'E' THEN e.employee_id
WHEN u.user_type = 'C' THEN c.customer_id
ELSE NULL
END AS entity_id,
CASE WHEN u.user_type = 'E' THEN string_agg(DISTINCT p.position_name, ' ' ORDER BY p.position_name) ELSE NULL END AS positions,
string_agg(DISTINCT r.role_name, ' ' ORDER BY r.role_name) AS roles,
string_agg(DISTINCT g.group_name, ' ' ORDER BY g.group_name) AS groups,
CASE
WHEN COUNT(DISTINCT at.attribute_name || '^=^' || aut.attribute_value) > 0 THEN string_agg(DISTINCT at.attribute_name || '^=^' || aut.attribute_value, '~' ORDER BY at.attribute_name || '^=^' || aut.attribute_value)
ELSE NULL
END AS attributes
FROM
user_t AS u
LEFT JOIN
user_host_t AS uh ON u.user_id = uh.user_id
LEFT JOIN
role_user_t AS ru ON u.user_id = ru.user_id
LEFT JOIN
role_t AS r ON ru.host_id = r.host_id AND ru.role_id = r.role_id
LEFT JOIN
attribute_user_t AS aut ON u.user_id = aut.user_id
LEFT JOIN
attribute_t AS at ON aut.host_id = at.host_id AND aut.attribute_id = at.attribute_id
LEFT JOIN
group_user_t AS gu ON u.user_id = gu.user_id
LEFT JOIN
group_t AS g ON gu.host_id = g.host_id AND gu.group_id = g.group_id
LEFT JOIN
employee_t AS e ON uh.host_id = e.host_id AND u.user_id = e.user_id
LEFT JOIN
customer_t AS c ON uh.host_id = c.host_id AND u.user_id = c.user_id
LEFT JOIN
employee_position_t AS ep ON e.host_id = ep.host_id AND e.employee_id = ep.employee_id
LEFT JOIN
position_t AS p ON ep.host_id = p.host_id AND ep.position_id = p.position_id
WHERE
u.email = '[email protected]'
GROUP BY
u.user_id, u.user_type, e.employee_id, c.customer_id;
And here is an example result from the test database:
utgdG50vRVOX3mL1Kf83aA E sh35 APIPlatformDelivery admin user delete insert select update country^=^CAN~peranent employee^=^true~security_clearance_level^=^2
Parse Attribute String
The query above returns attributes in a customized format. These attributes can be parsed using the Util.parseAttributes method available in the light-4j utility module
Portal View and Default Role
Given the flexibility of fine-grained authorization approaches, users can choose one or more methods to suit their business requirements. However, in scenarios where RBAC (Role-Based Access Control) is not utilized, the role claim may not exist in the custom claims of the JWT token.
Handling Missing role in JWT
For the portal-view application, at least one role is required to filter menu items. To address cases where no roles are present in the JWT:
-
Default Role Assignment:
If theroleclaim is absent in the JWT, the system will:- Assign a default role,
"user", to ensure compatibility. - Include this role in a
rolesfield in the browser cookie.
- Assign a default role,
-
Cookie Roles Field:
- The
rolesfield in the cookie will contain a single role:"user". - This ensures the portal-view can still function as expected by displaying the appropriate menu items for users.
- The
Example Workflow
- A user authenticates, and their JWT is generated without a
roleclaim. - During authentication handling:
- The StatelessAuthHandler checks for the presence of the
roleclaim. - If no roles are found, the
"user"role is added to therolesfield in the cookie.
- The StatelessAuthHandler checks for the presence of the
- The portal-view reads the
rolesfield from the cookie to filter menu items appropriately.
This approach provides a seamless experience while maintaining compatibility with applications requiring roles for authorization or UI customization.
Private Messages
Problem
Portal users need a way to exchange private messages from the user profile without exposing email addresses to each other. The sender should only need a recipient user id or a display-safe user label. The backend can resolve email internally when it needs to send an external notification, but email must not be part of the user-facing message contract.
Current State
The current codebase already has a partial private-message skeleton:
user-commandexposeslightapi.net/user/sendMessage/0.1.0.- The
sendMessagerequest containsuserId,subject, andcontent. light-portaldefinesPrivateMessageSentEvent.portal-dbdefinesmessage_t.portal-viewhas a mail menu, a private messages page, and aprivateMessageform.user-queryexposeslightapi.net/user/getPrivateMessage/0.1.0.
The current implementation is not complete enough to support production use:
GetPrivateMessagehas its real implementation commented out and currently returnsnull.SendMessageresolves the recipient throughqueryUserById, then stores the whole response astoEmail. That lookup currently returns too much user data, including email and sensitive fields that should not be exposed through a peer messaging flow.SendMessagedoes not putfromIdinto event data, but the projection code readsfromIdfrom event data.- The
message_ttable now hashost_id NOT NULL, but the projection insert does not writehost_id. - The table is inbox-style storage, keyed by sender and nonce, and does not model conversations, read state, participant visibility, or per-user delete.
- The UI mostly relies on the mail menu response and navigation state. The messages page should load its own data from the query API.
- The existing private-message tests are disabled stubs.
Goals
- Let one logged-in user send a message to another portal user without knowing or seeing the recipient email.
- Keep the message model host-scoped so tenant boundaries are explicit.
- Derive sender identity from the authorization token, not from form input.
- Store user ids in message records and events. Do not store recipient email in the message projection unless a short migration bridge requires it.
- Support an inbox page, unread badge, conversation view, reply, read state, and per-user hide/delete.
- Keep email notification as an optional side effect that resolves the recipient email internally.
- Provide a path from the existing
message_tskeleton to a conversation-based model without breaking existing UI routes immediately.
Non-Goals
- Do not build group chat in the first phase.
- Do not expose email addresses in message APIs, events, UI state, or task context.
- Do not use private messages as an audit or support-ticket system.
- Do not implement WebSocket or SSE push in the first phase. Polling is enough until the read/write model is stable.
- Do not make public user lookup broader as part of this feature.
Privacy Rules
Private messages should be user-id based at every external boundary.
The UI may show:
- Display name.
- Avatar or initials.
- User id when no better label exists.
- Message subject, preview, content, and timestamps.
The UI must not show:
- Sender email.
- Recipient email.
- Password, token, nonce, or other profile internals from
user_t.
The backend may resolve recipient email only inside trusted server code for
external email notification. That internal lookup should return the minimum
fields required, ideally user_id, email, current host membership, and a
display label.
Recommended Data Model
For a chat-like experience, introduce conversation identity instead of treating each message as an isolated inbox row.
CREATE TABLE private_conversation_t (
host_id UUID NOT NULL,
conversation_id UUID NOT NULL,
participant_low_id UUID NOT NULL,
participant_high_id UUID NOT NULL,
created_ts TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT CURRENT_TIMESTAMP,
last_message_id UUID NULL,
last_message_ts TIMESTAMP WITH TIME ZONE NULL,
PRIMARY KEY (host_id, conversation_id),
UNIQUE (host_id, participant_low_id, participant_high_id),
FOREIGN KEY (host_id) REFERENCES host_t(host_id) ON DELETE CASCADE
);
participant_low_id and participant_high_id are the two sorted user ids. This
gives each pair of users one stable conversation per host without relying on
email.
CREATE TABLE private_message_t (
host_id UUID NOT NULL,
message_id UUID NOT NULL,
conversation_id UUID NOT NULL,
from_user_id UUID NOT NULL,
to_user_id UUID NOT NULL,
subject VARCHAR(256) NULL,
content TEXT NOT NULL,
send_ts TIMESTAMP WITH TIME ZONE NOT NULL,
PRIMARY KEY (host_id, message_id),
FOREIGN KEY (host_id, conversation_id)
REFERENCES private_conversation_t(host_id, conversation_id)
ON DELETE CASCADE
);
CREATE TABLE private_message_state_t (
host_id UUID NOT NULL,
message_id UUID NOT NULL,
user_id UUID NOT NULL,
read_ts TIMESTAMP WITH TIME ZONE NULL,
deleted_ts TIMESTAMP WITH TIME ZONE NULL,
PRIMARY KEY (host_id, message_id, user_id),
FOREIGN KEY (host_id, message_id)
REFERENCES private_message_t(host_id, message_id)
ON DELETE CASCADE
);
The state table keeps read and delete behavior per participant. A user deleting a message should hide it from that user only. It should not erase the other participant’s copy.
Recommended indexes:
CREATE INDEX idx_private_conversation_last_message
ON private_conversation_t (host_id, participant_low_id, participant_high_id, last_message_ts DESC);
CREATE INDEX idx_private_message_conversation_ts
ON private_message_t (host_id, conversation_id, send_ts DESC);
CREATE INDEX idx_private_message_to_user_ts
ON private_message_t (host_id, to_user_id, send_ts DESC);
CREATE INDEX idx_private_message_state_unread
ON private_message_state_t (host_id, user_id)
WHERE read_ts IS NULL AND deleted_ts IS NULL;
If the first implementation needs to reuse message_t, treat it as a migration
bridge only. Add from_user_id, to_user_id, message_id, read_ts, and
per-user delete columns, then migrate to the conversation tables once the API
contract is stable.
Event Model
Keep the event-driven command/query pattern. A message send should create a CloudEvent and the query-side projection should update the private-message tables.
Recommended event data:
{
"hostId": "019...",
"conversationId": "019...",
"messageId": "019...",
"fromUserId": "019...",
"toUserId": "019...",
"subject": "Question about the API",
"content": "Can you take a look at this?"
}
fromUserId and hostId are derived from the token. toUserId, subject, and
content come from validated request data. conversationId can be generated by
the command side after looking up or creating the pair conversation, or it can
be derived during projection from the participant pair.
Do not put toEmail into PrivateMessageSentEvent. Email notification should
be a separate trusted server-side action.
API Contracts
Send Message
Keep the existing sendMessage action name for compatibility, but change the
contract to be user-id based.
{
"toUserId": "019...",
"conversationId": "019...",
"subject": "Question about the API",
"content": "Can you take a look at this?"
}
conversationId is optional. If absent, the backend resolves or creates the
conversation for the current user and toUserId.
Server responsibilities:
- Require an authorization-code token.
- Derive
fromUserIdfrom the token. - Derive
hostIdfrom the active user host. - Validate that
toUserIdbelongs to the same host. - Reject empty content and enforce size limits.
- Optionally reject self-messages unless a product decision allows notes to self.
- Write the event through the existing command event-store path.
- Send optional external email notification after the command is accepted.
Conversation List
Add or evolve a query endpoint for the inbox list.
{
"offset": 0,
"limit": 25
}
The backend derives hostId and userId from the token. The response should
include only conversations involving the current user.
{
"total": 1,
"conversations": [
{
"conversationId": "019...",
"otherUserId": "019...",
"otherUserLabel": "Jane Smith",
"lastMessageTs": "2026-05-08T13:30:00Z",
"lastMessagePreview": "Can you take a look at this?",
"unreadCount": 2
}
]
}
Conversation Messages
{
"conversationId": "019...",
"offset": 0,
"limit": 50
}
The backend validates that the current user is one of the participants.
{
"conversationId": "019...",
"messages": [
{
"messageId": "019...",
"fromUserId": "019...",
"fromUserLabel": "Jane Smith",
"subject": "Question about the API",
"content": "Can you take a look at this?",
"sendTs": "2026-05-08T13:30:00Z",
"read": false
}
]
}
Unread Count
The mail badge should call a count endpoint instead of loading all messages.
{
"count": 3
}
Mark Read and Delete
markPrivateConversationRead should mark unread rows in
private_message_state_t for the current user and conversation.
deletePrivateMessage or hidePrivateConversation should set deleted_ts for
the current user only.
Operational Cleanup
Private messages are user content, not operational status rows. They should not be hard-deleted only because they are old while either participant can still see them.
The operational cleanup job may purge active private-message rows only when all
participant state rows for the message have deleted_ts set and the latest
deleted_ts is older than privateMessageRetentionDays.
Cleanup responsibilities:
- Select purge candidates from
private_message_tjoined toprivate_message_state_t. - Require every participant state row for the message to have
deleted_tsset. - Use
MAX(deleted_ts)as the retention clock so the grace period starts after the last participant deletes the message. - Delete
private_message_state_trows first, then delete theprivate_message_trow in the same transaction. - Leave
private_conversation_trows in place so the participant pair keeps a stable conversation identity if a new message is sent later. - Skip private-message cleanup when
privateMessageRetentionDaysis less than or equal to zero.
The cleanup job should not purge visible messages, partially deleted messages, or recently deleted-by-all messages. A separate maximum retention policy for undeleted private messages would need an explicit product/security decision.
Authorization
The command and query handlers must not trust user ids supplied by the client for the current user. The current user is always the token subject.
Rules:
- A sender can send only as themself.
- A user can read only conversations where they are a participant.
- A user can mark read or delete only their own state rows.
- Admin visibility should be a separate explicit support/admin endpoint if it is needed later.
- Cross-host messaging should be rejected in the first phase. If cross-host messaging is later needed, the contract must model the recipient host explicitly and pass a product/security review.
Portal View
Use the current profile surfaces but make them data-driven:
MailMenushould poll unread count and show a small list of recent conversations only after the menu opens./app/messagesshould fetch conversation data directly. It should not depend onlocation.statefromMailMenu.- The
privateMessageform should usetoUserId, notuserId, to avoid confusing recipient identity with the current user. - Reply should prefill
toUserIdand optionallyconversationId. - User-facing labels should come from a display-safe user label endpoint.
- Empty inbox, loading, and error states should be explicit.
The first UI can be an inbox plus conversation thread. Real-time typing, presence, attachments, and rich-text editing are later enhancements.
Migration Plan
Phase 0: Stop the Broken Behavior
- Make
GetPrivateMessagereturn valid JSON even before the new model is complete. - Fix the existing projection insert to include
host_idifmessage_tremains in use. - Ensure
SendMessagestores sender identity from the token. - Stop using broad
queryUserByIdoutput as a recipient email value.
Phase 1: User-ID Based Backend
- Add the conversation/message/state tables.
- Update
PrivateMessageSentEventto usefromUserIdandtoUserId. - Add a trusted recipient resolver that returns only internal fields needed for validation and optional email notification.
- Implement conversation list, conversation messages, unread count, mark-read, and hide/delete APIs.
Phase 2: Portal View
- Update the mail badge to use unread count.
- Update
/app/messagesto load data directly. - Update the
privateMessageform and reply paths to usetoUserId. - Remove email assumptions from task context and UI state.
Phase 3: Cleanup
- Remove
to_emailfrom the active private-message path. - Remove disabled private-message tests and replace them with focused coverage.
- Ensure operational cleanup targets the active private-message tables and purges only messages deleted by all participants after the retention window.
- Add optional push delivery later if polling becomes insufficient.
Testing
Backend tests should cover:
- Sender is derived from token and cannot be spoofed.
- Recipient must belong to the current host.
- Message event contains user ids, not emails.
- Projection writes host-scoped conversation and message rows.
- Inbox query returns only conversations for the current user.
- Conversation query rejects non-participants.
- Unread count increments for the recipient and clears after mark-read.
- Delete/hide affects only the current user’s state.
- Operational cleanup purges only messages deleted by all participants after retention and keeps visible, partially deleted, and recently deleted messages.
Frontend tests should cover:
- Mail menu shows unread count without loading full inbox.
- Messages page fetches its own data.
- Reply pre-populates recipient context without email.
- Empty and error states do not produce JSON parse failures.
Open Questions
- Should users be able to send messages to themselves as private notes?
- Should profile pages expose a “Message” action only for users in the same host, or should some cross-host flows be allowed?
- Should email notification include the sender display label, or only say that a portal message was received?
- Should any maximum retention policy apply to undeleted private messages?
- Should administrators have a separate support/audit view, and under what permission?
Config Server
Default Config Properties
For each config class in light-4j modules, we use annotations to generate schemas for the config files with default values, comments and validation rules.
As one time step, we also generate events to input all the properties into the light-portal. These events will create a base-line of the config properties with default values. All events in this first time population doesn’t have a version.
For each version release, we will create and attach an event.json file with the change to the properties. Most likely, we will add some properties with default values for each release. All events in the is file will have a version associated. Once played on the portal, updates for the version will be populated.
On the portal ui, we load all properties and default values from database with a union of the base-line properties and all versions below and equal to the current version.
Instance Config Snapshot
Once a logical instance is created on the light-portal, we need to provide the product_version_id which will map to a specific product version. We also need to provide runtime configuration and deployment configuration for the instance to start the server and deploy it to a target environment. During the configuration updates, it might be a process of discovery and may take several revisit to complete. If a user makes a mistake, he/she might want to rollback the previous changes to a snapshot version to start it over again. During the deployment, we also need to save and tag the snapshot version so that we can rollback to the previous deployment configuration snapshot in case of deployment failure.
The above requirements force us to create a table that is record all the commit for the config updates at instance level. It is like a GitHub commit to group several updates together. The user needs to explicitly click the commit button on the UI to allow the server to run the query to populate the snapshot table to create a new snapshot id.
Durng the deployment, the deployment serivce will invoke the config server to force a commit and also link that commit to a deployment id just like a tag in GitHub.
To meet the requirement above, we need to design tables to store immutable snapshots associated with a commitId/snapshotId to proivde reliable rollback points.
Snapshot tables
CREATE TABLE config_snapshot_t (
snapshot_id UUID NOT NULL, -- Primary Key, maybe UUIDv7 for time ordering
snapshot_ts TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT CURRENT_TIMESTAMP,
snapshot_type VARCHAR(32) NOT NULL, -- e.g., 'DEPLOYMENT', 'USER_SAVE', 'SCHEDULED_BACKUP'
description TEXT, -- User-provided description or system-generated info
user_id UUID, -- User who triggered it (if applicable)
deployment_id UUID, -- FK to deployment_t if snapshot_type is 'DEPLOYMENT'
-- Scope columns define WHAT this snapshot represents:
scope_host_id UUID NOT NULL, -- Host context (always needed)
scope_config_phase CHAR(1) NOT NULL, -- config phase context(required)
scope_environment VARCHAR(16), -- Environment context (if snapshot is env-specific)
scope_product_id VARCHAR(8) -- Product id context
scope_product_version VARCHAR(12) -- Product version context
scope_service_id VARCHAR(512) -- Service id context
scope_api_id VARCHAR(16) -- Api id context
scope_api_version VARCHAR(16) -- Api version context
PRIMARY KEY(snapshot_id),
FOREIGN KEY(deployment_id) REFERENCES deployment_t(deployment_id) ON DELETE SET NULL,
FOREIGN KEY(user_id) REFERENCES user_t(user_id) ON DELETE SET NULL,
FOREIGN KEY(scope_host_id) REFERENCES host_t(host_id) ON DELETE CASCADE
);
-- Index for finding snapshots by type or scope
CREATE INDEX idx_config_snapshot_scope ON config_snapshot_t (scope_host_id, scope_config_phase, scope_environment,
scope_product_id, scope_product_version, scope_service_id, scope_api_id, scope_api_version, snapshot_type, snapshot_ts);
CREATE INDEX idx_config_snapshot_deployment ON config_snapshot_t (deployment_id);
CREATE TABLE config_snapshot_property_t (
snapshot_property_id UUID NOT NULL, -- Surrogate primary key for easier referencing/updates if needed
snapshot_id UUID NOT NULL, -- FK to config_snapshot_t
config_id UUID NOT NULL, -- The config id
property_id UUID NOT NULL, -- The final property id
property_name VARCHAR(64) NOT NULL, -- The final property name
property_type VARCHAR(32) NOT NULL, -- The property type
property_value TEXT, -- The effective property value at snapshot time
value_type VARCHAR(32), -- Optional: Store the type (string, int, bool...) for easier parsing later
source_level VARCHAR(32), -- e.g., 'instance', 'product_version', 'environment', 'default'
PRIMARY KEY(snapshot_property_id),
FOREIGN KEY(snapshot_id) REFERENCES config_snapshot_t(snapshot_id) ON DELETE CASCADE
);
-- Unique constraint to ensure one value per key within a snapshot
ALTER TABLE config_snapshot_property_t
ADD CONSTRAINT config_snapshot_property_uk UNIQUE (snapshot_id, config_id, property_id);
-- Index for quickly retrieving all properties for a snapshot
CREATE INDEX idx_config_snapshot_property_snapid ON config_snapshot_property_t (snapshot_id);
-- Snapshot of Instance API Overrides
CREATE TABLE snapshot_instance_api_property_t (
snapshot_id UUID NOT NULL,
host_id UUID NOT NULL,
instance_api_id UUID NOT NULL,
property_id UUID NOT NULL,
property_value TEXT,
update_user VARCHAR (255) NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE NOT NULL,
PRIMARY KEY(snapshot_id, host_id, instance_api_id, property_id), -- Composite PK matches original structure + snapshot_id
FOREIGN KEY(snapshot_id) REFERENCES config_snapshot_t(snapshot_id) ON DELETE CASCADE
);
CREATE INDEX idx_snap_iapi_prop ON snapshot_instance_api_property_t (snapshot_id);
-- Snapshot of Instance App Overrides
CREATE TABLE snapshot_instance_app_property_t (
snapshot_id UUID NOT NULL,
host_id UUID NOT NULL,
instance_app_id UUID NOT NULL,
property_id UUID NOT NULL,
property_value TEXT,
update_user VARCHAR (255) NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE NOT NULL,
PRIMARY KEY(snapshot_id, host_id, instance_app_id, property_id),
FOREIGN KEY(snapshot_id) REFERENCES config_snapshot_t(snapshot_id) ON DELETE CASCADE
);
CREATE INDEX idx_snap_iapp_prop ON snapshot_instance_app_property_t (snapshot_id);
-- Snapshot of Instance App API Overrides
CREATE TABLE snapshot_instance_app_api_property_t (
snapshot_id UUID NOT NULL,
host_id UUID NOT NULL,
instance_app_id UUID NOT NULL,
instance_api_id UUID NOT NULL,
property_id UUID NOT NULL,
property_value TEXT,
update_user VARCHAR (255) NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE NOT NULL,
PRIMARY KEY(snapshot_id, host_id, instance_app_id, instance_api_id, property_id),
FOREIGN KEY(snapshot_id) REFERENCES config_snapshot_t(snapshot_id) ON DELETE CASCADE
);
CREATE INDEX idx_snap_iaappi_prop ON snapshot_instance_app_api_property_t (snapshot_id);
-- Snapshot of Instance Overrides
CREATE TABLE snapshot_instance_property_t (
snapshot_id UUID NOT NULL,
host_id UUID NOT NULL,
instance_id UUID NOT NULL,
property_id UUID NOT NULL,
property_value TEXT,
update_user VARCHAR (255) NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE NOT NULL,
PRIMARY KEY(snapshot_id, host_id, instance_id, property_id),
FOREIGN KEY(snapshot_id) REFERENCES config_snapshot_t(snapshot_id) ON DELETE CASCADE
);
CREATE INDEX idx_snap_inst_prop ON snapshot_instance_property_t (snapshot_id);
-- Snapshot of Environment Overrides (If needed for rollback)
CREATE TABLE snapshot_environment_property_t (
snapshot_id UUID NOT NULL,
host_id UUID NOT NULL,
environment VARCHAR(16) NOT NULL,
property_id UUID NOT NULL,
property_value TEXT,
update_user VARCHAR (255) NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE NOT NULL,
PRIMARY KEY(snapshot_id, host_id, environment, property_id),
FOREIGN KEY(snapshot_id) REFERENCES config_snapshot_t(snapshot_id) ON DELETE CASCADE
);
CREATE INDEX idx_snap_env_prop ON snapshot_environment_property_t (snapshot_id);
CREATE TABLE snapshot_product_property_t (
snapshot_id UUID NOT NULL,
product_id VARCHAR(8) NOT NULL,
property_id UUID NOT NULL,
property_value TEXT,
update_user VARCHAR (255) NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE NOT NULL,
PRIMARY KEY(snapshot_id, product_id, property_id),
FOREIGN KEY(snapshot_id) REFERENCES config_snapshot_t(snapshot_id) ON DELETE CASCADE
);
CREATE INDEX idx_snap_prd_prop ON snapshot_product_property_t (snapshot_id);
CREATE TABLE snapshot_product_version_property_t (
snapshot_id UUID NOT NULL,
host_id UUID NOT NULL,
product_version_id UUID NOT NULL,
property_id UUID NOT NULL,
property_value TEXT,
update_user VARCHAR (255) NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE NOT NULL,
PRIMARY KEY(snapshot_id, host_id, product_version_id, property_id),
FOREIGN KEY(snapshot_id) REFERENCES config_snapshot_t(snapshot_id) ON DELETE CASCADE
);
CREATE INDEX idx_snap_pv_prop ON snapshot_product_version_property_t (snapshot_id);
How to generate rollback events
There are two options to generate rollback events or compensate events.
Option 1. With historical events.
- Identify Target State: You have a
snapshot_idrepresenting the desired historical state. - Find Snapshot Timestamp: Get the
snapshot_tsfromconfig_snapshot_tfor the targetsnapshot_id. - Query Events: Find all configuration events in your event store that:
- Occurred after the
snapshot_ts. - Relate to the specific scope (host, instance, environment, etc.) being rolled back.
- Occurred after the
- Generate Compensating Events: For each event found in step 3, create its logical inverse (a “compensating event”). For example:
InstancePropertyUpdated { propertyId: X, newValue: B, oldValue: A }->InstancePropertyUpdated { propertyId: X, newValue: A, oldValue: B }(Requires storingoldValuein the original event).InstancePropertyCreated { propertyId: X, value: A }->InstancePropertyDeleted { propertyId: X, value: A }(Requires storing the value in the delete event for potential future rollback).InstancePropertyDeleted { propertyId: X, value: A }->InstancePropertyCreated { propertyId: X, value: A }(Requires storing the value in the delete event).
- Order Compensating Events: Sort the generated compensating events in the reverse chronological order of the original events they are compensating for.
- Replay Compensating Events: Apply these ordered compensating events through your event handling system.
Conceptually, this is a valid approach often used in event sourcing patterns (related to compensating transactions). However, it comes with significant challenges and complexities:
Challenges & Considerations:
- Generating Perfect Inverse Events: This is the hardest part.
- Requires Rich Events: Your original events must contain enough information to construct their inverse. For updates, you need the
oldValue. For creations, the delete needs the key. For deletions, the create needs the deleted value. If your current events don’t store this, you cannot reliably generate compensating events this way. - Complexity: For multi-step or complex operations, determining the exact inverse sequence can be non-trivial.
- Requires Rich Events: Your original events must contain enough information to construct their inverse. For updates, you need the
- Order of Operations: Compensating events MUST be applied in strict reverse order. Getting this wrong can lead to incorrect states.
- State Dependencies: Event handlers sometimes make assumptions about the state before the event is applied. Replaying compensating events might encounter unexpected states if other unrelated changes have occurred or if the reverse logic isn’t perfect, potentially causing handler errors.
- Performance: Querying potentially thousands of events, generating inverses, and replaying them might be slow, especially if the time gap between the snapshot and the present is large.
- Snapshot Data Not Used: This approach doesn’t directly leverage the known good state stored in
config_snapshot_property_t. It relies solely on the ability to perfectly reverse subsequent events. - Idempotency: Compensating event handlers should ideally be idempotent (applying them multiple times has the same effect as applying them once), although this is hard to guarantee for inverse operations.
Option 2: Diff-based event generation.
- Get Target State: Fetch key-values from
config_snapshot_property_tforsnapshot_id. (TargetState) - Get Current State: Run aggregation query for the current configuration. (
CurrentState) - Calculate Diff: Find differences between
TargetStateandCurrentState. - Generate Corrective Events: Create events to transform
CurrentStateintoTargetState.- If
keyis inTargetStatebut different/missing inCurrentState-> GenerateUpsert[Level]Propertyevent with the value fromTargetState(applied at the highest relevant override level for the scope). - If
keyis inCurrentStatebut missing inTargetState-> GenerateDelete[Level]Propertyevent for the override that’s currently providing the value (likely the highest relevant override level).
- If
- Apply Events: Apply these corrective events.
Why the Diff-Based Approach is Often Preferred for Snapshot Rollback:
- Uses Known Good State: It directly uses the guaranteed state from the snapshot table.
- Less Reliant on Event Reversibility: It doesn’t matter if the original events are perfectly reversible or store old values. It focuses on achieving the target state from the current state.
- Potentially Fewer Events: Might generate fewer events than reversing a long history, focusing only on the net changes needed.
- More Direct: The generated events directly aim to establish the target state, which can feel less fragile than relying on reversing history.
Conclusion:
While method of reversing events since the snapshot is a recognized event sourcing pattern, it’s often more complex and potentially fragile for the specific task of rolling back to a known snapshot state compared to the diff-based corrective event generation method.
The diff-based method leverages the snapshot data directly and focuses on achieving the target state, making it generally more robust and often easier to implement correctly, as it doesn’t require perfectly reversible events.
How to create the snapshot
Let’s clarify how the scope_* columns in config_snapshot_t relate to the query that generates the snapshot and the override tables (*_property_t).
The Purpose of scope_* Columns:
The scope_* columns in config_snapshot_t serve one primary purpose: To record the specific context for which the snapshot was generated. They define what set of effective configuration values are stored in the associated config_snapshot_property_t rows.
Think of them as the input parameters that were used to run the aggregation query when the snapshot was created.
How They Are Used in the Snapshot Generation Query:
You do not need one scope_* column for every *_property_t table. Instead, the values you store in the scope_* columns are the parameters you pass into your aggregation query’s WHERE clauses to filter the rows from the relevant override tables according to the desired context.
Let’s refine the query strategy using the scope_* concept and aim for a more efficient query than repeated NOT EXISTS clauses (using ROW_NUMBER() or DISTINCT ON).
Example Scenario: Snapshotting for a specific Instance
Let’s say you want to create a snapshot for a specific instance_id on a specific host_id.
-
Input Parameters:
p_host_id(UUID)p_instance_id(UUID)
-
Derive Related IDs (Inside your snapshot creation logic/service):
- You’ll need to query
instance_tto get the associatedproduct_version_id,environment, etc., for this instance. - Query
product_version_tto getproduct_id. - Let’s call these derived values
v_product_version_id,v_environment,v_product_id.
- You’ll need to query
-
config_snapshot_tRecord:- Generate a
snapshot_id(e.g., UUIDv7). snapshot_ts:CURRENT_TIMESTAMPsnapshot_type: e.g., ‘DEPLOYMENT’scope_host_id:p_host_idscope_instance_id:p_instance_idscope_environment:v_environment(Store the derived environment for clarity, even though it came from the instance)scope_product_version_id:v_product_version_id(Store for clarity)scope_product_id:v_product_id(Store for clarity)- (Other
scope_*columns likescope_instance_api_idwould be NULL for this instance-level snapshot)
- Generate a
-
Aggregation Query (Using
ROW_NUMBER()): This query uses the input parameters (p_host_id,p_instance_id) and the derived values (v_product_version_id,v_environment,v_product_id) to find the highest priority value for eachproperty_id.
WITH – Parameters derived before running this query: – p_host_id UUID – p_instance_id UUID – v_product_version_id UUID (derived from p_instance_id) – v_environment VARCHAR(16) (derived from p_instance_id) – v_product_id VARCHAR(8) (derived from v_product_version_id)
– Find relevant instance_api_ids and instance_app_ids for the target instance RelevantInstanceApis AS ( SELECT instance_api_id FROM instance_api_t WHERE host_id = ? – p_host_id AND instance_id = ? – p_instance_id ), RelevantInstanceApps AS ( SELECT instance_app_id FROM instance_app_t WHERE host_id = ? – p_host_id AND instance_id = ? – p_instance_id ),
– Pre-process Instance App API properties with merging logic Merged_Instance_App_Api_Properties AS ( SELECT iaap.property_id, CASE cp.value_type WHEN ‘map’ THEN COALESCE(jsonb_merge_agg(iaap.property_value::jsonb), ‘{}’::jsonb)::text WHEN ‘list’ THEN COALESCE((SELECT jsonb_agg(elem ORDER BY iaa.update_ts) – Order elements based on when they were added via the link table? Or property update_ts? Assuming property update_ts. Check data model if linking time matters more. FROM jsonb_array_elements(sub.property_value::jsonb) elem WHERE jsonb_typeof(sub.property_value::jsonb) = ‘array’ ), ‘[]’::jsonb)::text – Requires subquery if ordering elements – Subquery approach for ordering list elements by property timestamp: /* COALESCE( (SELECT jsonb_agg(elem ORDER BY prop.update_ts) FROM instance_app_api_property_t prop, jsonb_array_elements(prop.property_value::jsonb) elem WHERE prop.host_id = iaap.host_id AND prop.instance_app_id = iaap.instance_app_id AND prop.instance_api_id = iaap.instance_api_id AND prop.property_id = iaap.property_id AND jsonb_typeof(prop.property_value::jsonb) = ‘array’ ), ‘[]’::jsonb )::text / ELSE MAX(iaap.property_value) – For simple types, MAX can work if only one entry expected, otherwise need timestamp logic – More robust for simple types: Pick latest based on timestamp / (SELECT property_value FROM instance_app_api_property_t latest WHERE latest.host_id = iaap.host_id AND latest.instance_app_id = iaap.instance_app_id AND latest.instance_api_id = iaap.instance_api_id AND latest.property_id = iaap.property_id ORDER BY latest.update_ts DESC LIMIT 1) */ END AS effective_value FROM instance_app_api_property_t iaap JOIN config_property_t cp ON iaap.property_id = cp.property_id JOIN instance_app_api_t iaa ON iaa.host_id = iaap.host_id AND iaa.instance_app_id = iaap.instance_app_id AND iaa.instance_api_id = iaap.instance_api_id – Join to potentially use its timestamp for ordering lists WHERE iaap.host_id = ? – p_host_id AND iaap.instance_app_id IN (SELECT instance_app_id FROM RelevantInstanceApps) AND iaap.instance_api_id IN (SELECT instance_api_id FROM RelevantInstanceApis) GROUP BY iaap.host_id, iaap.instance_app_id, iaap.instance_api_id, iaap.property_id, cp.value_type – Group to aggregate/merge ),
– Pre-process Instance API properties Merged_Instance_Api_Properties AS ( SELECT iap.property_id, CASE cp.value_type WHEN ‘map’ THEN COALESCE(jsonb_merge_agg(iap.property_value::jsonb), ‘{}’::jsonb)::text WHEN ‘list’ THEN COALESCE((SELECT jsonb_agg(elem ORDER BY prop.update_ts) FROM instance_api_property_t prop, jsonb_array_elements(prop.property_value::jsonb) elem WHERE prop.host_id = iap.host_id AND prop.instance_api_id = iap.instance_api_id AND prop.property_id = iap.property_id AND jsonb_typeof(prop.property_value::jsonb) = ‘array’), ‘[]’::jsonb)::text ELSE (SELECT property_value FROM instance_api_property_t latest WHERE latest.host_id = iap.host_id AND latest.instance_api_id = iap.instance_api_id AND latest.property_id = iap.property_id ORDER BY latest.update_ts DESC LIMIT 1) END AS effective_value FROM instance_api_property_t iap JOIN config_property_t cp ON iap.property_id = cp.property_id WHERE iap.host_id = ? – p_host_id AND iap.instance_api_id IN (SELECT instance_api_id FROM RelevantInstanceApis) GROUP BY iap.host_id, iap.instance_api_id, iap.property_id, cp.value_type ),
– Pre-process Instance App properties Merged_Instance_App_Properties AS ( SELECT iapp.property_id, CASE cp.value_type WHEN ‘map’ THEN COALESCE(jsonb_merge_agg(iapp.property_value::jsonb), ‘{}’::jsonb)::text WHEN ‘list’ THEN COALESCE((SELECT jsonb_agg(elem ORDER BY prop.update_ts) FROM instance_app_property_t prop, jsonb_array_elements(prop.property_value::jsonb) elem WHERE prop.host_id = iapp.host_id AND prop.instance_app_id = iapp.instance_app_id AND prop.property_id = iapp.property_id AND jsonb_typeof(prop.property_value::jsonb) = ‘array’), ‘[]’::jsonb)::text ELSE (SELECT property_value FROM instance_app_property_t latest WHERE latest.host_id = iapp.host_id AND latest.instance_app_id = iapp.instance_app_id AND latest.property_id = iapp.property_id ORDER BY latest.update_ts DESC LIMIT 1) END AS effective_value FROM instance_app_property_t iapp JOIN config_property_t cp ON iapp.property_id = cp.property_id WHERE iapp.host_id = ? – p_host_id AND iapp.instance_app_id IN (SELECT instance_app_id FROM RelevantInstanceApps) GROUP BY iapp.host_id, iapp.instance_app_id, iapp.property_id, cp.value_type ),
– Combine all levels with priority AllOverrides AS ( – Priority 10: Instance App API (highest) - Requires aggregating the merged results if multiple app/api combos apply to the instance SELECT m_iaap.property_id, – Need final merge/latest logic here if multiple app/api combos apply to the SAME instance_id and define the SAME property_id – Assuming for now we take the first one found or need more complex logic if merge is needed again at this stage – For simplicity, let’s assume we just take MAX effective value if multiple rows exist per property_id for the instance MAX(m_iaap.effective_value) as property_value, – This MAX might not be right for JSON, need specific logic if merging across app/api combos is needed here 10 AS priority_level FROM Merged_Instance_App_Api_Properties m_iaap – No additional instance filter needed if CTEs were already filtered by RelevantInstanceApps/Apis linked to p_instance_id GROUP BY m_iaap.property_id – Group to handle multiple app/api links potentially setting the same property for the instance
UNION ALL
-- Priority 20: Instance API
SELECT
m_iap.property_id,
MAX(m_iap.effective_value) as property_value, -- Similar merge concern as above
20 AS priority_level
FROM Merged_Instance_Api_Properties m_iap
GROUP BY m_iap.property_id
UNION ALL
-- Priority 30: Instance App
SELECT
m_iapp.property_id,
MAX(m_iapp.effective_value) as property_value, -- Similar merge concern
30 AS priority_level
FROM Merged_Instance_App_Properties m_iapp
GROUP BY m_iapp.property_id
UNION ALL
-- Priority 40: Instance
SELECT
ip.property_id,
ip.property_value,
40 AS priority_level
FROM instance_property_t ip
WHERE ip.host_id = ? -- p_host_id
AND ip.instance_id = ? -- p_instance_id
UNION ALL
-- Priority 50: Product Version
SELECT
pvp.property_id,
pvp.property_value,
50 AS priority_level
FROM product_version_property_t pvp
WHERE pvp.host_id = ? -- p_host_id
AND pvp.product_version_id = ? -- v_product_version_id
UNION ALL
-- Priority 60: Environment
SELECT
ep.property_id,
ep.property_value,
60 AS priority_level
FROM environment_property_t ep
WHERE ep.host_id = ? -- p_host_id
AND ep.environment = ? -- v_environment
UNION ALL
-- Priority 70: Product (Host independent)
SELECT
pp.property_id,
pp.property_value,
70 AS priority_level
FROM product_property_t pp
WHERE pp.product_id = ? -- v_product_id
UNION ALL
-- Priority 100: Default values
SELECT
cp.property_id,
cp.property_value, -- Default value
100 AS priority_level
FROM config_property_t cp
-- Optimization: Filter defaults to only those applicable to the product version?
-- JOIN product_version_config_property_t pvcp ON cp.property_id = pvcp.property_id
-- WHERE pvcp.host_id = ? AND pvcp.product_version_id = ?
), RankedOverrides AS ( SELECT ao.property_id, ao.property_value, ao.priority_level, ROW_NUMBER() OVER (PARTITION BY ao.property_id ORDER BY ao.priority_level ASC) as rn FROM AllOverrides ao WHERE ao.property_value IS NOT NULL – Exclude levels where the value was NULL (unless NULL is a valid override) ) – Final Selection for Snapshot Table SELECT – snapshot_id needs to be added here or during INSERT cfg.config_name || ‘.’ || cp.property_name AS property_key, ro.property_value, cp.property_type, cp.value_type – Include ro.priority_level AS source_priority if storing provenance FROM RankedOverrides ro JOIN config_property_t cp ON ro.property_id = cp.property_id JOIN config_t cfg ON cp.config_id = cfg.config_id WHERE ro.rn = 1;
5. **Populate `config_snapshot_property_t`:** Insert the results of this query into `config_snapshot_property_t`, using the `snapshot_id` generated in step 3.
**Key Takeaways:**
* The `scope_*` columns define the *context* of the snapshot.
* The values for these `scope_*` columns are used as *parameters* within the `WHERE` clauses of the aggregation query that *generates* the snapshot data.
* You don't need a `scope_*` column per override table. You need columns representing the different *dimensions* or *levels* by which you might want to define a snapshot's context (host, instance, environment, product version, etc.).
* The aggregation query uses these parameters to filter the relevant rows from each override table and then determines the highest priority value using `UNION ALL` and a ranking mechanism (`ROW_NUMBER()` or `DISTINCT ON`).
This approach keeps the `config_snapshot_t` table focused on metadata and context, while the query handles the complex logic of applying that context to the various override tables to produce the effective configuration for `config_snapshot_property_t`.
### Config Phase
In the config_t table, there is a config_phase column to separate different stages of api/app life cycles. For example, config for codegen, config for runtime, config for deployment.
Given your two main use cases:
1. **Service Startup:** Needs the *runtime* (`'R'`) configuration.
2. **Deployment Rollback:** Needs to potentially restore the state required for *deployment* (`'D'`) and the resulting *runtime* (`'R'`) configuration from that point in time. (Generator `'G'` configs are usually less relevant for deployment/runtime rollbacks).
Here are the options and the recommended approach:
**Option 1: Phase-Specific Snapshots (Separate Records)**
* **How:** Add `scope_config_phase CHAR(1)` to `config_snapshot_t`.
* **Snapshot Creation:** When a snapshot event occurs (e.g., pre-deployment):
* Generate a `snapshot_id_D` (e.g., using UUIDv7).
* Run the aggregation query with `config_phase = 'D'`.
* Store results in `config_snapshot_property_t` linked to `snapshot_id_D`.
* Create metadata in `config_snapshot_t` for `snapshot_id_D` with `scope_config_phase = 'D'`.
* Generate *another* `snapshot_id_R`.
* Run the aggregation query with `config_phase = 'R'`.
* Store results in `config_snapshot_property_t` linked to `snapshot_id_R`.
* Create metadata in `config_snapshot_t` for `snapshot_id_R` with `scope_config_phase = 'R'`.
* You'd need a way to link `snapshot_id_D` and `snapshot_id_R` to the same logical event (e.g., same `related_deployment_id`).
* **Pros:** Very explicit separation. Querying for a specific phase's snapshot is straightforward.
* **Cons:** Requires multiple runs of the aggregation query. Doubles the metadata rows in `config_snapshot_t`. Complicates linking phases related to the same event. Less efficient.
**Option 2: Single Snapshot, Phase Included in Properties (Recommended)**
* **How:** Do **not** add `scope_config_phase` to `config_snapshot_t`. Instead, add `config_phase CHAR(1)` to `config_snapshot_property_t`.
* **Snapshot Creation:**
* Generate a single `snapshot_id`.
* Create one metadata row in `config_snapshot_t` representing the overall scope and time (without phase).
* **Modify the Aggregation Query:**
* **Remove** the `WHERE c.config_phase = ?` filter entirely.
* **SELECT** the `c.config_phase` value in the final `SELECT` statement.
* Run this modified query *once*. It will calculate the effective properties across *all* phases applicable to the scope.
* Store the results in `config_snapshot_property_t`, populating the new `config_phase` column for each property based on the phase of the `config_t` record from which it originated.
* **`config_snapshot_property_t` Structure:**
```sql
CREATE TABLE config_snapshot_property_t (
-- ... other columns ...
config_phase CHAR(1) NOT NULL, -- Phase this property belongs to
property_key TEXT NOT NULL,
property_value TEXT,
property_type VARCHAR(32),
value_type VARCHAR(32),
-- ...
PRIMARY KEY(snapshot_property_id), -- Or PK(snapshot_id, config_phase, property_key)? Needs thought.
FOREIGN KEY(snapshot_id) REFERENCES config_snapshot_t(snapshot_id) ON DELETE CASCADE
);
-- Ensure uniqueness within a snapshot for a given key *and phase*
ALTER TABLE config_snapshot_property_t
ADD CONSTRAINT config_snapshot_property_uk UNIQUE (snapshot_id, config_phase, property_key);
-- Index for lookup by snapshot and phase
CREATE INDEX idx_config_snapshot_property_snap_phase ON config_snapshot_property_t (snapshot_id, config_phase);
```
* **Pros:**### commitConfigInstance
Let's outline the structure of your `commitConfigInstance` service method and the necessary SQL INSERT statements using JDBC.
This involves several steps within a single database transaction:
1. **Generate Snapshot ID:** Create a new UUID for the snapshot.
2. **Derive Scope IDs:** Query live tables (`instance_t`, `product_version_t`, etc.) based on the input `hostId` and `instanceId` to get other relevant scope identifiers (`environment`, `productId`, `productVersionId`, `serviceId`, etc.).
3. **Insert Metadata:** Insert a record into `config_snapshot_t`.
4. **Aggregate Effective Config:** Run the complex aggregation query (using `ROW_NUMBER()` or similar) to get the final effective properties.
5. **Insert Effective Config:** Insert the results from step 4 into `config_snapshot_property_t`.
6. **Snapshot Override Tables:** For each relevant live override table (`instance_property_t`, `instance_api_property_t`, etc.), select its current state (filtered by scope) and insert it into the corresponding `snapshot_*_property_t` table.
7. **Commit/Rollback:** Commit the transaction if all steps succeed, otherwise roll back.
**Java Service Method Structure (Conceptual)**
```java
import com.github.f4b6a3.uuid.UuidCreator; // For UUIDv7 generation
import javax.sql.DataSource; // Assuming you have a DataSource injected
import java.sql.*;
import java.time.OffsetDateTime;
import java.util.*;
public class ConfigSnapshotService {
private final DataSource ds;
// Inject DataSource via constructor
// Pre-compile your complex aggregation query (modify based on previous examples)
private static final String AGGREGATE_EFFECTIVE_CONFIG_SQL = """
WITH AllOverrides AS (
-- Priority 10: Instance App API (merged) ...
-- Priority 20: Instance API (merged) ...
-- Priority 30: Instance App (merged) ...
-- Priority 40: Instance ...
-- Priority 50: Product Version ...
-- Priority 60: Environment ...
-- Priority 70: Product ...
-- Priority 100: Default ...
),
RankedOverrides AS (
SELECT ..., ROW_NUMBER() OVER (PARTITION BY ao.property_id ORDER BY ao.priority_level ASC) as rn
FROM AllOverrides ao WHERE ao.property_value IS NOT NULL
)
SELECT
c.config_phase, -- Phase from config_t
cfg.config_id, -- Added config_id
cp.property_id, -- Added property_id
cp.property_name, -- Added property_name
cp.property_type,
cp.value_type,
cfg.config_name || '.' || cp.property_name AS property_key, -- Keep for logging/debug? Not needed in snapshot table itself
ro.property_value,
ro.priority_level -- To determine source_level
FROM RankedOverrides ro
JOIN config_property_t cp ON ro.property_id = cp.property_id
JOIN config_t cfg ON cp.config_id = cfg.config_id
WHERE ro.rn = 1;
"""; // NOTE: Add parameters (?) for host_id, instance_id, derived IDs etc.
public Result<String> commitConfigInstance(Map<String, Object> event) {
// 1. Extract Input Parameters
UUID hostId = (UUID) event.get("hostId");
UUID instanceId = (UUID) event.get("instanceId");
String snapshotType = (String) event.getOrDefault("snapshotType", "USER_SAVE"); // Default type
String description = (String) event.get("description");
UUID userId = (UUID) event.get("userId"); // May be null
UUID deploymentId = (UUID) event.get("deploymentId"); // May be null
if (hostId == null || instanceId == null) {
return Failure.of(new Status(INVALID_PARAMETER, "hostId and instanceId are required."));
}
UUID snapshotId = UuidCreator.getTimeOrderedEpoch(); // Generate Snapshot ID (e.g., V7)
Connection connection = null;
try {
connection = ds.getConnection();
connection.setAutoCommit(false); // Start Transaction
// 2. Derive Scope IDs
// Query instance_t and potentially product_version_t based on hostId, instanceId
DerivedScope scope = deriveScopeInfo(connection, hostId, instanceId);
if (scope == null) {
connection.rollback(); // Rollback if instance not found
return Failure.of(new Status(OBJECT_NOT_FOUND, "Instance not found for hostId/instanceId."));
}
// 3. Insert Snapshot Metadata
insertSnapshotMetadata(connection, snapshotId, snapshotType, description, userId, deploymentId, hostId, scope);
// 4 & 5. Aggregate and Insert Effective Config
insertEffectiveConfigSnapshot(connection, snapshotId, hostId, instanceId, scope);
// 6. Snapshot Individual Override Tables
// Use INSERT ... SELECT ... for efficiency
snapshotInstanceProperties(connection, snapshotId, hostId, instanceId);
snapshotInstanceApiProperties(connection, snapshotId, hostId, instanceId);
snapshotInstanceAppProperties(connection, snapshotId, hostId, instanceId);
snapshotInstanceAppApiProperties(connection, snapshotId, hostId, instanceId); // Requires finding relevant App/API IDs first
snapshotEnvironmentProperties(connection, snapshotId, hostId, scope.environment());
snapshotProductVersionProperties(connection, snapshotId, hostId, scope.productVersionId());
snapshotProductProperties(connection, snapshotId, scope.productId());
// Add others as needed
// 7. Commit Transaction
connection.commit();
logger.info("Successfully created config snapshot: {}", snapshotId);
return Success.of(snapshotId.toString());
} catch (SQLException e) {
logger.error("SQLException during snapshot creation for instance {}: {}", instanceId, e.getMessage(), e);
if (connection != null) {
try {
connection.rollback();
} catch (SQLException ex) {
logger.error("Error rolling back transaction:", ex);
}
}
return Failure.of(new Status(SQL_EXCEPTION, "Database error during snapshot creation."));
} catch (Exception e) { // Catch other potential errors (e.g., during scope derivation)
logger.error("Exception during snapshot creation for instance {}: {}", instanceId, e.getMessage(), e);
if (connection != null) {
try { connection.rollback(); } catch (SQLException ex) { logger.error("Error rolling back transaction:", ex); }
}
return Failure.of(new Status(GENERIC_EXCEPTION, "Unexpected error during snapshot creation."));
} finally {
if (connection != null) {
try {
connection.setAutoCommit(true); // Restore default behavior
connection.close();
} catch (SQLException e) {
logger.error("Error closing connection:", e);
}
}
}
}
// --- Helper Methods ---
// Placeholder for derived scope data structure
private record DerivedScope(String environment, String productId, String productVersion, UUID productVersionId, String serviceId /*, add API details if needed */) {}
private DerivedScope deriveScopeInfo(Connection conn, UUID hostId, UUID instanceId) throws SQLException {
// Query instance_t LEFT JOIN product_version_t ... WHERE i.host_id = ? AND i.instance_id = ?
// Extract environment, service_id from instance_t
// Extract product_id, product_version from product_version_t (via product_version_id in instance_t)
// Return new DerivedScope(...) or null if not found
String sql = """
SELECT i.environment, i.service_id, pv.product_id, pv.product_version, i.product_version_id
FROM instance_t i
LEFT JOIN product_version_t pv ON i.host_id = pv.host_id AND i.product_version_id = pv.product_version_id
WHERE i.host_id = ? AND i.instance_id = ?
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, hostId);
ps.setObject(2, instanceId);
try (ResultSet rs = ps.executeQuery()) {
if (rs.next()) {
return new DerivedScope(
rs.getString("environment"),
rs.getString("product_id"),
rs.getString("product_version"),
rs.getObject("product_version_id", UUID.class),
rs.getString("service_id")
);
} else {
return null; // Instance not found
}
}
}
}
private void insertSnapshotMetadata(Connection conn, UUID snapshotId, String snapshotType, String description,
UUID userId, UUID deploymentId, UUID hostId, DerivedScope scope) throws SQLException {
String sql = """
INSERT INTO config_snapshot_t
(snapshot_id, snapshot_ts, snapshot_type, description, user_id, deployment_id,
scope_host_id, scope_environment, scope_product_id, scope_product_version_id, -- Changed col name
scope_service_id /*, scope_api_id, scope_api_version - Add if applicable */)
VALUES (?, CURRENT_TIMESTAMP, ?, ?, ?, ?, ?, ?, ?, ?, ? /*, ?, ? */)
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setString(2, snapshotType);
ps.setString(3, description);
ps.setObject(4, userId); // setObject handles null correctly
ps.setObject(5, deploymentId); // setObject handles null correctly
ps.setObject(6, hostId);
ps.setString(7, scope.environment());
ps.setString(8, scope.productId());
ps.setObject(9, scope.productVersionId()); // Store the ID
ps.setString(10, scope.serviceId());
// Set API scope if needed ps.setObject(11, ...); ps.setString(12, ...);
ps.executeUpdate();
}
}
private void insertEffectiveConfigSnapshot(Connection conn, UUID snapshotId, UUID hostId, UUID instanceId, DerivedScope scope) throws SQLException {
String insertSql = """
INSERT INTO config_snapshot_property_t
(snapshot_property_id, snapshot_id, config_phase, config_id, property_id, property_name,
property_type, property_value, value_type, source_level)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""";
// Prepare the aggregation query
try (PreparedStatement selectStmt = conn.prepareStatement(AGGREGATE_EFFECTIVE_CONFIG_SQL);
PreparedStatement insertStmt = conn.prepareStatement(insertSql)) {
// Set ALL parameters for the AGGREGATE_EFFECTIVE_CONFIG_SQL query
int paramIndex = 1;
// Example: set parameters based on how AGGREGATE_EFFECTIVE_CONFIG_SQL is structured
// selectStmt.setObject(paramIndex++, hostId);
// selectStmt.setObject(paramIndex++, instanceId);
// ... set derived scope IDs (productVersionId, environment, productId) ...
// ... set parameters for all UNION branches and potential subqueries ...
try (ResultSet rs = selectStmt.executeQuery()) {
int batchCount = 0;
while (rs.next()) {
insertStmt.setObject(1, UuidCreator.getTimeOrderedEpoch()); // snapshot_property_id
insertStmt.setObject(2, snapshotId);
insertStmt.setString(3, rs.getString("config_phase"));
insertStmt.setObject(4, rs.getObject("config_id", UUID.class));
insertStmt.setObject(5, rs.getObject("property_id", UUID.class));
insertStmt.setString(6, rs.getString("property_name"));
insertStmt.setString(7, rs.getString("property_type"));
insertStmt.setString(8, rs.getString("property_value"));
insertStmt.setString(9, rs.getString("value_type"));
insertStmt.setString(10, mapPriorityToSourceLevel(rs.getInt("priority_level"))); // Map numeric priority back to level name
insertStmt.addBatch();
batchCount++;
if (batchCount % 100 == 0) { // Execute batch periodically
insertStmt.executeBatch();
}
}
if (batchCount % 100 != 0) { // Execute remaining batch
insertStmt.executeBatch();
}
}
}
}
// Helper to map priority back to source level name
private String mapPriorityToSourceLevel(int priority) {
return switch (priority) {
case 10 -> "instance_app_api"; // Adjust priorities as used in your query
case 20 -> "instance_api";
case 30 -> "instance_app";
case 40 -> "instance";
case 50 -> "product_version";
case 60 -> "environment";
case 70 -> "product";
case 100 -> "default";
default -> "unknown";
};
}
// --- Methods for Snapshotting Individual Override Tables ---
private void snapshotInstanceProperties(Connection conn, UUID snapshotId, UUID hostId, UUID instanceId) throws SQLException {
String sql = """
INSERT INTO snapshot_instance_property_t
(snapshot_id, host_id, instance_id, property_id, property_value, update_user, update_ts)
SELECT ?, host_id, instance_id, property_id, property_value, update_user, update_ts
FROM instance_property_t
WHERE host_id = ? AND instance_id = ?
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
ps.setObject(3, instanceId);
ps.executeUpdate();
}
}
private void snapshotInstanceApiProperties(Connection conn, UUID snapshotId, UUID hostId, UUID instanceId) throws SQLException {
// Find relevant instance_api_ids first
List<UUID> apiIds = findRelevantInstanceApiIds(conn, hostId, instanceId);
if (apiIds.isEmpty()) return; // No API overrides for this instance
String sql = """
INSERT INTO snapshot_instance_api_property_t
(snapshot_id, host_id, instance_api_id, property_id, property_value, update_user, update_ts)
SELECT ?, host_id, instance_api_id, property_id, property_value, update_user, update_ts
FROM instance_api_property_t
WHERE host_id = ? AND instance_api_id = ANY(?) -- Use ANY with array for multiple IDs
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
// Create a SQL Array from the List of UUIDs
Array sqlArray = conn.createArrayOf("UUID", apiIds.toArray());
ps.setArray(3, sqlArray);
ps.executeUpdate();
sqlArray.free(); // Release array resources
}
}
// Similar methods for snapshotInstanceAppProperties, snapshotInstanceAppApiProperties...
// These will need helper methods like findRelevantInstanceApiIds/findRelevantInstanceAppIds
private void snapshotEnvironmentProperties(Connection conn, UUID snapshotId, UUID hostId, String environment) throws SQLException {
if (environment == null || environment.isEmpty()) return; // No environment scope
String sql = """
INSERT INTO snapshot_environment_property_t
(snapshot_id, host_id, environment, property_id, property_value, update_user, update_ts)
SELECT ?, host_id, environment, property_id, property_value, update_user, update_ts
FROM environment_property_t
WHERE host_id = ? AND environment = ?
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
ps.setString(3, environment);
ps.executeUpdate();
}
}
private void snapshotProductVersionProperties(Connection conn, UUID snapshotId, UUID hostId, UUID productVersionId) throws SQLException {
if (productVersionId == null) return;
String sql = """
INSERT INTO snapshot_product_version_property_t
(snapshot_id, host_id, product_version_id, property_id, property_value, update_user, update_ts)
SELECT ?, host_id, product_version_id, property_id, property_value, update_user, update_ts
FROM product_version_property_t
WHERE host_id = ? AND product_version_id = ?
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
ps.setObject(3, productVersionId);
ps.executeUpdate();
}
}
private void snapshotProductProperties(Connection conn, UUID snapshotId, String productId) throws SQLException {
if (productId == null || productId.isEmpty()) return;
String sql = """
INSERT INTO snapshot_product_property_t
(snapshot_id, product_id, property_id, property_value, update_user, update_ts)
SELECT ?, product_id, property_id, property_value, update_user, update_ts
FROM product_property_t
WHERE product_id = ?
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setString(2, productId);
ps.executeUpdate();
}
}
// --- Helper method to find associated instance_api_ids ---
private List<UUID> findRelevantInstanceApiIds(Connection conn, UUID hostId, UUID instanceId) throws SQLException {
List<UUID> ids = new ArrayList<>();
String sql = "SELECT instance_api_id FROM instance_api_t WHERE host_id = ? AND instance_id = ?";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, hostId);
ps.setObject(2, instanceId);
try (ResultSet rs = ps.executeQuery()) {
while(rs.next()) {
ids.add(rs.getObject("instance_api_id", UUID.class));
}
}
}
return ids;
}
// --- Add similar helper for findRelevantInstanceAppIds ---
// --- Add similar helper for findRelevantInstanceAppApiIds (if needed) ---
}
SQL INSERT Statements:
-
config_snapshot_t:INSERT INTO config_snapshot_t (snapshot_id, snapshot_ts, snapshot_type, description, user_id, deployment_id, scope_host_id, scope_environment, scope_product_id, scope_product_version_id, scope_service_id /*, ... other scope cols */) VALUES (?, CURRENT_TIMESTAMP, ?, ?, ?, ?, ?, ?, ?, ?, ? /*, ... */)(Parameters: snapshotId, snapshotType, description, userId, deploymentId, hostId, environment, productId, productVersionId, serviceId, …)
-
config_snapshot_property_t: (Executed in a loop/batch)INSERT INTO config_snapshot_property_t (snapshot_property_id, snapshot_id, config_phase, config_id, property_id, property_name, property_type, property_value, value_type, source_level) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)(Parameters: new UUID, snapshotId, phase, configId, propertyId, propName, propType, propValue, valType, sourceLevelString)
-
snapshot_instance_property_t:INSERT INTO snapshot_instance_property_t (snapshot_id, host_id, instance_id, property_id, property_value, update_user, update_ts) SELECT ?, host_id, instance_id, property_id, property_value, update_user, update_ts FROM instance_property_t WHERE host_id = ? AND instance_id = ?(Parameters: snapshotId, hostId, instanceId)
-
snapshot_instance_api_property_t:INSERT INTO snapshot_instance_api_property_t (snapshot_id, host_id, instance_api_id, property_id, property_value, update_user, update_ts) SELECT ?, host_id, instance_api_id, property_id, property_value, update_user, update_ts FROM instance_api_property_t WHERE host_id = ? AND instance_api_id = ANY(?) -- Parameter is a SQL Array of relevant instance_api_ids(Parameters: snapshotId, hostId, SQL Array of instance_api_ids)
-
snapshot_instance_app_property_t:INSERT INTO snapshot_instance_app_property_t (snapshot_id, host_id, instance_app_id, property_id, property_value, update_user, update_ts) SELECT ?, host_id, instance_app_id, property_id, property_value, update_user, update_ts FROM instance_app_property_t WHERE host_id = ? AND instance_app_id = ANY(?) -- Parameter is a SQL Array of relevant instance_app_ids(Parameters: snapshotId, hostId, SQL Array of instance_app_ids)
-
snapshot_instance_app_api_property_t:INSERT INTO snapshot_instance_app_api_property_t (snapshot_id, host_id, instance_app_id, instance_api_id, property_id, property_value, update_user, update_ts) SELECT ?, host_id, instance_app_id, instance_api_id, property_id, property_value, update_user, update_ts FROM instance_app_api_property_t WHERE host_id = ? AND instance_app_id = ANY(?) -- SQL Array of relevant instance_app_ids AND instance_api_id = ANY(?) -- SQL Array of relevant instance_api_ids(Parameters: snapshotId, hostId, SQL Array of instance_app_ids, SQL Array of instance_api_ids)
-
snapshot_environment_property_t:INSERT INTO snapshot_environment_property_t (snapshot_id, host_id, environment, property_id, property_value, update_user, update_ts) SELECT ?, host_id, environment, property_id, property_value, update_user, update_ts FROM environment_property_t WHERE host_id = ? AND environment = ?(Parameters: snapshotId, hostId, environment)
-
snapshot_product_version_property_t:INSERT INTO snapshot_product_version_property_t (snapshot_id, host_id, product_version_id, property_id, property_value, update_user, update_ts) SELECT ?, host_id, product_version_id, property_id, property_value, update_user, update_ts FROM product_version_property_t WHERE host_id = ? AND product_version_id = ?(Parameters: snapshotId, hostId, productVersionId)
-
snapshot_product_property_t:INSERT INTO snapshot_product_property_t (snapshot_id, product_id, property_id, property_value, update_user, update_ts) SELECT ?, product_id, property_id, property_value, update_user, update_ts FROM product_property_t WHERE product_id = ?(Parameters: snapshotId, productId)
Important Considerations:
- Transaction Management: Ensure all these inserts happen within a single atomic transaction.
- Error Handling: Robust error handling and rollback are critical.
- Performance: The aggregation query can be heavy. Consider its performance impact. The
INSERT ... SELECTstatements should be reasonably efficient if the source tables are properly indexed on their scope columns. - Parameterization: Use
PreparedStatementfor all queries to prevent SQL injection and improve performance. - Scope Derivation Logic: Ensure the logic in
deriveScopeInfoand the helpers likefindRelevantInstanceApiIdsis correct and handles cases where relationships might not exist (e.g., an instance with no associated APIs). - UUID Generation: Use a suitable UUID generator (like UUIDv7 via
uuid-creator). - Logging: Add clear logging for snapshot creation success/failure.
- Refinement: You’ll need to adapt the
AGGREGATE_EFFECTIVE_CONFIG_SQLquery based on the final version usingROW_NUMBERand correctly incorporate parameters.- Only one aggregation query run per snapshot event.
- Captures the complete multi-phase state at that point under one
snapshot_id. - Simpler
config_snapshot_tmetadata. - Facilitates rollbacks that might need to restore both ‘D’ and ‘R’ phase configurations.
- Cons:
- Requires modifying the aggregation query.
- Consuming services (like startup) need to add
AND config_phase = 'R'when queryingconfig_snapshot_property_t.
Conclusion:
Option 2 is the better approach. Create a single snapshot representing the point-in-time state for the defined scope, but modify your aggregation query to:
- Remove the
config_phase = ?filter. - Select
c.config_phasein the final output. - Store this
config_phasealong with the effectiveproperty_keyandproperty_valuein theconfig_snapshot_property_ttable.
This is more efficient for snapshot creation and provides a complete view for rollbacks. Consumers simply need to add a phase filter when reading the specific configuration they need (e.g., 'R' for runtime).
Modified Aggregation Query Snippet (Final SELECT):
-- (Inside the final SELECT statement of the modified aggregation query)
SELECT
-- snapshot_id needs to be added here or during INSERT
c.config_phase, -- <-- Select the phase
cfg.config_name || '.' || cp.property_name AS property_key,
ro.property_value,
cp.property_type,
cp.value_type
-- Include ro.priority_level AS source_priority if storing provenance
FROM RankedOverrides ro
JOIN config_property_t cp ON ro.property_id = cp.property_id
JOIN config_t cfg ON cp.config_id = cfg.config_id
-- Make sure the join to config_t (aliased as c or cfg) is available here to get the phase
-- This join likely happened earlier to get config_name anyway.
WHERE ro.rn = 1;
commitConfigInstance
Okay, let’s outline the structure of your commitConfigInstance service method and the necessary SQL INSERT statements using JDBC.
This involves several steps within a single database transaction:
- Generate Snapshot ID: Create a new UUID for the snapshot.
- Derive Scope IDs: Query live tables (
instance_t,product_version_t, etc.) based on the inputhostIdandinstanceIdto get other relevant scope identifiers (environment,productId,productVersionId,serviceId, etc.). - Insert Metadata: Insert a record into
config_snapshot_t. - Aggregate Effective Config: Run the complex aggregation query (using
ROW_NUMBER()or similar) to get the final effective properties. - Insert Effective Config: Insert the results from step 4 into
config_snapshot_property_t. - Snapshot Override Tables: For each relevant live override table (
instance_property_t,instance_api_property_t, etc.), select its current state (filtered by scope) and insert it into the correspondingsnapshot_*_property_ttable. - Commit/Rollback: Commit the transaction if all steps succeed, otherwise roll back.
Java Service Method Structure (Conceptual)
import com.github.f4b6a3.uuid.UuidCreator; // For UUIDv7 generation
import javax.sql.DataSource; // Assuming you have a DataSource injected
import java.sql.*;
import java.time.OffsetDateTime;
import java.util.*;
public class ConfigSnapshotService {
private final DataSource ds;
// Inject DataSource via constructor
// Pre-compile your complex aggregation query (modify based on previous examples)
private static final String AGGREGATE_EFFECTIVE_CONFIG_SQL = """
WITH AllOverrides AS (
-- Priority 10: Instance App API (merged) ...
-- Priority 20: Instance API (merged) ...
-- Priority 30: Instance App (merged) ...
-- Priority 40: Instance ...
-- Priority 50: Product Version ...
-- Priority 60: Environment ...
-- Priority 70: Product ...
-- Priority 100: Default ...
),
RankedOverrides AS (
SELECT ..., ROW_NUMBER() OVER (PARTITION BY ao.property_id ORDER BY ao.priority_level ASC) as rn
FROM AllOverrides ao WHERE ao.property_value IS NOT NULL
)
SELECT
c.config_phase, -- Phase from config_t
cfg.config_id, -- Added config_id
cp.property_id, -- Added property_id
cp.property_name, -- Added property_name
cp.property_type,
cp.value_type,
cfg.config_name || '.' || cp.property_name AS property_key, -- Keep for logging/debug? Not needed in snapshot table itself
ro.property_value,
ro.priority_level -- To determine source_level
FROM RankedOverrides ro
JOIN config_property_t cp ON ro.property_id = cp.property_id
JOIN config_t cfg ON cp.config_id = cfg.config_id
WHERE ro.rn = 1;
"""; // NOTE: Add parameters (?) for host_id, instance_id, derived IDs etc.
public Result<String> commitConfigInstance(Map<String, Object> event) {
// 1. Extract Input Parameters
UUID hostId = (UUID) event.get("hostId");
UUID instanceId = (UUID) event.get("instanceId");
String snapshotType = (String) event.getOrDefault("snapshotType", "USER_SAVE"); // Default type
String description = (String) event.get("description");
UUID userId = (UUID) event.get("userId"); // May be null
UUID deploymentId = (UUID) event.get("deploymentId"); // May be null
if (hostId == null || instanceId == null) {
return Failure.of(new Status(INVALID_PARAMETER, "hostId and instanceId are required."));
}
UUID snapshotId = UuidCreator.getTimeOrderedEpoch(); // Generate Snapshot ID (e.g., V7)
Connection connection = null;
try {
connection = ds.getConnection();
connection.setAutoCommit(false); // Start Transaction
// 2. Derive Scope IDs
// Query instance_t and potentially product_version_t based on hostId, instanceId
DerivedScope scope = deriveScopeInfo(connection, hostId, instanceId);
if (scope == null) {
connection.rollback(); // Rollback if instance not found
return Failure.of(new Status(OBJECT_NOT_FOUND, "Instance not found for hostId/instanceId."));
}
// 3. Insert Snapshot Metadata
insertSnapshotMetadata(connection, snapshotId, snapshotType, description, userId, deploymentId, hostId, scope);
// 4 & 5. Aggregate and Insert Effective Config
insertEffectiveConfigSnapshot(connection, snapshotId, hostId, instanceId, scope);
// 6. Snapshot Individual Override Tables
// Use INSERT ... SELECT ... for efficiency
snapshotInstanceProperties(connection, snapshotId, hostId, instanceId);
snapshotInstanceApiProperties(connection, snapshotId, hostId, instanceId);
snapshotInstanceAppProperties(connection, snapshotId, hostId, instanceId);
snapshotInstanceAppApiProperties(connection, snapshotId, hostId, instanceId); // Requires finding relevant App/API IDs first
snapshotEnvironmentProperties(connection, snapshotId, hostId, scope.environment());
snapshotProductVersionProperties(connection, snapshotId, hostId, scope.productVersionId());
snapshotProductProperties(connection, snapshotId, scope.productId());
// Add others as needed
// 7. Commit Transaction
connection.commit();
logger.info("Successfully created config snapshot: {}", snapshotId);
return Success.of(snapshotId.toString());
} catch (SQLException e) {
logger.error("SQLException during snapshot creation for instance {}: {}", instanceId, e.getMessage(), e);
if (connection != null) {
try {
connection.rollback();
} catch (SQLException ex) {
logger.error("Error rolling back transaction:", ex);
}
}
return Failure.of(new Status(SQL_EXCEPTION, "Database error during snapshot creation."));
} catch (Exception e) { // Catch other potential errors (e.g., during scope derivation)
logger.error("Exception during snapshot creation for instance {}: {}", instanceId, e.getMessage(), e);
if (connection != null) {
try { connection.rollback(); } catch (SQLException ex) { logger.error("Error rolling back transaction:", ex); }
}
return Failure.of(new Status(GENERIC_EXCEPTION, "Unexpected error during snapshot creation."));
} finally {
if (connection != null) {
try {
connection.setAutoCommit(true); // Restore default behavior
connection.close();
} catch (SQLException e) {
logger.error("Error closing connection:", e);
}
}
}
}
// --- Helper Methods ---
// Placeholder for derived scope data structure
private record DerivedScope(String environment, String productId, String productVersion, UUID productVersionId, String serviceId /*, add API details if needed */) {}
private DerivedScope deriveScopeInfo(Connection conn, UUID hostId, UUID instanceId) throws SQLException {
// Query instance_t LEFT JOIN product_version_t ... WHERE i.host_id = ? AND i.instance_id = ?
// Extract environment, service_id from instance_t
// Extract product_id, product_version from product_version_t (via product_version_id in instance_t)
// Return new DerivedScope(...) or null if not found
String sql = """
SELECT i.environment, i.service_id, pv.product_id, pv.product_version, i.product_version_id
FROM instance_t i
LEFT JOIN product_version_t pv ON i.host_id = pv.host_id AND i.product_version_id = pv.product_version_id
WHERE i.host_id = ? AND i.instance_id = ?
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, hostId);
ps.setObject(2, instanceId);
try (ResultSet rs = ps.executeQuery()) {
if (rs.next()) {
return new DerivedScope(
rs.getString("environment"),
rs.getString("product_id"),
rs.getString("product_version"),
rs.getObject("product_version_id", UUID.class),
rs.getString("service_id")
);
} else {
return null; // Instance not found
}
}
}
}
private void insertSnapshotMetadata(Connection conn, UUID snapshotId, String snapshotType, String description,
UUID userId, UUID deploymentId, UUID hostId, DerivedScope scope) throws SQLException {
String sql = """
INSERT INTO config_snapshot_t
(snapshot_id, snapshot_ts, snapshot_type, description, user_id, deployment_id,
scope_host_id, scope_environment, scope_product_id, scope_product_version_id, -- Changed col name
scope_service_id /*, scope_api_id, scope_api_version - Add if applicable */)
VALUES (?, CURRENT_TIMESTAMP, ?, ?, ?, ?, ?, ?, ?, ?, ? /*, ?, ? */)
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setString(2, snapshotType);
ps.setString(3, description);
ps.setObject(4, userId); // setObject handles null correctly
ps.setObject(5, deploymentId); // setObject handles null correctly
ps.setObject(6, hostId);
ps.setString(7, scope.environment());
ps.setString(8, scope.productId());
ps.setObject(9, scope.productVersionId()); // Store the ID
ps.setString(10, scope.serviceId());
// Set API scope if needed ps.setObject(11, ...); ps.setString(12, ...);
ps.executeUpdate();
}
}
private void insertEffectiveConfigSnapshot(Connection conn, UUID snapshotId, UUID hostId, UUID instanceId, DerivedScope scope) throws SQLException {
String insertSql = """
INSERT INTO config_snapshot_property_t
(snapshot_property_id, snapshot_id, config_phase, config_id, property_id, property_name,
property_type, property_value, value_type, source_level)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""";
// Prepare the aggregation query
try (PreparedStatement selectStmt = conn.prepareStatement(AGGREGATE_EFFECTIVE_CONFIG_SQL);
PreparedStatement insertStmt = conn.prepareStatement(insertSql)) {
// Set ALL parameters for the AGGREGATE_EFFECTIVE_CONFIG_SQL query
int paramIndex = 1;
// Example: set parameters based on how AGGREGATE_EFFECTIVE_CONFIG_SQL is structured
// selectStmt.setObject(paramIndex++, hostId);
// selectStmt.setObject(paramIndex++, instanceId);
// ... set derived scope IDs (productVersionId, environment, productId) ...
// ... set parameters for all UNION branches and potential subqueries ...
try (ResultSet rs = selectStmt.executeQuery()) {
int batchCount = 0;
while (rs.next()) {
insertStmt.setObject(1, UuidCreator.getTimeOrderedEpoch()); // snapshot_property_id
insertStmt.setObject(2, snapshotId);
insertStmt.setString(3, rs.getString("config_phase"));
insertStmt.setObject(4, rs.getObject("config_id", UUID.class));
insertStmt.setObject(5, rs.getObject("property_id", UUID.class));
insertStmt.setString(6, rs.getString("property_name"));
insertStmt.setString(7, rs.getString("property_type"));
insertStmt.setString(8, rs.getString("property_value"));
insertStmt.setString(9, rs.getString("value_type"));
insertStmt.setString(10, mapPriorityToSourceLevel(rs.getInt("priority_level"))); // Map numeric priority back to level name
insertStmt.addBatch();
batchCount++;
if (batchCount % 100 == 0) { // Execute batch periodically
insertStmt.executeBatch();
}
}
if (batchCount % 100 != 0) { // Execute remaining batch
insertStmt.executeBatch();
}
}
}
}
// Helper to map priority back to source level name
private String mapPriorityToSourceLevel(int priority) {
return switch (priority) {
case 10 -> "instance_app_api"; // Adjust priorities as used in your query
case 20 -> "instance_api";
case 30 -> "instance_app";
case 40 -> "instance";
case 50 -> "product_version";
case 60 -> "environment";
case 70 -> "product";
case 100 -> "default";
default -> "unknown";
};
}
// --- Methods for Snapshotting Individual Override Tables ---
private void snapshotInstanceProperties(Connection conn, UUID snapshotId, UUID hostId, UUID instanceId) throws SQLException {
String sql = """
INSERT INTO snapshot_instance_property_t
(snapshot_id, host_id, instance_id, property_id, property_value, update_user, update_ts)
SELECT ?, host_id, instance_id, property_id, property_value, update_user, update_ts
FROM instance_property_t
WHERE host_id = ? AND instance_id = ?
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
ps.setObject(3, instanceId);
ps.executeUpdate();
}
}
private void snapshotInstanceApiProperties(Connection conn, UUID snapshotId, UUID hostId, UUID instanceId) throws SQLException {
// Find relevant instance_api_ids first
List<UUID> apiIds = findRelevantInstanceApiIds(conn, hostId, instanceId);
if (apiIds.isEmpty()) return; // No API overrides for this instance
String sql = """
INSERT INTO snapshot_instance_api_property_t
(snapshot_id, host_id, instance_api_id, property_id, property_value, update_user, update_ts)
SELECT ?, host_id, instance_api_id, property_id, property_value, update_user, update_ts
FROM instance_api_property_t
WHERE host_id = ? AND instance_api_id = ANY(?) -- Use ANY with array for multiple IDs
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
// Create a SQL Array from the List of UUIDs
Array sqlArray = conn.createArrayOf("UUID", apiIds.toArray());
ps.setArray(3, sqlArray);
ps.executeUpdate();
sqlArray.free(); // Release array resources
}
}
// Similar methods for snapshotInstanceAppProperties, snapshotInstanceAppApiProperties...
// These will need helper methods like findRelevantInstanceApiIds/findRelevantInstanceAppIds
private void snapshotEnvironmentProperties(Connection conn, UUID snapshotId, UUID hostId, String environment) throws SQLException {
if (environment == null || environment.isEmpty()) return; // No environment scope
String sql = """
INSERT INTO snapshot_environment_property_t
(snapshot_id, host_id, environment, property_id, property_value, update_user, update_ts)
SELECT ?, host_id, environment, property_id, property_value, update_user, update_ts
FROM environment_property_t
WHERE host_id = ? AND environment = ?
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
ps.setString(3, environment);
ps.executeUpdate();
}
}
private void snapshotProductVersionProperties(Connection conn, UUID snapshotId, UUID hostId, UUID productVersionId) throws SQLException {
if (productVersionId == null) return;
String sql = """
INSERT INTO snapshot_product_version_property_t
(snapshot_id, host_id, product_version_id, property_id, property_value, update_user, update_ts)
SELECT ?, host_id, product_version_id, property_id, property_value, update_user, update_ts
FROM product_version_property_t
WHERE host_id = ? AND product_version_id = ?
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
ps.setObject(3, productVersionId);
ps.executeUpdate();
}
}
private void snapshotProductProperties(Connection conn, UUID snapshotId, String productId) throws SQLException {
if (productId == null || productId.isEmpty()) return;
String sql = """
INSERT INTO snapshot_product_property_t
(snapshot_id, product_id, property_id, property_value, update_user, update_ts)
SELECT ?, product_id, property_id, property_value, update_user, update_ts
FROM product_property_t
WHERE product_id = ?
""";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setString(2, productId);
ps.executeUpdate();
}
}
// --- Helper method to find associated instance_api_ids ---
private List<UUID> findRelevantInstanceApiIds(Connection conn, UUID hostId, UUID instanceId) throws SQLException {
List<UUID> ids = new ArrayList<>();
String sql = "SELECT instance_api_id FROM instance_api_t WHERE host_id = ? AND instance_id = ?";
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, hostId);
ps.setObject(2, instanceId);
try (ResultSet rs = ps.executeQuery()) {
while(rs.next()) {
ids.add(rs.getObject("instance_api_id", UUID.class));
}
}
}
return ids;
}
// --- Add similar helper for findRelevantInstanceAppIds ---
// --- Add similar helper for findRelevantInstanceAppApiIds (if needed) ---
}
SQL INSERT Statements:
-
config_snapshot_t:INSERT INTO config_snapshot_t (snapshot_id, snapshot_ts, snapshot_type, description, user_id, deployment_id, scope_host_id, scope_environment, scope_product_id, scope_product_version_id, scope_service_id /*, ... other scope cols */) VALUES (?, CURRENT_TIMESTAMP, ?, ?, ?, ?, ?, ?, ?, ?, ? /*, ... */)(Parameters: snapshotId, snapshotType, description, userId, deploymentId, hostId, environment, productId, productVersionId, serviceId, …)
-
config_snapshot_property_t: (Executed in a loop/batch)INSERT INTO config_snapshot_property_t (snapshot_property_id, snapshot_id, config_phase, config_id, property_id, property_name, property_type, property_value, value_type, source_level) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)(Parameters: new UUID, snapshotId, phase, configId, propertyId, propName, propType, propValue, valType, sourceLevelString)
-
snapshot_instance_property_t:INSERT INTO snapshot_instance_property_t (snapshot_id, host_id, instance_id, property_id, property_value, update_user, update_ts) SELECT ?, host_id, instance_id, property_id, property_value, update_user, update_ts FROM instance_property_t WHERE host_id = ? AND instance_id = ?(Parameters: snapshotId, hostId, instanceId)
-
snapshot_instance_api_property_t:INSERT INTO snapshot_instance_api_property_t (snapshot_id, host_id, instance_api_id, property_id, property_value, update_user, update_ts) SELECT ?, host_id, instance_api_id, property_id, property_value, update_user, update_ts FROM instance_api_property_t WHERE host_id = ? AND instance_api_id = ANY(?) -- Parameter is a SQL Array of relevant instance_api_ids(Parameters: snapshotId, hostId, SQL Array of instance_api_ids)
-
snapshot_instance_app_property_t:INSERT INTO snapshot_instance_app_property_t (snapshot_id, host_id, instance_app_id, property_id, property_value, update_user, update_ts) SELECT ?, host_id, instance_app_id, property_id, property_value, update_user, update_ts FROM instance_app_property_t WHERE host_id = ? AND instance_app_id = ANY(?) -- Parameter is a SQL Array of relevant instance_app_ids(Parameters: snapshotId, hostId, SQL Array of instance_app_ids)
-
snapshot_instance_app_api_property_t:INSERT INTO snapshot_instance_app_api_property_t (snapshot_id, host_id, instance_app_id, instance_api_id, property_id, property_value, update_user, update_ts) SELECT ?, host_id, instance_app_id, instance_api_id, property_id, property_value, update_user, update_ts FROM instance_app_api_property_t WHERE host_id = ? AND instance_app_id = ANY(?) -- SQL Array of relevant instance_app_ids AND instance_api_id = ANY(?) -- SQL Array of relevant instance_api_ids(Parameters: snapshotId, hostId, SQL Array of instance_app_ids, SQL Array of instance_api_ids)
-
snapshot_environment_property_t:INSERT INTO snapshot_environment_property_t (snapshot_id, host_id, environment, property_id, property_value, update_user, update_ts) SELECT ?, host_id, environment, property_id, property_value, update_user, update_ts FROM environment_property_t WHERE host_id = ? AND environment = ?(Parameters: snapshotId, hostId, environment)
-
snapshot_product_version_property_t:INSERT INTO snapshot_product_version_property_t (snapshot_id, host_id, product_version_id, property_id, property_value, update_user, update_ts) SELECT ?, host_id, product_version_id, property_id, property_value, update_user, update_ts FROM product_version_property_t WHERE host_id = ? AND product_version_id = ?(Parameters: snapshotId, hostId, productVersionId)
-
snapshot_product_property_t:INSERT INTO snapshot_product_property_t (snapshot_id, product_id, property_id, property_value, update_user, update_ts) SELECT ?, product_id, property_id, property_value, update_user, update_ts FROM product_property_t WHERE product_id = ?(Parameters: snapshotId, productId)
Important Considerations:
- Transaction Management: Ensure all these inserts happen within a single atomic transaction.
- Error Handling: Robust error handling and rollback are critical.
- Performance: The aggregation query can be heavy. Consider its performance impact. The
INSERT ... SELECTstatements should be reasonably efficient if the source tables are properly indexed on their scope columns. - Parameterization: Use
PreparedStatementfor all queries to prevent SQL injection and improve performance. - Scope Derivation Logic: Ensure the logic in
deriveScopeInfoand the helpers likefindRelevantInstanceApiIdsis correct and handles cases where relationships might not exist (e.g., an instance with no associated APIs). - UUID Generation: Use a suitable UUID generator (like UUIDv7 via
uuid-creator). - Logging: Add clear logging for snapshot creation success/failure.
- Refinement: You’ll need to adapt the
AGGREGATE_EFFECTIVE_CONFIG_SQLquery based on the final version usingROW_NUMBERand correctly incorporate parameters.
rollbackConfigInstance
Okay, here’s the rollbackConfigInstance method implementing the DELETE/INSERT strategy to restore the state of instance-level and related sub-level overrides from a snapshot.
Assumptions:
- “Rolling back an instance” means restoring the overrides defined specifically for that instance and its associated APIs, Apps, and App-API combinations. It does not modify higher-level overrides (Environment, Product Version, Product).
- The
snapshot_*_property_ttables accurately store the state of the corresponding live tables at the time the snapshot was taken. - The necessary helper methods like
findRelevantInstanceApiIds,findRelevantInstanceAppIdsexist (examples provided).
import com.github.f4b6a3.uuid.UuidCreator; // If needed for audit logging ID
import javax.sql.DataSource;
import java.sql.*;
import java.util.*;
public class ConfigRollbackService {
private final DataSource ds;
// Inject DataSource via constructor
// --- SQL Templates ---
// DELETE Statements (Targeting LIVE tables)
private static final String DELETE_INSTANCE_PROPS_SQL = "DELETE FROM instance_property_t WHERE host_id = ? AND instance_id = ?";
private static final String DELETE_INSTANCE_API_PROPS_SQL = "DELETE FROM instance_api_property_t WHERE host_id = ? AND instance_api_id = ANY(?)";
private static final String DELETE_INSTANCE_APP_PROPS_SQL = "DELETE FROM instance_app_property_t WHERE host_id = ? AND instance_app_id = ANY(?)";
private static final String DELETE_INSTANCE_APP_API_PROPS_SQL = "DELETE FROM instance_app_api_property_t WHERE host_id = ? AND instance_app_id = ANY(?) AND instance_api_id = ANY(?)";
// INSERT ... SELECT Statements (From SNAPSHOT tables to LIVE tables)
private static final String INSERT_INSTANCE_PROPS_SQL = """
INSERT INTO instance_property_t
(host_id, instance_id, property_id, property_value, update_user, update_ts)
SELECT host_id, instance_id, property_id, property_value, update_user, update_ts
FROM snapshot_instance_property_t
WHERE snapshot_id = ? AND host_id = ? AND instance_id = ?
""";
private static final String INSERT_INSTANCE_API_PROPS_SQL = """
INSERT INTO instance_api_property_t
(host_id, instance_api_id, property_id, property_value, update_user, update_ts)
SELECT host_id, instance_api_id, property_id, property_value, update_user, update_ts
FROM snapshot_instance_api_property_t
WHERE snapshot_id = ? AND host_id = ? AND instance_api_id = ANY(?)
""";
private static final String INSERT_INSTANCE_APP_PROPS_SQL = """
INSERT INTO instance_app_property_t
(host_id, instance_app_id, property_id, property_value, update_user, update_ts)
SELECT host_id, instance_app_id, property_id, property_value, update_user, update_ts
FROM snapshot_instance_app_property_t
WHERE snapshot_id = ? AND host_id = ? AND instance_app_id = ANY(?)
""";
private static final String INSERT_INSTANCE_APP_API_PROPS_SQL = """
INSERT INTO instance_app_api_property_t
(host_id, instance_app_id, instance_api_id, property_id, property_value, update_user, update_ts)
SELECT host_id, instance_app_id, instance_api_id, property_id, property_value, update_user, update_ts
FROM snapshot_instance_app_api_property_t
WHERE snapshot_id = ? AND host_id = ? AND instance_app_id = ANY(?) AND instance_api_id = ANY(?)
""";
public Result<String> rollbackConfigInstance(Map<String, Object> event) {
// 1. Extract Input Parameters
UUID snapshotId = (UUID) event.get("snapshotId");
UUID hostId = (UUID) event.get("hostId");
UUID instanceId = (UUID) event.get("instanceId");
UUID userId = (UUID) event.get("userId"); // For potential auditing
String description = (String) event.get("rollbackDescription"); // Optional reason
if (snapshotId == null || hostId == null || instanceId == null) {
return Failure.of(new Status(INVALID_PARAMETER, "snapshotId, hostId, and instanceId are required."));
}
Connection connection = null;
List<UUID> currentApiIds = null;
List<UUID> currentAppIds = null;
try {
connection = ds.getConnection();
connection.setAutoCommit(false); // Start Transaction
// --- Pre-computation: Find CURRENT associated IDs for DELETE scope ---
// It's generally safer to delete based on current relationships and then
// insert based on snapshot relationships if they could have diverged.
currentApiIds = findRelevantInstanceApiIds(connection, hostId, instanceId);
currentAppIds = findRelevantInstanceAppIds(connection, hostId, instanceId);
// Note: InstanceAppApi requires both lists.
logger.info("Starting rollback for instance {} (host {}) to snapshot {}", instanceId, hostId, snapshotId);
// --- Execute Deletes from LIVE tables ---
executeDelete(connection, DELETE_INSTANCE_PROPS_SQL, hostId, instanceId);
if (!currentApiIds.isEmpty()) {
executeDeleteWithArray(connection, DELETE_INSTANCE_API_PROPS_SQL, hostId, currentApiIds);
// Also delete AppApi props related to these APIs if apps also exist
if (!currentAppIds.isEmpty()) {
executeDeleteWithTwoArrays(connection, DELETE_INSTANCE_APP_API_PROPS_SQL, hostId, currentAppIds, currentApiIds);
}
}
if (!currentAppIds.isEmpty()) {
executeDeleteWithArray(connection, DELETE_INSTANCE_APP_PROPS_SQL, hostId, currentAppIds);
// AppApi props deletion might have already happened above if APIs existed.
// If only apps existed but no APIs, delete AppApi here (redundant if handled above)
// Generally safe to run the AppApi delete again if needed, targeting only appIds.
// For simplicity, we assume the AppApi delete targeting both arrays covers necessary cases.
}
// --- Execute Inserts from SNAPSHOT tables ---
executeInsertSelect(connection, INSERT_INSTANCE_PROPS_SQL, snapshotId, hostId, instanceId);
// For array-based inserts, we need the IDs *from the snapshot time*
// However, the SELECT inside the INSERT query implicitly filters by snapshot_id AND the array condition,
// so it should correctly only insert relationships that existed in the snapshot.
// We still use the *current* IDs to DEFINE the overall scope of instance being affected,
// but the INSERT...SELECT filters correctly based on snapshot content.
if (!currentApiIds.isEmpty()) { // Use currentApiIds to decide IF we run the insert query
executeInsertSelectWithArray(connection, INSERT_INSTANCE_API_PROPS_SQL, snapshotId, hostId, currentApiIds);
if (!currentAppIds.isEmpty()) {
executeInsertSelectWithTwoArrays(connection, INSERT_INSTANCE_APP_API_PROPS_SQL, snapshotId, hostId, currentAppIds, currentApiIds);
}
}
if (!currentAppIds.isEmpty()) { // Use currentAppIds to decide IF we run the insert query
executeInsertSelectWithArray(connection, INSERT_INSTANCE_APP_PROPS_SQL, snapshotId, hostId, currentAppIds);
// Redundant AppApi insert if handled above? No, the INSERT uses the AppId filter.
// If only apps existed at snapshot time, this covers it.
}
// --- Optional: Audit Logging ---
// logRollbackActivity(connection, snapshotId, hostId, instanceId, userId, description);
// --- Commit Transaction ---
connection.commit();
logger.info("Successfully rolled back instance {} (host {}) to snapshot {}", instanceId, hostId, snapshotId);
return Success.of("Rollback successful to snapshot " + snapshotId);
} catch (SQLException e) {
logger.error("SQLException during rollback for instance {} to snapshot {}: {}", instanceId, snapshotId, e.getMessage(), e);
if (connection != null) {
try {
connection.rollback();
logger.warn("Transaction rolled back for instance {} snapshot {}", instanceId, snapshotId);
} catch (SQLException ex) {
logger.error("Error rolling back transaction:", ex);
}
}
return Failure.of(new Status(SQL_EXCEPTION, "Database error during rollback operation."));
} catch (Exception e) { // Catch other potential errors
logger.error("Exception during rollback for instance {} to snapshot {}: {}", instanceId, snapshotId, e.getMessage(), e);
if (connection != null) {
try { connection.rollback(); } catch (SQLException ex) { logger.error("Error rolling back transaction:", ex); }
}
return Failure.of(new Status(GENERIC_EXCEPTION, "Unexpected error during rollback operation."));
} finally {
if (connection != null) {
try {
connection.setAutoCommit(true); // Restore default behavior
connection.close();
} catch (SQLException e) {
logger.error("Error closing connection:", e);
}
}
}
}
// --- Helper Methods for Execution ---
private void executeDelete(Connection conn, String sql, UUID hostId, UUID instanceId) throws SQLException {
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, hostId);
ps.setObject(2, instanceId);
int rowsAffected = ps.executeUpdate();
logger.debug("Deleted {} rows from {} for instance {}", rowsAffected, getTableNameFromDeleteSql(sql), instanceId);
}
}
private void executeDeleteWithArray(Connection conn, String sql, UUID hostId, List<UUID> idList) throws SQLException {
if (idList == null || idList.isEmpty()) return; // Nothing to delete if list is empty
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, hostId);
Array sqlArray = conn.createArrayOf("UUID", idList.toArray());
ps.setArray(2, sqlArray);
int rowsAffected = ps.executeUpdate();
logger.debug("Deleted {} rows from {} for {} IDs", rowsAffected, getTableNameFromDeleteSql(sql), idList.size());
sqlArray.free();
}
}
private void executeDeleteWithTwoArrays(Connection conn, String sql, UUID hostId, List<UUID> idList1, List<UUID> idList2) throws SQLException {
if (idList1 == null || idList1.isEmpty() || idList2 == null || idList2.isEmpty()) return;
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, hostId);
Array sqlArray1 = conn.createArrayOf("UUID", idList1.toArray());
Array sqlArray2 = conn.createArrayOf("UUID", idList2.toArray());
ps.setArray(2, sqlArray1);
ps.setArray(3, sqlArray2);
int rowsAffected = ps.executeUpdate();
logger.debug("Deleted {} rows from {} for {}x{} IDs", rowsAffected, getTableNameFromDeleteSql(sql), idList1.size(), idList2.size());
sqlArray1.free();
sqlArray2.free();
}
}
private void executeInsertSelect(Connection conn, String sql, UUID snapshotId, UUID hostId, UUID instanceId) throws SQLException {
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
ps.setObject(3, instanceId);
int rowsAffected = ps.executeUpdate();
logger.debug("Inserted {} rows into {} from snapshot {}", rowsAffected, getTableNameFromInsertSql(sql), snapshotId);
}
}
private void executeInsertSelectWithArray(Connection conn, String sql, UUID snapshotId, UUID hostId, List<UUID> idList) throws SQLException {
if (idList == null || idList.isEmpty()) return; // No scope to insert for
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
Array sqlArray = conn.createArrayOf("UUID", idList.toArray());
ps.setArray(3, sqlArray);
int rowsAffected = ps.executeUpdate();
logger.debug("Inserted {} rows into {} from snapshot {} for {} IDs", rowsAffected, getTableNameFromInsertSql(sql), snapshotId, idList.size());
sqlArray.free();
}
}
private void executeInsertSelectWithTwoArrays(Connection conn, String sql, UUID snapshotId, UUID hostId, List<UUID> idList1, List<UUID> idList2) throws SQLException {
if (idList1 == null || idList1.isEmpty() || idList2 == null || idList2.isEmpty()) return;
try (PreparedStatement ps = conn.prepareStatement(sql)) {
ps.setObject(1, snapshotId);
ps.setObject(2, hostId);
Array sqlArray1 = conn.createArrayOf("UUID", idList1.toArray());
Array sqlArray2 = conn.createArrayOf("UUID", idList2.toArray());
ps.setArray(3, sqlArray1);
ps.setArray(4, sqlArray2);
int rowsAffected = ps.executeUpdate();
logger.debug("Inserted {} rows into {} from snapshot {} for {}x{} IDs", rowsAffected, getTableNameFromInsertSql(sql), snapshotId, idList1.size(), idList2.size());
sqlArray1.free();
sqlArray2.free();
}
}
// --- Helper methods to find associated IDs (same as before) ---
private List<UUID> findRelevantInstanceApiIds(Connection conn, UUID hostId, UUID instanceId) throws SQLException {
// ... implementation ...
}
private List<UUID> findRelevantInstanceAppIds(Connection conn, UUID hostId, UUID instanceId) throws SQLException {
// ... implementation ...
}
// --- Optional: Helper to get table name from SQL for logging ---
private String getTableNameFromDeleteSql(String sql) {
// Simple parsing, might need adjustment
try { return sql.split("FROM ")[1].split(" ")[0]; } catch (Exception e) { return "[unknown table]"; }
}
private String getTableNameFromInsertSql(String sql) {
try { return sql.split("INTO ")[1].split(" ")[0]; } catch (Exception e) { return "[unknown table]"; }
}
// --- Optional: Audit Logging Method ---
// private void logRollbackActivity(Connection conn, UUID snapshotId, ...) throws SQLException { ... }
}
Explanation:
- Parameter Extraction: Gets
snapshotId,hostId,instanceId. - Transaction Control: Sets
setAutoCommit(false)at the start and usescommit()orrollback(). - Find Current Related IDs: Queries
instance_api_tandinstance_app_tto find the currently associated APIs and Apps for the target instance. This is needed to define the scope for theDELETEoperations. - Execute Deletes: Uses helper methods to execute
DELETEstatements against the live override tables (instance_property_t,instance_api_property_t, etc.), filtering byhostId,instanceId, and the arrays ofcurrentApiIds/currentAppIdswhere applicable. This clears the current overrides within the specific scope. - Execute Inserts: Uses helper methods to execute
INSERT INTO [live_table] SELECT ... FROM [snapshot_table]statements.- These statements select data from the
snapshot_*_property_ttables. - They are filtered by the target
snapshotId. - Crucially, they are also filtered by
hostId,instanceId, and the relevantinstance_api_id/instance_app_idarrays. This ensures only the overrides relevant to this instance within that snapshot are inserted.
- These statements select data from the
- SQL Arrays: Uses
connection.createArrayOf("UUID", ...)to pass lists of IDs efficiently to PostgreSQL’sANY(?)operator. Remember tofree()the array resources. - Helpers: Includes helper methods for executing the different types of DELETE/INSERT statements and for finding the related API/App IDs.
- Error Handling: Uses
try-catch-finallyto manage the transaction and connection state. - Logging: Added basic logging for start, success, errors, and rows affected.
- Scope Focus: This implementation focuses the rollback on the instance and its direct sub-levels (API, App, App-API). It assumes rolling back an instance doesn’t automatically mean rolling back shared Environment or Product Version overrides.
This approach provides a clean and relatively robust way to restore the specific override state from your snapshots using the DELETE/INSERT strategy. Remember to test thoroughly!
SID and Host Verification
Problem
GitHub issue https://github.com/lightapi/portal-service/issues/39 reports that
config-server accepted a valid JWT whose service identity did not match the
requested service configuration.
The reported token contains:
{
"iss": "urn:com:networknt:oauth2:v1",
"aud": "urn:com.networknt",
"cid": "019e2825-146d-7a00-b0e8-3671158bb32a",
"scp": ["portal.r", "portal.w"],
"host": "01964b05-552a-7c4b-9184-6857e7f3dc5f",
"sid": "com.networknt.light-gateway-1.0.0"
}
The request used a different service id:
serviceId=com.networknt.ai.gateway-1.0.0
The token is cryptographically valid, but it must not authorize access to a
different service’s configuration. Signature, issuer, audience, and scope
validation prove that the token is valid; they do not prove that the token is
valid for the requested host and serviceId.
The security contract for runtime service tokens is now:
token.host == requested host context
token.sid == requested service context
token.env == requested environment context, when envTag is present
For config-server, the requested host context is the host query parameter.
For controller registry registration, the requested host context is the
controller’s configured hostId, because service/register does not carry a
separate hostId.
Original Gaps
Rust portal-service/apps/config-server
The Rust config server verifies the bearer token through JwtVerifier and binds
the decoded claims into each handler:
#![allow(unused)]
fn main() {
async fn get_configs(
State(state): State<AppState>,
_claims: Claims,
Query(query): Query<ConfigQuery>,
) -> Response
}The handlers then read host and service_id from the query and call the read
model. They did not compare token host with query.host, and did not compare
token sid with query.service_id.
Affected endpoints:
GET /config-server/configs
GET /config-server/certs
GET /config-server/files
Java light-config-server
The Java config server routes the same three endpoints through the default
chain, which includes JwtVerifyHandler. The Light-4j security handler stores
the verified JwtClaims in AUDIT_INFO under Constants.SUBJECT_CLAIMS.
The business handlers then read host and serviceId from query parameters
and call the database helpers. They did not compare token host with request
host, and did not compare token sid with request serviceId.
Affected handlers:
ConfigsGetHandler
CertsGetHandler
FilesGetHandler
Related Controller Registry Behavior
The controller registry paths already perform service identity binding during
runtime registration, but they must use the same strict sid and host
contract as config-server.
The registry request carries serviceId in the service/register payload. It
does not carry a separate hostId; registry writes are scoped to the
controller’s configured host id. The integration token must carry both sid
and host. The registration must be rejected before the runtime instance is
stored when the token has no sid, a blank sid, or a sid that differs from
the requested serviceId. It must also be rejected when the token has no
host, a blank host, or a host that differs from the configured controller
host id.
sub is not an acceptable fallback for registry authorization. It can still be
used by other OAuth flows as the subject, but the registry authorization check
must bind the explicit service authorization claim:
token.sid == register.params.serviceId
token.host == controller.config.hostId
In controller-rs, this rule belongs in ServiceJwtVerifier::validate, before
handle_socket persists the runtime instance. In Java light-controller, it
belongs in ServiceJwtValidator.validateServiceToken, called by
MicroserviceEndpoint.register with the requested serviceId.
The controller implementations should check env when the request provides
envTag, but that check is an additional constraint. It does not replace the
mandatory sid to serviceId comparison or the mandatory host to controller
hostId comparison.
Security Requirement
For any controller registry request or config-server request that asks for a
service-scoped resource with serviceId, the token must contain a sid claim
equal to that requested serviceId.
For any config-server request with a host query parameter, the token must
contain a host claim equal to that requested host.
For any controller registry service/register request, the token must contain
a host claim equal to the controller’s configured hostId.
For any config-server request or controller registry service/register request
with a non-blank envTag, the token must contain an env claim equal to that
requested envTag.
The request should be rejected when:
serviceIdis present and non-blank, but tokensidis missing.serviceIdis present and non-blank, but tokensidis blank.serviceIdis present and non-blank, but tokensiddiffers from it.hostis present and non-blank, but tokenhostis missing.hostis present and non-blank, but tokenhostis blank.hostis present and non-blank, but tokenhostdiffers from it.envTagis present and non-blank, but tokenenvis missing.envTagis present and non-blank, but tokenenvis blank.envTagis present and non-blank, but tokenenvdiffers from it.
The request may continue to use the existing product-level path when no
serviceId is supplied. Product-level requests are not service-scoped and
should not be forced to match sid until the product-level authorization model
is explicitly designed.
The same exception does not apply to controller registry registration because
service/register always carries a requested serviceId.
Goals
- Prevent one service token from downloading another service’s config, certs, or files.
- Prevent one service token from registering a runtime instance for another service id.
- Implement the same authorization rule in Rust
config-serverand Javalight-config-server. - Implement the same authorization rule in Rust
controller-rsand Javalight-controller. - Keep existing JWT signature, issuer, audience, and scope checks unchanged.
- Keep the rule local to config-server handlers, because only they know the
requested
hostandserviceId. - Return a clear authorization failure before any database lookup is executed.
Implemented Behavior
The implementation applies the same authorization contract in all four runtime paths:
token.host == requested host context
token.sid == requested service context
The implemented paths are:
controller-rs/src/auth.rs
light-controller/src/main/java/com/networknt/controller/auth/ServiceJwtValidator.java
portal-service/crates/internal-auth/src/lib.rs
portal-service/apps/config-server/src/main.rs
light-config-server/src/main/java/com/networknt/configserver/util/ServiceIdAuthorizationUtil.java
For Rust controller-rs, ServiceJwtVerifier::validate now requires a
non-blank sid and compares it to the registration serviceId. It also
requires a non-blank host and compares it to the controller hostId. When
registration includes envTag, it requires token env and compares it to that
envTag.
For Java light-controller, ServiceJwtValidator.validateServiceToken applies
the same checks when MicroserviceEndpoint.register passes the requested
serviceId.
For Rust config-server, internal-auth::Claims now exposes explicit optional
sid, host, and env fields. The configs, certs, and files handlers
call authorize_request_context before invoking the read model.
For Java light-config-server, ServiceIdAuthorizationUtil extracts verified
claims from AUDIT_INFO and applies the same host and SID checks before
ConfigsGetHandler, CertsGetHandler, or FilesGetHandler calls the database
helper.
The focused implementation tests cover missing and mismatched host, missing
and mismatched sid, missing and mismatched env when envTag is requested,
blank values, whitespace trimming, and case-sensitive identifier comparison.
Non-Goals
- Do not replace JWT verification middleware.
- Do not redesign OAuth token issuance.
- Do not require
sidfor product-level requests that do not carryserviceId. - Do not require
envwhen the request omitsenvTag. - Do not trust request headers such as
X-Service-Idas a substitute for the JWT claim. - Do not use
subas a fallback for service-scoped controller registry or config-server authorization.
Token Contract
Trusted service tokens used for config-server startup access should include:
{
"host": "<host-id>",
"sid": "<service-id>",
"env": "<optional-environment>"
}
sid is the runtime service id that the token is allowed to bootstrap. For
example:
{
"sid": "com.networknt.ai.gateway-1.0.0"
}
sid must be treated as a reserved authorization claim. It should be generated
from trusted client configuration or a trusted token request path, not from
unvalidated caller input.
Request Contract
For service-scoped requests:
GET /config-server/configs?host=...&serviceId=com.networknt.ai.gateway-1.0.0&envTag=dev
GET /config-server/certs?host=...&serviceId=com.networknt.ai.gateway-1.0.0&envTag=dev
GET /config-server/files?host=...&serviceId=com.networknt.ai.gateway-1.0.0&envTag=dev
The authorization rule is:
token.host == request.host
token.sid == request.serviceId
The comparisons should trim surrounding whitespace but should otherwise be exact and case-sensitive. Host ids and service ids are identifiers, not display names.
For requests without serviceId, the SID rule is not applied:
GET /config-server/configs?host=...&productId=lg&productVersion=1.5.1&envTag=dev
Those requests should continue through the existing product-level behavior, but the host binding rule still applies:
token.host == request.host
For any request with a non-blank envTag, including product-level requests,
the environment binding rule also applies:
token.env == request.envTag
Recommended Design
Add a small config-server authorization helper in both implementations, and
tighten the controller registry validators to use the same sid binding rule.
The helper should accept the decoded JWT claims and the parsed query object, and return either:
- success when there is no service-scoped request or the
sidmatches - an authorization response when the request is service-scoped and invalid
Pseudo logic:
requestedHost = trim(query.host)
tokenHost = trim(claim.host)
if tokenHost is empty:
reject 403
if tokenHost != requestedHost:
reject 403
requestedServiceId = trim(query.serviceId)
if requestedServiceId is not empty:
tokenServiceId = trim(claim.sid)
if tokenServiceId is empty:
reject 403
if tokenServiceId != requestedServiceId:
reject 403
requestedEnvTag = trim(query.envTag)
if requestedEnvTag is not empty:
tokenEnv = trim(claim.env)
if tokenEnv is empty:
reject 403
if tokenEnv != requestedEnvTag:
reject 403
allow
Run this check before getSnapshotConfigs, getSnapshotCerts,
getSnapshotFiles, or any live config query helper.
For controller registry registration, serviceId is not optional and the
expected host is the controller’s configured hostId. The same comparisons
should run after signature, issuer, and audience validation and before any
runtime instance lookup or persistence. A valid sub with a missing sid must
still be rejected, and a token with no host must also be rejected.
Response Status
Use 403 Forbidden for SID or host-binding failures.
The JWT has already passed authentication. The failure is authorization: the token is valid but not allowed to access the requested host or service configuration or environment.
Suggested response body:
Token sid does not match requested serviceId
Token host does not match requested host
Token env does not match requested envTag
Avoid echoing the full token or all claims in the response. Logging the
requested host, token host, requested serviceId, and token sid at warn
level is useful for operations. When envTag is present, also log requested
envTag and token env.
Controller Implementation
Rust controller-rs
ServiceJwtVerifier::validate now makes service registration read only
claims.sid, trims it, rejects blank or missing values, and compares it with
ServiceRegistrationParams.service_id.
The same validation path requires claims.host, trims it, and compares
it with Settings.host_id. Do not fall back to claims.sub for registry
authorization.
When ServiceRegistrationParams.env_tag is present and non-blank, the same
validation path requires a non-blank claims.env and compares it with the
requested envTag.
The WebSocket registration tests cover:
- a token with
sidand nosubstill registers - a token with matching
subbut missingsidis rejected - a token with matching
subbut mismatchedsidis rejected - a token with missing or mismatched
hostis rejected - a request with
envTagand missing or mismatched tokenenvis rejected
Java light-controller
ServiceJwtValidator.validateServiceToken now requires sid when
MicroserviceEndpoint.register passes a requested serviceId, and compares it
with that serviceId.
The validator also requires host and compares it with
ControllerRuntimeConfig.hostId. Do not fall back to JwtClaims.getSubject()
for registry authorization.
When envTag is present and non-blank, the validator also requires env and
compares it with that envTag.
The registration test token builders now include sid and host for normal
service JWTs. Regression tests cover missing and mismatched sid, plus missing
and mismatched host, plus missing and mismatched env when envTag is
requested.
Rust Config-Server Implementation
Claims
internal-auth::Claims now exposes sid and host as explicit optional
fields:
#![allow(unused)]
fn main() {
pub sid: Option<String>,
pub host: Option<String>,
pub env: Option<String>,
}This keeps the authorization path readable and avoids treating sid and
host as generic extension claims. They are first-class authorization claims
for config-server and controller runtime access.
Handler Flow
Each handler uses claims rather than _claims:
#![allow(unused)]
fn main() {
async fn get_configs(
State(state): State<AppState>,
claims: Claims,
Query(query): Query<ConfigQuery>,
) -> Response {
if let Err(response) = authorize_request_context(
&claims,
&query.host,
query.service_id.as_deref(),
query.env_tag.as_deref(),
) {
return response;
}
...
}
}The shared helper is:
#![allow(unused)]
fn main() {
fn authorize_request_context(
claims: &Claims,
requested_host: &str,
requested_service_id: Option<&str>,
requested_env_tag: Option<&str>,
) -> Result<(), Response>
}Apply the helper to:
get_configs
get_certs
get_files
Rust Tests
The helper tests cover:
- allows a matching
sid - allows a matching
host - allows an absent
serviceId - rejects missing
host - rejects mismatched
host - rejects missing
sidwhenserviceIdis present - rejects mismatched
sid - allows absent
envTag - rejects missing
envwhenenvTagis present - rejects mismatched
env - trims surrounding whitespace
- preserves case-sensitive matching
If the handlers are tested directly, add endpoint-level regressions that prove
mismatched host or sid returns 403 before the read model is called.
Java Config-Server Implementation
Claims Source
The Light-4j JwtVerifyHandler places the verified claims in:
Map<String, Object> auditInfo =
exchange.getAttachment(AttachmentConstants.AUDIT_INFO);
JwtClaims claims =
(JwtClaims)auditInfo.get(Constants.SUBJECT_CLAIMS);
The shared helper in light-config-server is:
com.networknt.configserver.util.ServiceIdAuthorizationUtil
Implemented API:
public static String authorizeRequestContext(
HttpServerExchange exchange,
String requestedHost,
String requestedServiceId,
String requestedEnvTag
)
public static String authorizeRequestContext(
JwtClaims claims,
String requestedHost,
String requestedServiceId,
String requestedEnvTag
)
The exchange overload extracts verified claims from AUDIT_INFO. The claims
overload is used by focused unit tests. Both methods return null on success
or a short error message when the request must be rejected with 403.
Handler Flow
At the top of each handler, after reading query parameters and before calling the DB helper:
String authorizationError =
ServiceIdAuthorizationUtil.authorizeRequestContext(exchange, host, serviceId, envTag);
if (authorizationError != null) {
exchange.setStatusCode(StatusCodes.FORBIDDEN);
exchange.getResponseSender().send(authorizationError);
return;
}
Apply the helper to:
ConfigsGetHandler
CertsGetHandler
FilesGetHandler
Java Tests
Focused unit tests cover:
- allows matching
sid - allows matching
host - allows blank
serviceId - rejects missing claims when
hostis present - rejects missing
host - rejects mismatched
host - rejects missing claims when
serviceIdis present - rejects missing
sid - rejects mismatched
sid - allows blank
envTag - rejects missing
envwhenenvTagis present - rejects mismatched
env - trims surrounding whitespace
- remains case-sensitive
Handler-level coverage can be added later if the test harness can cheaply inject
AUDIT_INFO. The first implementation relies on focused helper tests plus the
existing handler request coverage.
Token Issuance Check
This change depends on runtime service tokens carrying sid for service-scoped
startup access and controller registry registration. Before deploying the
authorization check broadly, verify the Light OAuth token path used by runtime
services.
For long-lived or trusted client_credentials runtime tokens:
- token custom claims should include
host - token custom claims should include
sid - token custom claims may include
env, but must includeenvfor runtimes that call config-server or controller withenvTag
If a runtime cannot mint a token with host and sid, it should fail early
during token setup rather than be allowed to call config-server or register
with controller using a broader token.
Backward Compatibility
This is a security-tightening change. It can break clients that currently call
config-server with a serviceId or register with controller while using a
token that has no host or sid. It can also break clients that pass
envTag while using a token with no matching env.
Recommended rollout for deployments that do not already mint service tokens
with host and sid:
- Verify runtime token issuance includes
hostandsid. Verifyenvis included whenever the runtime sendsenvTag. - Enable the rule by default in Rust and Java, because config-server returns sensitive config and cert material and controller registry defines runtime service identity.
- For one release, monitor explicit warning logs on host or SID failures.
- Update local and enterprise runtime token setup docs so service tokens carry
hostandsid.
If a temporary compatibility switch is required, make it explicit and narrow:
enforceSidHostMatch: true
Do not silently ignore mismatches in production deployments.
Error Handling
Use 403 Forbidden for:
- missing
sidwith requestedserviceId - mismatched
sid - missing
hostwith requestedhostor controllerhostId - mismatched
host - missing
envwith requestedenvTag - mismatched
env - missing decoded claims in Java after the security chain has supposedly run
Use existing 401 Unauthorized behavior for:
- missing Authorization header
- invalid token signature
- invalid issuer or audience
- expired token
This keeps authentication failures separate from service authorization failures.
Observability
On rejection, log:
requestedServiceId
tokenSid
requestedHost
tokenHost
envTag
tokenEnv
endpoint
Do not log the full JWT.
The log should make the exact issue visible:
Token sid com.networknt.light-gateway-1.0.0 does not match requested serviceId com.networknt.ai.gateway-1.0.0
Token host 01964b05-552a-7c4b-9184-6857e7f3dc5f does not match requested host 01964b05-552a-7c4b-9184-6857e7f3dc5e
Token env dev does not match requested envTag prod
Validation Checklist
After implementation, validate these cases against Rust and Java config-server:
sid=A, serviceId=A => 200
sid=A, serviceId=B => 403
sid missing, serviceId=A => 403
host=H1, request host=H1 => 200
host=H1, request host=H2 => 403
host missing, request host=H1 => 403
sid=A, serviceId omitted, productId/productVersion supplied, host matches => existing behavior
env=dev, envTag=dev => 200
env=dev, envTag=prod => 403
env missing, envTag=dev => 403
env missing, envTag omitted => existing behavior
invalid JWT => 401
missing JWT => 401
Also verify the three endpoint families:
/config-server/configs
/config-server/certs
/config-server/files
Validate the same service identity cases against Rust and Java controller registry registration:
token sid=A, register serviceId=A => registered
token sid=A, register serviceId=B => registration rejected
token sid missing, register serviceId=A, token sub=A => registration rejected
token sid blank, register serviceId=A => registration rejected
token host=H1, controller hostId=H1 => registered
token host=H1, controller hostId=H2 => registration rejected
token host missing, controller hostId=H1 => registration rejected
token env=dev, register envTag=dev => registered
token env=dev, register envTag=prod => registration rejected
token env missing, register envTag=dev => registration rejected
token env missing, register envTag omitted => existing behavior
invalid JWT => registration rejected
Focused verification commands used during implementation:
cargo test -p config-server authorize_request_context
cargo test microservice_registration_rejects
cargo test microservice_registration_uses_jwt_env_when_request_omits_env_tag
mvn -q -Dtest=ControllerWebSocketIntegrationTest#rejectsMicroserviceJwtWhenHostClaimIsMissing+rejectsMicroserviceJwtWhenHostClaimDiffersFromControllerHostId+rejectsMicroserviceJwtWhenSidIsMissing+rejectsMicroserviceJwtWhenSidDiffersFromServiceId+rejectsMicroserviceJwtWhenEnvClaimIsMissingAndEnvTagIsRequested+rejectsMicroserviceJwtWhenEnvClaimDiffersFromEnvTag+registersMicroserviceWhenEnvTagAndEnvClaimAreOmitted test
mvn -q -Dtest=ServiceIdAuthorizationUtilTest test
Open Questions
No open questions for SID, host, and environment binding in this phase.
Instance File Config Phase
Overview
instance_file_t stores instance-specific files that are not modeled as standard config_property_t rows. Examples include API specifications such as openapi.yaml and custom certificates or supporting files.
The config snapshot model currently separates two kinds of file data:
- Standard files are flattened into
config_snapshot_property_t. - Non-standard instance files are copied into
snapshot_instance_file_t.
The /config-server/files endpoint must return both sets. It already filters standard files by config_phase through config_snapshot_property_t.config_phase, but instance_file_t and snapshot_instance_file_t do not currently carry config_phase. That makes it impossible to union the two sources while preserving runtime, deployment, and generator phase semantics.
Problem
When a service starts through DefaultConfigLoader, it calls /config-server/files with host, serviceId, and envTag. The endpoint resolves the current snapshot and returns the files that should be written into /config.
For the sidecar case, openapi.yaml exists in both instance_file_t and snapshot_instance_file_t, but it does not exist in config_snapshot_property_t. Since the current /files query reads only config_snapshot_property_t, the response does not include openapi.yaml, and the sidecar cannot write it to /config.
The correct endpoint behavior is:
- Read standard files from
config_snapshot_property_t. - Read non-standard files from
snapshot_instance_file_t. - Filter both sources by the requested config phase.
- Return one filename-to-base64-content map.
Decision
Add config_phase to both runtime and snapshot instance file tables:
instance_file_t.config_phasesnapshot_instance_file_t.config_phase
The allowed values should match config_t.config_phase:
G: generatorD: deploymentR: runtime
The default value for existing and new rows should be R, because current instance files are consumed by runtime startup unless explicitly marked otherwise.
Schema Changes
Runtime Table
ALTER TABLE instance_file_t
ADD COLUMN config_phase CHAR(1) NOT NULL DEFAULT 'R';
ALTER TABLE instance_file_t
ADD CHECK (config_phase IN ('G', 'D', 'R'));
ALTER TABLE instance_file_t
DROP CONSTRAINT IF EXISTS instance_file_uk;
ALTER TABLE instance_file_t
ADD CONSTRAINT instance_file_uk
UNIQUE (host_id, instance_id, config_phase, v_file_name);
The unique constraint must include config_phase so the same filename can exist separately for runtime and deployment if needed.
Snapshot Table
ALTER TABLE snapshot_instance_file_t
ADD COLUMN config_phase CHAR(1) NOT NULL DEFAULT 'R';
ALTER TABLE snapshot_instance_file_t
ADD CHECK (config_phase IN ('G', 'D', 'R'));
CREATE INDEX idx_snap_inst_file_phase
ON snapshot_instance_file_t (snapshot_id, config_phase, file_type, active);
The primary key can remain (snapshot_id, host_id, instance_file_id) because instance_file_id identifies the copied runtime row. The phase-aware index supports config-server lookups.
Migration
Existing rows should be backfilled to runtime:
UPDATE instance_file_t
SET config_phase = 'R'
WHERE config_phase IS NULL;
UPDATE snapshot_instance_file_t
SET config_phase = 'R'
WHERE config_phase IS NULL;
If a historical custom file was actually intended for deployment or generator use, it must be corrected explicitly after migration. There is no reliable way to infer that from the current schema.
Snapshot Creation
create_snapshot must copy config_phase from instance_file_t into snapshot_instance_file_t.
Current copy shape:
INSERT INTO snapshot_instance_file_t (
snapshot_id, host_id, instance_file_id, instance_id, file_type,
file_name, file_value, file_desc, expiration_ts,
aggregate_version, active, update_user, update_ts
)
SELECT
p_snapshot_id, t.host_id, t.instance_file_id, t.instance_id, t.file_type,
t.file_name, t.file_value, t.file_desc, t.expiration_ts,
t.aggregate_version, t.active, t.update_user, t.update_ts
FROM instance_file_t t
WHERE t.host_id = p_host_id
AND t.instance_id = p_instance_id
AND t.active = TRUE;
Target copy shape:
INSERT INTO snapshot_instance_file_t (
snapshot_id, host_id, instance_file_id, instance_id, config_phase,
file_type, file_name, file_value, file_desc, expiration_ts,
aggregate_version, active, update_user, update_ts
)
SELECT
p_snapshot_id, t.host_id, t.instance_file_id, t.instance_id, t.config_phase,
t.file_type, t.file_name, t.file_value, t.file_desc, t.expiration_ts,
t.aggregate_version, t.active, t.update_user, t.update_ts
FROM instance_file_t t
WHERE t.host_id = p_host_id
AND t.instance_id = p_instance_id
AND t.active = TRUE;
Snapshot creation should continue copying all active instance files for the instance. Consumers filter by phase when reading.
Config Server Query
The /files endpoint should union standard files and non-standard instance files for the current snapshot.
Standard files:
SELECT
p.source_level AS source,
c.config_name,
p.property_name,
p.value_type,
p.property_value,
10 AS source_rank
FROM config_snapshot_property_t p
JOIN config_snapshot_t cs ON cs.snapshot_id = p.snapshot_id
JOIN config_t c ON c.config_id = p.config_id
JOIN host_t h ON cs.host_id = h.host_id
WHERE h.sub_domain || '.' || h.domain = ?
AND cs.current = TRUE
AND p.config_phase = ?
AND p.property_type = 'File'
AND cs.service_id = ?
AND cs.environment = ?
Non-standard instance files:
SELECT
'instance_file' AS source,
'files' AS config_name,
f.file_name AS property_name,
'string' AS value_type,
f.file_value AS property_value,
100 AS source_rank
FROM snapshot_instance_file_t f
JOIN config_snapshot_t cs
ON cs.snapshot_id = f.snapshot_id
AND cs.host_id = f.host_id
AND cs.instance_id = f.instance_id
JOIN host_t h ON h.host_id = cs.host_id
WHERE h.sub_domain || '.' || h.domain = ?
AND cs.current = TRUE
AND f.config_phase = ?
AND f.file_type = 'File'
AND f.active = TRUE
AND cs.service_id = ?
AND cs.environment = ?
The implementation can combine these with UNION ALL. If the same filename appears in both sources, the instance file should win because it is the instance-specific override. Java can enforce this by inserting standard rows first and custom rows second into the response map. SQL can enforce it with source_rank and DISTINCT ON (property_name) if the response is assembled directly from a result set.
The same model should be applied to /certs with property_type = 'Cert' and file_type = 'Cert', because instance_file_t.file_type already supports certificates.
API and Event Changes
All create, update, query, and replay paths for instance files should include configPhase.
Required behavior:
- New create/update requests accept
configPhase. - Missing
configPhasedefaults toRfor backward compatibility. - Created and updated events include
configPhase. - Replay of historical events defaults missing
configPhasetoR. - Query responses expose
configPhase. - UI forms and grids allow the operator to choose or filter by phase.
Code Impact
Expected implementation surfaces:
portal-db/postgres/ddl.sqlportal-db/postgres/ddl-dbvis.sql- New
portal-db/postgres/patch_*.sql portal-db/postgres/sp_tr_fn.sqllight-portal/db-providerpersistence for create, update, query, snapshot, clone, and replay flowslight-config-serversnapshot/filesand/certsquery behavior throughConfigServerQueryPersistenceImplportal-service/crates/portal-coresnapshot file and cert queriesportal-service/apps/config-serverresponse assembly if duplicate precedence is handled outside SQLportal-viewschemas/forms/pages for instance files
Validation
Minimum checks:
- Create or migrate an instance file named
openapi.yamlwithconfig_phase = 'R'. - Create a snapshot for the instance.
- Verify
snapshot_instance_file_thas the sameconfig_phase. - Call
/config-server/files?host=dev.lightapi.net&serviceId=...&envTag=dev. - Confirm the response contains both standard files such as
logback.xmland non-standard files such asopenapi.yaml. - Start a sidecar with
DefaultConfigLoaderand confirm/config/openapi.yamlis written.
Regression tests should cover:
- Existing instance files default to runtime.
- Same filename can exist in different phases.
/filesfilters out non-matching phases.- Custom instance files override standard files with the same filename.
- Java and Rust config-server implementations return the same file keys.
Out of Scope
This change does not move non-standard files into config_snapshot_property_t. Keeping them in snapshot_instance_file_t preserves the distinction between modeled config properties and instance-specific file artifacts.
Deployment
Deployment service allows users to deploy and manage their configured light products. This service is used by the application and api developers and operations.
The deployment service contains pipeline management, platform management and deployment management. It also integrates with product management and instance management services.
Light Portal Install
Purpose
light-portal-install provides a one-command local installation path for Light Portal. The target user should only need Docker Compose on the host machine and should not need to clone the individual service repositories, build Java or Rust projects, install Node.js, or manually copy static assets.
The intended entrypoint is:
curl -sL https://raw.githubusercontent.com/networknt/light-portal-install/main/install.sh | bash
The installer downloads the install bundle, prepares the local data directory, writes the selected image and asset versions, and starts the stack with Docker Compose.
Recommendation
This approach should work if the repo owns the local installation contract instead of acting as a thin pointer to the current developer checkout.
The install repo contains:
install.sh, the idempotent installer and updater.docker-compose.yml, the default local stack using the Rust services fromall-in-lt..env.example, the documented image tags, ports, and optional secrets.VERSION, the default portal bundle version.- fixed R2 archive names for
hybrid-command,hybrid-query,lightapi, andsigninassets. README.md, the short public usage guide.
The repo should not require the user to clone portal-config-loc, service-asset, portal-view, login-view, or any service source repository. Those repos remain build and release inputs. light-portal-install consumes released images and released asset bundles.
Runtime Shape
The first version should be a Rust-only all-in-lt stack:
postgresconfig-serverlight-oauthcontrollerportal-servicehybrid-commandhybrid-querylight-workflowlight-gatewaylight-agent- demo customer profile API
- demo offer decision API
The Compose service names should stay compatible with the current local stack names: controller, config-server, light-oauth, portal-service, light-gateway, hybrid-command, and hybrid-query. Internal URLs and existing bootstrap data already depend on those names.
light-agent and the demo APIs are part of the default local stack, not optional add-ons, because the install repo is meant to support a complete local demo. The Compose file should include an AI agent service based on the released networknt/light-agent image and wire it to PostgreSQL, controller, config-server, hybrid-query, and light-gateway the same way the current all-in-lt Rust profile does.
The default host entrypoint should be the gateway:
https://localhost
If binding to host port 443 fails, the installer should fall back to a documented high port such as 8443 and write the chosen value to .env.
Compose Design
docker-compose.yml should be self-contained for a released local install. It can preserve the current all-in-lt service topology, but it should not require local source-tree mounts for application jars, Rust config folders, SPA dist folders, or seed SQL unless the installer downloads them first.
The Compose file should use image variables with released defaults:
services:
config-server:
image: ${CONFIG_SERVER_IMAGE:-networknt/config-server:2.3.5}
light-oauth:
image: ${LIGHT_OAUTH_IMAGE:-networknt/light-oauth:2.3.5}
controller:
image: ${CONTROLLER_RS_IMAGE:-networknt/controller-rs:2.3.5}
portal-service:
image: ${PORTAL_SERVICE_IMAGE:-networknt/portal-service:2.3.5}
light-gateway:
image: ${LIGHT_GATEWAY_IMAGE:-networknt/light-gateway:2.3.5}
light-agent:
image: ${LIGHT_AGENT_IMAGE:-networknt/light-agent:2.3.5}
demo-customer-profile-api:
image: ${DEMO_CUSTOMER_PROFILE_API_IMAGE:-networknt/demo-customer-profile-api:2.3.5}
demo-offer-decision-api:
image: ${DEMO_OFFER_DECISION_API_IMAGE:-networknt/demo-offer-decision-api:2.3.5}
The image list is generated by release-docker-images.sh. With --upload-r2, the script uploads docker-images.env to:
light-portal/releases/<tag>/docker-images.env
light-portal/releases/latest/docker-images.env
docker-images.env
For public installs, install.sh downloads docker-images.env for the selected LIGHT_PORTAL_VERSION and runs Compose with both the downloaded image env file and the local .env overrides:
docker compose --env-file docker-images.env --env-file .env up -d
The Compose file should keep persistent state in named volumes by default:
postgres-datafor PostgreSQL.portal-datafor user-uploaded or generated portal data.
The installer may support a --dev-bind-mounts option later, but the default public path should prefer downloaded, immutable release assets over bind mounts to a developer workspace.
Local Authentication
The local install should use the same OAuth authorization code flow through login-view that is used by the current portal-config-loc/all-in-lt and portal-config-dev deployments. The gateway serves both the portal UI and the sign-in UI, and light-oauth remains the local authorization server.
To keep the first public local install simple, the bundle should continue using the existing long-lived local demo tokens already used by the current local stack. Token generation can be revisited later, but it should not block the initial installer.
Installer Flow
install.sh should be idempotent and safe to rerun.
- Detect
docker compose. - Resolve the requested version. Default to the repo
VERSION; allowLIGHT_PORTAL_VERSION=.... - Create an install directory, defaulting to
$HOME/.light-portal. - Download
docker-images.envfromlight-portal/releases/<version>/docker-images.env. - Download
hybrid-command.zip,hybrid-query.zip,lightapi.zip,signin.zip, andevents.zipfrom R2. - Use the checked-in bootstrap config, seed SQL, certificates, and Compose file.
- Preserve existing
.envvalues when updating. - Start the stack with
docker compose up -d. - Wait for health checks and print the portal URL.
The script should provide explicit subcommands:
install.sh install
install.sh update
install.sh start
install.sh stop
install.sh status
install.sh logs
install.sh uninstall
uninstall should ask for confirmation before deleting volumes or $HOME/.light-portal.
Static Asset Distribution
The current service-asset GitHub repository is useful as a build artifact repository for developers, but it is not ideal as the long-term public CDN for local installers. Released static content and install scripts should move to Cloudflare R2 as the long-term artifact channel, with fixed archive objects, checksums, and rollback.
update-asset.sh --upload-r2 currently uploads refreshed service assets to bucket lightapi. Directory assets are compressed before upload. The default object paths are:
hybrid-command.zip
hybrid-query.zip
lightapi.zip
signin.zip
events.zip
release-docker-images.sh --upload-r2 uploads the image env file under:
light-portal/releases/<tag>/docker-images.env
light-portal/releases/latest/docker-images.env
docker-images.env
daily-release.sh is the top-level release entrypoint. It calls update-asset.sh --upload-r2 first, then runs the dev copy steps, then calls release-docker-images.sh --upload-r2.
The install repo should treat R2 as an artifact origin, not as the source of truth. Source of truth remains the service and UI repos plus the release pipeline. The release pipeline publishes immutable versioned objects to R2.
Once the static bundles, scripts, generated manifests, and release asset publishing are fully moved to R2, the service-asset repository can be removed. During migration, it can remain as a staging or compatibility source until the install pipeline no longer depends on it.
Current object layout:
hybrid-command.zip
hybrid-query.zip
lightapi.zip
signin.zip
events.zip
docker-images.env
light-portal/releases/
<tag>/
docker-images.env
latest/
docker-images.env
The installer can default to latest for daily local demo installs, while still allowing LIGHT_PORTAL_VERSION=<tag> for reproducible installs.
Because the installer should not depend on AWS CLI access, it cannot use aws s3 ls to discover R2 objects. It downloads the known compressed archives directly with curl and unpacks them with unzip into the Docker Compose bind-mount directories.
R2 Tradeoffs
R2 is attractive because it supports S3-compatible tooling, public buckets, custom domains, caching through Cloudflare, and no R2 egress bandwidth charges. Cloudflare documents Standard storage pricing, request-class pricing, a free tier, and free egress for R2. Cloudflare also documents that public buckets can be exposed through custom domains for production use, while r2.dev public URLs are intended for non-production traffic.
The main tradeoff is that heavy asset reads still have request-operation cost. The current implementation publishes five compressed archives for hybrid-command, hybrid-query, lightapi, signin, and events.json, plus docker-images.env, to keep install downloads coarse-grained.
For production-quality public distribution, use a custom domain such as:
https://assets.lightapi.net/light-portal/releases/2.3.5/manifest.json
Do not use an r2.dev URL as the documented installer default.
Release Pipeline
The current release pipeline produces one installable daily version with these steps:
daily-release.shcallsupdate-asset.sh --upload-r2.update-asset.shrebuilds/copiesportal-view,login-view, hybrid service jars, andevents.json.update-asset.shreplaces the configured R2 asset prefixes in bucketlightapi.daily-release.shrunscopy-service-dev.shandcopy-site-dev.shfor dev.daily-release.shcallsrelease-docker-images.sh --upload-r2.release-docker-images.shbuilds/pushes the selected image profile and writesdocker-images.env.release-docker-images.shuploadsdocker-images.envto the versioned,latest, and compatibility R2 paths.
The next release-pipeline improvement should generate and upload:
- checksums for each archive and metadata file
- an install smoke-test result
The smoke test should run from an empty install directory and verify:
- Docker Compose starts all required services.
- PostgreSQL bootstrap completes.
- gateway is reachable.
- sign-in and portal static assets load through gateway.
- health checks pass for the Rust services.
Settled Decisions
- Include
light-agentin the defaultdocker-compose.ymlas the AI agent service for local demos. - Include the demo customer profile and offer decision APIs in the default local stack.
- Use the local OAuth authorization code flow with
login-view, matchingportal-config-loc/all-in-ltandportal-config-dev. - Use the existing long-lived local demo tokens in the first version to keep the installer simple.
- Move static content, install scripts, generated manifests, and release bundles to Cloudflare R2 for long-term flexibility.
- Remove the
service-assetrepository after the R2-based release pipeline fully replaces it. - Keep Docker Compose as the only container runtime dependency; use
curlfor R2 downloads, not AWS CLI. - Use fixed archive names for the current R2 object set until the release pipeline publishes a richer manifest automatically.
Decision
Create light-portal-install as the public local install repo with Docker Compose as the only container runtime dependency. Use the Rust all-in-lt service topology, including light-agent and the demo APIs, but package it as checked-in runtime config plus R2-downloaded service jars, SPA assets, events.json, and docker-images.env. Keep the local OAuth authorization code flow through login-view and use existing long-lived local demo tokens for the first version. Move static install artifacts from GitHub repo distribution to Cloudflare R2 behind a custom domain, download the fixed asset archives with curl, extract them with unzip, and remove service-asset after the R2 pipeline fully replaces it.
Timestamp
Okay, let’s break down the best way to persist Java’s OffsetDateTime in PostgreSQL.
1. Best Database Column Type: TIMESTAMP WITH TIME ZONE (or TIMESTAMPTZ)
This is unequivocally the best choice in PostgreSQL for storing OffsetDateTime objects. Here’s why:
- Preserves the Instant:
OffsetDateTimerepresents a specific instant in time with an offset from UTC.TIMESTAMPTZis designed precisely for this. - UTC Normalization: When you insert a value into a
TIMESTAMPTZcolumn, PostgreSQL uses the provided offset to normalize the timestamp and stores it internally as UTC. This is crucial for correctly representing the absolute point in time, regardless of the original offset. - Automatic Conversion on Retrieval: When you select data from a
TIMESTAMPTZcolumn, PostgreSQL automatically converts the stored UTC value back to the current session’s timezone setting (TimeZoneparameter). Your JDBC driver then maps this appropriately. - Avoids Ambiguity: Using
TIMESTAMPTZprevents the ambiguity that can arise withTIMESTAMP WITHOUT TIME ZONE, where the lack of offset/timezone information can lead to incorrect interpretations depending on server and client settings.
Why NOT TIMESTAMP WITHOUT TIME ZONE (or TIMESTAMP)?
- This type stores the date and time literally as provided, discarding any timezone or offset information.
- If you store an
OffsetDateTime’s local date/time part into this column, you lose the offset, making it impossible to know the exact instant it represents globally. This is generally incorrect forOffsetDateTime.
2. How to Convert (JDBC)
Modern JDBC drivers (PostgreSQL JDBC driver versions supporting JDBC 4.2+, which is most versions used today) handle the conversion automatically and correctly when you use the appropriate methods.
Persisting (Saving):
- Use
PreparedStatement.setObject(int parameterIndex, OffsetDateTime value)
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.time.OffsetDateTime;
import java.time.ZoneOffset;
// Assume 'conn' is your established JDBC Connection
public void saveEventTime(Connection conn, int eventId, OffsetDateTime eventTime) throws SQLException {
// Use TIMESTAMPTZ in your table definition
String sql = "UPDATE events SET event_timestamp = ? WHERE id = ?";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
// Use setObject for OffsetDateTime - the driver handles conversion
pstmt.setObject(1, eventTime); // Pass the OffsetDateTime directly
pstmt.setInt(2, eventId);
pstmt.executeUpdate();
}
}
// Example Usage:
// OffsetDateTime nowWithOffset = OffsetDateTime.now(); // Uses system default offset
// OffsetDateTime specificTime = OffsetDateTime.of(2023, 10, 27, 10, 30, 0, 0, ZoneOffset.ofHours(-4));
// saveEventTime(connection, 1, specificTime);
The JDBC driver sends the OffsetDateTime (including its offset) to PostgreSQL. PostgreSQL’s TIMESTAMPTZ type normalizes this to UTC for storage.
Retrieving (Loading):
- Use
ResultSet.getObject(int columnIndex, OffsetDateTime.class)orResultSet.getObject(String columnLabel, OffsetDateTime.class)
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.time.OffsetDateTime;
public OffsetDateTime loadEventTime(Connection conn, int eventId) throws SQLException {
String sql = "SELECT event_timestamp FROM events WHERE id = ?";
OffsetDateTime eventTime = null;
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, eventId);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
// Use getObject with the target class - the driver handles conversion
eventTime = rs.getObject("event_timestamp", OffsetDateTime.class);
}
}
}
return eventTime;
}
// Example Usage:
// OffsetDateTime retrievedTime = loadEventTime(connection, 1);
// if (retrievedTime != null) {
// System.out.println("Retrieved: " + retrievedTime);
// // Note: The offset might be different from the original if your
// // JVM's default timezone or JDBC connection timezone differs
// // from the original offset, but it represents the SAME instant in time.
// }
When retrieving, PostgreSQL sends the stored UTC timestamp. The JDBC driver, knowing the target type is OffsetDateTime and considering the session’s timezone setting, converts the UTC value back into an appropriate OffsetDateTime object representing the correct instant.
Summary:
- Database Column: Use
TIMESTAMP WITH TIME ZONE(TIMESTAMPTZ). - Persisting (Java -> DB): Use
PreparedStatement.setObject(index, yourOffsetDateTime). - Retrieving (DB -> Java): Use
ResultSet.getObject(column, OffsetDateTime.class). - JDBC Driver: Ensure you are using a modern PostgreSQL JDBC driver that supports JDBC 4.2 / Java 8 Time API.
- Session Timezone: Be aware that the
OffsetDateTimeretrieved might have an offset corresponding to the client/session’s timezone setting, but it will represent the same exact instant as the one stored (because it was normalized to UTC).
Tag
Let’s design a tagging system for your light-portal entities. Tags are typically non-hierarchical keywords or labels that you can assign to entities for flexible organization and discovery, complementing categories.
1. Database Design (PostgreSQL)
For a flexible and efficient tagging system, we’ll use two main tables: a central tags table and a join table entity_tags to create a many-to-many relationship between entities and tags.
a) tag Table:
Stores the definitions of the tags themselves.
CREATE TABLE tag_t (
tag_id VARCHAR(22) NOT NULL, -- Unique ID for the tag
host_id VARCHAR(22), -- null means global tag
tag_name VARCHAR(100) UNIQUE NOT NULL, -- Tag name (e.g., "featured", "urgent", "api", "documentation") - Enforce uniqueness
tag_desc VARCHAR(1024), -- Optional description of the tag
update_user VARCHAR(255) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY (tag_id)
);
-- Index for efficient lookup by tag_name (common search/filter)
CREATE INDEX idx_tags_tag_name ON tags_t (tag_name);
tag_id: Unique identifier for each tag.tag_name: The actual tag value (e.g., “featured”).UNIQUE NOT NULLconstraint ensures tag names are unique across the system (global tags in this design).tag_desc: Optional description for the tag.update_user,update_ts: Standard audit columns.UNIQUE (tag_name): Important constraint to ensure tag names are unique. This makes tag management simpler and consistent.
b) entity_tags_t Join Table (Many-to-Many Relationship):
Links entities to tags.
CREATE TABLE entity_tags_t (
entity_id VARCHAR(22) NOT NULL, -- ID of the entity (schema, product, document, etc.)
entity_type VARCHAR(50) NOT NULL, -- Type of the entity ('schema', 'product', 'document', etc.)
tag_id VARCHAR(22) NOT NULL REFERENCES tags_t(tag_id) ON DELETE CASCADE, -- Foreign key to tags_t
PRIMARY KEY (entity_id, entity_type, tag_id) -- Composite primary key to prevent duplicate tag assignments to the same entity
);
-- Indexes for efficient queries
CREATE INDEX idx_entity_tags_tag_id ON entity_tags_t (tag_id); -- Find entities by tag
CREATE INDEX idx_entity_tags_entity ON entity_tags_t (entity_id, entity_type); -- Find tags for an entity
entity_id: ID of the entity being tagged.entity_type: Type of the entity (must match the types you use for categories and other entity-related tables).tag_id: Foreign key referencing thetags_ttable.- Composite Primary Key (
entity_id,entity_type,tag_id): Ensures that an entity of a specific type cannot be associated with the same tag multiple times. ON DELETE CASCADE: If a tag is deleted fromtags_t, all associations inentity_tags_tare automatically removed. ConsiderON DELETE RESTRICTif you want to prevent tag deletion if it’s still in use.
2. Service Endpoints
You’ll need service endpoints to manage tags themselves and to manage the associations between tags and entities.
a) Tag Management Endpoints (Likely in a TagService or Admin-Specific Service):
- POST /tags - Create a new tag
- Request Body (JSON):
{ "tagId": "uniqueTagId123", // Optional - let backend generate if not provided "tagName": "featured", // Required - unique tag name "tagDesc": "Items that are highlighted or promoted" // Optional } - Response: 201 Created, with Location header (URL of the new tag) and response body (created tag JSON).
- Request Body (JSON):
- GET /tags - List all tags (with pagination, filtering, sorting - similar to
getCategoryendpoint)- Query Parameters:
offset,limit,tagName,tagDesc, etc. - Response: 200 OK, JSON array of tag objects (with
totalcount).
- Query Parameters:
- GET /tags/{tagId} - Get a specific tag by ID
- Path Parameter:
tagId - Response: 200 OK, tag object in JSON. 404 Not Found if not exists.
- Path Parameter:
- PUT /tags/{tagId} - Update an existing tag
- Path Parameter:
tagId - Request Body (JSON): (Same structure as POST, but
tagIdin the path is used for identification) - Response: 200 OK, updated tag object in JSON. 404 Not Found if tag not found.
- Path Parameter:
- DELETE /tags/{tagId} - Delete a tag
- Path Parameter:
tagId - Response: 204 No Content. 404 Not Found if tag not found.
- Path Parameter:
b) Entity Tag Association Endpoints (Likely within Entity-Specific Services like SchemaService, ProductService):
- (Within POST /schemas, PUT /schemas/{schemaId}, etc. entity creation/update endpoints):
- Request Body for creating or updating an entity should include a field (e.g.,
tagIds:["tagId1", "tagId2"]) to specify the tags to associate with the entity. - Service logic (like in the updated
createSchemaandupdateSchemamethods) will handle updating theentity_tags_ttable (deleting old links and inserting new ones) within the same transaction as the entity creation/update.
- Request Body for creating or updating an entity should include a field (e.g.,
- GET /schemas/{schemaId}/tags (or
/products/{productId}/tags, etc.) - Get tags associated with a specific entity- Path Parameter:
schemaId(orproductId, etc.) - Response: 200 OK, JSON array of tag objects associated with the entity.
- Path Parameter:
- PUT /schemas/{schemaId}/tags (or similar) - Replace tags associated with an entity (Less common, often handled within the entity update endpoint directly)
- Path Parameter:
schemaId - Request Body (JSON):
{ "tagIds": ["tagIdA", "tagIdB"] }- list of tag IDs to associate. - Response: 200 OK, updated entity object (or just 204 No Content).
- Path Parameter:
c) Entity Filtering/Search Endpoints:
- GET /schemas (or
/products,/documents, etc.) - List entities, now with tag filtering:- Query Parameter:
tagNames(ortagIds, ortags- choose one and be consistent), e.g.,tagNames=featured,api&tagNames=urgent(multiple tags to filter by). - Backend logic: Modify the
getSchema(orgetProduct,getDocument, etc.) service methods to:- Parse the
tagNamesparameter (could be comma-separated, multiple parameters, etc.). - Modify the SQL query to include a
JOINwithentity_tags_tandtags_tand add aWHEREclause to filter by the provided tag names. You might need to useEXISTSorINsubqueries for efficient filtering by multiple tags.
- Parse the
- Query Parameter:
Example Query for Filtering Schemas by Tags (using PostgreSQL EXISTS):
SELECT schema_t.*, ... -- Select schema columns
FROM schema_t
WHERE EXISTS (
SELECT 1
FROM entity_tags_t et
INNER JOIN tags_t t ON et.tag_id = t.tag_id
WHERE et.entity_id = schema_t.schema_id
AND et.entity_type = 'schema'
AND t.tag_name IN (?, ?, ?) -- Parameterized tag names list
);
UI Considerations:
- Tag Management UI: Similar to category management, likely an admin section to create, edit, delete tags.
- Tag Assignment UI:
- Entity creation/edit forms should include a tag selection component (e.g., tag input with autocomplete, checkboxes, tag pills).
- Allow users to search/browse existing tags and assign them.
- Tag Filtering/Browsing UI:
- Display tags prominently (tag cloud, list, filters).
- Clicking/selecting a tag should filter the entity lists to show only entities associated with that tag.
Benefits of this Tagging System:
- Flexible Organization: Tags are free-form and non-hierarchical, allowing for more flexible and ad-hoc categorization than categories alone.
- Discoverability: Improves search and filtering capabilities, making it easier for users to find relevant entities.
- Metadata Enrichment: Tags add valuable metadata to entities.
- Scalability: The database design is efficient for querying and managing tags and associations even with a large number of entities and tags.
This design provides a solid foundation for a tagging system. You can further refine it based on your specific requirements, such as adding tag groups, permissions for tag management, or more advanced search capabilities.
UUID
In the light-portal database, we are using UUID for most of the keys in order to support event replay between multiple environments. To balance database performance with the need for URL-friendly, we are using the PostgreSQL native UUID type for the key.
CREATE TABLE your_table (
id UUID PRIMARY KEY,
-- other columns
);
The PostgreSQL can only generate UUIDv4 and it causes index locality problem. So we are using Java to generate UUIDv7 which is Time-Ordered UUID. These embed a timestamp, making them roughly sequential and significantly improving index locality and insert performance. You’ll need a library for this.
import com.github.f4b6a3.uuid.UuidCreator;
import java.util.UUID;
// In your entity or service
UUID primaryKey = UuidCreator.getTimeOrderedEpoch(); // UUIDv7
// Store this 'primaryKey' directly.
In light-4j utility module, we have a UuidUtil class that can generate the UUIDv7 and also encode/decode to base64 string.
Here is the class.
package com.networknt.utility;
import com.github.f4b6a3.uuid.UuidCreator;
import java.util.Base64;
import java.util.UUID;
import java.nio.ByteBuffer;
public class UuidUtil {
// Use Java 8's built-in Base64 encoder/decoder
private static final Base64.Encoder URL_SAFE_ENCODER = Base64.getUrlEncoder().withoutPadding();
private static final Base64.Decoder URL_SAFE_DECODER = Base64.getUrlDecoder();
public static UUID getUUID() {
return UuidCreator.getTimeOrderedEpoch(); // UUIDv7
}
/**
* Generate a UUID and encode it to a URL-safe Base64 string.
*
* @return A URL-safe Base64 encoded UUID string.
*/
public static String uuidToBase64(UUID uuid) {
ByteBuffer bb = ByteBuffer.wrap(new byte[16]);
bb.putLong(uuid.getMostSignificantBits());
bb.putLong(uuid.getLeastSignificantBits());
return URL_SAFE_ENCODER.encodeToString(bb.array());
}
/**
* Decode a URL-safe Base64 string back to a UUID.
*
* @param base64 A URL-safe Base64 encoded UUID string.
* @return The decoded UUID.
*/
public static UUID base64ToUuid(String base64) {
byte[] bytes = URL_SAFE_DECODER.decode(base64);
ByteBuffer bb = ByteBuffer.wrap(bytes);
long high = bb.getLong();
long low = bb.getLong();
return new UUID(high, low);
}
}
Composit key vs Surrogate UUID key
Composite key with 5 or more columns
User the following three tables as examples. We have composite key with 5 columns and some of them are varchar types in product version_property_t table. Is is a good idea to create UUID keys for config_property_t and product_version_t?
-- each config file will have a config_id reference and this table contains all the properties including default.
CREATE TABLE config_property_t (
config_id UUID NOT NULL,
property_name VARCHAR(64) NOT NULL,
property_type VARCHAR(32) DEFAULT 'Config' NOT NULL,
light4j_version VARCHAR(12), -- only newly introduced property has a version.
display_order INTEGER,
required BOOLEAN DEFAULT false NOT NULL,
property_desc VARCHAR(4096),
property_value TEXT,
value_type VARCHAR(32),
property_file TEXT,
resource_type VARCHAR(30) DEFAULT 'none',
update_user VARCHAR(255) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL
);
ALTER TABLE config_property_t
ADD CHECK ( property_type IN ( 'Cert', 'Config', 'File') );
COMMENT ON COLUMN config_property_t.property_value IS
'Property Default Value';
COMMENT ON COLUMN config_property_t.value_type IS
'One of string, boolean, integer, float, map, list';
COMMENT ON COLUMN config_property_t.resource_type IS
'One of none, api, app, app_api, api|app_api, app|app_api, all';
ALTER TABLE config_property_t ADD CONSTRAINT config_property_pk PRIMARY KEY ( config_id, property_name );
CREATE TABLE product_version_t (
host_id UUID NOT NULL,
product_id VARCHAR(8) NOT NULL,
product_version VARCHAR(12) NOT NULL, -- internal product version
light4j_version VARCHAR(12) NOT NULL, -- open source release version
break_code BOOLEAN DEFAULT false, -- breaking code change to upgrade to this version.
break_config BOOLEAN DEFAULT false, -- config server need this to decide if clone is allowed for this version.
release_note TEXT,
version_desc VARCHAR(1024),
release_type VARCHAR(24) NOT NULL, -- Alpha Version, Beta Version, Release Candidate, General Availability, Production Release
current BOOLEAN DEFAULT false,
version_status VARCHAR(16) NOT NULL,
update_user VARCHAR (255) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY(host_id, product_id, product_version)
);
-- customized property for product version within the host.
CREATE TABLE product_version_property_t (
host_id UUID NOT NULL,
product_id VARCHAR(8) NOT NULL,
product_version VARCHAR(12) NOT NULL,
config_id UUID NOT NULL,
property_name VARCHAR(64) NOT NULL,
property_value TEXT,
property_file TEXT,
update_user VARCHAR (126) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL
);
ALTER TABLE product_version_property_t
ADD CONSTRAINT product_version_property_pk PRIMARY KEY ( host_id,
product_id,
product_version,
config_id,
property_name);
Replacing the wide, multi-column composite primary key in product_version_property_t with one based on surrogate UUID keys from the parent tables is generally a very good idea for several reasons, primarily related to performance and maintainability.
Let’s break down the pros and cons:
Current Situation (Composite Keys):
config_property_tPK: (config_idUUID,property_nameVARCHAR(64)) - Size: 16 + (up to 64 + overhead) bytes. Reasonably sized.product_version_tPK: (host_idUUID,product_idVARCHAR(8),product_versionVARCHAR(12)) - Size: 16 + (8 + overhead) + (12 + overhead) bytes. Getting wider.product_version_property_tPK: (host_idUUID,product_idVARCHAR(8),product_versionVARCHAR(12),config_idUUID,property_nameVARCHAR(64)) - Size: 16 + (8+oh) + (12+oh) + 16 + (64+oh) bytes. This is quite wide.
Problems with the Wide Composite Key in product_version_property_t:
- Large Primary Key Index: The B-tree index for this 5-column PK will be large. Larger indexes consume more disk space, more memory (reducing cache efficiency), and take longer to scan during queries, updates, and deletes.
- Large Foreign Keys (Implicit): If any other table were to reference
product_version_property_t(unlikely given its nature, but possible), the foreign key would also need all 5 columns. - Larger Secondary Indexes: Any other indexes you create on
product_version_property_twill typically include the primary key columns implicitly (in PostgreSQL leaf nodes). A wide PK bloats all other indexes on the table, magnifying the performance impact. - Update Overhead: Updating any of the PK columns (though generally discouraged) is very expensive. More importantly, index maintenance during INSERTs and DELETEs is heavier with wider keys.
- Join Complexity: Joining on 5 columns is syntactically more verbose.
Proposed Solution (Surrogate UUID Keys):
-
Add Surrogate Key to
config_property_t:- Add a new column:
cp_id UUID PRIMARY KEY DEFAULT gen_random_uuid()(or use UUIDv7 generator). - Add a
UNIQUEconstraint on the original natural key:ALTER TABLE config_property_t ADD CONSTRAINT config_property_nat_key UNIQUE (config_id, property_name);(This is CRITICAL to maintain data integrity). - Size of new PK: 16 bytes.
- Add a new column:
-
Add Surrogate Key to
product_version_t:- Add a new column:
pv_id UUID PRIMARY KEY DEFAULT gen_random_uuid()(or UUIDv7). - Add a
UNIQUEconstraint on the original natural key:ALTER TABLE product_version_t ADD CONSTRAINT product_version_nat_key UNIQUE (host_id, product_id, product_version);(CRITICAL). - Size of new PK: 16 bytes.
- Add a new column:
-
Modify
product_version_property_t:- Remove the existing 5-column PK.
- Replace the 5 individual columns used for the PK/FK relationship with two new columns:
pv_id UUIDandcp_id UUID. - Create the new Primary Key:
ALTER TABLE product_version_property_t ADD CONSTRAINT product_version_property_pk PRIMARY KEY (pv_id, cp_id); - Add Foreign Key constraints:
ALTER TABLE product_version_property_t ADD CONSTRAINT product_version_property_fk_pv FOREIGN KEY (pv_id) REFERENCES product_version_t(pv_id) ON DELETE CASCADE; -- Or appropriate action ALTER TABLE product_version_property_t ADD CONSTRAINT product_version_property_fk_cp FOREIGN KEY (cp_id) REFERENCES config_property_t(cp_id) ON DELETE CASCADE; -- Or appropriate action - Size of new PK: 16 + 16 = 32 bytes.
Advantages of the Proposed Solution:
- Significantly Smaller PK Index: The PK index on
product_version_property_tshrinks from potentially >100 bytes wide to just 32 bytes. This is the biggest win. - Smaller Secondary Indexes: All other indexes on
product_version_property_twill also be smaller. - Improved Query Performance: Smaller indexes mean faster scans, better cache utilization, and quicker lookups, updates, and deletes involving the PK or indexes on
product_version_property_t. - Simpler Joins: Joining
product_version_property_tto its parent tables now only requires joining on the singlepv_idorcp_idcolumns. - Simpler Foreign Keys: The FK definitions are simpler.
Disadvantages/Considerations:
- Need for
UNIQUEConstraints: You absolutely must add theUNIQUEconstraints on the original natural keys in the parent tables (config_property_t,product_version_t) to prevent duplicate entries based on business logic. This adds two new indexes. - Storage Overhead (Parent Tables): You add 16 bytes per row to
config_property_tandproduct_version_tfor the new UUID PKs. - Migration Effort: You need to:
- Add the new UUID columns to the parent tables.
- Populate them with unique UUIDs for all existing rows.
- Add the new FK columns (
pv_id,cp_id) toproduct_version_property_t. - Update
product_version_property_tto populate these new columns by joining back to the parent tables based on the original composite keys. - Drop the old PK and FK constraints (or the old columns if they are no longer needed besides the value overrides).
- Add the new PK and FK constraints.
- Add the
UNIQUEconstraints on the parent tables.
- Lookups by Natural Key: Queries that previously used the composite PK directly on the parent tables (e.g.,
SELECT ... FROM product_version_t WHERE host_id = ? AND product_id = ? AND product_version = ?) will now use the newUNIQUEindex instead of the PK index. Performance should still be very good, but it’s technically hitting a different index.
Conclusion:
Yes, it is a good idea. The performance benefits gained from dramatically reducing the size of the primary (and consequently, secondary) indexes on the frequently accessed product_version_property_t table likely outweigh the disadvantages (extra storage on parent tables, migration effort, extra unique indexes). The simplification of joins and foreign keys is also a significant maintainability improvement.
Recommendation:
Proceed with the plan to introduce surrogate UUID keys (preferably UUIDv7 for generation if using a library) on config_property_t and product_version_t, and change product_version_property_t to use these two UUIDs as its composite primary key. Do not forget to add the UNIQUE constraints on the original natural keys in the parent tables.
Composite key with 3 or 4 columns
If a composite key with 3 or 4 columns, it is less definitive than the 5-column case. It moves into a “it depends” territory, requiring weighing the pros and cons more carefully based on specifics.
Here’s a breakdown of factors to consider for 3 or 4 column composite primary keys:
Arguments for Sticking with the Composite Natural Key (CNK):
- Simplicity (Potentially): No need for an extra surrogate key column and an extra
UNIQUEindex on the natural key columns. The schema might feel slightly less cluttered if the natural key is intuitive and stable. - Reduced Storage (Parent Table): Avoids adding 16 bytes per row for the UUID PK in the table itself.
- Meaningful Key: The PK components have inherent business meaning, which can sometimes be useful for direct queries or understanding relationships without extra joins (though the
UNIQUEindex on the SUK approach provides this lookup too). - Migration Cost: Avoids the effort of adding columns, backfilling data, and changing referencing tables.
Arguments for Refactoring to a Surrogate UUID Key (SUK):
- Index Size (Still Relevant): This is the biggest factor.
- Calculate the Width: Add up the maximum potential size of the 3 or 4 columns in the CNK.
UUID: 16 bytesINT: 4 bytesBIGINT: 8 bytesVARCHAR(N): N bytes + 1 or 4 bytes overhead (depending on length)TIMESTAMP: 8 bytesBOOLEAN: 1 byte
- Compare: Compare the calculated width to the typical width of a surrogate key reference (16 bytes for one UUID, or 32 bytes if the child table needs two UUIDs like in your
product_version_property_texample). - Threshold: If the CNK width starts exceeding ~32-40 bytes, the performance benefits of a narrower SUK (especially for secondary indexes and joins) become increasingly attractive. Even a 3-column key like
(UUID, VARCHAR(8), VARCHAR(12))is already16 + (8+1) + (12+1) = 38bytes. A 4-column key is almost certainly wider.
- Calculate the Width: Add up the maximum potential size of the 3 or 4 columns in the CNK.
- Secondary Index Bloat: Remember, all other indexes on the table implicitly include the PK columns. A wide CNK makes every index larger, impacting cache efficiency and scan speed across the board. This effect is magnified if you have many secondary indexes.
- Join Performance/Simplicity: Joining on a single UUID column is generally faster and syntactically simpler than joining on 3 or 4 columns, especially if some are strings.
- Foreign Key Simplicity: Tables referencing this table only need to store a single UUID column as the foreign key, rather than 3 or 4 columns. This significantly reduces storage and complexity in child tables.
- Immutability/Stability: Surrogate keys are inherently stable. If there’s any chance the values in the natural key columns might need to change (which is generally bad practice for PKs but sometimes unavoidable), using a SUK provides crucial insulation.
Decision Rubric (Heuristics):
- Scenario 1: Key is mostly small, fixed-width types (e.g., 3 INTs, 2 INTs + UUID). Total width < ~32 bytes.
- Lean towards: Keeping the CNK might be acceptable, especially if the table isn’t heavily referenced or doesn’t have many secondary indexes. The benefits of SUK are less pronounced.
- Scenario 2: Key includes even one moderately sized VARCHAR (e.g., VARCHAR(20+)) or multiple smaller VARCHARs. Total width > ~32-40 bytes.
- Lean towards: Refactoring to SUK. The performance benefits from reduced index sizes (primary and secondary) and simpler joins/FKs likely start to outweigh the costs.
- Scenario 3: Key includes wide VARCHARs (VARCHAR(50+)).
- Lean towards: Strongly consider refactoring to SUK. Benefits are significant.
- Scenario 4: The table is frequently referenced by other tables via FK.
- Lean towards: Refactoring to SUK to simplify the child tables.
- Scenario 5: The table has many secondary indexes.
- Lean towards: Refactoring to SUK to keep those indexes smaller.
- Scenario 6: Any component of the natural key is potentially volatile.
- Lean towards: Refactoring to SUK for stability.
Conclusion:
For 3 or 4 columns, it’s less of a slam dunk than for 5 columns, but refactoring to a surrogate UUID key is still often beneficial, especially if VARCHARs are involved or the total key width exceeds roughly 32-40 bytes. The key drivers are the reduction in primary and secondary index size and the simplification of foreign keys and joins.
Carefully calculate the width of your specific 3 or 4 column composite keys and consider the usage patterns of the table before deciding.
Atomic Events vs Composite Events
Event Design
This is a fundamental design decision in any Event Sourcing system, and the choice has significant long-term consequences for your system’s flexibility, maintainability, and clarity.
The overwhelming consensus and best practice is to design atomic events.
Let’s break down why, and then look at the trap of composite events.
1. Atomic Events (The Recommended Approach)
An atomic event represents a single, granular, immutable fact that has occurred in your system. It is the smallest possible unit of change that has meaning to the business domain.
Example Scenario: A user updates their profile by changing their name and their shipping address on the same form.
With atomic events, this single user action (the Command) would result in two separate events being written to the stream:
CustomerNameChanged { customerId: "123", newName: "Jane Doe" }CustomerAddressChanged { customerId: "123", newAddress: "..." }
Why Atomic Events are Superior:
a) Maximum Flexibility and Reusability:
- Targeted Consumers: You can have different parts of your system (projections, process managers, other microservices) subscribe to only the events they care about. The shipping department only needs to know about
CustomerAddressChanged, while the marketing department might only care aboutCustomerNameChanged. With a composite event, both would have to subscribe and parse the larger event to see if the part they care about was updated. - Future-Proofing: Six months from now, you might need to build a new feature that triggers a welcome kit to be sent when a customer provides an address for the first time. It’s trivial to add a new consumer for the
CustomerAddressChangedevent.
b) Clear and Unambiguous Intent:
- Each event has a single, well-defined purpose. The name of the event, like
ItemAddedToCart, tells you exactly what happened. - A composite event like
ProfileUpdatedis ambiguous. Did the name change? The address? The phone number? The password? You have to inspect the payload to understand the actual change, which makes the event stream harder to read and debug.
c) Simplified Event Handlers (Projections):
- Your event handlers become small and simple. The logic for handling
CustomerAddressChangedis focused purely on updating the address. - With a composite event, your handler becomes a complex series of
ifstatements:if (event.newName != null) { updateName(); } if (event.newAddress != null) { updateAddress(); } .... This is brittle and hard to maintain.
d) Better for Versioning:
- Events are immutable and stored forever. Your system will evolve. It’s much easier to version a small, focused event (e.g., add an optional field to
CustomerAddressChanged_v2) than it is to version a large, complex composite event where any one of its dozen fields might change.
2. Composite Events (The Anti-Pattern)
A composite event attempts to bundle multiple state changes into a single, large event. It’s often a result of developers mapping the event directly to the UI form or the incoming command.
Using the same scenario (updating name and address):
A composite event might look like this:
CustomerProfileUpdated { customerId: "123", name: "Jane Doe", address: "...", phoneNumber: null }
The Problems with this Approach:
- Loss of Granularity: As explained above, you lose the ability to react to specific changes.
- Ambiguous Intent: The event name doesn’t tell the whole story.
- Sparse Payloads: What if the user only changed their name? The
addressandphoneNumberfields in the event payload would benullor unchanged. Your consumers have to handle these sparse, optional fields, leading to more complex logic. - False Cohesion: It groups things together that only changed at the same time but are not necessarily part of the same business fact.
3. The Key Insight: The Role of the Aggregate
You might be thinking, “But the name and address change must be atomic! What if the system crashes after writing the first event but before the second?”
This is where the Aggregate from Domain-Driven Design (DDD) comes in. The Aggregate is the consistency boundary.
Here is the correct flow:
- Command: A single
UpdateCustomerProfileCommandis sent to the system. It contains both the new name and the new address. - Aggregate: The
CustomerAggregate receives the command. It validates the business rules (e.g., the name isn’t empty, the address is valid). - Event Generation: If the rules pass, the Aggregate’s method produces a list of atomic events:
[CustomerNameChanged, CustomerAddressChanged]. - Atomic Persistence: The Event Store then takes this list of events and persists them to the event stream in a single, atomic transaction. It’s all or nothing. You will never have a
CustomerNameChangedin the stream without the correspondingCustomerAddressChangedfrom the same command.
Key Takeaway: The Command can be composite (representing a single user gesture), but it should be resolved into a set of atomic Events. The atomicity of writing these events is guaranteed by your Aggregate and Event Store, not by bundling them into a single event type.
How to Design Good Atomic Events (A Checklist)
- Name it in the Past Tense:
UserRegistered,OrderShipped,PasswordReset. It’s a fact that has already happened. - Capture Business Intent: Don’t just record a CRUD-like change.
ProductPriceUpdatedis okay, butPriceAdjustedForSaleis better because it captures the why. - Ensure it’s a Complete Fact: Include all necessary data for a consumer to understand the event without having to look up previous state. For example,
ItemAddedToCartshould includeproductId,quantity, andpriceAtTimeOfAdding, not justproductId. - Include Causation and Correlation IDs: Add metadata to your events. Who triggered this change (
userId)? What command caused it (causationId)? What overall business process is this part of (correlationId)? - Think “What happened?” not “What changed?”: An event is a story.
OrderSubmittedis a great event. A composite event likeOrderStateChanged { oldState: "Pending", newState: "Submitted" }is far less expressive.
Final Verdict
Always design atomic events.
Use the Aggregate pattern to ensure that multiple atomic events resulting from a single command are persisted transactionally. This approach gives you a system that is far more flexible, maintainable, readable, and ready for future evolution.
Transaction
When using Kafka to handle the events, we need to handle the transactions on both producer side and consumer side along with database transation to ensure multiple events can be handled together. The choice you make here directly impacts the atomicity, ordering, and resilience of your entire system.
Let’s break down the options and the correct way to handle transactions on both the producer and consumer side.
The Correct Approach: Multiple Events, One Transaction
The best practice, by far, is to push multiple, individual event messages per command, wrapped in a single Kafka producer transaction.
This approach maintains the benefits of atomic events (flexibility, clarity) while guaranteeing the all-or-nothing atomicity you need.
How to Implement This (Producer Side)
Your service that processes the command and talks to the Aggregate will do the following:
- Generate Events: The
CustomerAggregate generates the list of atomic events:[CustomerNameChanged, CustomerAddressChanged]. - Use Kafka Producer Transactions: This is the key feature that makes it all work.
Here is a conceptual code flow (using Java-like syntax):
// IMPORTANT: Configure your producer for transactions and idempotence
// props.put("transactional.id", "my-unique-transactional-id");
// props.put("enable.idempotence", "true");
KafkaProducer<String, Event> producer = new KafkaProducer<>(props);
// The list of events from your Aggregate
List<Event> events = customerAggregate.handle(updateProfileCommand);
// 1. Initialize the transaction
producer.initTransactions();
try {
// 2. Begin the transaction
producer.beginTransaction();
// The Aggregate ID (e.g., "customer-123") is the Kafka Key
String aggregateId = customerAggregate.getId();
for (Event event : events) {
// 3. Send EACH event as a SEPARATE message.
// CRUCIAL: All events for this transaction MUST have the same key.
// This ensures they all go to the same partition and are consumed in order.
producer.send(new ProducerRecord<>("customer-events-topic", aggregateId, event));
}
// 4. Commit the transaction.
// This makes all messages in the transaction visible to consumers atomically.
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// These are fatal errors, we should close the producer
producer.close();
} catch (KafkaException e) {
// 5. If anything goes wrong, abort. None of the messages will be visible.
producer.abortTransaction();
}
producer.close();
Why this is the best way:
- Atomicity Guaranteed: Kafka guarantees that consumers will either see ALL the messages from
commitTransactionor NONE of them (if youabortTransaction). - Ordering Guaranteed: By using the same key (
aggregateId) for all events in the transaction, you ensure they are written to the same partition in the exact order you sent them. Your consumer will read them in that same order. - Consumer Flexibility: Your stream processors can now consume individual, meaningful events. A shipping-related processor can filter for and process only
CustomerAddressChangedevents, completely ignoringCustomerNameChanged.
How to Process Events Transactionally (Consumer Side)
Now, how does your streams processor populate the database tables while maintaining consistency? This is often called the “Transactional Outbox” pattern, but in reverse—a “Transactional Inbox”.
The goal is to atomically update the database AND commit the Kafka offset. You never want to commit an offset for a message whose database update failed.
Here is the standard, robust pattern for a custom consumer/streams processor:
-
Disable Kafka Auto-Commit: This is the most important step. Your application must take manual control of committing offsets. In your consumer configuration, set
enable.auto.commit=false. -
Consume and Process in Batches:
// This is a conceptual loop for your consumer
while (true) {
// 1. Poll for a batch of records. Kafka gives you a batch.
ConsumerRecords<String, Event> records = consumer.poll(Duration.ofMillis(1000));
if (records.isEmpty()) {
continue;
}
// Get your database connection
Connection dbConnection = database.getConnection();
dbConnection.setAutoCommit(false); // Start manual DB transaction management
try {
// 2. Process each record in the polled batch
for (ConsumerRecord<String, Event> record : records) {
Event event = record.value();
// Apply the change to the database based on the event type
processEvent(event, dbConnection);
}
// 3. If all events in the batch were processed successfully, commit the database transaction
dbConnection.commit();
// 4. IMPORTANT: Only after the DB commit succeeds, commit the Kafka offset.
// This tells Kafka "I have successfully and durably processed all messages up to this point."
consumer.commitSync();
} catch (SQLException e) {
// 5. If the DB update fails, rollback the DB transaction...
dbConnection.rollback();
// ...and DO NOT commit the Kafka offset.
// The consumer will re-poll and re-process this same batch of messages later.
// This is why your processing logic MUST be idempotent.
System.err.println("Database update failed. Rolling back. Will retry batch.");
// You might want to seek to the beginning of the failed batch to be explicit
// consumer.seek(record.topic(), record.partition(), record.offset());
} finally {
dbConnection.close();
}
}
It is possible to handle transactions in a Kafka Streams processor, but it requires using the low-level Processor API and is significantly more complex than the standard consumer approach. You cannot achieve this with the high-level DSL (.map(), .filter(), etc.) alone.
If your processor’s only job is to read from Kafka and write to a database: Use the Plain Kafka Consumer. It is simpler, more direct, less error-prone, and purpose-built for this task. You are essentially building a custom, lightweight Kafka Connect sink.
The Critical Need for Idempotency
Because a failure can occur after the DB commit but before the Kafka offset commit, your application might restart and re-process the same batch of events.
Your database update logic must be idempotent. This means running the same update multiple times produces the same result as running it once.
Examples of Idempotent Operations:
INSERTwith a primary key:INSERT INTO customers (...) VALUES (...) ON DUPLICATE KEY UPDATE ...(MySQL) orINSERT ... ON CONFLICT ... DO UPDATE ...(PostgreSQL).UPDATEstatements:UPDATE customers SET name = 'Jane Doe' WHERE customer_id = '123'. Running this 5 times is the same as running it once.- Using Versioning: Store a
versionorlast_processed_event_idin your database table.
If the update tries to run again, theUPDATE customers SET name = 'Jane Doe', version = 2 WHERE customer_id = '123' AND version = 1;WHEREclause will not match, and no rows will be affected.
Why Not Put a List of Events in One Message?
This is an anti-pattern that solves one problem (producer atomicity) by creating many more downstream.
- Loss of Meaning: The fundamental unit is the event, not a list of events. A Kafka message should represent one fact.
- Consumer Complexity: Every single consumer now has to be written to expect a list. It has to deserialize the list and loop through it.
- No Filtering: A consumer who only cares about
CustomerAddressChangedstill has to receive and parse the entire message containing theCustomerNameChangedevent, only to discard it. This is inefficient and tightly couples your consumers to the producer’s batching behavior. - Versioning Hell: Versioning a list of events is much harder than versioning a single event.
Summary
| Action | Recommended Approach |
|---|---|
| Event Design | Atomic Events: CustomerNameChanged, CustomerAddressChanged. |
| Producing to Kafka | Multiple Messages, One Kafka Transaction: Use producer.beginTransaction() and producer.commitTransaction(). |
| Kafka Message Key | Aggregate ID: Use the same key (e.g., customer-123) for all events from the same command to ensure ordering. |
| Consuming from Kafka | Manual Offset Commits: Disable auto-commit. |
| Database Updates | Transactional Batch Processing: [Start DB Tx] -> [Process Batch] -> [Commit DB Tx] -> [Commit Kafka Offset]. |
| Database Logic | Idempotent: Your UPDATE/INSERT logic must handle being re-run on the same event without causing errors or incorrect data. |
Mixed Aggregates vs Single Aggregate
In the simple batch-processing consumer example I provided, the Kafka message key is not being used to segregate processing. The example processes a batch of records polled from Kafka, and that batch can indeed contain events for many different user_ids or host_ids, all mixed together in a single database transaction.
Let’s break down why this happens, the implications, and how to design a consumer that does respect aggregate boundaries for processing.
Why the Simple Batch Consumer Mixes Aggregates
-
Kafka’s Partitioning: You use the
user_id/host_idas the key. Kafka’s producer hashes this key to determine which partition the message goes to. This is excellent because it guarantees that all events for a single user (a single aggregate) will always go to the same partition and will be consumed in the order they were produced. -
The Consumer’s Polling: A Kafka consumer is assigned one or more partitions to read from. When it calls
consumer.poll(), it fetches a batch of records that have arrived on all of its assigned partitions since the last poll.- If your consumer is assigned Partition 0, and events for User A, User B, and User C have all landed on Partition 0, your polled batch will contain
[EventA1, EventB1, EventC1, EventA2, ...]. - They are mixed together, but the ordering per key is preserved (Event A1 will always come before Event A2).
- If your consumer is assigned Partition 0, and events for User A, User B, and User C have all landed on Partition 0, your polled batch will contain
-
The Simple Transaction Loop: The example loop I showed takes this entire mixed batch (
records) and processes it within one DB transaction.// This loop combines multiple aggregates into one DB transaction dbConnection.beginTransaction(); for (ConsumerRecord record : records) { // 'records' contains events for User A, B, C... updateDatabase(record.value()); } dbConnection.commit();
Is This a Problem? (The Trade-offs)
For many use cases, processing mixed aggregates in a single batch is perfectly fine and often more performant.
- Pro: High Throughput. Batching database commits is much more efficient than committing after every single event. Committing a transaction that updates 100 rows for 50 different users is faster than running 100 separate transactions.
- Con: “Noisy Neighbor” Problem. If processing an event for User C throws an unrecoverable
SQLException, the entire batch transaction will be rolled back. This means the valid updates for User A and User B will also be rolled back and retried. The failure of one aggregate’s event processing blocks the progress of others in the same batch. - Con: Loss of Concurrency. You are processing everything serially within a single consumer thread. You aren’t taking advantage of the fact that User A’s events are independent of User B’s events.
The Better Approach: Processing per Aggregate
If you want to isolate failures and potentially parallelize work, you need to change your consumer logic to process events grouped by their key (user_id/host_id).
This pattern is more complex but far more robust for multi-tenant systems.
Conceptual Code for Aggregate-based Processing
This approach reorganizes the polled batch by key before processing.
// Still disable auto-commit: enable.auto.commit=false
while (true) {
ConsumerRecords<String, Event> records = consumer.poll(Duration.ofMillis(1000));
if (records.isEmpty()) continue;
// 1. Group the polled records by their key (the aggregate ID)
Map<String, List<ConsumerRecord<String, Event>>> recordsByAggregate = new HashMap<>();
for (ConsumerRecord<String, Event> record : records) {
recordsByAggregate
.computeIfAbsent(record.key(), k -> new ArrayList<>())
.add(record);
}
// This map now holds the highest offset for each partition from this poll
Map<TopicPartition, OffsetAndMetadata> offsetsToCommit = new HashMap<>();
// 2. Process the events for EACH aggregate in its OWN transaction
for (Map.Entry<String, List<ConsumerRecord<String, Event>>> entry : recordsByAggregate.entrySet()) {
String aggregateId = entry.getKey();
List<ConsumerRecord<String, Event>> aggregateEvents = entry.getValue();
// Start a DB transaction FOR THIS AGGREGATE ONLY
Connection dbConnection = database.getConnection();
dbConnection.setAutoCommit(false);
try {
for (ConsumerRecord<String, Event> record : aggregateEvents) {
// Your idempotent database logic
updateDatabaseForAggregate(record.value(), dbConnection);
// Keep track of the highest offset we've successfully processed
TopicPartition partition = new TopicPartition(record.topic(), record.partition());
OffsetAndMetadata offset = new OffsetAndMetadata(record.offset() + 1);
offsetsToCommit.merge(partition, offset, (oldVal, newVal) -> newVal.offset() > oldVal.offset() ? newVal : oldVal);
}
// Commit the DB transaction for this one aggregate
dbConnection.commit();
} catch (Exception e) {
// FAILURE for a single aggregate!
System.err.println("Failed to process batch for aggregate: " + aggregateId + ". Rolling back.");
dbConnection.rollback();
// What to do now?
// Option A: Skip this aggregate and continue with others (might break ordering).
// Option B (Better): Stop processing the entire poll, log the poison pill, and DO NOT commit any offsets.
// Let's assume Option B. We would break out of this loop.
// For simplicity, we'll just log and continue, but in reality, you need a robust dead-letter queue strategy here.
} finally {
dbConnection.close();
}
}
// 3. After attempting to process all aggregates in the batch, commit the offsets
// for all the partitions where we made progress.
if (!offsetsToCommit.isEmpty()) {
consumer.commitSync(offsetsToCommit);
}
}
Key Differences and Improvements in this Pattern:
- Isolation: A failure in processing for
user-123no longer affectsuser-456. The transaction foruser-456can still be committed. - Correctness: The database state for each aggregate is updated transactionally, respecting its own event sequence.
- Concurrency (Potential): This design is a stepping stone to true parallel processing. You could submit each
List<ConsumerRecord>(the events for one aggregate) to a thread pool for processing, allowing you to update multiple users’ data concurrently. This requires careful management of the offsets to commit.
Summary and Recommendation
Your intuition was exactly right. The simple batch consumer ignores the key for processing logic, which can be a problem.
| Approach | When to Use | Key Benefit | Key Drawback |
|---|---|---|---|
| Simple Batch Processing | - High-throughput, simple ETL jobs. - When a single failure blocking a whole batch is acceptable. - Low-contention systems. | Simplicity & Performance. Easiest to write and often the fastest for bulk loading. | Noisy Neighbor Problem. One bad event can halt processing for all others in the batch. |
| Per-Aggregate Processing | - Multi-tenant systems (your case). - Systems requiring high reliability and fault isolation. - When you need to guarantee progress for healthy aggregates even if others are failing. | Robustness & Isolation. Failures are contained to a single aggregate. | Increased Complexity. Requires more code to group records and manage transactions and offsets carefully. |
For your system, especially a multi-tenant one, the “Per-Aggregate Processing” model is strongly recommended. The added complexity is a worthwhile investment for the significant gains in robustness and fault isolation. It correctly uses the Kafka key not just for partitioning, but also as the logical boundary for your downstream processing and transactions.
DLQ and Process Flow
This is the final, crucial piece of the puzzle for building a truly resilient system. You’ve identified the exact scenario that separates a robust consumer from a brittle one: handling a “poison pill” message.
A poison pill is a message that your consumer cannot process successfully, no matter how many times it retries. A database constraint violation (UNIQUE constraint failed, FOREIGN KEY constraint failed) is a perfect example. If you simply roll back and retry, you will be stuck in an infinite loop, processing the same failing message forever and making no progress.
Yes, you absolutely must handle this by routing the problematic events to a Dead Letter Queue (DLQ), which is typically another Kafka topic.
Here is the complete, robust workflow for handling these failures.
The Dead Letter Queue (DLQ) Pattern
The goal is to isolate the “bad” event(s) so that the consumer can move on and continue processing subsequent “good” events for that aggregate and others.
1. The DLQ Topic
First, you create another Kafka topic specifically for these failed events. For example, if your main topic is customer-events, your DLQ topic might be customer-events-dlq.
The messages in the DLQ topic should be enriched with metadata about the failure:
- The original event payload.
- The original topic, partition, and offset.
- The
consumer-groupthat failed to process it. - A timestamp of the failure.
- The error message or stack trace (e.g., “UNIQUE constraint failed on customers.email”).
2. Modified Consumer Logic with DLQ
Let’s refine the “Per-Aggregate Processing” logic to include the DLQ step.
// Assumes you have a separate KafkaProducer instance for the DLQ
KafkaProducer<String, DeadLetterEvent> dlqProducer = ...;
while (true) {
ConsumerRecords<String, Event> records = consumer.poll(...);
if (records.isEmpty()) continue;
// Group records by aggregate key
Map<String, List<ConsumerRecord<String, Event>>> recordsByAggregate = groupRecordsByKey(records);
Map<TopicPartition, OffsetAndMetadata> offsetsToCommit = new HashMap<>();
for (Map.Entry<String, List<ConsumerRecord<String, Event>>> entry : recordsByAggregate.entrySet()) {
String aggregateId = entry.getKey();
List<ConsumerRecord<String, Event>> aggregateEvents = entry.getValue();
Connection dbConnection = database.getConnection();
dbConnection.setAutoCommit(false);
try {
for (ConsumerRecord<String, Event> record : aggregateEvents) {
// Your idempotent database update logic
updateDatabaseForAggregate(record.value(), dbConnection);
}
// If all events for this aggregate succeed, commit the DB transaction
dbConnection.commit();
// And mark the final offset for this aggregate as ready to commit
markOffsetsAsProcessed(aggregateEvents, offsetsToCommit);
} catch (SQLException e) {
// A "poison pill" or unrecoverable error was detected!
dbConnection.rollback(); // Roll back any partial DB changes for this aggregate
System.err.println("Unrecoverable error processing aggregate " + aggregateId + ". Sending to DLQ. Error: " + e.getMessage());
// **THE DLQ LOGIC**
// Send the entire batch of events for this failing aggregate to the DLQ.
// It's crucial to send the whole batch to preserve their relative order.
for (ConsumerRecord<String, Event> failedRecord : aggregateEvents) {
DeadLetterEvent dlqEvent = createDlqEvent(failedRecord, e);
// Use the same key to keep ordering in the DLQ
dlqProducer.send(new ProducerRecord<>("customer-events-dlq", aggregateId, dlqEvent));
}
// **CRITICAL STEP:** We have now "handled" these poison pill events by sending them to the DLQ.
// We must treat them as successfully processed from the perspective of the main topic
// so we can commit their offsets and move on.
markOffsetsAsProcessed(aggregateEvents, offsetsToCommit);
} catch (Exception otherException) {
// Handle transient errors (e.g., network timeout) differently.
// You might want to retry these without going to the DLQ immediately.
dbConnection.rollback();
// Don't commit offsets, let the consumer re-poll and retry.
System.err.println("Transient error occurred. Will retry batch.");
// Break the loop and wait for the next poll
break;
} finally {
dbConnection.close();
}
}
// After processing all aggregates in the poll...
if (!offsetsToCommit.isEmpty()) {
// Commit the offsets for both successfully processed and DLQ'd aggregates.
// This advances the consumer past the poison pill.
consumer.commitSync(offsetsToCommit);
}
}
// Helper method to create a DLQ event
private DeadLetterEvent createDlqEvent(ConsumerRecord record, Exception e) {
// Populate with original event, error message, topic, offset, etc.
return new DeadLetterEvent(...);
}
// Helper method to update the offsets map
private void markOffsetsAsProcessed(List<ConsumerRecord<String, Event>> records, Map<TopicPartition, OffsetAndMetadata> offsets) {
records.forEach(rec -> {
TopicPartition partition = new TopicPartition(rec.topic(), rec.partition());
OffsetAndMetadata offset = new OffsetAndMetadata(rec.offset() + 1);
offsets.merge(partition, offset, (oldVal, newVal) -> newVal.offset() > oldVal.offset() ? newVal : oldVal);
});
}
What to Do with the DLQ Topic?
The DLQ is not a garbage can. It’s a hospital for sick messages. You need a strategy for managing it.
-
Monitoring and Alerting: Set up alerts on the DLQ topic. A message landing here is an exceptional event that indicates a bug, bad data, or a system inconsistency. A human needs to be notified.
-
Manual Intervention: An operator or developer should inspect the DLQ message.
- Is it a bug in the consumer? If so, deploy a fix to the consumer code.
- Is it bad data from the producer? For example, a
UserRegisteredevent was sent with an email that already exists. The upstream service needs to be fixed. - Is it a state inconsistency? Maybe an event arrived out of order due to a misconfiguration, and the state it expects in the database doesn’t exist yet.
-
Reprocessing (The “Re-drive” Pattern): Once the underlying issue is fixed (e.g., the consumer bug is patched, or the inconsistent DB state is manually corrected), you need a way to re-introduce the events from the DLQ back into the main processing flow. This is typically done with a separate utility or “re-driver” application that reads from the DLQ and publishes the original event back to the original topic.
Differentiating Error Types
It’s crucial to distinguish between:
- Transient Errors: Network issues, temporary database unavailability, lock timeouts. These are retryable. The correct response is to roll back and not commit the offset, forcing a retry on the next poll.
- Permanent Errors: DB constraint violations, deserialization errors, unrecoverable business logic failures (
NullPointerException). These are not retryable. The correct response is to route to the DLQ and commit the offset to move on.
Your catch blocks should be structured to differentiate these.
try {
// ... processing logic
} catch (SQLIntegrityConstraintViolationException | DeserializationException e) {
// PERMANENT: Rollback, send to DLQ, commit offset
} catch (SQLTransientConnectionException | LockTimeoutException e) {
// TRANSIENT: Rollback, DO NOT commit offset, let it retry
} catch (Exception e) {
// Generic catch-all, probably treat as permanent to be safe
// Rollback, send to DLQ, commit offset
}
By implementing this complete pattern, you create a system that is not only transactional and correct but also self-healing. It can automatically isolate failures, alert you to the problem, and continue operating for all healthy aggregates, preventing a single bad event from bringing your entire system to a halt.
Notification and Event Store
1. Is notification_t replacing the DLQ?
Short Answer: No, not effectively. They serve different primary purposes, though they can complement each other.
Let’s clarify the roles:
-
Dead Letter Queue (DLQ - Kafka Topic):
- Primary Purpose: Operational recovery. It’s a queue of unprocessable messages that allows your consumer to move on and continue processing subsequent messages. It’s designed for reprocessing the original event once the underlying issue (code bug, bad data, external system outage) is resolved.
- Nature: A temporary holding area for raw events that need to be re-driven into the main processing flow. It’s part of your automated error handling and retry mechanism.
- Mechanism: It preserves the original message payload (and its context) in a format easily consumable by other Kafka applications (like a re-driver).
-
notification_t(Database Table):- Primary Purpose: Audit, visibility, and user-facing reporting. It’s a record of processing outcomes (success/failure) and associated metadata (error messages). It’s a read model or a projection for displaying status.
- Nature: A durable log or materialized view of processing activity. It’s primarily for human intervention and analysis.
- Mechanism: Stores a summary or specific details about what happened during processing, typically in a structured way that can be queried and displayed.
Why notification_t doesn’t replace a DLQ:
-
Reprocessing:
- If an event fails and you only log it to
notification_t, your Kafka consumer is still stuck. If it commits the offset for that failed message, the message is lost from the Kafka topic (due to retention policies). You’d then have to reconstruct the original message fromnotification_tand manually re-publish it to Kafka, which is cumbersome. - A DLQ (Kafka topic) already holds the raw message and allows for a more automated re-driving process.
- If an event fails and you only log it to
-
Operational Flow:
- A DLQ is part of an automated pipeline: consumer fails -> sends to DLQ -> consumer moves on. Alerts are triggered.
- With just
notification_t, you need an external mechanism (human reading the UI, another scheduled job) to query the table, identify failures, and trigger manual re-publishing. This is less reactive and scalable.
-
Mixing Concerns:
- Your
notification_ttable correctly stores processing results. This is a projection of the events. - The raw events themselves are what need to be re-driven.
- A DLQ focuses solely on holding the raw, unprocessable events.
- Your
How they can complement each other:
- When an event is sent to the DLQ, you also log an entry in
notification_tindicating the failure, which event was sent to DLQ, and why. This provides the user-facing visibility you want while maintaining the operational robustness of the DLQ. - Your re-driver for the DLQ could also update the
notification_tentry when an event is successfully re-processed.
Conclusion on DLQ vs. notification_t: Your notification_t is a valuable audit and reporting tool, but it should not be your sole mechanism for handling unprocessable Kafka messages. The DLQ pattern with a dedicated Kafka topic is the industry standard for robust, scalable error handling and reprocessing in a streaming architecture.
2. Using notification_t as the Event Store for replay?
Short Answer: This is generally a poor idea due to mixed concerns and potential data loss, unless your notification_t is specifically designed as a pure Event Store.
Let’s define “Event Store” in Event Sourcing:
- The Event Store: This is the single, authoritative source of truth for your system’s state. It stores all historical domain events (atomic, immutable facts) in the exact order they occurred, for all time (or at least for a very long retention period). It’s used to:
- Rebuild the current state of an aggregate.
- Replay all events to build new read models (projections).
- Perform historical analysis.
Evaluating notification_t as an Event Store:
-
“Save all the events”: This is the fundamental requirement. If it indeed stores the full, raw, original event payload for every event that enters your system, then this part is met.
-
“Success or failure of the processing with error message”: This is where it breaks the Event Store principle. An Event Store should only contain facts that happened. Whether an event was processed successfully or failed is a derived state (a projection or audit log entry), not the event itself.
- Problem 1: Mixing Concerns: Mixing raw events with processing results violates the purity of an Event Store. It makes the Event Store harder to reason about and potentially less efficient for replay.
- Problem 2: Data Integrity/Purity for Replay: If you replay events from this table, do you replay the “success/failure” status? No, you only care about the event itself. This metadata is irrelevant for rebuilding aggregate state or building new projections.
-
“Kafka topic might not contain all the events”: This is a critical point.
- If your Kafka topics have short retention (e.g., 7 days), then yes, you absolutely need an external, durable Event Store that retains events indefinitely.
- A relational database is a perfectly valid choice for an Event Store. Many Event Sourcing implementations use a relational DB table (
eventsorevent_stream) where each row is an event, uniquely identified, with the aggregate ID, sequence number, event type, and event payload.
Recommendation for your Event Store:
-
Dedicate a separate table as your Event Store: If you want to use a database for event storage (which is fine!), create a table specifically for
eventsorevent_store.- This table should only store the raw, immutable event data (ID, aggregate ID, sequence number, timestamp, type, payload).
- It should not include processing status or error messages. These are projection data.
-
Maintain
notification_tas a separate read model: Yournotification_ttable should remain exactly as it is: a valuable projection that tracks the processing success/failure for auditing and user visibility. It is derived from the events, not the source of events. -
Choose your Event Store carefully:
- Kafka: If you configure Kafka topics for infinite retention (or very long, e.g., years), Kafka can serve as your primary Event Store. This is powerful for stream processing.
- Relational Database: If Kafka retention is short, or if you prefer a traditional database for your Event Store, design a dedicated
eventstable that conforms to the Event Store principles. - Specialized Event Stores: There are also purpose-built Event Stores (e.g., EventStoreDB) that excel at this task.
Combined Ideal Architecture:
- Producers send atomic events to Kafka topics (e.g.,
customer-events) using Kafka transactions for atomicity. - Kafka topics are configured with long retention if they are your Event Store, or short retention if you’re using a separate database as Event Store.
- Consumers/Stream Processors read from Kafka.
- They process events (e.g., update a materialized view, send to another service).
- They also persist a copy of the event to your dedicated, pure Event Store table (if Kafka isn’t your long-term store). This must happen transactionally with their other updates or be a separate, guaranteed write.
- They also update your
notification_ttable with the processing status (success/failure) for audit/UI. - If an unrecoverable error occurs, they send the original event to a DLQ topic (e.g.,
customer-events-dlq) and log the failure tonotification_t. - They then commit their offsets on the main topic.
- DLQ management: Separate processes monitor the DLQ, allow manual inspection, and facilitate re-driving events back to the main topic after a fix.
- Replaying: When needed, new services or new read models can be built by replaying all events from your chosen Event Store (long-retention Kafka topics or your dedicated
eventsdatabase table).
This separation of concerns leads to a much more robust, understandable, and maintainable system.
Event Store
When to populate the event store is a crucial design decision for ensuring the integrity and completeness of your Event Store. There are two main patterns to consider, each with its own trade-offs.
Option 1: Populating the Event Store (DB Table) Before Publishing to Kafka (Transactional Outbox Pattern)
This is generally the most robust and recommended approach for ensuring at-least-once (often effectively once) persistence of your events. It guarantees that an event is durably stored in your Event Store before it is ever considered for publishing to Kafka.
How it works:
-
Command Processing:
- Your
Aggregatereceives a command and generates a list of atomic events. - These events are persisted to your dedicated Event Store table (e.g.,
events_store_t) within the same local database transaction as any state changes to your aggregate’s materialized view (if applicable). This is the key: a single local transaction. - Alongside storing the event in
events_store_t, the event is also stored in an “Outbox” table (e.g.,outbox_messages) in the same database transaction. Theoutbox_messagestable serves as a temporary holding area for events that need to be published to Kafka.
- Your
-
Outbox Relayer/Publisher:
- A separate, dedicated process (the “Outbox Relayer” or “Change Data Capture (CDC) Publisher”) continuously monitors the
outbox_messagestable for new entries. - When it finds new events in the
outbox_messagestable, it reads them and publishes them to Kafka. - After successfully publishing to Kafka, it marks the event as “published” in the
outbox_messagestable or deletes it.
- A separate, dedicated process (the “Outbox Relayer” or “Change Data Capture (CDC) Publisher”) continuously monitors the
Why this is best:
- Atomicity Guaranteed (Local): The critical guarantee is that the event is either stored in your Event Store AND in the Outbox table, or neither. If the application crashes after generating events but before publishing to Kafka, the events are durably stored in the Outbox and will be published later by the relayer.
- No Data Loss: Events are never lost between generation and publication to Kafka.
- Decoupling: The service generating events doesn’t need to know about Kafka’s availability. It only needs to commit to its local database. The Outbox Relayer handles the Kafka dependency.
- Effective Once: Combined with Kafka’s idempotent producer, this provides effectively once-delivery.
- Source of Truth: The event_store_t database table will be our source of truth and it allows queries against it.
Where the events_store_t is populated:
- In the same local DB transaction where the events are generated and recorded in the Outbox table.
Option 2: Populating the Event Store (DB Table) After Consuming from Kafka
This approach involves two stages of atomicity: first, the producer guarantees delivery to Kafka, and then the consumer guarantees persistence from Kafka to your Event Store.
How it works:
-
Command Processing & Kafka Publishing:
- Your
Aggregategenerates events. - These events are immediately published to Kafka using Kafka producer transactions (as we discussed previously, to guarantee all events from a command are published atomically).
- Your
-
Consumer Processing:
- Your Kafka consumer (the one responsible for populating your Event Store) reads events from Kafka.
- For each event (or batch of events from the same aggregate), it persists the event to your dedicated
events_store_ttable within a local database transaction. - Crucially: It commits the Kafka offset only after the database transaction to
events_store_tis successful.
Why this is generally less ideal for the primary Event Store:
- Producer Responsibility: The service that generates the events also has the responsibility of publishing to Kafka. If Kafka is down or slow, the producer service might be blocked or need to implement complex retry logic.
- Data Durability Gap: There’s a theoretical, albeit small, window where events are generated but might not yet be durably committed to your authoritative
events_store_tdatabase if the consumer or Kafka has issues. (Kafka itself provides durability, but your application’s Event Store is separate). - Complexity for Replay: If your consumer fails and you need to replay events, where do you replay from? Kafka? What if Kafka’s retention is short? This pattern requires Kafka to be the true long-term Event Store, or it introduces a reliance on the consumer correctly populating the DB.
- Source of Truth: The Kafka topic is written first and it will be our event store. It doesn’t support query on the events directly.
Where the events_store_t is populated:
- In the consumer process, within a local DB transaction, after polling from Kafka.
Answering your Specific Questions:
-
“Where is the best place to populate this table?” The best place is in the same database transaction where the event is generated and stored in an Outbox table (Option 1). This ensures that your authoritative Event Store (your
events_store_ttable) is always the first and most reliable source of truth. -
“In the second case, should we populate the failed events (events went to DLQ) to the event store?” This question is about what constitutes “truth” in your Event Store.
No, you should populate all original events to the
events_store_ttable regardless of whether they later cause a processing error or end up in a DLQ.Reasoning:
- The
events_store_tis a record of what happened in the domain. An event likeOrderPlacedis a fact that occurred, regardless of whether a downstream system successfully processed it or failed due to a unique constraint violation. - The
events_store_tshould be pure. It tells the story of your system’s state changes. - The fact that an event failed to be processed by a consumer is a processing audit detail that belongs in your
notification_ttable or system logs, not in the fundamental Event Store. - If you don’t put the failed event in
events_store_t, you are losing part of your system’s history. When you rebuild state by replaying fromevents_store_t, you would miss this event, leading to an incorrect state.
In summary:
events_store_t: Stores all events that happened, always.notification_t: Stores the status of processing each event (success/failure, error message), as a projection.- DLQ: Stores unconsumable events for reprocessing.
- The
Conclusion
I strongly recommend implementing the Transactional Outbox pattern (Option 1) for populating your events_store_t table. This pattern has become an industry best practice for achieving reliable event publishing from a database-backed service. It is more complex initially but provides superior durability and resilience compared to directly publishing to Kafka from your domain service.
And regardless of the publishing mechanism, your events_store_t should be a complete, immutable log of all domain events, untainted by processing outcomes.
Change Data Capture
Using Change Data Capture (CDC) (like Debezium) for the Transactional Outbox is the gold standard for reliably publishing events from a database-backed service to Kafka.
Here’s a detailed design and a conceptual Java implementation for the producer side, along with the Debezium configuration.
Overall Architecture
-
Producer Service (Your Java Application):
- Receives commands (e.g.,
UpdateCustomerProfileCommand). - Interacts with the
CustomerAggregate. - Generates a list of atomic domain events (e.g.,
CustomerNameChanged,CustomerAddressChanged). - Crucially: Persists these events to two database tables within a single local database transaction:
events_store_t: Your immutable, authoritative Event Store (long-term historical log).outbox_messages: A temporary table used by CDC to pick up events for Kafka.
- Receives commands (e.g.,
-
Transactional Outbox Table (
outbox_messages):- A simple database table that acts as a queue for events to be published.
- Rows are inserted into this table in the same transaction as any other domain state changes.
-
CDC Tool (Debezium):
- Monitors the
outbox_messagestable (and potentiallyevents_store_tif you want a separate stream for the full event store, though typically you’d monitor the outbox). - Detects new rows (inserts).
- Captures the
afterimage of the inserted row. - Transforms this data into a Kafka message.
- Publishes the Kafka message to the configured topic.
- Monitors the
-
Kafka Topic(s):
- Events are published here. You can configure Debezium to route events to different topics based on the
aggregate_typeorevent_typefrom youroutbox_messagestable.
- Events are published here. You can configure Debezium to route events to different topics based on the
-
Kafka Consumers:
- Your downstream services (stream processors, materialized view builders, notification services) consume from these Kafka topics.
- They process the events, update their read models, and commit their offsets.
Design of the Database Tables
1. events_store_t (Your Primary Event Store)
This table holds the immutable, ordered sequence of all domain events.
CREATE TABLE events_store_t (
id UUID PRIMARY KEY, -- Unique ID for the event itself
aggregate_id VARCHAR(255) NOT NULL, -- The ID of the aggregate (e.g., customer-123)
aggregate_type VARCHAR(255) NOT NULL, -- The type of aggregate (e.g., 'Customer')
event_type VARCHAR(255) NOT NULL, -- The specific type of event (e.g., 'CustomerNameChanged')
sequence_number BIGINT NOT NULL, -- Monotonically increasing sequence number per aggregate
timestamp TIMESTAMP WITH TIME ZONE NOT NULL, -- When the event occurred
payload JSONB NOT NULL, -- The full event payload (JSON)
metadata JSONB, -- Optional: correlation IDs, causation IDs, user ID, etc.
-- Constraints for event order and uniqueness per aggregate
UNIQUE (aggregate_id, sequence_number)
);
-- Index for efficient lookup by aggregate
CREATE INDEX idx_events_store_aggregate ON events_store_t (aggregate_id);
2. outbox_messages (For CDC Publishing)
This table serves as the bridge to Kafka.
CREATE TABLE outbox_messages (
id UUID PRIMARY KEY, -- Unique ID for this outbox message
aggregate_id VARCHAR(255) NOT NULL, -- The ID of the aggregate (for Kafka key)
aggregate_type VARCHAR(255) NOT NULL, -- The type of aggregate (for Kafka topic routing)
event_type VARCHAR(255) NOT NULL, -- The specific type of event
timestamp TIMESTAMP WITH TIME ZONE NOT NULL, -- When the event was created
payload JSONB NOT NULL, -- The full event payload (JSON)
metadata JSONB, -- Optional: correlation IDs, causation IDs, user ID, etc.
-- Note: No sequence_number here, as the Event Store manages that.
-- Debezium will process these by insertion order.
);
-- An index on timestamp can be useful for manual cleanup or if not using CDC
-- CREATE INDEX idx_outbox_timestamp ON outbox_messages (timestamp);
Java Implementation (Producer Service)
We’ll use Spring Boot for simplicity, Spring Data JPA for database interaction, and Jackson for JSON serialization.
Dependencies (build.gradle):
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.postgresql:postgresql' // Or your chosen DB driver
runtimeOnly 'com.h2database:h2' // For in-memory testing convenience
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
implementation 'com.fasterxml.jackson.core:jackson-databind' // For JSON
implementation 'com.fasterxml.jackson.datatype:jackson-datatype-jsr310' // For Java 8 Date/Time
}
1. Domain Events
// domain/events/DomainEvent.java
package com.example.eventoutbox.domain.events;
import com.fasterxml.jackson.annotation.JsonSubTypes;
import com.fasterxml.jackson.annotation.JsonTypeInfo;
import java.time.Instant;
import java.util.UUID;
// Use JsonTypeInfo for polymorphic deserialization (if you need to deserialize events later)
@JsonTypeInfo(use = JsonTypeInfo.Id.NAME, property = "eventType")
@JsonSubTypes({
@JsonSubTypes.Type(value = CustomerNameChanged.class, name = "CustomerNameChanged"),
@JsonSubTypes.Type(value = CustomerAddressChanged.class, name = "CustomerAddressChanged")
})
public abstract class DomainEvent {
private final UUID eventId;
private final Instant timestamp;
private final String aggregateId;
private final String aggregateType;
private final long sequenceNumber; // Important for Event Sourcing
public DomainEvent(UUID eventId, Instant timestamp, String aggregateId, String aggregateType, long sequenceNumber) {
this.eventId = eventId;
this.timestamp = timestamp;
this.aggregateId = aggregateId;
this.aggregateType = aggregateType;
this.sequenceNumber = sequenceNumber;
}
public UUID getEventId() { return eventId; }
public Instant getTimestamp() { return timestamp; }
public String getAggregateId() { return aggregateId; }
public String getAggregateType() { return aggregateType; }
public long getSequenceNumber() { return sequenceNumber; }
public abstract String getEventType();
}
// domain/events/CustomerNameChanged.java
package com.example.eventoutbox.domain.events;
import java.time.Instant;
import java.util.UUID;
public class CustomerNameChanged extends DomainEvent {
private final String newName;
public CustomerNameChanged(UUID eventId, Instant timestamp, String customerId, long sequenceNumber, String newName) {
super(eventId, timestamp, customerId, "Customer", sequenceNumber);
this.newName = newName;
}
public String getNewName() { return newName; }
@Override
public String getEventType() { return "CustomerNameChanged"; }
}
// domain/events/CustomerAddressChanged.java
package com.example.eventoutbox.domain.events;
import java.time.Instant;
import java.util.UUID;
public class CustomerAddressChanged extends DomainEvent {
private final String newAddress; // Simple string for address example
public CustomerAddressChanged(UUID eventId, Instant timestamp, String customerId, long sequenceNumber, String newAddress) {
super(eventId, timestamp, customerId, "Customer", sequenceNumber);
this.newAddress = newAddress;
}
public String getNewAddress() { return newAddress; }
@Override
public String getEventType() { return "CustomerAddressChanged"; }
}
2. Aggregate
// domain/Customer.java
package com.example.eventoutbox.domain;
import com.example.eventoutbox.domain.events.CustomerAddressChanged;
import com.example.eventoutbox.domain.events.CustomerNameChanged;
import com.example.eventoutbox.domain.events.DomainEvent;
import lombok.Getter;
import java.time.Instant;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
// This is a simplified Aggregate. In a real ES system, you'd load state from events.
// For this example, we're just focusing on event generation.
@Getter
public class Customer {
private final String customerId;
private String name;
private String address;
private long currentSequenceNumber; // Tracks the next sequence number for new events
private final List<DomainEvent> uncommittedEvents = new ArrayList<>();
public Customer(String customerId, long currentSequenceNumber) {
this.customerId = customerId;
this.currentSequenceNumber = currentSequenceNumber;
}
public static Customer create(String customerId) {
return new Customer(customerId, 0L); // Start with seq 0 for a new aggregate
}
public void changeName(String newName) {
if (!newName.equals(this.name)) { // Only emit event if something actually changed
this.name = newName;
this.currentSequenceNumber++;
uncommittedEvents.add(new CustomerNameChanged(UUID.randomUUID(), Instant.now(), customerId, currentSequenceNumber, newName));
}
}
public void changeAddress(String newAddress) {
if (!newAddress.equals(this.address)) {
this.address = newAddress;
this.currentSequenceNumber++;
uncommittedEvents.add(new CustomerAddressChanged(UUID.randomUUID(), Instant.now(), customerId, currentSequenceNumber, newAddress));
}
}
// After events are stored, clear them
public void markEventsCommitted() {
this.uncommittedEvents.clear();
}
}
3. Persistence Layer (Entities and Repositories)
// infrastructure/persistence/outbox/OutboxMessage.java
package com.example.eventoutbox.infrastructure.persistence.outbox;
import jakarta.persistence.*;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.hibernate.annotations.JdbcTypeCode;
import org.hibernate.type.SqlTypes;
import java.time.Instant;
import java.util.UUID;
@Entity
@Table(name = "outbox_messages")
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class OutboxMessage {
@Id
private UUID id; // Event ID
private String aggregateId;
private String aggregateType;
private String eventType;
private Instant timestamp;
@JdbcTypeCode(SqlTypes.JSON) // For PostgreSQL JSONB type
@Column(columnDefinition = "jsonb")
private String payload; // Store payload as JSON string
@JdbcTypeCode(SqlTypes.JSON)
@Column(columnDefinition = "jsonb")
private String metadata; // Optional metadata as JSON string
}
// infrastructure/persistence/outbox/OutboxMessageRepository.java
package com.example.eventoutbox.infrastructure.persistence.outbox;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.UUID;
public interface OutboxMessageRepository extends JpaRepository<OutboxMessage, UUID> {}
// infrastructure/persistence/eventstore/EventStoreEvent.java
package com.example.eventoutbox.infrastructure.persistence.eventstore;
import jakarta.persistence.*;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.hibernate.annotations.JdbcTypeCode;
import org.hibernate.type.SqlTypes;
import java.time.Instant;
import java.util.UUID;
@Entity
@Table(name = "events_store_t")
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class EventStoreEvent {
@Id
private UUID id; // Event ID
private String aggregateId;
private String aggregateType;
private String eventType;
private Instant timestamp;
private long sequenceNumber;
@JdbcTypeCode(SqlTypes.JSON)
@Column(columnDefinition = "jsonb")
private String payload; // Store payload as JSON string
@JdbcTypeCode(SqlTypes.JSON)
@Column(columnDefinition = "jsonb")
private String metadata; // Optional metadata as JSON string
}
// infrastructure/persistence/eventstore/EventStoreEventRepository.java
package com.example.eventoutbox.infrastructure.persistence.eventstore;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.UUID;
public interface EventStoreEventRepository extends JpaRepository<EventStoreEvent, UUID> {}
4. Application Service (Handles Commands and Persistence)
This is where the magic of the single transaction happens.
// application/CustomerApplicationService.java
package com.example.eventoutbox.application;
import com.example.eventoutbox.domain.Customer;
import com.example.eventoutbox.domain.events.DomainEvent;
import com.example.eventoutbox.infrastructure.persistence.eventstore.EventStoreEvent;
import com.example.eventoutbox.infrastructure.persistence.eventstore.EventStoreEventRepository;
import com.example.eventoutbox.infrastructure.persistence.outbox.OutboxMessage;
import com.example.eventoutbox.infrastructure.persistence.outbox.OutboxMessageRepository;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.io.IOException;
import java.util.List;
import java.util.UUID;
import java.util.stream.Collectors;
@Service
@RequiredArgsConstructor
public class CustomerApplicationService {
private final OutboxMessageRepository outboxMessageRepository;
private final EventStoreEventRepository eventStoreEventRepository;
private final ObjectMapper objectMapper; // For JSON serialization
// Represents an incoming command from e.g., a REST endpoint
public record UpdateCustomerProfileCommand(String customerId, String newName, String newAddress) {}
// @Transactional ensures that all database operations within this method
// (saving to outbox_messages and events_store_t) are part of a single DB transaction.
@Transactional
public void updateCustomerProfile(UpdateCustomerProfileCommand command) {
// --- 1. Load/Create Aggregate (Simplified for this example) ---
// In a real Event Sourcing system, you would load the Customer's state
// by replaying events from eventStoreEventRepository for command.customerId.
// For simplicity, we'll assume a new customer or just focus on event generation.
Customer customer = Customer.create(command.customerId);
// customer.loadFromEvents(eventStoreEventRepository.findByAggregateIdOrderBySequenceNumberAsc(command.customerId));
// --- 2. Apply Business Logic & Generate Events ---
if (command.newName() != null) {
customer.changeName(command.newName());
}
if (command.newAddress() != null) {
customer.changeAddress(command.newAddress());
}
// --- 3. Persist Events to Event Store & Outbox (Atomically) ---
List<DomainEvent> eventsToStore = customer.getUncommittedEvents();
if (eventsToStore.isEmpty()) {
return; // No changes, no events to publish
}
List<EventStoreEvent> eventStoreEntities = eventsToStore.stream()
.map(this::mapToEventStoreEvent)
.collect(Collectors.toList());
eventStoreEventRepository.saveAll(eventStoreEntities); // Save to the authoritative Event Store
List<OutboxMessage> outboxMessages = eventsToStore.stream()
.map(this::mapToOutboxMessage)
.collect(Collectors.toList());
outboxMessageRepository.saveAll(outboxMessages); // Save to the Outbox for CDC
customer.markEventsCommitted(); // Clear uncommitted events after successful persistence
}
private OutboxMessage mapToOutboxMessage(DomainEvent event) {
try {
return OutboxMessage.builder()
.id(event.getEventId())
.aggregateId(event.getAggregateId())
.aggregateType(event.getAggregateType())
.eventType(event.getEventType())
.timestamp(event.getTimestamp())
.payload(objectMapper.writeValueAsString(event)) // Serialize event to JSON
.metadata(null) // Add actual metadata if needed
.build();
} catch (IOException e) {
throw new RuntimeException("Failed to serialize event to JSON: " + event.getEventId(), e);
}
}
private EventStoreEvent mapToEventStoreEvent(DomainEvent event) {
try {
return EventStoreEvent.builder()
.id(event.getEventId())
.aggregateId(event.getAggregateId())
.aggregateType(event.getAggregateType())
.eventType(event.getEventType())
.timestamp(event.getTimestamp())
.sequenceNumber(event.getSequenceNumber())
.payload(objectMapper.writeValueAsString(event)) // Serialize event to JSON
.metadata(null) // Add actual metadata if needed
.build();
} catch (IOException e) {
throw new RuntimeException("Failed to serialize event to JSON: " + event.getEventId(), e);
}
}
}
5. REST Controller (Entry Point)
// application/CustomerController.java
package com.example.eventoutbox.application;
import lombok.RequiredArgsConstructor;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/customers")
@RequiredArgsConstructor
public class CustomerController {
private final CustomerApplicationService customerApplicationService;
@PostMapping("/profile")
public ResponseEntity<String> updateCustomerProfile(@RequestBody CustomerApplicationService.UpdateCustomerProfileCommand command) {
customerApplicationService.updateCustomerProfile(command);
return ResponseEntity.ok("Customer profile update command received and processed.");
}
}
6. Spring Boot Application (and application.properties)
// EventOutboxApplication.java
package com.example.eventoutbox;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class EventOutboxApplication {
public static void main(String[] args) {
SpringApplication.run(EventOutboxApplication.class, args);
}
}
# application.properties (for H2 in-memory for testing)
spring.datasource.url=jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.jpa.hibernate.ddl-auto=update # Use 'update' for schema management in dev
spring.jackson.serialization.write-dates-as-timestamps=false # Good practice for Instant
# If using PostgreSQL:
# spring.datasource.url=jdbc:postgresql://localhost:5432/yourdb
# spring.datasource.username=youruser
# spring.datasource.password=yourpassword
# spring.jpa.database-platform=org.hibernate.dialect.PostgreSQLDialect
Debezium Configuration (Conceptual)
You’ll deploy Debezium as a Kafka Connect connector. Here’s a sample configuration (e.g., postgresql-outbox-connector.json) for PostgreSQL.
{
"name": "outbox-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "secret",
"database.dbname": "configserver",
"database.server.name": "postgres",
"topic.prefix": "portal-event",
"schema.include.list": "public",
"table.include.list": "public.outbox_message_t",
"message.key.columns": "public.outbox_message_t:host_id",
"plugin.name": "pgoutput",
"publication.name": "dbz_publication",
"slot.name": "dbz_replication_slot",
"slot.drop.on.stop": "false",
"signal.when.disconnected": "true",
"tombstones.on.delete": "true",
"max.retries": 5,
"retry.delay.ms": 10000,
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter.schemas.enable": "false",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"transforms": "unwrap,addTransactionIdHeader,timestamp_converter,outbox,extractPayload,extractKey,final_route",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"transforms.unwrap.delete.handling.mode": "none",
"transforms.addTransactionIdHeader.type": "org.apache.kafka.connect.transforms.HeaderFrom$Value",
"transforms.addTransactionIdHeader.fields": "transaction_id",
"transforms.addTransactionIdHeader.headers": "transaction_id",
"transforms.addTransactionIdHeader.operation": "copy",
"transforms.timestamp_converter.type": "org.apache.kafka.connect.transforms.TimestampConverter$Value",
"transforms.timestamp_converter.field": "event_ts",
"transforms.timestamp_converter.target.type": "unix",
"transforms.timestamp_converter.format": "yyyy-MM-dd'T'HH:mm:ss.SSSSSS'Z'",
"transforms.outbox.type": "io.debezium.transforms.outbox.EventRouter",
"transforms.outbox.table.field.event.id": "id",
"transforms.outbox.table.field.event.key": "host_id",
"transforms.outbox.table.field.event.type": "event_type",
"transforms.outbox.table.field.event.timestamp": "event_ts",
"transforms.outbox.table.field.event.payload": "payload",
"transforms.outbox.table.field.event.metadata": "metadata",
"transforms.outbox.table.field.aggregate.type": "aggregate_type",
"transforms.outbox.table.field.aggregate.id": "aggregate_id",
"transforms.extractPayload.type": "org.apache.kafka.connect.transforms.ExtractField$Value",
"transforms.extractPayload.field": "payload",
"transforms.extractKey.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractKey.field": "host_id",
"transforms.final_route.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.final_route.regex": "portal-event\\.public\\.outbox_message_t",
"transforms.final_route.replacement": "portal-event"
}
}
And here is the curl command to create the connector locally.
curl --location --request POST 'http://localhost:8083/connectors' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "outbox-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "secret",
"database.dbname": "configserver",
"database.server.name": "postgres",
"topic.prefix": "portal-event",
"schema.include.list": "public",
"table.include.list": "public.outbox_message_t",
"message.key.columns": "public.outbox_message_t:host_id",
"plugin.name": "pgoutput",
"publication.name": "dbz_publication",
"slot.name": "dbz_replication_slot",
"slot.drop.on.stop": "false",
"signal.when.disconnected": "true",
"tombstones.on.delete": "true",
"max.retries": 5,
"retry.delay.ms": 10000,
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter.schemas.enable": "false",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"transforms": "unwrap,addTransactionIdHeader,timestamp_converter,outbox,extractPayload,extractKey,final_route",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"transforms.unwrap.delete.handling.mode": "none",
"transforms.addTransactionIdHeader.type": "org.apache.kafka.connect.transforms.HeaderFrom$Value",
"transforms.addTransactionIdHeader.fields": "transaction_id",
"transforms.addTransactionIdHeader.headers": "transaction_id",
"transforms.addTransactionIdHeader.operation": "copy",
"transforms.timestamp_converter.type": "org.apache.kafka.connect.transforms.TimestampConverter$Value",
"transforms.timestamp_converter.field": "event_ts",
"transforms.timestamp_converter.target.type": "unix",
"transforms.timestamp_converter.format": "yyyy-MM-dd'\''T'\''HH:mm:ss.SSSSSS'\''Z'\''",
"transforms.outbox.type": "io.debezium.transforms.outbox.EventRouter",
"transforms.outbox.table.field.event.id": "id",
"transforms.outbox.table.field.event.key": "host_id",
"transforms.outbox.table.field.event.type": "event_type",
"transforms.outbox.table.field.event.timestamp": "event_ts",
"transforms.outbox.table.field.event.payload": "payload",
"transforms.outbox.table.field.event.metadata": "metadata",
"transforms.outbox.table.field.aggregate.type": "aggregate_type",
"transforms.outbox.table.field.aggregate.id": "aggregate_id",
"transforms.extractPayload.type": "org.apache.kafka.connect.transforms.ExtractField$Value",
"transforms.extractPayload.field": "payload",
"transforms.extractKey.type": "org.apache.kafka.connect.transforms.ExtractField$Key",
"transforms.extractKey.field": "host_id",
"transforms.final_route.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.final_route.regex": "portal-event\\.public\\.outbox_message_t",
"transforms.final_route.replacement": "portal-event"
}
}
'
The following are the commands to check the connector status and config:
# Check connector status
curl http://localhost:8083/connectors/outbox-connector/status
# Check connector config
curl http://localhost:8083/connectors/outbox-connector/config
Important Notes on Debezium Transforms:
EventRouterTransform: This is a specialized Debezium SMT (Single Message Transform) designed specifically for the Transactional Outbox pattern.- It expects
id,aggregate_id,aggregate_type,event_type,timestamp,payload, andmetadatafields in youroutbox_messagestable. - It automatically wraps the
payloadinto the Kafka message value and sets the Kafka key based onaggregate_id. - It can route to specific topics (e.g.,
outbox.Customer,outbox.Order) based onaggregate_type. - It filters out
DELETEoperations on theoutbox_messagestable (which is what your clean-up process would do, if you had one).
- It expects
- CDC (Debezium) only processes
INSERTs: When you insert a row intooutbox_messages, Debezium picks it up. After it’s published, you can (optionally) have a separate, idempotent cleanup job or a Debezium signal that deletes the record fromoutbox_messages. Debezium will then capture thisDELETEevent, but theEventRoutertransform will typically filter it out, preventing re-publishing.
How to test the Java Producer Service
-
Run your Spring Boot application.
-
Use a tool like
curlor Postman to send a POST request:curl -X POST http://localhost:8080/customers/profile \ -H "Content-Type: application/json" \ -d '{ "customerId": "customer-abc-123", "newName": "Alice Smith", "newAddress": "123 Main St, Anytown" }' -
Check your database
events_store_tandoutbox_messagestables. You should see entries forCustomerNameChangedandCustomerAddressChangedin both, all committed atomically.
Key Benefits of this Setup
- Guaranteed Event Persistence: Events are first stored in your durable
events_store_tandoutbox_messagestables within a single, local, ACID transaction. This means if your application crashes before the event is published to Kafka, it’s still safe in your database and will be picked up by Debezium later. - Decoupling: Your core business logic (in
CustomerApplicationService) doesn’t directly interact with Kafka. It only interacts with the database. This makes your service more resilient to Kafka outages. - Simplified Retries: Debezium and Kafka Connect handle the complexities of retrying Kafka publication.
- Single Source of Truth: Your
events_store_tremains the authoritative event log for replay and aggregate reconstruction. - Scalability: You can scale your application service and Debezium independently.
This pattern is a fundamental building block for highly reliable, event-driven microservices.
Multiple Topics
This is a classic scenario in event-driven architectures: an event needs to trigger processing in multiple downstream systems. The key is maintaining atomicity and understanding transaction boundaries.
Given your setup where:
ScheduleCreatedEventoriginates from your service’s outbox.- Debezium pushes it to
portal-event. - Your
PortalEventConsumerreads fromportal-eventand performs database updates (likenotification_t). - The same event needs to go to be processed by the Schedule Kafka Streams.
- All operations related to processing this event should ideally be atomic.
Understanding the Transactional Challenge
Your PortalEventConsumer has a well-defined transactional boundary:
[Start DB Tx] -> [DB Updates (e.g., notification_t)] -> [DB Commit] -> [Kafka Consumer Offset Commit]
You want to add “push to light-schedule” into this atomic unit.
Options for Pushing to light-schedule
Let’s evaluate the best places:
1. NOT Recommended: Direct Kafka Producer Send within PortalEventConsumer’s DB Transaction.
- Approach: Inside the
PortalEventConsumerloop, after processingScheduleCreatedEventand beforeconn.commit(), instantiate a Kafka Producer andproducer.send()the event tolight-schedule. - Problem: This is incredibly difficult to make truly atomic across all three resources (source Kafka topic
portal-eventoffset, your database transaction, AND the target Kafka topiclight-schedule).- If
producer.send()tolight-schedulefails afterconn.commit()but beforeconsumer.commitSync(), you have an inconsistent state:notification_tis updated, butlight-scheduledidn’t get the event. The consumer will re-process, leading to duplicates innotification_t(which requires idempotency) and potential duplicates tolight-schedule. - Managing Kafka Producer transactions nested within a JDBC transaction is not standard and adds immense complexity.
- If
2. Recommended for Robustness (but more infrastructure): A Secondary Outbox Table.
- Approach:
- When
PortalEventConsumerprocessesScheduleCreatedEventfromportal-event, it updatesnotification_t(and any other DB projections) in its current DB transaction. - Within the same DB transaction, it also inserts a record (representing the
ScheduleCreatedEventforlight-schedule) into a new, dedicated outbox table (e.g.,schedule_events_outbox_t). - A second Debezium connector (or a polling publisher) then monitors
schedule_events_outbox_tand pushes events to thelight-scheduletopic.
- When
- Benefits:
- True Atomicity: The event lands in
notification_tAND is queued forlight-schedulepublishing, all within thePortalEventConsumer’s single DB transaction. This is guaranteed. - High Reliability: Leverages the proven Transactional Outbox pattern again.
- True Atomicity: The event lands in
- Drawbacks:
- Adds another outbox table to manage.
- Requires another Debezium connector instance.
- More operational overhead.
3. Most Recommended for Simplicity & Kafka Streams Integration: A Separate Kafka Streams Application.
- Approach:
- Your
PortalEventConsumercontinues to subscribe toportal-eventand performs its database updates tonotification_t(and other projections) as it currently does. It remains the sink for all events fromportal-eventinto your relational database. - Create a separate, dedicated Kafka Streams application whose sole purpose is to process scheduling events.
- This Kafka Streams application subscribes directly to the
portal-eventtopic. - It uses Kafka Streams DSL to
filterforScheduleCreatedEvents.
- Your
- Benefits:
- Clean Separation of Concerns: Your
PortalEventConsumeris a database sink. Your Kafka Streams app is a stream processor. - Kafka Streams EOS (Exactly-Once Semantics): Kafka Streams handles transactional guarantees (atomic consumption from
portal-eventand process the scheduled events natively. - Simpler Code: No complex producer/consumer/DB transaction coordination in one app.
- Scalability: Each application can scale independently.
- Clean Separation of Concerns: Your
- Drawbacks:
- Adds another logical application to deploy and manage.
Best Place to Push to light-schedule:
For your setup, the Separate Kafka Streams Application (Option 3) is generally the best approach.
- Your
PortalEventConsumer’s role: It acts as a generic projection builder into your relational database, consuming all events fromportal-eventand updatingnotification_t(and any other necessary read models). This ensures a full audit and visibility for all processed events in your DB. - The new Kafka Streams app’s role: It acts as a specialized router and processor for
ScheduleCreatedEvents specifically, forwarding them to the appropriate Kafka Streams pipeline (light-schedule).
This maintains a clean, decoupled architecture where each component has a clear responsibility and leverages Kafka’s native stream processing capabilities for atomic Kafka-to-Kafka operations.
Database Concurrency
Multiple users updating the same aggregate is a classic concurrency problem in multi-user applications, often referred to as the “lost update” problem. In an Event Sourcing system, preventing this overwrite is crucial because the sequence of events defines the state.
The standard and most effective way to prevent concurrent updates from overwriting each other in an Event Sourcing system is through Optimistic Concurrency Control (OCC), specifically using version numbers (or sequence numbers) at the aggregate level.
How Optimistic Concurrency Control (OCC) Works in Event Sourcing
-
Version Tracking (Sequence Number):
- Every Aggregate (e.g., a
Customer, anOrder, aProduct) has a version, which is typically its current sequence number in the event stream. This sequence number represents the number of events that have been applied to build its current state. - Your
events_store_ttable already hassequence_numberfor this purpose:
TheCREATE TABLE events_store_t ( id UUID PRIMARY KEY, aggregate_id VARCHAR(255) NOT NULL, -- ... other fields ... sequence_number BIGINT NOT NULL, -- This is the key! UNIQUE (aggregate_id, sequence_number) -- CRITICAL constraint! );UNIQUE (aggregate_id, sequence_number)constraint is the fundamental database-level guarantee against concurrent writes for the same aggregate at the same version.
- Every Aggregate (e.g., a
-
Load the Aggregate’s Current Version:
- When your application service wants to modify an aggregate, it first loads the aggregate’s current state by replaying all events for that
aggregate_idfrom theevents_store_t. - During this replay, it tracks the
currentSequenceNumber(the sequence number of the last event applied).
- When your application service wants to modify an aggregate, it first loads the aggregate’s current state by replaying all events for that
-
Pass Expected Version with Command:
- The user interface (UI) or the client application that initiated the change should also hold the
currentSequenceNumberit observed when it last fetched the aggregate’s state. - This
expectedVersion(orexpectedSequenceNumber) is then sent along with the command (e.g.,UpdateCustomerProfileCommand(customerId, newName, newAddress, expectedSequenceNumber)).
- The user interface (UI) or the client application that initiated the change should also hold the
-
Conditional Event Appending:
- When your
CustomerApplicationServicereceives the command:- It loads the
Customeraggregate from theevents_store_t, determining its actualcurrentSequenceNumber. - It compares the
command.expectedSequenceNumberwith thecustomer.actualCurrentSequenceNumber(derived from the Event Store). - If
command.expectedSequenceNumberdoes NOT matchcustomer.actualCurrentSequenceNumber: This means another concurrent transaction has already written new events for this aggregate since the client loaded its state. AConcurrencyException(or similar domain-specific exception) is thrown. - If they DO match: The aggregate’s business logic is applied, generating new events. These new events will have
customer.actualCurrentSequenceNumber + 1,customer.actualCurrentSequenceNumber + 2, etc.
- It loads the
- When your
-
Atomic Persistence (The DB Constraint):
- The new events are then attempted to be saved to
events_store_t(andoutbox_messages) within a single database transaction. - If a concurrency conflict was not detected at step 4 (meaning two commands arrived almost simultaneously and passed the initial check), the
UNIQUE (aggregate_id, sequence_number)constraint in theevents_store_ttable will prevent the “lost update.” Only the first transaction to successfully insert events with the “next” sequence numbers will succeed. The second will fail with aDataIntegrityViolationException(or similar).
- The new events are then attempted to be saved to
Example Flow:
- User A fetches
Customer-123. The current state (replayed fromevents_store_t) showssequenceNumber = 5. - User B also fetches
Customer-123. It also seessequenceNumber = 5. - User A sends
UpdateCustomerProfileCommand(customerId="123", newName="Alice", expectedSequenceNumber=5).- App Service loads
Customer-123, actualsequenceNumber = 5. MatchesexpectedSequenceNumber. - Generates
CustomerNameChangedevent withsequenceNumber = 6. - Attempts to save event(s) to
events_store_t(andoutbox_messages). Succeeds.
- App Service loads
- User B sends
UpdateCustomerProfileCommand(customerId="123", newAddress="456 Oak", expectedSequenceNumber=5).- App Service loads
Customer-123. It now replays events up tosequenceNumber = 6. So,actualSequenceNumber = 6. - It compares
command.expectedSequenceNumber=5withcustomer.actualSequenceNumber=6. They do NOT match! - The
CustomerApplicationServicethrows aConcurrencyException. - The transaction is rolled back, and no events are written from User B’s command.
- App Service loads
Java Implementation Changes
Let’s modify the previous CustomerApplicationService and add a way to load the aggregate from events.
1. Customer Aggregate (Revised)
// domain/Customer.java (Revised)
package com.example.eventoutbox.domain;
import com.example.eventoutbox.domain.events.CustomerAddressChanged;
import com.example.eventoutbox.domain.events.CustomerNameChanged;
import com.example.eventoutbox.domain.events.DomainEvent;
import lombok.Getter;
import java.time.Instant;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
@Getter
public class Customer {
private final String customerId;
private String name;
private String address;
private long version; // This is the 'sequenceNumber' of the LAST applied event
private final List<DomainEvent> uncommittedEvents = new ArrayList<>();
// Constructor for creating a new aggregate
public Customer(String customerId) {
this.customerId = customerId;
this.version = 0; // New aggregates start at version 0
}
// Static factory method to load an aggregate from its events
public static Customer loadFromEvents(String customerId, List<DomainEvent> history) {
Customer customer = new Customer(customerId);
history.forEach(customer::applyEvent); // Apply each historical event
return customer;
}
// Method to apply an event to the aggregate's state
private void applyEvent(DomainEvent event) {
// This is where you would update the aggregate's internal state
// based on the specific event type.
if (event instanceof CustomerNameChanged nameChanged) {
this.name = nameChanged.getNewName();
} else if (event instanceof CustomerAddressChanged addressChanged) {
this.address = addressChanged.getNewAddress();
}
this.version = event.getSequenceNumber(); // Update version to the sequence number of the applied event
}
// Domain behavior methods that generate new events
public void changeName(String newName) {
if (!newName.equals(this.name)) {
// New events get the *next* sequence number
long nextSequence = this.version + 1;
CustomerNameChanged event = new CustomerNameChanged(UUID.randomUUID(), Instant.now(), customerId, nextSequence, newName);
uncommittedEvents.add(event);
applyEvent(event); // Apply immediately to current state for consistency
}
}
public void changeAddress(String newAddress) {
if (!newAddress.equals(this.address)) {
long nextSequence = this.version + 1;
CustomerAddressChanged event = new CustomerAddressChanged(UUID.randomUUID(), Instant.now(), customerId, nextSequence, newAddress);
uncommittedEvents.add(event);
applyEvent(event);
}
}
public void markEventsCommitted() {
this.uncommittedEvents.clear();
}
}
2. ConcurrencyException
// domain/ConcurrencyException.java
package com.example.eventoutbox.domain;
public class ConcurrencyException extends RuntimeException {
public ConcurrencyException(String message) {
super(message);
}
}
3. CustomerApplicationService (Revised)
// application/CustomerApplicationService.java (Revised)
package com.example.eventoutbox.application;
import com.example.eventoutbox.domain.ConcurrencyException;
import com.example.eventoutbox.domain.Customer;
import com.example.eventoutbox.domain.events.DomainEvent;
import com.example.eventoutbox.infrastructure.persistence.eventstore.EventStoreEvent;
import com.example.eventoutbox.infrastructure.persistence.eventstore.EventStoreEventRepository;
import com.example.eventoutbox.infrastructure.persistence.outbox.OutboxMessage;
import com.example.eventoutbox.infrastructure.persistence.outbox.OutboxMessageRepository;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import lombok.RequiredArgsConstructor;
import org.springframework.dao.DataIntegrityViolationException;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.io.IOException;
import java.util.List;
import java.util.Optional;
import java.util.UUID;
import java.util.stream.Collectors;
@Service
@RequiredArgsConstructor
public class CustomerApplicationService {
private final OutboxMessageRepository outboxMessageRepository;
private final EventStoreEventRepository eventStoreEventRepository;
private final ObjectMapper objectMapper;
// Command now includes expectedVersion
public record UpdateCustomerProfileCommand(String customerId, String newName, String newAddress, long expectedVersion) {}
@Transactional
public void updateCustomerProfile(UpdateCustomerProfileCommand command) {
// --- 1. Load Aggregate State ---
List<EventStoreEvent> historicalEvents = eventStoreEventRepository.findByAggregateIdOrderBySequenceNumberAsc(command.customerId());
Customer customer;
if (historicalEvents.isEmpty()) {
customer = new Customer(command.customerId());
// If it's a new aggregate, expectedVersion must be 0
if (command.expectedVersion() != 0) {
throw new ConcurrencyException("Customer with ID " + command.customerId() + " does not exist or expected version is incorrect.");
}
} else {
// Deserialize historical events to DomainEvent objects
List<DomainEvent> domainEventsHistory = historicalEvents.stream()
.map(this::deserializeEventStoreEvent)
.collect(Collectors.toList());
customer = Customer.loadFromEvents(command.customerId(), domainEventsHistory);
// --- 2. OPTIMISTIC CONCURRENCY CHECK ---
if (customer.getVersion() != command.expectedVersion()) {
throw new ConcurrencyException(
"Customer with ID " + command.customerId() + " has been updated by another user. " +
"Expected version " + command.expectedVersion() + " but found " + customer.getVersion() + "."
);
}
}
// --- 3. Apply Business Logic & Generate Events ---
if (command.newName() != null) {
customer.changeName(command.newName());
}
if (command.newAddress() != null) {
customer.changeAddress(command.newAddress());
}
// --- 4. Persist Events to Event Store & Outbox (Atomically) ---
List<DomainEvent> eventsToStore = customer.getUncommittedEvents();
if (eventsToStore.isEmpty()) {
return; // No changes, no events to publish
}
try {
List<EventStoreEvent> eventStoreEntities = eventsToStore.stream()
.map(this::mapToEventStoreEvent)
.collect(Collectors.toList());
eventStoreEventRepository.saveAll(eventStoreEntities);
List<OutboxMessage> outboxMessages = eventsToStore.stream()
.map(this::mapToOutboxMessage)
.collect(Collectors.toList());
outboxMessageRepository.saveAll(outboxMessages);
customer.markEventsCommitted();
} catch (DataIntegrityViolationException e) {
// This catches the UNIQUE constraint violation on (aggregate_id, sequence_number)
// This means another transaction has just written to this aggregate
throw new ConcurrencyException(
"Another concurrent update detected for customer " + command.customerId() + ". " +
"Please refresh and try again.", e
);
} catch (IOException e) {
throw new RuntimeException("Failed to serialize event to JSON", e);
}
}
// Helper methods for mapping/deserializing (similar to before)
private OutboxMessage mapToOutboxMessage(DomainEvent event) {
try {
return OutboxMessage.builder()
.id(event.getEventId())
.aggregateId(event.getAggregateId())
.aggregateType(event.getAggregateType())
.eventType(event.getEventType())
.timestamp(event.getTimestamp())
.payload(objectMapper.writeValueAsString(event))
.metadata(null)
.build();
} catch (JsonProcessingException e) {
throw new RuntimeException("Failed to serialize event to JSON: " + event.getEventId(), e);
}
}
private EventStoreEvent mapToEventStoreEvent(DomainEvent event) {
try {
return EventStoreEvent.builder()
.id(event.getEventId())
.aggregateId(event.getAggregateId())
.aggregateType(event.getAggregateType())
.eventType(event.getEventType())
.timestamp(event.getTimestamp())
.sequenceNumber(event.getSequenceNumber())
.payload(objectMapper.writeValueAsString(event))
.metadata(null)
.build();
} catch (JsonProcessingException e) {
throw new RuntimeException("Failed to serialize event to JSON: " + event.getEventId(), e);
}
}
private DomainEvent deserializeEventStoreEvent(EventStoreEvent eventStoreEvent) {
try {
// Assuming your event JSON includes the 'eventType' field for polymorphic deserialization
return objectMapper.readValue(eventStoreEvent.getPayload(), DomainEvent.class);
} catch (JsonProcessingException e) {
throw new RuntimeException("Failed to deserialize event: " + eventStoreEvent.getId(), e);
}
}
}
4. EventStoreEventRepository (Add find method)
// infrastructure/persistence/eventstore/EventStoreEventRepository.java (Revised)
package com.example.eventoutbox.infrastructure.persistence.eventstore;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.List;
import java.util.UUID;
public interface EventStoreEventRepository extends JpaRepository<EventStoreEvent, UUID> {
List<EventStoreEvent> findByAggregateIdOrderBySequenceNumberAsc(String aggregateId);
}
5. CustomerController (Handle Exception)
// application/CustomerController.java (Revised)
package com.example.eventoutbox.application;
import com.example.eventoutbox.domain.ConcurrencyException;
import lombok.RequiredArgsConstructor;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/customers")
@RequiredArgsConstructor
public class CustomerController {
private final CustomerApplicationService customerApplicationService;
public record UpdateCustomerProfileRequest(String customerId, String newName, String newAddress, long expectedVersion) {}
@PostMapping("/profile")
public ResponseEntity<String> updateCustomerProfile(@RequestBody UpdateCustomerProfileRequest request) {
CustomerApplicationService.UpdateCustomerProfileCommand command =
new CustomerApplicationService.UpdateCustomerProfileCommand(
request.customerId(), request.newName(), request.newAddress(), request.expectedVersion()
);
customerApplicationService.updateCustomerProfile(command);
return ResponseEntity.ok("Customer profile update command received and processed.");
}
@ExceptionHandler(ConcurrencyException.class)
public ResponseEntity<String> handleConcurrencyException(ConcurrencyException ex) {
return ResponseEntity.status(HttpStatus.CONFLICT).body(ex.getMessage());
}
}
How to Handle Concurrency Conflicts on the Client/UI Side:
When ConcurrencyException is thrown:
- Inform the User: Display a message like “This item has been updated by another user. Please refresh the page to see the latest changes and try your update again.”
- Retry (less common for user-facing, but possible for background jobs): For non-interactive or automated processes, you might implement a retry mechanism. This retry would need to:
- Fetch the latest state of the aggregate from a read model.
- Re-create the command based on the original intent and the newly fetched expected version.
- Re-send the command.
- This is typically only done if the change is “safe” to re-apply (e.g., adding an item, not changing a specific value).
By combining the version check in your application service with the UNIQUE constraint in your database, you create a robust optimistic concurrency control mechanism that prevents lost updates effectively.
What if event consumer fails to apply an event to its read model
In this case, the read model becomes stale, and subsequent attempts to update based on that stale data will lead to conflicts.
Let’s break down the scenario and the robust solution.
The Problem Scenario (as you described)
- UI: Queries
entity_ttable (read model), getsEntity (aggregate_version = 5). - User: Makes changes.
- UI: Sends
UpdateCommand (..., expectedVersion = 5)to the write model. - Write Model (Command Handler):
- Loads aggregate from
event_store_t. Let’s say itsactualVersionis5. - OCC Check:
actualVersion (5) == expectedVersion (5). Success. - Generates
Event (..., sequence_number = 6). - Persists
Event (..., sequence_number = 6)toevent_store_tandoutbox_message_tin an ACID transaction. This commits version 6 to theevent_store_t. - Debezium publishes this event to Kafka.
- Loads aggregate from
- Kafka Consumer (PortalEventConsumer):
- Reads
Event (..., sequence_number = 6, expectedVersion = 5). - Tries to update
entity_t(your read model):UPDATE entity_t SET ..., aggregate_version = 6 WHERE entity_id = ? AND aggregate_version = 5. - FAILURE: An exception occurs in the database update (e.g., a network error, a constraint violation unrelated to
aggregate_version, or the consumer’s JVM crashes). - Result: The
entity_ttable is NOT updated and remains ataggregate_version = 5. Theevent_store_tis ataggregate_version = 6. The read model is now stale.
- Reads
- Next UI interaction:
- UI queries
entity_tagain. It still getsEntity (aggregate_version = 5)because the read model is stale. - UI sends
UpdateCommand (..., expectedVersion = 5).
- UI queries
- Write Model (Command Handler) - Second Attempt:
- Loads aggregate from
event_store_t. ItsactualVersionis6. - OCC Check:
actualVersion (6) != expectedVersion (5). Conflict detected! - Result: The command handler throws a
ConcurrencyException. It does NOT try to insert a new event intoevent_store_twithsequence_number=6(because that would be a duplicate and would indeed fail on the unique constraint). It correctly rejects the command.
- Loads aggregate from
The specific symptom you mentioned (“new event insert into the event_store_t and it will fail because the aggregate version is used before”) should ideally not happen if the write model correctly detects OCC. The ConcurrencyException should prevent the duplicate event generation.
The core problem, then, is stale read models due to consumer processing failures, which then lead to ConcurrencyException at the write model.
The Solution: Robust Kafka Consumer Processing (Retry & DLQ)
The solution lies entirely within your Kafka Consumer’s (PortalEventConsumerStartupHook) error handling strategy.
Your most recent incremental code includes the processSingleEventWithRetries method with retry and DLQ logic. This is precisely the mechanism designed to handle this situation.
Here’s how it’s supposed to work and what you need to ensure is functioning correctly:
-
Idempotency of Read Model Updates:
- All your
dbProvider.createXxx,updateXxx,deleteXxxmethods (e.g.,updateRole,deleteRole,createRole) must be idempotent in their database effects. - For
UPDATEandDELETE,WHERE aggregate_version = expectedVersionmakes them idempotent. If the update was already applied (or a newer version is present),0 rows affectedmeans no harm done (though it might still trigger aConcurrencyExceptionwithin the consumer’sdbProvidermethods if you implement the record-not-found-vs-conflict check). - For
INSERT, useINSERT ... ON CONFLICT (primary_key) DO UPDATE SET aggregate_version = excluded.aggregate_version, ...(UPSERT) if the “create” event might be re-delivered and you expect it to update an existing record (e.g., in a snapshot table). Otherwise, if it’s strictly a “create-only” and a duplicate PK is a bug, theSQLExceptionfor unique constraint violation is correct.
- All your
-
Consumer’s Retry/DLQ Logic (The core fix): The
processSingleEventWithRetriesmethod is crucial.-
Transient Errors:
- If
dbProvider.updateXxx(or any other part ofprocessSingleEventWithRetries) throws a transientSQLException(e.g., connection timeout, deadlock), thecurrentRetryis incremented, andThread.sleepoccurs. - If
maxRetriesis not exhausted,processSingleEventWithRetrieswill returnfalse. - The
onCompletionloop will thenbreak;(meaning it won’tcommitSync()any offsets for this batch). - On the next
readRecordscall, the entire batch (including the transiently failed record) will be re-polled and re-processed. This relies on idempotency.
- If
-
Permanent Errors:
- If
dbProvider.updateXxxthrows aDbProvider.ConcurrencyException(meaning the read model’s version was stale, so theWHERE aggregate_version = expectedVersionupdate in the consumer failed with 0 rows, but the record did exist at a higher version) or anIllegalArgumentException(bad data) or a permanentSQLException(e.g., unique constraint violation on anINSERTwhere it shouldn’t happen, or foreign key constraint violation):processSingleEventWithRetrieswill catch it and callhandlePermanentFailure.handlePermanentFailuresends the original Kafka record to the DLQ.processSingleEventWithRetriesthen returnstrue(because the event has been “handled” by being DLQ’d).onCompletionthen does include this record’s offset inoffsetsToCommitand proceeds tocommitSync()for the batch.- Result: The consumer makes progress past this “poison pill.” The stale event in
entity_tis not updated by this specific event, but the consumer doesn’t get stuck.
- If
-
How to Handle the Stale UI Problem
Once the consumer’s retry/DLQ is robust, the stale UI becomes a UX problem rather than a system consistency problem.
-
Producer’s
ConcurrencyExceptionis Key: When the UI sendsUpdateCommand(..., expectedVersion = 5)and theevent_store_tis already at version 6, the write model will throwConcurrencyException. This is the correct behavior. -
UI Response to
ConcurrencyException:- The UI must catch this
ConcurrencyExceptionfrom the API. - It should display a clear message to the user: “This record has been updated by another user. Please refresh the page to see the latest changes and re-apply your modifications if desired.”
- It should then trigger a refresh of the data from the read model, which will then fetch
Entity (aggregate_version = 6)(assuming the consumer eventually caught up or the record was DLQ’d and a manual fix was applied).
- The UI must catch this
Summary and What to Focus On:
- Ensure
processSingleEventWithRetriesis fully correct and deployed. This is your primary defense against the consumer getting stuck. - Carefully verify the
isTransientSqlErrorlogic. It must accurately identify only recoverable database errors. Misclassifying permanent errors as transient will exhaust retries and then DLQ; misclassifying transient as permanent sends to DLQ too soon. - Confirm
handlePermanentFailurecorrectly sends to DLQ and logs. - Confirm your
dbProvidermethods are truly idempotent for re-delivered messages.UPDATE ... WHERE aggregate_version = expectedVersionis idempotent.INSERTs are trickier. - Educate your UI/API layer: They must handle the
ConcurrencyExceptionfrom the write model by forcing a refresh and user notification.
Your recent changes to PortalEventConsumerStartupHook already implement this retry/DLQ pattern. The next step is to ensure that code is compilable, deployed correctly, and that the dbProvider methods are fully integrated with the aggregate_version for idempotency and OCC checking as discussed in the previous detailed answer.
What if DLQ messages are not handled in a timely fashion
This is a critical operational risk with the Dead Letter Queue (DLQ) pattern: DLQ messages are “handled exceptions,” not “disappearing problems.” If they aren’t processed, they represent real, unapplied business facts that can lead to data inconsistencies and broken business processes over time.
If a message sits in the DLQ for 30 days, your read models will be stale, your UIs will report incorrect data, and downstream systems relying on that information will also be out of sync. This can severely damage data integrity and user trust.
The DLQ is a “Hospital” or “Quarantine Zone,” Not a “Graveyard”
It’s a place for messages that need human intervention or a specific, non-automated re-driving process. It’s not a place for messages to just die.
Strategies to Prevent DLQ Message Stagnation
To ensure DLQ messages are handled in a timely fashion, you need a robust DLQ management strategy that goes beyond just pushing messages to the topic.
1. Robust Monitoring & Alerting (Immediate Action)
- Metric: Count of messages in DLQ topics (
kafka_topic_partition_current_offset,kafka_consumer_group_lag, or custom JMX metrics). - Alerting Thresholds:
- Urgent: Alert immediately (PagerDuty, Slack, SMS) if the number of messages in any DLQ topic goes above 0 or a very small threshold (e.g., 5-10 messages). A DLQ is an exceptional queue.
- Warning: Alert if messages persist for a certain duration (e.g., 1 hour, 4 hours).
- Dashboards: Create a dashboard that prominently displays the number of messages in each DLQ topic and their age.
2. Clear Ownership & Standard Operating Procedures (SOPs)
- Who owns the DLQ? Assign clear responsibility to a specific team (e.g., SRE, Development team for that microservice).
- What’s the process? Define a clear SOP for handling DLQ alerts:
- Acknowledge alert.
- Inspect the DLQ message content (payload, error message, original topic/offset).
- Identify the root cause (code bug, malformed data, transient external system outage, business process error).
- Decide on action:
- Fix Code/Data: If it’s a bug, deploy a fix. If it’s bad data, decide if it needs manual correction in the database or if upstream data entry needs fixing.
- Re-drive: After fixing the root cause, re-drive the message(s) back to the original topic.
- Discard (Rare & Documented): Only if the message is truly unrecoverable garbage or a test message that accidentally ended up there, and its impact is negligible. This decision must be audited and requires strong justification.
3. Automated DLQ Re-driving with Human Trigger (Operational Playbook)
- You’ll need a “re-driver” tool/application.
- Purpose: This tool reads messages from the DLQ, and publishes them back to their original topic for re-processing.
- Features:
- Preview: Show content of DLQ messages before re-driving.
- Selectivity: Allow re-driving specific messages, or ranges of messages.
- Filtering: Filter by error type, timestamp, etc.
- Audit: Log who re-drove what message.
- Integration:
- Could be a simple command-line tool.
- Could be integrated into your internal developer portal or ops dashboard.
- Could be a scheduled job that runs periodically but requires explicit human approval before actually publishing.
4. Automated Retries (Beyond Initial Consumer)
For certain classes of “permanent-but-maybe-not-really” errors (e.g., external API rate limits, very long-running external process), you could have a separate, simpler consumer that specifically subscribes to the DLQ.
- Purpose: This DLQ consumer would only handle a very specific, narrow class of DLQ messages.
- Logic: It would apply its own retry logic (e.g., exponential backoff for a longer period, up to 24 hours).
- Re-DLQ: If this DLQ consumer also fails after its retries, it would push the message back to the same DLQ topic (or a different, truly “unresolvable” DLQ) to re-trigger human intervention.
- Caution: This adds complexity and should only be done for errors you’ve explicitly identified as potentially auto-recoverable over a very long time.
5. Data Reconciliation (Long-Term Strategy)
- For critical business data, even with DLQs, sometimes manual reconciliation or a dedicated reconciliation service might be needed.
- This involves periodically comparing your read model state with the authoritative Event Store (or an authoritative external system) to detect and resolve discrepancies that might have slipped through.
Addressing “Most errors cannot be recovered anyway”
If “most errors cannot be recovered anyway” and always lead to DLQ, it points to a need for:
- Better
isTransientSqlErrorlogic: Are you correctly identifying all transient SQL errors that could be retried by the main consumer? - More robust validation upstream: Can you prevent more malformed/invalid data from even generating events that will fail downstream? (E.g., more validation in the command handler).
- Refined Domain Model/Business Rules: Sometimes, a “permanent” error in the consumer points to a business rule that isn’t fully handled by events, or a valid state transition that wasn’t expected.
DLQs are not a substitute for preventing errors, but they are essential for graceful failure and ensuring eventual consistency. Their effectiveness hinges entirely on the operational discipline and tooling around them.
How to handle the scenario that it takes weeks or even months to fix a bug and get it deployed
This is an issue regarding a major reality of enterprise software: deployment cycles can be slow, and manual intervention for DLQs simply isn’t scalable for a continuous stream of errors. This is precisely why a purely “human-in-the-loop” DLQ management strategy breaks down in a corporate context with persistent bugs.
To handle a bug that takes weeks/months to deploy, you need a strategy that focuses on containment, bypass, and eventually, reconciliation.
Strategy for Long-Deployment-Cycle Bugs (Weeks/Months)
The goal is to stop the errors from piling up indefinitely in the DLQ, and to allow the rest of the system to continue processing, even if some data is temporarily inconsistent.
1. Immediate Containment: Filtering or Skipping “Poison Pill” Messages
-
Implement a “Hot Fix” Filter (Code-based or SMT-based):
- In your Kafka Consumer (
PortalEventConsumerStartupHook): If you identify a bug where a specific type of event (or event with specific data) consistently causes failures:- Add a temporary code filter. For instance, if
ScheduleCreatedEventwithnulluserIdis causingNullPointerException, add:if (eventType.equals(PortalConstants.SCHEDULE_CREATED_EVENT) && eventMap.get("userId") == null) { logger.warn("Skipping known bug event type {} for record {} due to null userId. Not processing.", eventType, record.offset()); handlePermanentFailure(record, "Known bug: null userId for " + eventType, "KnownBugSkip"); return true; // Mark as handled (DLQ'd), commit offset, move on. } - If the bug is in a specific
dbProvidermethod: You can wrap that call in a try-catch forPermanentProcessingExceptionspecifically for that event type, and if it’s the known bug, send it to DLQ and commit.
- Add a temporary code filter. For instance, if
- Using Kafka Connect SMT (if source is Kafka Connect): You could implement a custom
FilterSMT that drops/routes specific problematic messages before they even hit your consumer app. This requires deploying a new SMT, but it can be faster than an app deployment.
- In your Kafka Consumer (
-
Why: This immediately stops the DLQ from growing uncontrollably with known bad messages. It sacrifices processing that specific message but ensures the consumer stays healthy.
2. Automated (Limited) Re-driving for Transient/Known Issues (Or Triage)
- “Error Triage” Consumer: Instead of just sending to a single DLQ, consider a dedicated consumer that subscribes to your main DLQ topic.
- This consumer acts as an automated triage.
- It checks the
errorType(fromhandlePermanentFailure’s metadata). - If
errorTypeis “TransientSqlError” or “RetriesExhausted” (but could eventually succeed): It re-publishes the original message back to theportal-eventtopic with an exponential backoff. It might implement its own max retries (e.g., 50 retries over 24 hours). If it still fails, then it pushes to a “Final DLQ” that truly requires manual intervention. - If
errorTypeis “ConcurrencyConflict”, “DataValidationError”, “UnhandledEventType”, or “KnownBugSkip”: It pushes to a separate “Permanent DLQ” topic. This queue is smaller and truly requires human eyes.
- Why: This handles messages that might eventually self-resolve or that you know can’t be fixed by immediate retries but aren’t necessarily “dead forever.” It reduces the volume of messages requiring immediate human attention.
3. Manual Intervention for “Permanent DLQ” / Complex Bugs (When Devs Get Involved)
- The “Permanent DLQ” is where true bugs/bad data sit.
- The same monitoring and alerting from before applies, but now it’s for a much smaller, higher-priority queue.
- Developers must actively:
- Analyze: What exactly caused this? Why did it bypass automated retries/filters?
- Fix: Develop and deploy the bug fix.
- Reconcile/Re-drive:
- If the bug fix resolves the issue, use a re-driver tool to re-submit messages from the Permanent DLQ to the
portal-eventtopic. - If the bug resulted in data inconsistencies that can’t be fixed by re-driving (e.g., a critical business state was violated), you might need to perform a manual database correction on the affected aggregate(s) (this is the most dangerous and should be avoided if possible).
- If the bug fix resolves the issue, use a re-driver tool to re-submit messages from the Permanent DLQ to the
4. Long-Term Data Reconciliation / Auditing
- Offline Reconciliation: For critical data, implement daily/weekly batch jobs that compare the state of your read model tables with the authoritative Event Store.
- If discrepancies are found, they are reported, and a reconciliation process is triggered (either manual or automated). This ensures that even if events were missed or misapplied, data consistency is eventually achieved.
- Event Replay (When all else fails): If a significant bug causes widespread data corruption or loss of consistency, the ultimate fallback is to:
- Deploy the bug fix.
- Stop the affected read model consumer.
- Clear the affected read model tables.
- Replay all historical events from the
event_store_t(or long-retention Kafka topics) through the fixed consumer logic. This rebuilds the read model from scratch, reflecting the correct business logic. This is why Event Sourcing is so powerful.
Example Workflow with a Long-Deployment-Cycle Bug
- Bug Identified:
ScheduleCreatedEventcreates a schedule, but due to a bug in the consumer’sdbProvider.createSchedulemethod, it tries to insert a duplicate primary key ifscheduleId(aggregate ID) exists, and this causes a permanent error in the consumer. - Immediate Containment (Filter/Bypass):
- A hotfix is applied to the
PortalEventConsumerStartupHook(or a dedicated filter SMT) to recognizeScheduleCreatedEventwherescheduleIdalready exists. - For such events, it
handlePermanentFailure()the message to aportal-event-dlq-permanenttopic (or aKnownBugDLQ). This prevents the main consumer from getting stuck.
- A hotfix is applied to the
- DLQ Accumulation & Monitoring: Messages related to this bug pile up in
portal-event-dlq-permanent. Alerts are firing. - Development Fix: The development team works on a fix for
dbProvider.createSchedule(e.g., changing it to anUPSERTif a “create” event implies “idempotent create/update” or better handling of duplicate primary keys if it truly is an error). This takes weeks. - Deployment: The fix is deployed.
- Re-driving: Operations team uses the re-driver tool to:
- Read messages from
portal-event-dlq-permanent. - Publish them back to the
portal-eventtopic. - The now-fixed consumer processes them correctly.
- Read messages from
This approach balances immediate operational stability with eventual consistency, acknowledging the realities of enterprise deployment cycles.
MSAL Light OAuth Integration
Token Exchange
We have a React Single Page Application(SPA) running within a corporate network using Azure AD for SSO. However, we want to use JWT tokens from another OAuth 2.0 provider Light-OAuth to issue the token with additional custom claims for fine-grained Authorization. What is the best way to do the integration?
This is a common and powerful architectural pattern used to separate authentication from authorization, allowing you to use a central identity provider (like Azure AD) for who the user is and a specialized service for what the user can do.
The goal is to use the trusted identity established by Microsoft to “mint” a new, enriched token from your second provider.
The best and most secure way to achieve this is by using the OAuth 2.0 Token Exchange Flow (RFC 8693). This process happens on your backend, ensuring that no sensitive client secrets or complex token logic is exposed in the React SPA.
Let’s break down the architecture and the steps involved.
The Recommended Architecture: Backend-Mediated Token Exchange
In this model, your React SPA’s responsibility remains simple: authenticate the user with Microsoft and get a token. It then sends this token to your own backend API. Your backend is the one that communicates with the second OAuth provider to exchange the token.
Here is a diagram of the flow:
+-----------+ +-----------------+ +----------------+
| | (1) | | (2) | |
| React SPA |---->| Microsoft |---->| React SPA |
| | | Entra ID (MSAL)| | (has MS Token) |
+-----------+ +-----------------+ +----------------+
|
| (3) Sends MS Token to Backend
v
+-----------+ +-----------------+ +----------------+
| | (4) | | (5) | |
| Your |---->| Second OAuth |---->| Your |
| Backend | | Provider | | Backend |
| API | | (Token Exchange)| | (has New Token)|
+-----------+ +-----------------+ +----------------+
|
| (6) Establishes session / returns new token
v
+-----------+
| React SPA |
| (is now |
| authorized)|
+-----------+
Why this is the best approach:
- Security: Your second provider’s
client_idandclient_secretare kept securely on your backend, never exposed to the browser. - Separation of Concerns: The React app only worries about authenticating with Microsoft. Your backend handles the complex authorization logic.
- Flexibility: You can swap out the second authorization provider without changing your entire frontend authentication flow.
- Standard-Compliant: The Token Exchange grant type is an official standard designed for this exact “delegation” or “impersonation” scenario.
Step-by-Step Integration Guide
Here’s how to implement this pattern.
Step 1: Configure Your Second OAuth 2.0 Provider
This is the most critical setup step. You need to configure your authorization provider (e.g., Auth0, Okta, Duende IdentityServer, or a custom one) to:
- Trust Microsoft Entra ID (Azure AD) as an Identity Provider: It must be able to validate the signature of the token it receives from your backend. This usually involves pointing it to Microsoft’s OIDC discovery endpoint (
https://login.microsoftonline.com/{tenant-id}/v2.0/.well-known/openid-configuration) to get the public signing keys. - Enable the Token Exchange Grant Type: You’ll need to create a new “client” or “application” within this provider for your backend API. This client must be configured to use the
urn:ietf:params:oauth:grant-type:token-exchangegrant type. - Define a User Mapping Strategy: The provider needs to know how to link the incoming Microsoft token to a user in its own database. A common practice is to map the
oid(Object ID) orsub(Subject) claim from the Microsoft token to a user profile in the second provider. This is how it knows which fine-grained permissions (claims) to add. - Define the Custom Claims: Configure the rules that add the additional claims to the new token when the exchange is successful. For example: “If the incoming user has
oid‘123-abc’, add the claimspermissions: ['create:document', 'read:report'].”
Step 2: Update Your React SPA Logic
Your React app’s interaction with MSAL will remain largely the same, with one key difference in what you do after a successful login.
-
Authenticate and Acquire a Token: Use MSAL as you normally would to log the user in and get an access token for your own backend API.
// msalConfig.js - Make sure you have a scope for your own backend API export const msalConfig = { auth: { /* ... */ }, cache: { /* ... */ }, }; export const loginRequest = { scopes: ["User.Read", "api://<your-backend-client-id>/access_as_user"] }; -
Call Your Backend: After getting the token, instead of using it to call various protected resources, you make a single call to a dedicated endpoint on your backend (e.g.,
/auth/ms/exchange) to initiate the session.import { useMsal } from "@azure/msal-react"; import { loginRequest } from "./msalConfig"; function MyComponent() { const { instance, accounts } = useMsal(); const handleLoginAndExchange = async () => { try { // 1. Get the MSAL token for our backend const response = await instance.acquireTokenSilent({ ...loginRequest, account: accounts[0], }); const microsoftAccessToken = response.accessToken; // 2. Send it to our backend for exchange const backendResponse = await fetch('/auth/ms/exchange', { method: 'POST', headers: { 'Authorization': `Bearer ${microsoftAccessToken}`, 'Content-Type': 'application/json', }, }); if (!backendResponse.ok) { throw new Error('Token exchange failed'); } // The backend will likely set a secure HttpOnly cookie, // so there might be nothing else to do here. // Or, it might return the new token to be stored in memory. const { newAccessToken } = await backendResponse.json(); console.log("Received new, enriched token from our backend!"); // Now use this newAccessToken for subsequent API calls } catch (error) { // Handle token acquisition or exchange errors console.error(error); if (error.name === "InteractionRequiredAuthError") { instance.acquireTokenPopup(loginRequest); } } }; // ... }
Step 3: Implement the Backend Token Exchange Endpoint
This is where the core logic resides. You’ll create an endpoint that receives the Microsoft token and exchanges it.
-
Protect the Endpoint: Configure your backend to validate the
Bearertoken from Microsoft that it receives from your React app. This ensures only authenticated users from your SPA can trigger an exchange. -
Implement the Exchange Logic:
if (exchange.getRelativePath().equals(config.getExchangePath())) { // token exchange request handling. if(logger.isTraceEnabled()) logger.trace("MsalTokenExchangeHandler exchange is called."); String authHeader = exchange.getRequestHeaders().getFirst(Headers.AUTHORIZATION); if (authHeader == null || !authHeader.startsWith("Bearer ")) { setExchangeStatus(exchange, JWT_BEARER_TOKEN_MISSING); return; } String microsoftToken = authHeader.substring(7); // --- Validate the incoming Microsoft Token --- if(msalJwtVerifier == null) { // handle case where config failed to load throw new Exception("MsalJwtVerifier is not initialized."); } try { // We only need to verify it, we don't need the claims for much. // The second provider will do its own validation and claim mapping. // Set skipAudienceVerification to true if the 'aud' doesn't match this BFF's client ID. String reqPath = exchange.getRequestPath(); msalJwtVerifier.verifyJwt(microsoftToken, msalSecurityConfig.isIgnoreJwtExpiry(), true, null, reqPath, null); } catch (InvalidJwtException e) { logger.error("Microsoft token validation failed.", e); setExchangeStatus(exchange, INVALID_AUTH_TOKEN, e.getMessage()); return; } // --- Perform Token Exchange --- String csrf = UuidUtil.uuidToBase64(UuidUtil.getUUID()); TokenExchangeRequest request = new TokenExchangeRequest(); request.setSubjectToken(microsoftToken); request.setSubjectTokenType("urn:ietf:params:oauth:token-type:jwt"); request.setCsrf(csrf); // The CSRF for the *new* token we are getting Result<TokenResponse> result = OauthHelper.getTokenResult(request); if (result.isFailure()) { logger.error("Token exchange failed with status: {}", result.getError()); setExchangeStatus(exchange, TOKEN_EXCHANGE_FAILED, result.getError().getDescription()); return; } // --- The setCookies logic is identical --- List<String> scopes = setCookies(exchange, result.getResult(), csrf); if(logger.isTraceEnabled()) logger.trace("scopes = {}", scopes); exchange.setStatusCode(StatusCodes.OK); exchange.getResponseHeaders().put(Headers.CONTENT_TYPE, "application/json"); // Return the scopes in the response body Map<String, Object> rs = new HashMap<>(); rs.put(SCOPES, scopes); exchange.getResponseSender().send(JsonMapper.toJson(rs)); } else if (exchange.getRelativePath().equals(config.getLogoutPath())) { // logout request handling, this is the same as StatelessAuthHandler to remove the cookies. if(logger.isTraceEnabled()) logger.trace("MsalTokenExchangeHandler logout is called."); removeCookies(exchange); exchange.endExchange(); } else { // This is the subsequent request handling after the token exchange. Here we verify the JWT in the cookies. if(logger.isTraceEnabled()) logger.trace("MsalTokenExchangeHandler is called for subsequent request."); String jwt = null; Cookie cookie = exchange.getRequestCookie(ACCESS_TOKEN); if(cookie != null) { jwt = cookie.getValue(); // verify the jwt with the internal verifier, the token is from the light-oauth token exchange. JwtClaims claims = internalJwtVerifier.verifyJwt(jwt, securityConfig.isIgnoreJwtExpiry(), true); String jwtCsrf = claims.getStringClaimValue(Constants.CSRF); // get csrf token from the header. Return error is it doesn't exist. String headerCsrf = exchange.getRequestHeaders().getFirst(HttpStringConstants.CSRF_TOKEN); if(headerCsrf == null || headerCsrf.trim().length() == 0) { setExchangeStatus(exchange, CSRF_HEADER_MISSING); return; } // verify csrf from jwt token in httpOnly cookie if(jwtCsrf == null || jwtCsrf.trim().length() == 0) { setExchangeStatus(exchange, CSRF_TOKEN_MISSING_IN_JWT); return; } if(logger.isDebugEnabled()) logger.debug("headerCsrf = " + headerCsrf + " jwtCsrf = " + jwtCsrf); if(!headerCsrf.equals(jwtCsrf)) { setExchangeStatus(exchange, HEADER_CSRF_JWT_CSRF_NOT_MATCH, headerCsrf, jwtCsrf); return; } // renew the token 1.5 minute before it is expired to keep the session if the user is still using it // regardless the refreshToken is long term remember me or not. The private message API access repeatedly // per minute will make the session continue until the browser tab is closed. if(claims.getExpirationTime().getValueInMillis() - System.currentTimeMillis() < 90000) { jwt = renewToken(exchange, exchange.getRequestCookie(REFRESH_TOKEN)); } } else { // renew the token and set the cookies jwt = renewToken(exchange, exchange.getRequestCookie(REFRESH_TOKEN)); } if(logger.isTraceEnabled()) logger.trace("jwt = " + jwt); if(jwt != null) exchange.getRequestHeaders().put(Headers.AUTHORIZATION, "Bearer " + jwt); // if there is no jwt and refresh token available in the cookies, the user not logged in or // the session is expired. Or the endpoint that is trying to access doesn't need a token // for example, in the light-portal command side, createUser doesn't need a token. let it go // to the service and an error will be back if the service does require a token. // don't call the next handler if the exchange is completed in renewToken when error occurs. if(!exchange.isComplete()) Handler.next(exchange, next); }
What to Avoid: The Anti-Pattern
Do not try to perform two separate, chained OAuth flows in the frontend. This would involve:
- User logs in with MSAL.
- Your React app gets the MSAL token.
- Your React app then initiates a second redirect or popup flow with the other provider, trying to pass the MSAL token as a parameter.
This is a bad idea because:
- Terrible User Experience: It can lead to multiple redirects, popups, and a confusing login process.
- Security Risk: It increases the surface area for token handling in the browser and might require you to use less secure flows (like Implicit flow) on the second provider.
- Complexity: Managing the state of two independent authentication libraries and their tokens in a SPA is extremely difficult and error-prone.
Client Secret
Token exchange specification doesn’t require client_id and client_secret to be sent to the second OAuth 2.0 provider to exchage the token. However, it is highly recommended to pass the client_id and client_secret from the BFF to the second OAuth 2.0 provider. The subject token along is not sufficient.
This is a critical security aspect of the Token Exchange flow. Let’s break down why.
The “Two Questions” Security Model
When your BFF makes the token exchange request, the second OAuth provider needs to answer two fundamental security questions:
-
WHO IS THE USER? (Authentication of the Subject)
- This question is answered by the
subject_token(the Microsoft token). - The provider validates the token’s signature, issuer (
iss), expiration (exp), and audience (aud) to confirm that it’s a legitimate token for a valid user from a trusted identity provider (Microsoft).
- This question is answered by the
-
WHO IS ASKING FOR THIS TOKEN? (Authentication of the Client)
- This question is answered by the
client_idandclient_secret. - This is crucial. The provider needs to know which application is requesting to act on the user’s behalf. It’s not enough that the user is valid; the application making the request must also be a known, trusted, and authorized client.
- This question is answered by the
Why the Subject Token Alone is a Security Risk
Imagine if only the subject_token were required. Any malicious actor or compromised service that managed to get a user’s Microsoft access token could then send it to your second OAuth provider and exchange it for a new token containing your fine-grained authorization claims. This would allow them to impersonate the user within your system completely.
By requiring the client_id and client_secret, you ensure that only your specific, trusted BFF application is allowed to perform this exchange. The client_secret is the proof that the request is coming from your backend and not some other application.
The Token Exchange Request Body
So, the POST request your MsalTokenExchangeHandler (the BFF) sends to your second provider’s token endpoint will be application/x-www-form-urlencoded and must look like this:
grant_type=urn:ietf:params:oauth:grant-type:token-exchange
&client_id=YOUR_BFFS_CLIENT_ID_FOR_THE_SECOND_PROVIDER
&client_secret=YOUR_BFFS_CLIENT_SECRET
&subject_token=THE_MICROSOFT_ACCESS_TOKEN_FROM_THE_SPA
&subject_token_type=urn:ietf:params:oauth:token-type:access_token
&scope=permissions_for_the_new_token
Configuration Checklist for your Second OAuth Provider
This means that on your second OAuth 2.0 provider, you must:
- Create a Client Registration: Create a new “Application” or “Client” specifically for your
light-gatewayBFF. - Set Client Type: Configure this client as a Confidential Client (as opposed to a Public Client like a SPA), because it is capable of securely storing a secret.
- Generate Credentials: Generate a
client_idand aclient_secretfor this BFF client. - Enable Grant Type: Explicitly enable the
urn:ietf:params:oauth:grant-type:token-exchangegrant type for this specific client. Your provider’s security policy should only allow trusted, confidential clients to use this powerful grant type. - Store Credentials Securely: Store the generated
client_idandclient_secretsecurely in your BFF’s configuration (e.g., insecret.ymlor environment variables), where they are not exposed to the outside world.
In short:
- The
subject_tokenproves who the user is. - The
client_idandclient_secretprove who your BFF is.
Both are required for a secure delegation and token exchange process.
Token Verification
It is necessary to verify the jwt token from Azure AD on both BFF and light-oauth based on the “Zero Trust” principle. They perform the validation for different, but equally important, reasons.
Skipping the validation on the BFF, while technically possible, is a significant security anti-pattern. Let’s break down the distinct roles of each validation step.
1. The BFF’s Responsibility: “Am I Talking to a Legitimate Client?”
The validation performed by your MsalTokenExchangeHandler in the BFF serves as a gatekeeper for your own system. Its purpose is to protect the BFF itself and the downstream services it communicates with.
When the BFF validates the Microsoft token, it’s asking these questions:
- Is this token even real? (Signature validation).
- Is it from an identity provider I trust? (Checking the
issor “issuer” claim is fromlogin.microsoftonline.com/...). - Is this token actually meant for me? (This is CRITICAL). The BFF must check the
audor “audience” claim. Theaudshould be the Client ID of your BFF application. This prevents a token that was issued for another API (like the Microsoft Graph API) from being replayed against your BFF to trick it. This is a defense against the “confused deputy” problem. - Has it expired? (Checking the
expor “expiration” claim).
Why this is crucial for the BFF:
- Fail Fast: You immediately reject invalid, expired, or improperly targeted tokens. This is a better user experience and saves system resources.
- Denial-of-Service (DoS) Protection: If you don’t validate, your BFF becomes a dumb proxy that forwards every piece of junk it receives to your second OAuth provider. An attacker could flood your BFF with garbage tokens, causing it to swamp your authorization server with useless validation and exchange requests, potentially taking it down.
- Security Boundary: The BFF is the first line of defense. It should never blindly trust any input it receives from the public internet, even from your own SPA.
2. The Second OAuth Provider’s Responsibility: “Can I Issue a New Token for this Subject?”
The validation performed by the second OAuth provider is the authoritative act of delegation. It’s the ultimate source of truth for the new, enriched token. It cannot and must not trust that the BFF has already performed a valid check.
When the second OAuth provider receives the subject_token, it asks all the same questions as the BFF, but for its own security policy:
- Is this token real and from a trusted issuer? (Signature and
issvalidation). It must have Microsoft configured as a trusted external identity provider. - Is this token meant for a client that is allowed to exchange it? (It might check the
audclaim). - Is the client making the request (the BFF) authorized to perform a token exchange? (This is validated via the
client_idandclient_secretyou send in the request). - How do I map this external user to an internal user? (This is the most important unique step). It will inspect the
oid,sub,email, or another claim from the Microsoft token to find the corresponding user in its own database. - What new claims should I issue for this user? Based on the mapped internal user, it will apply its authorization rules to mint the new token with fine-grained permissions.
Analogy: A High-Security Building
Think of it like this:
- The React SPA is you, the visitor.
- The Microsoft Token is your government-issued driver’s license.
- The BFF is the receptionist at the front desk of the building. They look at your driver’s license (
BFF validation) to make sure it’s not expired and that your name is on the visitor list for that day (audcheck). They protect the building from random people just walking in. - The Second OAuth Provider is the guard in front of the secure vault on the 10th floor. When you get to the 10th floor, the guard doesn’t just say, “Oh, the receptionist let you in, so you must be fine.” No, they perform their own, more thorough check of your driver’s license (
OAuth provider validation), check their specific access logs (user mapping), and then issue you a special keycard (new enriched token) that only opens the specific safety deposit box you’re allowed to access (fine-grained claims).
You wouldn’t want a security system where the vault guard blindly trusts the front desk. Each layer must perform its own validation.
Conclusion
Do not skip the validation on the BFF.
- Verify on the BFF to protect your own application, fail fast, and prevent it from becoming a DoS vector.
- The Second OAuth Provider MUST verify as its core function to securely map the user and issue an authoritative, enriched token.
The verifications are not redundant; they are a fundamental part of a layered, defense-in-depth security strategy.
Single Page Application
There are two endpoints that the SPA should access for both token exchange and logout.
Login
After the SSO with Azure AD via SSO, you need to send this ID token to the backend API endpoint “/auth/ms/exchange” to establish the session with a GET request. The header is the standard authorization header with “Bearer IdToken”. You will receive a response in JSON with a list of scopes that is represent the access permission. You can display them to the user for consent or simply ignore them. Along with the response body, some cookies will be set on the browser local storage to establish the session. Once the login is done, the backend will automatically renew the access token with a refresh token automatically as long as the user sending the request to the server.
Logout
To logout, you need to logout from the Azure AD and then send a GET request to the backend API endpoint “/auth/ms/logout” to remove session cookies.
User Registration and Onboarding
In light-portal, user management is the foundation of the authentication and authorization to access different services.
There are two different apporaches to create an user entry in the system: Internet and Corporation.
Internet User
This is for Internet users to register and verify via email to a cloud Light Portal instance.
The entry point is the createUser command handle in the user-command service.
Corporation User
This is for corporation users to onboard to a dedicated Intranet Light Portal instance.
The entry point is the onboardUser command handler in the user-comand service.
User Password
In the user_t table, the password is nullable and onboardUser doesn’t have password passed in as the authentication is done through Azure AD and ECIF etc.
Optimistic vs Pessimistic UI
When you create, update, delete an entity on the UI and refresh the list immediately, chances are the newly updated entity doesn’t show up the changes. This is a classic challenge when working with systems that use Event Sourcing and CQRS (Command Query Responsibility Segregation).
- Command: Your
deleteHostrequest is a Command. It’s sent to the write-model to change the state of the system and publish an event (e.g.,HostDeletedEvent). - Query: Your
fetchDatarequest is a Query. It reads from a separate read-model (thehostsdatabase view/table). - Eventual Consistency: There is a delay (usually milliseconds, but it can vary) between the command succeeding and the event consumer updating the read-model.
Your UI is so fast that it’s sending the Query before the read-model has been updated, leading to the stale data problem.
Should we wait a few seconds?
No, please do not use a setTimeout to wait. This is the most important takeaway. It’s an unreliable “magic number” that will cause problems:
- Bad UX: It forces the user to wait for an arbitrary amount of time, even if the system is fast.
- Unreliable: If the system is under heavy load, the delay might be longer than your timeout, and the bug will reappear.
- It’s a “code smell”: It indicates that the UI isn’t correctly handling the nature of the backend architecture.
The Professional Solutions
There are two primary, robust patterns for handling this on the UI. The best choice depends on the desired user experience.
Option 1: Optimistic UI (Recommended for Best UX)
This is the most common and user-friendly approach in modern web applications. You assume the command will succeed and update the UI immediately.
How it works:
- User clicks “Delete”.
- You immediately remove the item from your local React state. The user sees the item disappear instantly.
- You send the
deleteHostcommand to the server in the background. - Crucially: If the command fails for some reason (e.g., validation error, server down), you revert the UI change (add the item back) and show an error message.
This provides the best possible user experience because the UI feels instantaneous.
Here is how you would implement this in your handleDelete function:
// Delete handler - OPTIMISTIC UI APPROACH
const handleDelete = useCallback(async (row: MRT_Row<HostType>) => {
if (!window.confirm(`Are you sure you want to delete host: ${row.original.subDomain}?`)) {
return;
}
// Keep a copy of the current data in case we need to roll back
const originalData = [...data];
// 1. Optimistically update the UI
setData(prevData => prevData.filter(host => host.hostId !== row.original.hostId));
setRowCount(prev => prev - 1); // Also optimistically update the total count
// 2. Send the command to the server
const cmd = {
host: 'lightapi.net',
service: 'host',
action: 'deleteHost',
version: '0.1.0',
data: { hostId: row.original.hostId, aggregateVersion: row.original.aggregateVersion },
};
try {
const result = await apiPost({ url: '/portal/command', headers: {}, body: cmd });
if (result.error) {
// 3a. On failure, revert the UI and show an error
console.error('API Error on delete:', result.error);
alert('Failed to delete host. Please try again.'); // Or use a snackbar
setData(originalData);
setRowCount(originalData.length); // Revert the count
}
// 3b. On success, do nothing! The UI is already correct.
// You could trigger a silent background refetch here if you want to be 100% in sync, but it's often not necessary.
} catch (e) {
// Also handle network errors
console.error('Network Error on delete:', e);
alert('Failed to delete host due to a network error.');
setData(originalData);
setRowCount(originalData.length);
}
}, [data]); // The main dependency is the 'data' for rollback.
Option 2: Pessimistic UI with State Locking (Simpler, Good UX)
This approach is more straightforward. You “lock” the UI in a loading state until you are certain the operation is complete.
How it works:
- User clicks “Delete”.
- You show a loading spinner on that specific row or disable the whole table.
- Send the
deleteHostcommand. - When the command API call returns a success, you then call
fetchData()to get the fresh data. Because the command has completed, it’s much more likely the read model is now consistent. This is essentially what you were trying to do before.
The problem, as you noted, is that even after the command returns, the read model might still not be updated. The optimistic approach neatly sidesteps this entire timing issue. If you must stick to a pessimistic approach, the Optimistic UI is still the superior and often easier pattern to implement correctly.
To fix your current pessimistic implementation, you’d have to implement polling, which is complex:
- Send delete command.
- On success, start a
setIntervalto callfetchDataevery 2 seconds. - In each
fetchDataresponse, check if the deleted item is gone. - If it is,
clearIntervaland stop. - Add a timeout to stop polling after ~10-15 seconds to prevent infinite loops.
As you can see, this is much more complicated than the optimistic update.
Recommendation
Adopt the Optimistic UI pattern (Option 1). It provides the best user experience, is resilient to timing issues caused by eventual consistency, and the implementation is clean and modern. The code provided for the optimistic handleDelete is a drop-in replacement that will solve your problem robustly.
Should you poll peroidically to sync other users’ changes
The short answer is: No, you should still avoid client-side polling for this specific use case. It’s generally the wrong tool for this problem and creates more issues than it solves. The Optimistic UI approach is still preferable, but it needs to be combined with a robust backend and potentially other real-time technologies for a complete solution.
Let’s break down why and explore the professional-grade solutions.
Why Polling is a Bad Fit Here
Your concern is valid: polling does add significant pressure, and it’s inefficient.
- High Network Traffic: Every active user would be sending a
getHostquery every few seconds. If you have 50 users on that page, that’s 10-25 queries per second just from this one component, most of which will return no new data. - Database and Service Layer Load: This traffic directly translates to load on your service and database. Your
SELECTquery, while indexed, still consumes resources. At scale, this can become a significant performance bottleneck. - Delayed UX: The user experience is still poor. A user makes a change and might have to wait up to
Xseconds (your polling interval) to see it reflected, which feels sluggish. - Complexity: As we discussed, managing polling logic (starting, stopping, timeouts) on the client adds complexity and potential bugs.
So, while polling can eventually get you the latest data, it’s a brute-force approach with major drawbacks.
The Professional-Grade Solutions for Multi-User Environments
The key is to shift from a “pull” model (client polling) to a “push” model (server notifies the client). This is where real-time technologies shine.
Solution 1: Optimistic UI + Server-Sent Events (SSE) or WebSockets (Best for Real-Time)
This is the gold standard for collaborative applications.
How it Works:
-
Frontend (Your Optimistic UI):
- User A deletes a host. Their UI updates instantly (optimistic update). The
deleteHostcommand is sent to the server. - User B is looking at the same list. Their screen is unchanged for now.
- User A deletes a host. Their UI updates instantly (optimistic update). The
-
Backend (The Magic):
- The command handler processes the
deleteHostcommand and publishes aHostDeletedEvent. - An Event Notifier Service listens for this event.
- Upon receiving the event, this service pushes a notification to all connected clients who are interested in
hostupdates. This is done via Server-Sent Events (SSE) or WebSockets. SSE is often simpler for server-to-client-only communication.
- The command handler processes the
-
Frontend (Receiving the Push):
- User B’s browser receives the
HostDeletedEventpush notification. - The React component’s event listener fires. It can do one of two things:
- A) Smart Update (Ideal): The event payload contains the
hostIdthat was deleted. The client simply finds that ID in its localdatastate and removes it. This is hyper-efficient. - B) Refetch (Simpler): Upon receiving any host-related event, the client triggers a
fetchData()call to get the latest list. This is less efficient than a smart update but still vastly better than polling.
- A) Smart Update (Ideal): The event payload contains the
- User A’s browser also receives the event. It can simply ignore it, as its UI is already up-to-date.
- User B’s browser receives the
Why this is the best solution:
- Real-Time: Updates are pushed instantly to all users.
- Hyper-Efficient: No unnecessary network requests. The server and client only communicate when there’s an actual state change.
- Scalable: A single event from the backend can update thousands of connected clients simultaneously.
- Excellent UX: The application feels alive and collaborative.
Solution 2: Optimistic UI + Stale-While-Revalidate (SWR) / react-query with Refetch-on-Focus
This is a powerful and very easy-to-implement pattern that offers a great “80% solution” without needing a full real-time backend setup. Libraries like react-query (now TanStack Query) or Vercel’s swr are built for this.
How it Works:
- You replace your manual
useState/useEffect/fetchDatalogic with theuseQueryhook fromreact-query. - User A deletes a host. You perform an optimistic update using the library’s built-in tools.
- User B is looking at the list. Nothing happens yet.
- Now, User B switches from another browser tab back to your application tab.
react-queryautomatically detects this “window focus” event and triggers a background refetch of the data.- The UI is seamlessly updated with the latest data (showing User A’s deletion).
Why this is a great solution:
- Extremely Simple to Implement: You get this behavior for free just by using the library.
- “Good Enough” Real-Time: Data is refreshed exactly when the user is most likely to need it (when they re-engage with the app).
- Efficient: Avoids constant polling. It only refetches on specific, user-driven events (window focus, network reconnect, etc.).
- Handles Caching, Loading States, etc.: These libraries solve many data-fetching headaches for you.
Recommendation & Path Forward
-
Immediate Step: Stick with the Optimistic UI approach from my previous answer. It correctly handles the single-user eventual consistency problem, which is your most pressing issue. It’s the foundation for everything else.
-
Next Step (Highly Recommended): Introduce a data-fetching library like TanStack Query (
react-query). This will simplify your code and give you the “refetch-on-focus” behavior out of the box, largely solving the multi-user problem with minimal effort. -
Long-Term Goal (For True Real-Time): If your application’s core value is real-time collaboration (like a Google Doc or Figma), then plan to add a Server-Sent Events (SSE) or WebSocket layer to your backend to push updates to clients.
In summary: Avoid client-side polling. Implement the optimistic UI pattern now, and for multi-user synchronization, use a purpose-built library like react-query or a real-time backend push technology like SSE.
Soft Delete vs Hard Delete
Soft Delete vs Hard Delete
Here is a classic problem in Event Sourcing, often related to the concept of “soft deletes” or “state transitions” versus “hard deletes” and re-insertions. The core issue is that aggregate_version must be strictly unique for a given aggregate. If you try to re-insert an aggregate at an old version, it fundamentally violates Event Sourcing principles.
Let’s break down the scenario and the best ways to handle it.
The Problem Scenario: Version Conflict on Re-add
Your scenario:
UserHostCreatedEvent (userId=U, hostId=H, aggregate_version=1)->event_store_thas version 1.user_host_t(projection) has version 1.UserHostDeletedEvent (userId=U, hostId=H, aggregate_version=2)->event_store_thas version 2.user_host_teither deletes or marks as inactive.UserHostCreatedEvent (userId=U, hostId=H, aggregate_version=1)-> CONFLICT! This event says the aggregate(U,H)is at version 1 again, butevent_store_talready has version 2 for(U,H).
Root Cause: You cannot “re-add” an aggregate at an old version. An aggregate’s version always strictly increases. The action of “adding back” is not a “first time add” in the event history; it’s a new state transition.
Best Ways to Handle This Kind of Scenario
The solution involves redefining what “add back” means in an Event Sourcing context and how your aggregates and projections handle it.
Option 1: State Transitions (Recommended for your scenario)
This is the most common and robust approach. Instead of thinking of “add” and “remove” as discrete CRUD operations on a single record, think of them as state changes of an aggregate instance that always exists.
Aggregate Design (Conceptual UserHostMapping Aggregate):
- An aggregate representing the state of a
(User, Host)relationship (e.g.,UserHostMappingAggregate(userId, hostId)). - It has a state, e.g.,
ACTIVE,INACTIVE. - The
aggregate_idfor this aggregate would be a composite ID (e.g.,userId + "-" + hostIdor a UUID that represents this specific mapping). - It has a
version(sequence number).
Event Types:
UserHostActivatedEvent (userId, hostId, sequence_number)UserHostDeactivatedEvent (userId, hostId, sequence_number)
Scenario with State Transitions:
-
Add Host to User Mapping (First Time):
- Command:
ActivateUserHostMapping(userId=U, hostId=H, expectedVersion=0)(Expected version 0 because it doesn’t exist yet). - Aggregate
(U,H): GeneratesUserHostActivatedEvent (userId=U, hostId=H, sequence_number=1). event_store_t: Saves version 1.user_host_t(projection): INSERTS record(U, H, status=ACTIVE, aggregate_version=1).
- Command:
-
Remove Host to User Mapping:
- Command:
DeactivateUserHostMapping(userId=U, hostId=H, expectedVersion=1). - Aggregate
(U,H): GeneratesUserHostDeactivatedEvent (userId=U, hostId=H, sequence_number=2). event_store_t: Saves version 2.user_host_t(projection): UPDATES record(U, H)tostatus=INACTIVE, aggregate_version=2. (Doesn’t delete the row).
- Command:
-
Add Back the Same Host to User Mapping:
- Command:
ReactivateUserHostMapping(userId=U, hostId=H, expectedVersion=2). (Expected version 2 because it’s currently INACTIVE at version 2). - Aggregate
(U,H): GeneratesUserHostActivatedEvent (userId=U, hostId=H, sequence_number=3). event_store_t: Saves version 3.user_host_t(projection): UPDATES record(U, H)tostatus=ACTIVE, aggregate_version=3.
- Command:
Benefits of State Transitions:
- Strictly Monotonic Versions: The
sequence_numberfor theUserHostMappingaggregate (U,H) always increases (0 -> 1 -> 2 -> 3). No version conflicts. - Complete History: The Event Store clearly shows the activation/deactivation cycle.
- Simpler Projection: The projection (
user_host_t) never deletes rows; it only updates their status and version. This makes updates simple (UPDATE ... WHERE aggregate_id = ? AND aggregate_version = ?) and avoidsINSERTconflicts on “re-add.” - Idempotent Read Model Updates: The consumer logic is straightforward.
Option 2: Unique ID for Each Relationship Instance (Less common for simple toggles)
- Approach: Instead of
(U,H)being one aggregate that changes status, you treat each “active period” of(U,H)as a new, distinct aggregate. aggregate_id: A brand new UUID for each activation of(U,H).- Event Types:
UserHostCreatedEvent (mappingId=M1, userId=U, hostId=H, sequence_number=1)UserHostDeletedEvent (mappingId=M1, userId=U, hostId=H, sequence_number=2)UserHostCreatedEvent (mappingId=M2, userId=U, hostId=H, sequence_number=1)(for the second time)
- Projection: The
user_host_ttable would track thesemappingIds, possibly withstart_tsandend_ts. When a mapping is terminated, you update itsend_ts. When “added back,” you insert a new row with a newmappingId. - Complexity: Managing which
mappingIdis current for(U,H)can be tricky. It’s usually overkill for simple active/inactive toggles.
Option 3: History Table for User Host Mapping
- Approach: Create a user_host_history_t to keep a history of UserHostMapping.
- Projection: The
user_host_tanduser_host_history_tjoin together for the query with both snapshot and historical views. - Complexity: Managing both original and historical tables is overkill in this use case unless you need historical query very frequently.
Recommended Approach for your user_host_t scenario
Go with Option 1: State Transitions for a (User, Host) Aggregate.
Detailed Changes:
-
Database Schema for
user_host_t:- Add a
statuscolumn (e.g.,VARCHAR(10) NOT NULL DEFAULT 'ACTIVE'). - Ensure
aggregate_versioncolumn exists. - Primary key/unique constraint likely remains
(host_id, user_id).
ALTER TABLE user_host_t ADD COLUMN status VARCHAR(10) NOT NULL DEFAULT 'ACTIVE', ADD COLUMN aggregate_version BIGINT NOT NULL DEFAULT 0; -- Add a unique constraint if not already present on (host_id, user_id) -- ALTER TABLE user_host_t ADD CONSTRAINT pk_user_host PRIMARY KEY (host_id, user_id); - Add a
-
Define specific Event Types:
UserHostActivatedEventUserHostDeactivatedEvent
-
Command Handling Logic (Write Model):
- When the “add host to user” command comes in:
- Load the
UserHostMappingaggregate (identified by(host_id, user_id)). - If not found (expectedVersion 0), generate
UserHostActivatedEvent. - If found and
status=INACTIVE(expectedVersion > 0), generateUserHostActivatedEvent. - If found and
status=ACTIVE(expectedVersion > 0), reject (already active, idempotent no-op).
- Load the
- When the “remove host from user” command comes in:
- Load the
UserHostMappingaggregate. - If not found or
status=INACTIVE, reject (already inactive/not found). - If
status=ACTIVE, generateUserHostDeactivatedEvent.
- Load the
- When the “add host to user” command comes in:
-
PortalEventConsumerLogic (Read Model Update):-
For
UserHostActivatedEvent:- This event means the mapping is now active.
- Try to
UPDATE user_host_t SET status='ACTIVE', aggregate_version=? WHERE host_id=? AND user_id=? AND aggregate_version=?. - If 0 rows updated:
- Check if the record exists (
SELECT COUNT(*) ...). - If it exists (and version didn’t match), it’s a
ConcurrencyException. - If it doesn’t exist, it’s the very first time this mapping became active, so
INSERT INTO user_host_t (...) VALUES (...).
- Check if the record exists (
- This will handle both initial creation and reactivation as idempotent updates/inserts based on state.
-
For
UserHostDeactivatedEvent:- This event means the mapping is now inactive.
UPDATE user_host_t SET status='INACTIVE', aggregate_version=? WHERE host_id=? AND user_id=? AND aggregate_version=?.- If 0 rows updated, it’s either
ConcurrencyExceptionor “not found” (already inactive).
-
This approach treats the user_host_t relationship as a single logical entity (an aggregate instance) that transitions through states (ACTIVE/INACTIVE), ensuring the aggregate_version always progresses monotonically and avoiding the conflict you described.
Command Handler Logic
It is crucial to figure out the db logic between the read model (what the UI sees) and the command model (what the command handler needs to decide). The command handler cannot rely solely on the UI’s expectedVersion in this scenario. It needs to query its own source of truth (the Event Store) to decide if it’s an “initial activation” or a “reactivation.”
Let’s refine the command handling logic for the UserHostMapping aggregate.
Key: The Command Handler Owns the Decision, Using the Event Store
The command handler’s job is to:
- Load the aggregate’s current state (by replaying events from
event_store_t). - Determine its current status and current version based on that replay.
- Compare the
expectedVersionfrom the command with the aggregate’scurrentVersion. - Apply business rules to decide what event(s) to generate.
Event Types & Aggregate ID (as per previous recommendation)
- Aggregate ID: A composite of
hostIdanduserId(e.g.,hostId + "_" + userId). - Events:
UserHostActivatedEvent: Represents the relationship becoming active.UserHostDeactivatedEvent: Represents the relationship becoming inactive.
Step-by-Step Command Handling Logic
Let’s assume your command handler is UserHostMappingCommandHandler and it interacts with a UserHostMappingAggregate.
1. UserHostMappingAggregate (Internal Logic):
This aggregate needs to rebuild its state (currentStatus, currentVersion) from its event stream.
public class UserHostMappingAggregate {
private final String hostId;
private final String userId;
private UserHostMappingStatus currentStatus; // Enum: ACTIVE, INACTIVE, NON_EXISTENT
private long currentVersion; // Sequence number of the last applied event
private List<DomainEvent> uncommittedEvents = new ArrayList<>();
public UserHostMappingAggregate(String hostId, String userId) {
this.hostId = hostId;
this.userId = userId;
this.currentStatus = UserHostMappingStatus.NON_EXISTENT; // Initial state
this.currentVersion = 0;
}
public static UserHostMappingAggregate loadFromEvents(String hostId, String userId, List<DomainEvent> history) {
UserHostMappingAggregate aggregate = new UserHostMappingAggregate(hostId, userId);
if (history != null && !history.isEmpty()) {
history.forEach(aggregate::applyEvent);
}
return aggregate;
}
private void applyEvent(DomainEvent event) {
if (event instanceof UserHostActivatedEvent) {
this.currentStatus = UserHostMappingStatus.ACTIVE;
} else if (event instanceof UserHostDeactivatedEvent) {
this.currentStatus = UserHostMappingStatus.INACTIVE;
}
this.currentVersion = event.getSequenceNumber(); // Update version based on event
}
// --- Command Handling Methods ---
public void activateMapping(long expectedVersion) {
// OCC Check (optional here, but good practice if not relying solely on DB constraint)
if (this.currentVersion != expectedVersion) {
throw new ConcurrencyException("Concurrency conflict. Expected version " + expectedVersion + ", actual " + this.currentVersion);
}
// Business Logic: What state must it be in to activate?
if (this.currentStatus == UserHostMappingStatus.ACTIVE) {
// Already active, idempotent no-op or reject as invalid transition
logger.info("Mapping for user {} host {} is already active. No new event generated.", userId, hostId);
return;
}
// Generate new event
long nextVersion = this.currentVersion + 1;
UserHostActivatedEvent event = new UserHostActivatedEvent(
UUID.randomUUID(), Instant.now(), getAggregateId(), "UserHostMapping", nextVersion, hostId, userId
);
uncommittedEvents.add(event);
applyEvent(event); // Apply to internal state immediately for consistency
}
public void deactivateMapping(long expectedVersion) {
// OCC Check
if (this.currentVersion != expectedVersion) {
throw new ConcurrencyException("Concurrency conflict. Expected version " + expectedVersion + ", actual " + this.currentVersion);
}
// Business Logic
if (this.currentStatus != UserHostMappingStatus.ACTIVE) {
logger.info("Mapping for user {} host {} is not active. Cannot deactivate.", userId, hostId);
throw new IllegalStateException("Mapping is not active and cannot be deactivated.");
}
// Generate new event
long nextVersion = this.currentVersion + 1;
UserHostDeactivatedEvent event = new UserHostDeactivatedEvent(
UUID.randomUUID(), Instant.now(), getAggregateId(), "UserHostMapping", nextVersion, hostId, userId
);
uncommittedEvents.add(event);
applyEvent(event);
}
// Helper to get the composite aggregate ID
public String getAggregateId() {
return hostId + "_" + userId; // Consistent composite ID
}
// Getters for external access
public UserHostMappingStatus getCurrentStatus() { return currentStatus; }
public long getCurrentVersion() { return currentVersion; }
public List<DomainEvent> getUncommittedEvents() { return uncommittedEvents; }
public void markEventsCommitted() { uncommittedEvents.clear(); }
public enum UserHostMappingStatus {
ACTIVE, INACTIVE, NON_EXISTENT
}
}
2. UserHostMappingCommandHandler (Application Service):
This is where the command logic happens. The key is that the command from the UI is now generic (e.g., SetUserHostMappingStatus).
public class UserHostMappingCommandHandler { // This is your application service
private final EventStoreEventRepository eventStoreRepository; // To load events
private final OutboxMessageRepository outboxRepository; // To save new events
// Constructor injection
// ...
public void handleSetUserHostMappingStatus(String hostId, String userId, boolean activate, long expectedVersionFromUI) {
String aggregateId = hostId + "_" + userId;
// 1. Load aggregate state from Event Store
List<DomainEvent> history = eventStoreRepository.findByAggregateIdOrderBySequenceNumberAsc(aggregateId)
.stream()
.map(this::deserializeEventStoreEvent) // Deserialize from DB format
.collect(Collectors.toList());
UserHostMappingAggregate aggregate = UserHostMappingAggregate.loadFromEvents(hostId, userId, history);
// 2. Perform business logic based on intent (activate) and current state
if (activate) {
aggregate.activateMapping(expectedVersionFromUI); // Will generate UserHostActivatedEvent
} else {
aggregate.deactivateMapping(expectedVersionFromUI); // Will generate UserHostDeactivatedEvent
}
// 3. Persist new events
List<DomainEvent> newEvents = aggregate.getUncommittedEvents();
if (!newEvents.isEmpty()) {
// Your transactional outbox logic (save to Event Store and Outbox)
eventStoreRepository.saveAll(newEvents.stream().map(this::mapToEventStoreEvent).collect(Collectors.toList()));
outboxRepository.saveAll(newEvents.stream().map(this::mapToOutboxMessage).collect(Collectors.toList()));
aggregate.markEventsCommitted();
}
}
// Helper methods for serialization/deserialization as shown in previous examples
// ...
}
3. PortalEventConsumer Logic (Read Model Update):
The consumer updates user_host_t based on the events.
-
For
UserHostActivatedEvent:// In your PortalEventConsumer (inside processSingleEventWithRetries for this event type) Map<String, Object> eventData = extractEventData(eventMap); String hostId = (String) eventMap.get(Constants.HOST); // Assuming hostId is a CE extension String userId = (String) eventMap.get(Constants.USER); // Assuming userId is a CE extension String aggregateId = (String) eventMap.get(CloudEventV1.SUBJECT); // Or extract from eventData if set as such long newVersion = getEventSequenceNumber(eventMap); // SQL: UPSERT is ideal here. If record exists, update status/version. If not, insert. // This handles both initial activation (INSERT) and reactivation (UPDATE) idempotently. final String upsertSql = "INSERT INTO user_host_t (host_id, user_id, status, aggregate_version, update_user, update_ts) " + "VALUES (?, ?, ?, ?, ?, ?) " + "ON CONFLICT (host_id, user_id) DO UPDATE SET " + "status = EXCLUDED.status, " + "aggregate_version = EXCLUDED.aggregate_version, " + "update_user = EXCLUDED.update_user, " + "update_ts = EXCLUDED.update_ts " + "WHERE user_host_t.aggregate_version < EXCLUDED.aggregate_version"; // Only update if incoming event is newer try (PreparedStatement statement = conn.prepareStatement(upsertSql)) { statement.setObject(1, UUID.fromString(hostId)); statement.setObject(2, UUID.fromString(userId)); statement.setString(3, UserHostMappingAggregate.UserHostMappingStatus.ACTIVE.name()); statement.setLong(4, newVersion); statement.setString(5, (String)eventMap.get(Constants.USER)); // From CE extension statement.setObject(6, OffsetDateTime.parse((String)eventMap.get(CloudEventV1.TIME))); statement.executeUpdate(); }- Crucial
ON CONFLICT ... WHERE user_host_t.aggregate_version < EXCLUDED.aggregate_version: This makes the projection update idempotent and handles out-of-order delivery. If the database already has a newer version than the incoming event, it simply does nothing (0 rows affected), preventing a stale event from overwriting a more recent state.
- Crucial
-
For
UserHostDeactivatedEvent:// In your PortalEventConsumer (inside processSingleEventWithRetries for this event type) Map<String, Object> eventData = extractEventData(eventMap); String hostId = (String) eventMap.get(Constants.HOST); String userId = (String) eventMap.get(Constants.USER); long newVersion = getEventSequenceNumber(eventMap); final String updateSql = "UPDATE user_host_t SET status='INACTIVE', aggregate_version=?, update_user=?, update_ts=? " + "WHERE host_id = ? AND user_id = ? AND aggregate_version < ?"; // Only update if incoming event is newer try (PreparedStatement statement = conn.prepareStatement(updateSql)) { statement.setLong(1, newVersion); statement.setString(2, (String)eventMap.get(Constants.USER)); statement.setObject(3, OffsetDateTime.parse((String)eventMap.get(CloudEventV1.TIME))); statement.setObject(4, UUID.fromString(hostId)); statement.setObject(5, UUID.fromString(userId)); statement.setLong(6, newVersion); // Only update if current DB version < newVersion (from event) statement.executeUpdate(); }
How to Figure it Out in the Command Handler (from UI perspective)
The UI will initially query the user_host_t read model.
-
Scenario A: UI queries, no record for
(U,H)found.- UI infers state is “Non-Existent” or “Inactive”.
- UI provides
expectedVersion = 0to the command (because the read model had no entry). - Command handler:
aggregate.currentStatus == NON_EXISTENT. GeneratesUserHostActivatedEvent (sequence_number=1).
-
Scenario B: UI queries, record
(U,H, status=ACTIVE, aggregate_version=1)found.- UI provides
expectedVersion = 1to the command. - User wants to “remove.”
- Command handler:
aggregate.currentStatus == ACTIVE. GeneratesUserHostDeactivatedEvent (sequence_number=2).
- UI provides
-
Scenario C: UI queries, record
(U,H, status=INACTIVE, aggregate_version=2)found. (This assumes your UI could list inactive items, or an admin UI can see it.)- UI provides
expectedVersion = 2to the command. - User wants to “add back” / “reactivate.”
- Command handler:
aggregate.currentStatus == INACTIVE. GeneratesUserHostActivatedEvent (sequence_number=3).
- UI provides
-
Crucial UI Aspect: If the UI doesn’t display inactive items (which is typical for a “list active” view), and the user tries to “add” an item that used to exist but is now inactive, the UI would initially send
expectedVersion = 0.- Command handler receives
expectedVersion = 0, but aggregate is actuallyINACTIVEatversion=2. - OCC Conflict!
aggregate.currentVersion (2) != expectedVersion (0). Command is rejected. - User Experience: “Cannot add. This mapping exists in an inactive state. Please activate it instead.” This forces a clearer UI workflow.
- Command handler receives
By leveraging state transitions within your aggregate and using ON CONFLICT / WHERE aggregate_version < EXCLUDED.aggregate_version in your projection updates, you ensure strict versioning, idempotent read models, and a consistent business logic flow.
Tenant Migration and Environment Promotion
This document addresses the reality of tenant migration and environment promotion in an Event Sourcing context. You must preserve the event sequence (aggregate_version) while making necessary adjustments (hostId, new userId UUIDs) to fit the target environment.
Design Strategy: The Event Mutator
The best design is to introduce a specific, configurable pipeline stage—an Event Mutator—that runs after deserialization but before the final DB insert.
We’ll define the replacement and enrichment parameters as JSON/YAML structures and create a separate utility to apply the mutations.
1. Mutation Configuration Format
We’ll define the parameters to be a JSON string representing a list of mutation rules.
replacement(-r): Find a field with an old value and replace it with a new value.- Example:
[{"field": "hostId", "from": "UUID_A", "to": "UUID_B"}, {"field": "user_id", "from": "ID_X", "to": "ID_Y"}]
- Example:
enrichment(-e): Find a field and generate a new, unique value for it.- Example:
[{"field": "id", "action": "generateUUID"}, {"field": "userId", "action": "mapAndGenerate", "sourceField": "originalUserId"}]
- Example:
2. The EventMutator Class
This class will handle parsing the configuration and applying the changes to the CloudEvent attributes and the data payload.
Refactored Cli.java and New EventMutator Logic
Here is the updated Cli.java and a conceptual EventMutator structure.
A. New Class: EventMutator.java
This class handles the core logic. Since CloudEvents are immutable, any change requires rebuilding the event (CloudEventBuilder.v1(cloudEvent)).
package net.lightapi.importer;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.networknt.config.Config;
import com.networknt.utility.UuidUtil;
import io.cloudevents.CloudEvent;
import io.cloudevents.core.builder.CloudEventBuilder;
import net.lightapi.portal.PortalConstants;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.UUID;
public class EventMutator {
private static final Logger logger = LoggerFactory.getLogger(EventMutator.class);
private final ObjectMapper mapper = Config.getInstance().getMapper();
// Parsed list of rules
private final List<Map<String, String>> replacementRules;
private final List<Map<String, String>> enrichmentRules;
// Map to track generated UUIDs for consistent replacement across events (e.g., old user ID -> new user ID)
private final Map<String, String> generatedIdMap = new HashMap<>();
public EventMutator(String replacementJson, String enrichmentJson) {
this.replacementRules = parseRules(replacementJson);
this.enrichmentRules = parseRules(enrichmentJson);
}
private List<Map<String, String>> parseRules(String json) {
if (json == null || json.isEmpty()) return Collections.emptyList();
try {
return mapper.readValue(json, new TypeReference<List<Map<String, String>>>() {});
} catch (IOException e) {
logger.error("Failed to parse mutation rules JSON: {}", json, e);
throw new IllegalArgumentException("Invalid JSON format for mutation rules.", e);
}
}
/**
* Applies all replacement and enrichment rules to a single CloudEvent.
* @param originalEvent The original CloudEvent object.
* @return The mutated CloudEvent.
*/
public CloudEvent mutate(CloudEvent originalEvent) {
CloudEventBuilder builder = CloudEventBuilder.v1(originalEvent);
Map<String, Object> dataMap = null;
// Deserialize data payload once (if present)
if (originalEvent.getData() != null && originalEvent.getData().toBytes().length > 0) {
try {
dataMap = mapper.readValue(originalEvent.getData().toBytes(), new TypeReference<HashMap<String, Object>>() {});
} catch (IOException e) {
logger.error("Failed to deserialize CloudEvent data for mutation. Skipping data mutation.", e);
// Continue with just extension mutation
}
}
// 1. Apply Replacements
applyReplacements(builder, dataMap);
// 2. Apply Enrichments
applyEnrichments(builder, dataMap);
// Rebuild CloudEvent with mutated data if it was changed
if (dataMap != null && dataMap.containsKey("__MUTATED_DATA__")) {
builder.withData(originalEvent.getDataContentType().orElse("application/json"), dataMap.get("__MUTATED_DATA__"));
// Remove the internal flag
dataMap.remove("__MUTATED_DATA__");
}
return builder.build();
}
// --- Private Mutation Helpers ---
private void applyReplacements(CloudEventBuilder builder, Map<String, Object> dataMap) {
for (Map<String, String> rule : replacementRules) {
String field = rule.get("field");
String from = rule.get("from");
String to = rule.get("to");
if (field == null || from == null || to == null) continue;
// Check CloudEvent Extensions (including known attributes like host, user)
Object extensionValue = builder.getExtension(field);
if (extensionValue != null && extensionValue.toString().equals(from)) {
builder.withExtension(field, to);
logger.debug("Replaced extension {} from {} to {}", field, from, to);
}
// Check CloudEvent Data Payload
if (dataMap != null && dataMap.containsKey(field) && dataMap.get(field) != null && dataMap.get(field).toString().equals(from)) {
dataMap.put(field, to);
dataMap.put("__MUTATED_DATA__", dataMap); // Flag that data was mutated
logger.debug("Replaced data field {} from {} to {}", field, from, to);
}
}
}
private void applyEnrichments(CloudEventBuilder builder, Map<String, Object> dataMap) {
for (Map<String, String> rule : enrichmentRules) {
String field = rule.get("field");
String action = rule.get("action");
if (field == null || action == null) continue;
String generatedId = null;
if ("generateUUID".equalsIgnoreCase(action)) {
// Generate and cache a new UUID for the whole import run if needed, or always generate new.
// For simplicity, we assume we generate a new UUID for the field.
generatedId = UuidUtil.getUUID().toString();
} else if ("mapAndGenerate".equalsIgnoreCase(action)) {
String sourceField = rule.get("sourceField");
String originalId = null;
// Get the original ID from a source field in the data payload (e.g., from an 'oldUserId' field)
if (dataMap != null && sourceField != null && dataMap.containsKey(sourceField)) {
originalId = dataMap.get(sourceField).toString();
}
// Or get from a specific CloudEvent extension/subject
else if ("subject".equalsIgnoreCase(sourceField) && builder.getSubject() != null) {
originalId = builder.getSubject();
}
if (originalId != null) {
// Check cache for consistency (e.g., ensure old_user_ID_A always maps to new_user_ID_X)
generatedId = generatedIdMap.computeIfAbsent(field + ":" + originalId, k -> UuidUtil.getUUID().toString());
logger.debug("Mapped original ID {} to new ID {}", originalId, generatedId);
} else {
// Cannot map, fall back to simple UUID generation if allowed
generatedId = UuidUtil.getUUID().toString();
}
} else if ("aggregateIdMap".equalsIgnoreCase(action) && field.equals("subject")) {
// This complex logic is for when a related aggregate ID needs to be updated.
// E.g., when importing a User, the UserCreatedEvent ID is the new Subject/AggregateId.
// The actual logic for this is too complex for a generic SMT and relies on a separate lookup service.
// Skip for this simple mutator.
continue;
}
if (generatedId != null) {
// Mutate CloudEvent Extensions (Subject, ID, etc.)
if ("id".equalsIgnoreCase(field)) {
builder.withId(generatedId);
} else if ("subject".equalsIgnoreCase(field)) {
builder.withSubject(generatedId);
} else if (builder.getExtension(field) != null) { // Custom extension
builder.withExtension(field, generatedId);
}
// Mutate Data Payload
if (dataMap != null && dataMap.containsKey(field)) {
dataMap.put(field, generatedId);
dataMap.put("__MUTATED_DATA__", dataMap); // Flag that data was mutated
}
logger.debug("Enriched field {} with new ID {}", field, generatedId);
}
}
}
}
B. Updated Cli.java to Integrate EventMutator
package net.lightapi.importer;
// ... (Existing imports) ...
import com.networknt.config.JsonMapper;
import com.networknt.db.provider.SqlDbStartupHook;
import com.networknt.monad.Result;
import com.networknt.service.SingletonServiceFactory;
import com.networknt.status.Status;
import com.networknt.utility.Constants;
import com.networknt.utility.UuidUtil; // Used in mutator
import io.cloudevents.CloudEvent;
import io.cloudevents.core.builder.CloudEventBuilder;
import io.cloudevents.core.format.EventFormat;
import io.cloudevents.core.provider.EventFormatProvider;
import io.cloudevents.jackson.JsonFormat;
import net.lightapi.portal.EventTypeUtil;
import net.lightapi.portal.PortalConstants;
import net.lightapi.portal.db.PortalDbProvider;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.UUID; // Used in mutator
public class Cli {
private static final Logger logger = LoggerFactory.getLogger(Cli.class); // Added logger
public static PortalDbProvider dbProvider;
public static SqlDbStartupHook sqlDbStartupHook;
@Parameter(names={"--filename", "-f"}, required = false,
description = "The filename to be imported.")
String filename;
@Parameter(names={"--batchSize", "-b"}, required = false,
description = "Number of events to import per database transaction batch. Default is 1000.")
int batchSize = 1000;
@Parameter(names={"--replacement", "-r"}, required = false,
description = "JSON array string of replacement rules: [{'field': 'oldHostId', 'from': 'UUID_A', 'to': 'UUID_B'}].")
String replacement;
@Parameter(names={"--enrichment", "-e"}, required = false,
description = "JSON array string of enrichment rules: [{'field': 'userId', 'action': 'mapAndGenerate', 'sourceField': 'oldUserId'}].")
String enrichment;
@Parameter(names={"--help", "-h"}, help = true)
private boolean help;
public static void main(String ... argv) throws Exception {
try {
// ... (Startup initialization remains the same) ...
Cli cli = new Cli();
JCommander jCommander = JCommander.newBuilder().addObject(cli).build();
jCommander.parse(argv);
// Assuming SingletonServiceFactory and SqlDbStartupHook setup is correct
dbProvider = (PortalDbProvider) SingletonServiceFactory.getBean(DbProvider.class);
cli.run(jCommander);
} catch (ParameterException e) {
System.err.println("Command line parameter error: " + e.getLocalizedMessage());
jCommander.usage();
} catch (Exception e) {
System.err.println("An unexpected error occurred during startup or import: " + e.getLocalizedMessage());
e.printStackTrace();
}
}
public void run(JCommander jCommander) throws Exception {
if (help) {
jCommander.usage();
return;
}
logger.info("Starting event import with batch size: {}", batchSize);
if (replacement != null) logger.info("Replacement rules: {}", replacement);
if (enrichment != null) logger.info("Enrichment rules: {}", enrichment);
EventFormat cloudEventFormat = EventFormatProvider.getInstance().resolveFormat(JsonFormat.CONTENT_TYPE);
if (cloudEventFormat == null) {
logger.error("No CloudEvent JSON format provider found.");
throw new IllegalStateException("CloudEvent JSON format not found.");
}
// --- Instantiate EventMutator ---
EventMutator mutator = new EventMutator(replacement, enrichment);
List<CloudEvent> currentBatch = new ArrayList<>(batchSize);
long importedCount = 0;
long lineNumber = 0;
try (BufferedReader reader = new BufferedReader(new FileReader(filename))) {
String line;
while((line = reader.readLine()) != null) {
lineNumber++;
if(line.startsWith("#") || line.trim().isEmpty()) continue;
try {
// Assuming format: "key value" (where key is user_id, value is the full database row JSON)
int firstSpace = line.indexOf(" ");
if (firstSpace == -1) {
logger.warn("Skipping malformed line {} (no space separator): {}", lineNumber, line);
continue;
}
String dbRowJson = line.substring(firstSpace + 1); // <<< Full DB row JSON
// 1. Deserialize the nested CloudEvent (The Fix from prior step)
Map<String, Object> dbRowMap = Config.getInstance().getMapper().readValue(dbRowJson, new TypeReference<HashMap<String, Object>>() {});
String cloudEventJsonFromPayload = (String) dbRowMap.get("payload");
CloudEvent cloudEvent = cloudEventFormat.deserialize(cloudEventJsonFromPayload.getBytes(StandardCharsets.UTF_8));
// 2. Perform Mutation/Enrichment
CloudEvent mutatedEvent = mutator.mutate(cloudEvent);
// 3. Finalization/Validation (Transfer critical top-level DB fields to Extensions)
// Transferring nonce and aggregateVersion from the exported DB row into the CloudEvent's extensions.
Object dbNonceObj = dbRowMap.get("nonce");
if (dbNonceObj instanceof Number) {
mutatedEvent = CloudEventBuilder.v1(mutatedEvent)
.withExtension(PortalConstants.NONCE, ((Number)dbNonceObj).longValue())
.build();
}
Object dbAggVersionObj = dbRowMap.get("aggregateVersion");
if (dbAggVersionObj instanceof Number) {
mutatedEvent = CloudEventBuilder.v1(mutatedEvent)
.withExtension(PortalConstants.EVENT_AGGREGATE_VERSION, ((Number)dbAggVersionObj).longValue())
.build();
}
// 4. Add to current batch.
currentBatch.add(mutatedEvent);
// If batch is full, process it
if (currentBatch.size() >= batchSize) {
processBatch(currentBatch);
importedCount += currentBatch.size();
currentBatch.clear();
}
} catch (Exception e) {
logger.error("Error processing line {}: {}", lineNumber, e.getMessage(), e);
// Log and continue to process the rest of the file.
}
} // end while loop
// Process any remaining events in the last batch
if (!currentBatch.isEmpty()) {
processBatch(currentBatch);
importedCount += currentBatch.size();
}
} catch (IOException e) {
logger.error("Error reading file {}: {}", filename, e.getMessage(), e);
throw e;
} finally {
logger.info("Import process finished. Total events successfully imported in batches: {}", importedCount);
}
logger.info("All Portal Events have been imported successfully from {}. Have fun!!!", filename);
}
/**
* Processes a batch of CloudEvents by inserting them into the database in a single transaction.
* @param batch The list of CloudEvents to insert.
*/
private void processBatch(List<CloudEvent> batch) {
// --- Transaction Management ---
// The transaction logic is ideally handled inside dbProvider.insertEventStore
// or by a wrapper method if insertEventStore doesn't handle transactions internally.
Result<String> eventStoreResult = dbProvider.insertEventStore(batch.toArray(new CloudEvent[0]));
if(eventStoreResult.isFailure()) {
logger.error("Failed to insert batch of {} events. Rollback occurred. Error: {}", batch.size(), eventStoreResult.getError());
// In a CLI, failing the batch often means stopping the entire import process
// to ensure data integrity, as a full rollback on the entire batch has occurred.
// If you want to continue, you would need complex tracking of failed batches.
// For now, logging the error is sufficient, and the method returns.
} else {
logger.info("Imported batch of {} records successfully.", batch.size());
}
}
}
Key Usage Examples for the CLI
When calling the CLI, you pass the mutation rules as a single JSON string (often enclosed in single quotes '...' in the shell):
1. Replace Host ID (Tenant Migration)
You moved from old_host_uuid to new_host_uuid.
java -jar importer.jar -f events.log -r '[{"field": "hostId", "from": "OLD_HOST_UUID", "to": "NEW_HOST_UUID"}]'
2. Replace Host ID and Generate New Aggregate IDs (Full Isolation)
You want to map the old userId to a new userId and generate new eventIds and subject (aggregate ID).
java -jar importer.jar -f events.log \
-r '[{"field": "hostId", "from": "OLD_HOST_UUID", "to": "NEW_HOST_UUID"}]' \
-e '[
{"field": "id", "action": "generateUUID"},
{"field": "subject", "action": "generateUUID"},
{"field": "originalUserId", "action": "mapAndGenerate", "sourceField": "userId"}
]'
(Note: For the user mapping, you would need a custom solution that first reads a mapping table or performs a one-time query to get the originalUserId from a previous step, and then uses the mapping to generate the new ID consistently.)
Product Version Config
When using light-portal to manage the configurations for Apis or Apps. The configuration can be overwritten at different level. On top of platform default, the production level and production version level are utilized very often.
There are two options:
- Extract the config files from the product jar and create the events for mapping. This includes all config and config properties in the jar file per product and product version.
Pros:
- Can be automatically done with a process.
- Standardized and hardly make mistakes.
Cons:
- It cannot be customized per organization.
- Manually create events for mappings per product and per product version for the properties that is potentially changeable.
Pros:
- Flexible and customizable per organization.
- Can be improved in a process.
Cons:
- May take some time to create and maintain the event file for every release.
Product Version Config Mapping Automation
The portal-view config update page depends on product-version applicability
metadata before it can show configurable properties for instance, API, app, and
app-api scopes. The metadata is stored in two product release mapping tables:
product_version_config_tproduct_version_config_property_t
The current Rust bootstrap data is generated into import files:
event-importer/events/local/09-rust-product-version-configs.jsonevent-importer/events/local/08-rust-product-version-config-properties.json
The same import-file approach can be used for Java products, but it does not scale well if every Java or Rust release requires a hand-maintained set of mapping events across all portal instances. This design proposes a release mapping automation model that keeps the existing event-sourced write path and removes the need to manually recreate mapping files for every product release.
Problem
Product versions are released often. Each new release can introduce a new
productVersionId, and the config update page only knows which configs and
properties are applicable when mappings exist for that exact product version.
Without automation:
- new releases have empty config update views until mappings are imported
- each portal instance must be updated separately
- Java and Rust products need parallel manual processes
- copying JSON import files by hand can drift from the actual product config schema
- support teams cannot safely tell whether an empty page means “no configs” or “missing mappings”
The automation must support two release modes:
- release all Java products
- release one or more Rust products
It must also support tenant-specific product versions without copying the same standard config mappings into every tenant.
Current Model
product_version_config_t maps a product version to a config:
host_id + product_version_id + config_id
product_version_config_property_t maps a product version to a config
property:
host_id + product_version_id + property_id
The event types already exist:
ProductVersionConfigCreatedEventProductVersionConfigDeletedEventProductVersionConfigPropertyCreatedEventProductVersionConfigPropertyDeletedEvent
The command APIs already exist:
product/createProductVersionConfig/0.1.0product/deleteProductVersionConfig/0.1.0product/createProductVersionConfigProperty/0.1.0product/deleteProductVersionConfigProperty/0.1.0
The projection handlers insert into the mapping tables through the event processor. The preferred automation path is therefore event-based, not direct SQL.
Product Versioning Policy
The release process must separate three related but different concepts:
release train change != product artifact change != config contract change
A Java release train can have one shared version number for coordination, but
that does not mean every product necessarily has a changed config contract. At
the same time, a product can legitimately need a new product version even when
its own repository did not change. For example, if a shared light-4j module
changes and every Java product must be rebuilt to pick up that dependency, each
rebuilt artifact is a real product release.
Recommended policy:
- Create a new product version when the product artifact changes.
- Treat common library upgrades as product artifact changes for every rebuilt product.
- Do not create a new product version for a product that is not rebuilt and not redeployed as part of the release.
- Treat config mapping as a separate decision from product version creation.
- If the config contract is unchanged, inherit the previous product version’s profile link.
- If the config contract changed or
breakConfig=true, require an explicit profile manifest.
This lets Java keep the operational benefit of release trains while preventing unnecessary mapping maintenance. Rust can continue independent product versioning because Rust products are already released separately.
If the portal needs to show that an unchanged product participated in a Java
release train, model that as release-set membership, not as a new product
version. A release set can link to the existing productVersionId for
unchanged products and to the new productVersionId for rebuilt products.
The release metadata should record why a product version exists:
{
"releaseReason": "light4j-dependency-upgrade",
"artifactChanged": true,
"sourceChanged": false,
"configChanged": false,
"breakConfig": false,
"configMappingPolicy": "inheritProfileFromPrevious"
}
Decision matrix:
| Case | Product Version | Mapping Action |
|---|---|---|
| Product source changed and config changed | create new version | explicit profile manifest |
| Product source changed but config unchanged | create new version | inherit previous profile link |
| Shared Java dependency changed and product rebuilt | create new version | inherit profile link unless config changed |
| Product not rebuilt and not redeployed | no new version | no mapping action |
| Breaking config change | create new version | explicit profile manifest required |
Goals
- Auto-populate config mappings for every new Java or Rust product release.
- Preserve event replay, auditability, and projection rebuild behavior.
- Support all portal hosts with one release operation without per-host mapping event amplification.
- Avoid hard-coded
productVersionIdvalues in reusable release manifests. - Support dry-run reporting before events are emitted.
- Keep manual override and cleanup possible through existing mapping commands.
- Make generated events idempotent enough for safe retry.
- Detect missing config and property definitions before a release appears complete.
Non-Goals
- Do not change the config override hierarchy.
- Do not write directly to config mapping projection tables.
- Do not make the config update page infer product applicability by scanning all config properties at runtime.
- Do not require schema-registry completion before mappings can be automated.
- Do not force all organizations to use the same product mappings if they need host-specific customization.
Recommended Approach
Use ConfigProfile as the reusable config contract, then link tenant product
versions to the profile.
The existing product_version_config_t and
product_version_config_property_t tables are host-scoped because
product_version_t is host-scoped. That model works for tenant-specific
extensions, but it is expensive for standard product mappings because every
host receives a duplicate copy of the same config/property rows.
The profile model separates the global product config contract from the tenant’s product release:
ConfigProfile = standard config contract for a product/runtime/framework line
ProductVersion = tenant-owned release artifact/version
ProductVersionConfigProfile = tenant product version points to standard profile
For example, every tenant can have its own internal lg product version while
all of those versions point to the same light-gateway-java-2.3.5 config
profile if their config contract is the same.
The existing product-version mapping tables remain useful, but their role changes:
config_profile_config_tandconfig_profile_property_thold standard global applicability.product_version_config_profile_tlinks a tenant product version to the standard profile.product_version_config_tandproduct_version_config_property_thold tenant-specific additions or legacy direct mappings.
This removes the need for allHosts=true to generate the same mapping events
for every tenant. A release creates or updates one profile, then each tenant
product version emits one profile-link event.
Schema Proposal
The profile tables are global because config_t and config_property_t are
already global definitions.
CREATE TABLE config_profile_t (
profile_id UUID PRIMARY KEY,
profile_name VARCHAR(255) NOT NULL,
runtime_family VARCHAR(32) NOT NULL,
product_id VARCHAR(8) NOT NULL,
light4j_version VARCHAR(32),
contract_version VARCHAR(64) NOT NULL,
profile_desc VARCHAR(1024),
aggregate_version BIGINT DEFAULT 1 NOT NULL,
active BOOLEAN NOT NULL DEFAULT TRUE,
delete_user VARCHAR(255),
delete_ts TIMESTAMP WITH TIME ZONE,
update_user VARCHAR(255) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL
);
CREATE UNIQUE INDEX config_profile_unique_idx
ON config_profile_t(runtime_family, product_id, contract_version)
WHERE active = true;
CREATE TABLE config_profile_config_t (
profile_id UUID NOT NULL,
config_id UUID NOT NULL,
aggregate_version BIGINT DEFAULT 1 NOT NULL,
active BOOLEAN NOT NULL DEFAULT TRUE,
delete_user VARCHAR(255),
delete_ts TIMESTAMP WITH TIME ZONE,
update_user VARCHAR(255) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY(profile_id, config_id),
FOREIGN KEY(profile_id) REFERENCES config_profile_t(profile_id) ON DELETE CASCADE,
FOREIGN KEY(config_id) REFERENCES config_t(config_id) ON DELETE CASCADE
);
CREATE TABLE config_profile_property_t (
profile_id UUID NOT NULL,
property_id UUID NOT NULL,
aggregate_version BIGINT DEFAULT 1 NOT NULL,
active BOOLEAN NOT NULL DEFAULT TRUE,
delete_user VARCHAR(255),
delete_ts TIMESTAMP WITH TIME ZONE,
update_user VARCHAR(255) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY(profile_id, property_id),
FOREIGN KEY(profile_id) REFERENCES config_profile_t(profile_id) ON DELETE CASCADE,
FOREIGN KEY(property_id) REFERENCES config_property_t(property_id) ON DELETE CASCADE
);
CREATE TABLE product_version_config_profile_t (
host_id UUID NOT NULL,
product_version_id UUID NOT NULL,
profile_id UUID NOT NULL,
aggregate_version BIGINT DEFAULT 1 NOT NULL,
active BOOLEAN NOT NULL DEFAULT TRUE,
delete_user VARCHAR(255),
delete_ts TIMESTAMP WITH TIME ZONE,
update_user VARCHAR(255) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY(host_id, product_version_id),
FOREIGN KEY(host_id, product_version_id)
REFERENCES product_version_t(host_id, product_version_id) ON DELETE CASCADE,
FOREIGN KEY(profile_id) REFERENCES config_profile_t(profile_id) ON DELETE RESTRICT
);
Using a separate product_version_config_profile_t link table is preferred
over adding config_profile_id to product_version_t because it keeps the
product version aggregate smaller and lets profile linking be introduced as a
separate event stream. If a future product version needs multiple profiles, the
primary key can be extended to (host_id, product_version_id, profile_id) with
an order_index column.
ON DELETE RESTRICT on product_version_config_profile_t.profile_id is
intentional. A profile cannot be deleted while any tenant product version is
linked to it. Operators must first migrate linked product versions to another
profile, unlink them, or delete the tenant product versions.
The database constraints only apply to hard deletes. Because projections use
soft deletes, command handlers must manually reject profile deletion while
active product-version profile links exist, and the ConfigProfileDeletedEvent
projection must mark active config_profile_config_t and
config_profile_property_t rows inactive.
Recommended event types:
ConfigProfileCreatedEventConfigProfileDeletedEventConfigProfileConfigCreatedEventConfigProfileConfigDeletedEventConfigProfilePropertyCreatedEventConfigProfilePropertyDeletedEventProductVersionConfigProfileLinkedEventProductVersionConfigProfileUnlinkedEvent
The existing ProductVersionConfigCreatedEvent and
ProductVersionConfigPropertyCreatedEvent remain valid for host-specific
direct mappings.
Query Resolution
getConfigUpdateProperties should resolve applicable configs/properties from
both profile mappings and direct product-version mappings:
-- profile-backed standard mappings
SELECT cpc.config_id
FROM product_version_config_profile_t pvcp
JOIN config_profile_t cp ON cp.profile_id = pvcp.profile_id
JOIN config_profile_config_t cpc ON cpc.profile_id = pvcp.profile_id
WHERE pvcp.host_id = :hostId
AND pvcp.product_version_id = :productVersionId
AND pvcp.active = true
AND cp.active = true
AND cpc.active = true
UNION
-- tenant-specific direct additions and legacy mappings
SELECT pvc.config_id
FROM product_version_config_t pvc
WHERE pvc.host_id = :hostId
AND pvc.product_version_id = :productVersionId
AND pvc.active = true;
The property query follows the same pattern with
config_profile_property_t and product_version_config_property_t.
If a tenant must remove a standard profile property for its own product version, the clean path is to assign a different profile for that product version. Direct mapping tables are additive and should not try to represent negative overrides unless a future exclusion table is explicitly added.
Manifest Source
The canonical public manifest source is the
lightapi/config-profile-manifests repository:
https://github.com/lightapi/config-profile-manifests
This repository stores portable, product-level ConfigProfile manifests for
LightAPI releases. It is intentionally not a generated-event repository.
Customer-specific hostId, productVersionId, admin user IDs, generated
CloudEvents, tenant overrides, and secrets must stay outside the public repo.
Real release manifests should use this path convention:
java/<product-id>/<product-version>/manifest.json
rust/<product-id>/<product-version>/manifest.json
The repository also contains the manifest schema, example manifests, a local
validation script, and a GitHub Actions workflow. Release automation should
validate manifests in that repository before using them as input to
event-importer --generate-config-profiles.
The manifest itself is portable. It uses logical product, config, and property names, not customer-only database IDs. It defines a config profile once, then links product versions to that profile.
{
"runtimeFamily": "java",
"light4jVersion": "2.3.5",
"profiles": [
{
"profileName": "light-gateway-java-2.3.5",
"productId": "lg",
"contractVersion": "2.3.5",
"configs": [
{
"configName": "server.yml",
"properties": "*"
},
{
"configName": "handler.yml",
"properties": ["enabled", "path"]
}
]
}
],
"products": [
{
"productId": "lg",
"productVersion": "2.3.5",
"configProfileRef": "lg|2.3.5"
}
]
}
For Java products, a shared Java dependency upgrade can create new tenant product versions while reusing the same profile if the config contract did not change. If the config contract changed, the release creates a new profile and links rebuilt product versions to it.
If a Java release train includes products that were not rebuilt, those products
should be linked to the release set but should not receive new
productVersionId values or new mapping events.
Generator Responsibilities
The generator takes:
- optional
hostId, product, or release-set filters for profile links - runtime family:
java,rust, or both - manifest path, normally from
lightapi/config-profile-manifests - dry-run flag
For each profile entry, it resolves:
configIdfromconfigNamepropertyIdfromconfigName + propertyName- existing
profileIdfromruntimeFamily + productId + contractVersion, or a deterministic newprofileId
Then it emits profile events only for missing or changed profile mappings:
- one
ConfigProfileCreatedEventfor each new profile - one
ConfigProfileConfigCreatedEventfor each profile config - one
ConfigProfilePropertyCreatedEventfor each profile property - in
syncProfilereplacement mode, oneConfigProfileConfigDeletedEventorConfigProfilePropertyDeletedEventfor each active profile mapping that is no longer present in the manifest
Profile deletion or replacement must be explicit. The default sync mode should
be additive so a partial manifest cannot accidentally remove a property from
every tenant linked to the profile. A delete-capable sync must require
replace=true or an equivalent explicit flag and must show affected linked
product versions in dry-run output.
For each product entry, it resolves:
productVersionIdfromhostId + productId + productVersionprofileIdfromconfigProfileRef
Then it emits:
- one
ProductVersionConfigProfileLinkedEventper tenant product version - optional direct
ProductVersionConfigCreatedEventandProductVersionConfigPropertyCreatedEventonly for tenant-specific additions
If dryRun=true, no events are emitted. The response returns a report:
{
"releaseSet": "java-2026-06",
"profiles": [
{
"profileName": "light-gateway-java-2.3.5",
"profileId": "019f...",
"configsToCreate": 15,
"propertiesToCreate": 183,
"alreadyMappedConfigs": 0,
"alreadyMappedProperties": 0,
"missingConfigs": [],
"missingProperties": []
}
],
"products": [
{
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f",
"productId": "lg",
"productVersion": "2.0.0",
"productVersionId": "019f...",
"profileId": "019f...",
"linkToCreate": true,
"alreadyLinked": false
}
]
}
Dry run must fail the release when any required product version, profile, config, or property cannot be resolved.
Inheritance From Previous Version
inheritFrom is useful for frequent releases, but it should usually inherit a
profile link, not copy rows.
Recommended rules:
- If the config contract is unchanged, link the new product version to the same profile as the previous product version.
- If a manifest lists an explicit profile with configs/properties, create or update that profile and link the product version to it.
- If
configMappingPolicy=inheritProfileFromPrevious, copy the previous profile link. - If
inheritFromis set and the manifest omitsconfigProfileRef, copy the profile link from the source product version. - If both inheritance and
add/removeare set, create a new profile derived from the inherited profile, apply the changes, and link to the new profile. - If the new product version has
breakConfig=true, require an explicit profile manifest. Do not silently inherit. - If
breakConfig=false, inheritance is allowed, but dry run should still compare the inherited mappings against any known generated config metadata. - If
configChanged=false, profile-link inheritance is the default mapping policy. - If
configChanged=true, require either explicitconfigsor explicitadd/removesections.
Example:
{
"productId": "api",
"productVersion": "1.0.2",
"inheritFrom": {
"productVersion": "1.0.1"
},
"remove": [
{
"configName": "old-config"
}
],
"add": [
{
"configName": "new-config",
"properties": ["enabled", "endpoint"]
}
]
}
This gives release automation a low-maintenance path for patch releases while still allowing breaking releases to declare exact applicability.
Event Idempotency
The generator should produce deterministic event IDs so the same release operation can be retried safely.
Use a stable namespace string such as:
runtimeFamily|productId|contractVersion
profileId|configId
profileId|propertyId
hostId|productVersionId|profileId
hostId|productVersionId|configId
hostId|productVersionId|propertyId
The aggregate subject should match the mapping aggregate identity used by the
event model. Profile aggregate subjects do not need hostId. Product-version
profile links and direct tenant mappings do need hostId and
productVersionId.
Direct IDs are preferred in generated events:
{
"type": "ProductVersionConfigProfileLinkedEvent",
"aggregatetype": "ProductVersionConfigProfile",
"data": {
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f",
"productId": "gtw",
"productVersion": "1.0.1",
"productVersionId": "019f...",
"profileId": "019f...",
"profileName": "light-gateway-java-2.3.5",
"aggregateVersion": 0,
"newAggregateVersion": 1
}
}
The human-readable names are still useful for audit and diagnostics, but the projection should not depend on name resolution after the generator has already resolved the IDs.
Command API Option
Add a new product command:
product/syncProductVersionConfigProfiles/0.1.0
Request:
{
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f",
"runtimeFamily": "java",
"releaseSet": "java-2026-06",
"manifest": {},
"allHosts": false,
"dryRun": true,
"mode": "syncProfile"
}
Modes:
syncProfile: create or update profile mappings from a manifest; additive by default, replacement only with an explicit delete-capable flaglinkProfile: link tenant product versions to profilesinheritProfile: link a new product version to the previous version’s profilebackfillLinks: link existing product versions to matching profilesverify: report missing profiles, links, configs, or properties without creating events
Profile delete and replacement operations must respect the
ON DELETE RESTRICT link. A command cannot delete a profile while any active
product_version_config_profile_t row references it; it must first migrate or
unlink the affected product versions.
Because projections soft-delete rows instead of issuing hard DELETE
statements, the command handler must perform this active-link check explicitly
before emitting ConfigProfileDeletedEvent. The projection handler should also
defensively skip parent deletion while active links exist and cascade a
successful profile soft-delete to active config_profile_config_t and
config_profile_property_t rows.
The command handler should not directly update projection tables. It should emit profile and profile-link events.
For large all-host release sets, the command should avoid one giant synchronous transaction. It can either:
- emit the profile events first because they are host-neutral, then
- enqueue one profile-link job per host and product
The second step is cheap compared with copying every config property mapping, but it should still be asynchronous for large tenant counts.
Importer Option
The event importer supports a generator mode:
java -jar target/event-importer.jar \
--generate-config-profiles \
--manifest java/lg/2.3.5/manifest.json \
--targetHostId 01964b05-552a-7c4b-9184-6857e7f3dc5f \
--adminUserId 01964b05-5532-7c79-8cde-191dcbd421b8 \
--output ./generated \
--dry-run
For deployment bundles, the generator can write normal JSON import files:
generated/07-config-profiles.json
generated/08-config-profile-properties.json
generated/09-config-profile-configs.json
generated/10-product-version-config-profile-links.json
This is the fastest migration path because it extends the current JSON import process. It also lets teams review the generated events before importing them.
The importer path is best for bootstrap and local environments. The command API path is better for live portal operations where the release needs to create profiles once and link tenant product versions without copying files into each deployment.
Release Flow
Recommended release pipeline:
- Determine the product release set.
- Classify each product as artifact changed, source changed, config changed, or unchanged.
- Generate or update config/property definitions for products whose config contract changed.
- Add or update the release manifest in
lightapi/config-profile-manifests. - Validate the manifest with the repo validation workflow.
- Create or reuse
ConfigProfilerows for each config contract. - Create new
ProductVersionCreatedEventrows for every product whose artifact changed. - Run profile and profile-link dry-run for all target hosts.
- Fail the release if dry-run reports unresolved product versions, profiles, configs, or properties.
- Emit profile events and product-version profile-link events.
- Verify
config_profile_config_t,config_profile_property_t, andproduct_version_config_profile_tcounts. - Smoke-test
getConfigUpdatePropertiesfor at least one instance, API, app, and app-api target for the release.
For patch releases where config does not change, the pipeline can use
inheritFrom and verify that the new version links to the same profile as the
previous version.
For Java common-library upgrades, all rebuilt Java products should receive new
product versions even if their own repositories did not change. If
configChanged=false, the mapping generator should inherit mappings from each
product’s previous version by reusing the previous profile link.
For breaking config releases, the pipeline should require an explicit manifest and should report added and removed configs/properties in the release note.
Backfill Existing Product Versions
Backfill is needed for product versions that already exist but have no profile link or still depend only on legacy direct mappings.
Backfill should support:
- one product version
- all versions of one product
- all products in one runtime family
- all active product versions for all hosts
Backfill must be conservative:
- create only missing active profiles and profile links
- never delete existing direct product-version mappings automatically
- report direct mappings that duplicate profile mappings so operators can decide whether to clean them up later
- report conflicting or inactive config/property definitions
- keep generated events deterministic
Backfill output should include counts by host, product, product version, profile, and direct legacy mappings so operators can confirm why a config update page was empty before the fix.
Migration from the current tables should be done in three steps:
- Create profiles from known Java and Rust manifests or from trusted existing product-version mappings.
- Link existing product versions to the correct profile.
- Leave existing direct mappings in place until query resolution proves the profile path covers the same configs/properties.
After migration, release automation should stop generating direct product-version mapping events for standard mappings. Direct mapping events remain available for tenant-specific additions.
Host and Tenant Handling
The profile manifest is host-neutral. The generator resolves global profile IDs once, then resolves tenant product-version IDs only for profile links.
For allHosts=true, the generator should query active hosts that have matching
product versions and create profile-link events per product version. It should
not generate per-host config/property mapping events for standard profile
mappings. If a host does not have the target product version, it should be
reported as skipped, not failed, unless the release request marks that product
version as required for every host.
Host-specific overrides are allowed through optional manifest sections:
{
"hostOverrides": {
"01964b05-552a-7c4b-9184-6857e7f3dc5f": {
"products": [
{
"productId": "gtw",
"directAdd": [
{
"configName": "tenant-plugin",
"properties": ["enabled", "endpoint"]
}
]
}
]
}
}
}
The default path should be shared profiles. Host overrides should be rare and visible in dry-run output.
Host overrides should not live in the public
lightapi/config-profile-manifests repository. They are tenant-specific
operational inputs and should be kept in private deployment overlays or entered
through the command API.
If a tenant needs to remove a standard profile property, assign a different profile to that product version. Avoid negative host-specific overrides in the MVP because they make query resolution and audit history harder to reason about.
Observability
The generator or command should publish a structured summary:
- release set
- runtime family
- host count
- product count
- generated profile events
- generated profile config events
- generated profile property events
- generated product-version profile-link events
- skipped existing profile links
- duplicate direct mappings
- missing product versions
- missing profiles
- missing configs
- missing properties
- failed hosts
The config update page empty-state message should reference this operational check: if an instance has no applicable config properties, verify the product version has a profile link or direct config/config-property mappings.
Phased Implementation
Phase 1: Manifest Generator for Importer
- Create and maintain Java and Rust mapping manifests in
lightapi/config-profile-manifests. - Validate manifests with the repository schema and workflow.
- Generate JSON import files for
ConfigProfile, profile config/property mappings, and product-version profile links. - Use direct IDs in generated events.
- Add dry-run validation and count reports.
- Use this path to backfill current local/dev deployments.
Phase 2: Sync Command
- Add
syncProductVersionConfigProfiles. - Support
dryRun,syncProfile,linkProfile,inheritProfile,backfillLinks, andverify. - Emit profile and profile-link events instead of direct SQL.
- Add RBAC so only product/release admins can run it.
Phase 3: Release Pipeline Integration
- Call dry-run during Java and Rust release workflows.
- Fail release on unresolved profiles, product versions, configs, or properties.
- Emit profile events and profile-link events after product versions are created.
- Record mapping summary in release artifacts.
Phase 4: Runtime Drift Detection
- Add scheduled or on-demand verification.
- Report active product versions with no profile link and no direct config mappings.
- Report config properties referenced by manifests but missing from
config_property_t. - Add a portal-view diagnostics link from the config update page.
Open Questions
- Should
ProductVersionCreatedEventoptionally carry aconfigProfileRef, or should profile linking remain a separate release step? - Do we need an organization-level policy to prevent inheritance for selected regulated products?
- Do we need a profile-clone command for tenant-specific removals, or is manual profile creation enough for the MVP?
Recommendation
Implement the profile schema and Phase 1 importer generator first, then add the sync command for live all-host operations.
The long-term target is release-time automation:
- product CI generates or validates the profile manifest in
lightapi/config-profile-manifestsfrom source metadata instead of relying on hand-maintained JSON - product release creates product versions
- profile dry-run validates configs/properties once
- profile-link dry-run validates every tenant product version
- profile and profile-link events are emitted or imported
- config update page works for the new release without manual follow-up
For Java, manifest generation should eventually come from a Maven plugin that
introspects the light-4j config modules or generated config metadata during
the build. For Rust, the equivalent should be a Cargo build script or release
tool that extracts config structs and their generated metadata. This keeps the
manifest aligned with the code and turns manual manifest editing into an
exception path.
This keeps the config update page simple and keeps product applicability in the event-sourced product release model without duplicating standard mappings for every tenant.
Release Workflow
Status
Proposed design.
Light Portal should use light-workflow as the durable release orchestrator
for Java and Rust releases. The workflow should coordinate repository checkout,
preflight validation, build, test, package, ConfigProfile manifest handling,
artifact publishing, AI-assisted failure diagnosis, and human approval.
The workflow engine should not execute release commands directly inside the
portal service process. Command execution belongs in a sandboxed release
runner, with light-workflow owning state, task routing, retries, approvals,
and audit history.
Problem
Java releases currently depend on light-bot, while Rust releases are handled
through separate command-line and repository-specific steps. This works, but it
keeps release knowledge outside the same workflow model used by Light Portal
for human tasks, automation tasks, and approval flows.
The release process is stateful and failure-prone:
- a release can span many repositories,
- Java and Rust products use different build and publish tools,
- a failure may require log analysis before the next action is obvious,
- publish and signing steps require stricter approval and secret handling,
- ConfigProfile manifests and generated import events must be checked before customers see the release as complete,
- an operator needs a durable record of what ran, what failed, what was fixed, and who approved publication.
The release workflow should be flexible enough to call existing command-line tools, but controlled enough that it does not become an unrestricted shell inside Light Portal.
Goals
- Replace the current Java
light-botrelease path withlight-workflowonce parity is proven. - Support both Java release trains and independent Rust product releases.
- Run build, test, package, and import-generation commands in sandboxed release runners.
- Capture command output, exit status, artifacts, and workspace changes as workflow task results.
- Let an AI agent analyze failed commands and propose or apply bounded fixes when policy allows it.
- Escalate unclear, risky, or approval-required cases to human tasks.
- Integrate ConfigProfile manifest validation and
event-importerdry-run reporting into the release gate. - Keep publish, signing, tag creation, and external customer-visible actions behind explicit approval.
- Preserve release auditability and reproducibility.
Non-Goals
- Do not run arbitrary release commands in the Light Portal service process.
- Do not replace Maven, Cargo, Docker, GitHub CLI, or existing release scripts where they already work.
- Do not allow an AI agent to publish artifacts, sign releases, rotate secrets, or push final tags without human approval.
- Do not make generated tenant-specific events public. Public release metadata should be portable manifests, not customer import output.
- Do not remove
light-botuntil Java release parity has been demonstrated through several successful workflow-managed releases.
Current State
light-bot is the practical Java release automation path today. It contains
working release knowledge and should remain available as a fallback during the
migration.
light-workflow is a good orchestration target because it already models
durable workflow instances, tasks, branching, context updates, and human task
patterns. The current executor supports control-plane task types such as
ask, assert, call, set, and switch.
The workflow model also defines run.container, run.script, run.shell, and
run.workflow. Those task types are the right DSL surface for release command
execution, but the runtime still needs sandbox-backed execution support before
release commands can move from scripts into light-workflow.
The ConfigProfile mapping work adds another release concern. Reusable profile
manifest files should live in the public lightapi/config-profile-manifests
repository. The release workflow should validate those manifests and use
event-importer to generate dry-run reports and import events for target
portal environments.
Recommended Architecture
Use light-workflow as the host-side orchestrator and delegate effectful
release work to sandboxed release runners.
Light Portal
|
| start release / approve / inspect task history
v
light-workflow
|
| durable tasks, branching, retries, audit
v
Sandboxed Release Runner
|
| git, mvn, cargo, docker, gh, event-importer
v
Release Repositories and Registries
The main components are:
light-workflow: Owns workflow instance state, task claiming, context, branching, retry policy, approval gates, human task creation, and audit metadata.- Release runner: Executes approved commands in a sandbox or controlled worker. It owns checkout directories, build caches, generated files, and command output capture.
- AI release assistant: Consumes failed command context, classifies the failure, proposes fixes, and optionally creates a bounded patch when policy allows it.
- Human task UI: Presents failed steps, AI analysis, command logs, proposed actions, and approval options.
- Release integrations: GitHub, Maven repositories, Cargo crates, Docker
registries, config-profile manifests,
event-importer, and deployment verification tools.
Execution Boundary
Host execution should be limited to orchestration and approved control-plane calls:
askassertsetswitch- context merge
- task claiming and completion
- process state persistence
- calls to approved internal APIs
Sandbox execution should be required for release effectors:
run.shellrun.scriptrun.container- repository checkout and mutation
- build, test, and package commands
- Docker build and image publishing
- Maven and Cargo publishing
- GitHub release and tag commands
event-importerexecution- external MCP server processes
- AI-agent tool execution that can mutate files or repositories
For normal build, test, package, and dry-run work, use one sandbox session per workflow instance. This lets checkout state, dependency caches, generated artifacts, and temporary files survive across related tasks.
For publish, signing, tag creation, and tasks with release secrets, use a fresh per-task sandbox with task-scoped secrets. These tasks should be isolated from the broader build workspace unless policy explicitly allows artifact transfer.
Release Lifecycle
The release workflow should follow this lifecycle.
- Create release request.
- Resolve release scope.
- Run preflight checks.
- Prepare the sandbox workspace.
- Build and test selected Java and Rust repositories.
- Validate ConfigProfile manifests.
- Run
event-importerdry-run for generated mapping events. - Package artifacts and images.
- Diagnose and repair failures when policy allows.
- Request human approval for publish.
- Publish artifacts, tags, images, and release notes.
- Verify published artifacts and generated portal events.
- Close the release workflow with a durable summary.
Release Request
The release request should be explicit enough to reproduce the run.
{
"releaseId": "2026.06.0",
"releaseType": "java-train",
"runtimeFamilies": ["java"],
"repos": [
{
"name": "light-4j",
"url": "https://github.com/networknt/light-4j.git",
"ref": "master",
"version": "2.3.5"
}
],
"configProfileManifest": {
"repo": "https://github.com/lightapi/config-profile-manifests.git",
"ref": "main",
"paths": ["java/light-gateway/2.3.5.json"]
},
"portalTargets": [
{
"name": "dev",
"hostId": "host-id-for-dev",
"dryRunRequired": true
}
],
"publishPolicy": {
"requireHumanApproval": true,
"allowAiPatch": true,
"maxRepairAttempts": 2
}
}
Rust product releases use the same shape, but releaseType can be
rust-products and the repository list can contain only the selected Rust
products.
Preflight Checks
The preflight stage should fail before any publishable side effect.
Required checks:
- requested release version is valid,
- target branches and tags do not already conflict,
- release repositories are reachable,
- release scripts and tool versions are available in the runner image,
- portal target credentials are present but not exposed in logs,
- ConfigProfile manifest files validate against the public schema,
event-importercan connect to the target read model for dry-run lookup,- no required human approval is missing.
Preflight failures should create a human task directly unless the error is a known repairable workspace issue.
ConfigProfile Gate
ConfigProfile mappings should be part of the release gate, not a manual afterthought.
The workflow should:
- Check out
lightapi/config-profile-manifests. - Validate every manifest selected by the release request.
- Run
event-importer --generate-config-profiles --dry-runfor each target portal environment. - Persist the dry-run report as a workflow artifact.
- Block publish if the report contains missing config or property references.
- Require human approval when
--replacewould delete profile mappings. - Emit or attach generated import events only after approval.
The public manifest repository should contain portable product profile contracts. Tenant-specific generated event files, customer host IDs, and private overrides should remain outside the public repository.
AI Failure Loop
When a command task fails, the release workflow should create a structured failure record and route it to the AI release assistant.
The record should include:
- workflow instance ID,
- failed task name and attempt number,
- command template and arguments,
- sanitized environment summary,
- exit code,
- stdout and stderr excerpts,
- full log artifact reference,
- repository status,
- changed files,
- relevant test reports or build artifacts,
- previous repair attempts.
The AI assistant should classify the failure before proposing a fix.
Recommended categories:
| Category | Example | Default Action |
|---|---|---|
| transient infrastructure | registry timeout, GitHub API rate limit | retry with backoff |
| dependency resolution | Maven or Cargo dependency conflict | propose dependency fix |
| compile failure | Java or Rust compiler error | propose source patch |
| test failure | deterministic unit test failure | propose source or test fix |
| release metadata | version, tag, changelog, manifest error | propose metadata patch |
| permission or secret | denied publish, missing token | create human task |
| policy violation | command not approved, network blocked | create human task |
| uncertain | unclear logs or risky patch | create human task |
If policy allows repair, the AI assistant can:
- inspect the checked-out repository,
- propose a patch,
- apply a patch in the sandbox,
- rerun the failed command or a narrower verification command,
- create a branch or pull request for human review.
The AI assistant must not:
- read or print release secrets,
- bypass workflow approvals,
- publish artifacts,
- sign artifacts,
- push final tags,
- change command allowlists,
- increase its own permission scope.
Retries must be bounded. After the configured retry limit, or after any high-risk classification, the workflow should create a human task.
Human Task Escalation
Human tasks are the safety valve for release automation. A failed or approval-required step should create a task with enough context for a quick decision.
The task should show:
- release ID and release type,
- failed workflow step,
- repository and ref,
- command result summary,
- log and artifact links,
- AI classification and confidence,
- proposed patch or action,
- affected products and portal targets,
- approval history,
- available actions.
Common actions:
- retry same step,
- approve AI patch and rerun,
- reject AI patch,
- open generated pull request,
- skip non-required product,
- abort release,
- approve publish,
- request manual intervention.
Workflow Definition Sketch
The exact DSL can evolve with light-workflow, but release definitions should
look like normal workflow definitions with sandbox metadata and run.* tasks.
document:
dsl: "1.0.3"
namespace: release
name: lightapi-release
version: "0.1.0"
metadata:
lightWorkflow:
security:
executionProfile: release-sandbox
sandbox:
mode: workflow-session
provider: cubesandbox
template: lightapi-release-runner
do:
- validate-config-profile-manifests:
run:
shell:
command: python3
arguments:
- scripts/validate-manifests.py
metadata:
lightWorkflow:
artifactPolicy:
capture:
- validation-report.json
- build-java-products:
run:
shell:
command: ./release.sh
arguments:
- "${ .release.version }"
metadata:
lightWorkflow:
onFailure:
call: ai-release-diagnosis
- config-profile-dry-run:
run:
shell:
command: java
arguments:
- "-jar"
- "event-importer.jar"
- "--generate-config-profiles"
- "--manifest"
- "${ .release.configProfileManifestPath }"
- "--targetHostId"
- "${ .portal.hostId }"
- "--adminUserId"
- "${ .release.adminUserId }"
- "--output"
- "./generated"
- "--dry-run"
- approve-release:
ask:
assignee: "${ .release.owner }"
prompt: "Approve publishing release ${ .release.version }"
- publish-release:
run:
shell:
command: ./publish.sh
arguments:
- "${ .release.version }"
metadata:
lightWorkflow:
security:
sandbox:
mode: per-task
reason: release-token-isolation
secrets:
- github-release-token
- maven-publish-token
Command Result Contract
Each sandbox command should return a normalized task result so workflow branching and AI diagnosis do not depend on raw console parsing.
{
"taskName": "build-java-products",
"attempt": 1,
"command": "./release.sh 2.3.5",
"exitCode": 1,
"status": "failed",
"startedAt": "2026-06-07T18:10:00Z",
"completedAt": "2026-06-07T18:18:30Z",
"durationMs": 510000,
"stdoutRef": "artifact://release/2026.06.0/build-java/stdout.log",
"stderrRef": "artifact://release/2026.06.0/build-java/stderr.log",
"summary": "Maven test failure in db-provider",
"changedFiles": [],
"artifacts": [
"artifact://release/2026.06.0/build-java/surefire-reports.zip"
]
}
The workflow context should store references and summaries, not unbounded logs. Full logs belong in artifact storage with retention and access policy.
Security Requirements
Release automation needs stricter controls than normal background tasks.
- Commands must come from approved workflow definitions or approved templates.
- The runner image must be versioned and auditable.
- Network egress must be policy controlled.
- Secrets must be scoped to the smallest task that needs them.
- Logs must be redacted before they are stored or sent to AI analysis.
- Publish and signing tasks require human approval.
- AI repair tasks must have bounded retry counts and clear write permissions.
- Workflow audit records must include effective policy, runner image, command template, artifact references, approvals, and repair attempts.
- Release artifacts should be reproducible from the recorded repository refs, workflow definition version, runner image, and command results.
Phased Implementation
Phase 1: Runtime Foundation
- Implement sandbox-backed execution for
run.shell,run.script, andrun.container. - Define the command result contract.
- Add log capture, artifact storage references, and redaction.
- Add workflow and task metadata for execution security profiles.
- Keep publish tasks disabled until approval and secret policy are implemented.
Phase 2: Java Release Parity
- Model the existing
light-botJava release flow as a workflow definition. - Call the existing Java release scripts from sandbox tasks.
- Compare generated artifacts, tags, release notes, and publish behavior with
the current
light-botpath. - Run several releases with
light-botretained as fallback.
Phase 3: Rust Release Support
- Add Rust product release workflow definitions.
- Support Cargo build, test, package, image build, and publish tasks.
- Allow release requests to select one Rust product or a set of Rust products.
- Share the same approval and artifact model used by Java releases.
Phase 4: ConfigProfile Release Gate
- Check out and validate
lightapi/config-profile-manifests. - Run
event-importerdry-run for selected portal targets. - Persist dry-run reports as workflow artifacts.
- Require approval for replacement deletes or missing-reference exceptions.
- Emit approved import events through the normal event-import path.
Phase 5: AI Repair Loop
- Add AI failure classification for failed command tasks.
- Allow bounded AI patch attempts in sandbox workspaces.
- Create branches or pull requests for human review.
- Add retry policy and automatic escalation after uncertain or exhausted repairs.
Phase 6: Publish and Verification
- Add per-task sandbox isolation for signing and publish tasks.
- Add post-publish verification for Maven, Cargo, Docker, GitHub releases, and portal import events.
- Add release dashboard and final release summary.
- Retire
light-botafter Java parity and rollback procedures are proven.
Risks and Open Questions
- The sandbox runner must be reliable enough for long-running release builds.
- Artifact retention needs a concrete storage backend and access policy.
- Secret handling must be designed before publish tasks are enabled.
- The AI repair scope must be narrow enough to prevent accidental broad refactors during release pressure.
- Cross-repository version coordination needs a clear source of truth.
- Rollback behavior for partially published releases must be defined per artifact type.
- The first implementation should decide whether AI patches create pull requests by default or only update the sandbox workspace for operator review.
Recommendation
Moving Java and Rust releases to light-workflow is a good direction, provided
the migration treats light-workflow as the orchestrator and uses sandboxed
runners for command execution. This gives the release process durable state,
human approvals, AI-assisted diagnostics, and a single model for Java, Rust,
and ConfigProfile release gates.
The migration should be incremental. Keep light-bot as the Java fallback
until the workflow release path has matched it in real releases. Enable AI
analysis early, but keep AI-generated changes and all publish actions behind
explicit policy and human approval.
Optimistic Concurrency Control (OCC)
In the previous documento optimistic-pessimistic-ui, we have decided to leverage the OCC to prevent multiple users update the same aggregate at the same time from different browser sessions.
With OCC, we have the single point of necessary trust: the read model must be consistent enough to support the OCC check.
The concern here is the core trade-off of CQRS: Eventual Consistency.
The Problem: When Eventual Consistency Breaks OCC
Your system’s flow is:
- Read (UI): Reads
ReadModel (V=5)from Projection DB. - Write (Command Handler):
- Command arrives with
expectedVersion=5. - Handler verifies against Event Store (Source of Truth):
EventStore.currentVersionmust be5.
- Command arrives with
- The Stale Read Model Gap (The Problem):
- Event
E6is processed by the Command Handler and committed toEventStore (V=6). - Before the Consumer applies
E6to the Projection DB, the UI reads. - UI still reads
ReadModel (V=5)(STALE). - User submits
Command2 (expectedVersion=5). - The Conflict: The Command Handler checks
EventStore.currentVersionwhich is now 6. It sees6 != 5and throws a ConcurrencyException.
- Event
Result: The user is incorrectly told there was a conflict and must refresh, even though their original read was perfectly valid and their change was submitted before any other user’s command. The issue is that the read model was too slow to reflect the change that already happened in the source of truth.
The Solution: Shift the OCC Check to the Event Store’s Version
The best way to handle this and eliminate the dependency on the read model’s consistency is to ensure the UI’s OCC is based on the authoritative version from the Event Store itself.
Here are three practical options for injecting the authoritative version.
The “best” option balances data consistency (critical) against performance and complexity (practical). Given the context of a high-performance CQRS/ES application, here is the evaluation and recommendation.
Evaluation of Options for OCC Version Retrieval
| Option | Where Version is Fetched | Consistency Status | Performance Impact | Complexity | Evaluation |
|---|---|---|---|---|---|
1. Join with event_store_t (Pagination Query) | Read Model + Event Store | Authoritative (Best) | High (Slows down every page load, large joins are expensive). | High (Complex SQL, need to avoid full table scans). | POOR (Breaks Read Performance/Scalability). |
| 2. Button Click/Form Load | Dedicated Version Service (Event Store) | Authoritative (Best) | Low/Moderate (1 extra, quick, targeted query per form load). | Low/Moderate (Easy to implement service). | GOOD (Decouples Read/Write, best UX). |
| 3. Command Submission | Dedicated Version Service (Event Store) | Authoritative (Best) | Low (1 extra query per command). | Low/Moderate (Easy to implement service). | GOOD but FLAWED UX (Causes more false failures). |
The Recommended Option: Option 2 (Button Click / Form Load)
Fetch the authoritative version when the user initiates the edit (button click / form load).
Why Option 2 is the Best Balance:
- Highest Consistency & UX: It provides the highest level of consistency without sacrificing the performance of the common “list entities” query. When the user loads the edit form, they are guaranteed to see the latest version. If another user commits a change before the form loads, the user will see the newest data and version, preventing the immediate “false conflict.”
- Performance Preservation: The most frequently executed query (
queryAllEntitiesWithPagination) remains fast, hitting only the optimized Projection DB. The extra query (VersionLookup) only runs when a user takes the action to edit, which is a rare event compared to listing. - Simplicity: It requires a simple, dedicated, fast endpoint in your backend (e.g.,
/api/version/role/{id}) that executes theSELECT MAX(sequence_number) ...query against yourevent_store_t.
Why the Other Options Fail:
- Option 1 (Join with Pagination Query): Fails Scalability. Joining a wide, paginated projection table with a potentially massive, ever-growing
event_store_ttable (even with indexes) is a performance killer. It makes every single query slow. You use CQRS to avoid this kind of cross-cutting query. - Option 3 (Command Submission): Fails User Experience.
- User loads data (Version 5).
- User spends 5 minutes making changes.
- During those 5 minutes, another user commits V6 and V7.
- User submits
Command (expectedVersion=5). - Handler fetches latest version (V7). Conflict: 7 != 5.
- User is rejected and loses 5 minutes of work.
- By contrast, Option 2 would have made the user refresh immediately upon clicking ‘Edit’ (because the version check would have failed then), saving the user from losing their work.
Implementation Flow for Option 2 (The Correct Flow)
- UI/List View: Populated from
Projection.queryEntities(offset, limit, filters). This query is fast and returns the version from Read Model. (The version might be the stale one). - User Action: User clicks “Edit” button for
role_id=R1. - Backend Call 1 (Version Check): UI calls a dedicated endpoint:
/api/write/version/{aggregate_id}(R1). The backend executesSELECT MAX(aggregate_version) FROM event_store_t WHERE aggregate_id = 'R1'. ReturnscurrentVersion = V. - Version Comparison 1: Compare the V with aggregate_version of the UI form data derived from the list view. If they are the same, no further action.
- Backend Call 2: If the form data version is less than the V from event_store_t, UI calls
/api/read/role/{id}to get fresh form data from the Read Model. - Version Comprison 2: Compare the V with aggregate_version reload from the Read Model. In most of the case, they should be the same. However, the Read Model might not be updated if there is consumer lag. In this case, an error message will be shown on the UI to inform user to wait several minutes to refresh. If problem persist, the user needs to report to the support team to get the issue resolved.
- UI Form: Data is populated. A hidden field is set to
aggregateVersion = V. - User Submission: UI sends
UpdateCommand(..., expectedVersion=V)to the command endpoint. - Command Handler: Executes OCC check against the Event Store. This check is now authoritative and highly likely to succeed.
Aggregate Version in Projection
Adding aggregate_version in all tables in read models is the most common, reliable, and scalable pattern to implement Optimistic Concurrency Control (OCC) in a CQRS/Event Sourcing system that uses a relational database for its read models.
Confirmation of the OCC Pattern
| Component | Responsibility for OCC | Details |
|---|---|---|
| Projection Tables (Read Model) | Store the Version | Required: Must have an aggregate_version column (e.g., BIGINT) on every entity row that represents an Aggregate Root. |
| Pagination/List Query (UI Read) | Retrieve the Version | Required: The API endpoint for listing entities must include the aggregate_version column in its SELECT statement and return it to the UI. |
| UI Form (Client) | Hold the Version | Required: The UI must store this retrieved aggregate_version (often in a hidden field) and rename it to expectedVersion for the next command. |
| Command Handler (Write Model) | Perform the Check | Required: When the command arrives, check: EventStore.actualVersion MUST EQUAL command.expectedVersion. |
Summary of Why This is Necessary
- Atomicity of the Check: The
aggregate_versionin the read model serves as the handle for the OCC check. The UI has to pass some authoritative marker of the state it observed. - Decoupling: By having the version in the read model, you avoid performing costly
SELECT MAX(sequence_number)queries against theevent_store_tfor every single row in the pagination result. Instead, you only perform the authoritative version lookup (or the OCC check itself) on the one specific record the user is attempting to modify. - Read/Write Split: This solution maintains the separation of concerns:
- Read Side: Fast, optimized for retrieval.
- Write Side: Slow, transactionally consistent, responsible for the final state check.
Final Recommendation:
Yes, we must include aggregate_version in all projected tables that are used as the basis for user updates, and it must be part of the data retrieved by the UI’s list queries.
This is the non-negotiable step to ensuring your access control system prevents the dangerous “Last-Write-Wins” scenario.
Refresh Data for Edit
We need to get the latest data after user click the ‘Edit’ button, there are two ways to get the lastet data: Read model or Replay. Let’s clarify exactly what data consistency level is needed for the “Edit” form.
The answer is: You should read the data from the Read Model (Projection) and retrieve the latest aggregate_version from the Event Store.
You should NOT replay the Event Store to populate the UI form.
Analysis of the Two Read Operations
| Operation | Source | Purpose | Consistency Level | Performance |
|---|---|---|---|---|
| Data Retrieval | Read Model (role_t Projection) | To populate the UI form fields (name, description, etc.). | Eventual (It’s the data the user sees). | Fast (Single row lookup by PK). |
| Version Retrieval | Event Store (event_store_t) | To provide the authoritative expectedVersion for OCC. | Strictly Authoritative (Source of Truth). | Fast (Single SELECT MAX(sequence_number) WHERE aggregate_id=? query). |
| Replay Operation | Event Store (event_store_t) | To reconstruct the current state by re-running all events. | Source of Truth (Highest fidelity). | Slow (Involves reading many rows, deserialization, and business logic execution). |
Why Combining Read Model + Version Lookup is Best
The flow for the /api/read/role/{id} endpoint should be:
-
Retrieve Authoritative Version:
- Execute:
SELECT MAX(sequence_number) AS authoritative_version FROM event_store_t WHERE aggregate_id = ? - (This is fast).
- Execute:
-
Retrieve Data (The actual form fields):
- Execute:
SELECT * FROM role_t WHERE role_id = ? - (This is also fast).
- Execute:
-
Combine and Return:
- Return the data from the Read Model and replace the
aggregate_versionin the final JSON with theauthoritative_versionretrieved in Step 1.
// Final API Response { "roleId": "R1", "roleDesc": "...", // Data from Read Model "updateUser": "...", // Data from Read Model "aggregateVersion": [Authoritative_Version_from_ES] // Replaced version from Event Store } - Return the data from the Read Model and replace the
Reasons for this Approach:
- Speed (Performance): Replaying the Event Store is computationally expensive and slow. You would never do this for a simple read-to-populate-a-form scenario unless the Read Model was completely missing the data. Using the existing projected data for the form fields is orders of magnitude faster.
- Decoupling (Read/Write Split): This maintains the CQRS separation. The Read Model is still the source for what is displayed to the user. The Event Store is only queried for the transactional anchor (
MAX(sequence_number)). - Consistency (High Enough): By replacing the read model’s version (
V_stale) with the authoritative version (V_authoritative), you achieve transactional consistency for the critical OCC field, and high eventual consistency for the form data (since the event consumer should be very fast at updating the read model).
What if the Read Model is Out of Sync?
The only time this approach is problematic is if the read model is severely stale (e.g., the consumer has been down for hours). In this case, the form data the user sees might not reflect the most recent events, even though the aggregateVersion is correct.
- Example: Event E6 added a field
is_admin = true. The consumer is down. The Read Model doesn’t haveis_admin = true. The UI loads the form, setsaggregateVersion=V6, but the form field foris_adminis missing. - Mitigation: The expectation in a healthy CQRS system is that the read model lag is measured in milliseconds, not minutes or hours. If lag is severe, the solution is to fix the consumer and the Eventual Consistency pipeline, not to slow down every read operation by resorting to full Event Replay.
Conclusion: The solution is to mix and match: Read data from the projection, but read the version from the source of truth (Event Store).
Eventual Consistency Trade Off
Availability/consistency trade-off is the most nuanced and important philosophical point in CQRS/Event Sourcing.
It is correct that Option 2 (Version Lookup on Button Click) temporarily breaks pure eventual consistency for the purpose of transactional integrity.
Here is the detailed elaboration on why this is necessary and how it redefines the consistency boundary, rather than fundamentally destroying the trade-off.
1. The Principle of Eventual Consistency (EC)
- Definition: The system state (Read Model) will eventually equal the Source of Truth (Write Model/Event Store) after a small delay ($\Delta t$).
- Trade-Off: You trade strong/immediate consistency for high availability and high performance (speed of writes and reads).
- The Acceptable Lie: The Read Model is allowed to lie for $\Delta t$ seconds.
2. The Unacceptable Lie: Breaking Transactional Integrity
The moment a user wants to perform a write operation, the system must enforce Strong Consistency for that single transaction, regardless of the CQRS pattern.
- Goal of the Transaction: To guarantee that the command (write) is based on a known, singular, correct state of the Aggregate.
- The Problem: If we use the stale version from the Projection DB (
V_stale), and the Write Model is atV_authoritative, one of two things happens:- If
V_authoritative > V_stale(Stale Read): The command is rejected (correctly by the Command Handler’s OCC check). The user is told to refresh. - If we tried to bypass OCC: A new event is generated based on stale data, potentially creating an invalid state (e.g., inventory going negative). This is a data integrity failure.
- If
Conclusion: For the Write Path, you must have Strong Consistency. The Write Path does not participate in the EC trade-off.
3. Why Option 2 is the Best Synthesis (The Redefined Trade-Off)
Option 2 queries Projection AND Event Store) is a controlled and highly localized violation of pure EC that elevates transactional integrity.
| Operation | Consistency Mechanism | Status |
|---|---|---|
| A. List View | Eventual Consistency (EC) | Hits Projection DB only. Fast. Can be stale. $\checkmark$ |
| B. Button Click/Form Load | Read-Your-Own-Writes Consistency (RYOW) / Strong Consistency | Hits Event Store for Version ONLY. Checks V_stale against V_authoritative. If V_stale < V_authoritative, the read is aborted, forcing a fresh, consistent read for the form. $\checkmark$ |
| C. Command Submission | Optimistic Concurrency Control (OCC) / Strong Consistency | Hits Event Store for the final check. Guarantees data integrity. $\checkmark$ |
The “Controlled Violation” Justification
- Only for the Edit Form: The slow, authoritative query is only done for one Aggregate when a user chooses to edit it. This minimizes performance impact.
- Only for the Version: The authoritative query (
SELECT MAX(sequence_number)) is the lightest possible query against the Event Store, ensuring minimum latency for this strong consistency check. It doesn’t incur the cost of full Event Replay or full Projection DB reads. - Redefining the UX Contract: You are establishing a clear contract: “The List View is for quick display (EC). The Edit Form guarantees that the state you see is the last known state, and we checked the Source of Truth just for you (Strong Consistency).”
The Availability Trade-off is NOT Broken:
- Availability: The Write Model (Command Handler) is still available. The Read Model (Projection) is still available. The system has not halted.
- Performance: The List View remains fast (available). The Write Path remains fast (available).
- The Cost: The cost is one extra, fast, authoritative query right before the edit begins, which is a small price to pay for preventing a major data integrity or user experience failure.
Summary
The pattern you are implementing with Option 2 (Projection Data + Event Store Version) is the standard, correct way to implement OCC across the Read-Write boundary in a performant CQRS/ES system. It is a necessary local “tightening” of the eventual consistency model to ensure transactional correctness where it absolutely matters: at the point of data modification.
Cascade Soft Delete
With the recent refactor, relying on ON DELETE CASCADE is no longer suitable after implementing soft deletes, because soft delete is an UPDATE operation (SET active = FALSE) and not a true DELETE from the database.
The pattern we should follow in an Event Sourcing / Event-Driven Architecture with soft deletes is:
1. The Principle of Causality (or Domain Consistency)
When a parent entity (e.g., role_t) is soft-deleted, all its dependent children entities (e.g., role_user_t, role_permission_t, etc.) must also be soft-deleted to maintain domain consistency. This cascade logic must be implemented in the application layer (the projection service or command handler or database).
2. Implementation in the Command/Event Handler/Database
Strategy A: Event Amplification
The command handler that received the initial command/event (e.g., DeleteRoleCommand -> RoleDeletedEvent) should not directly perform the cascading database updates. Instead, it should be responsible for emitting new cascading events for each child entity.
- Incoming Command: Generate a
RoleDeletedEvent(for a specificrole_id). - Emitting Child Events: It then emits an event for each dependent child, such as
RoleUserRemovedEvent(role_id, user_id)andRolePermissionRemovedEvent(role_id, permission_id). - Event Store: Push an array of events to event_store_t and outbox_message_t tables in a transaction.
- Event Processor: All events will be processed in the same transaction to update parent table and child tables together.
Pro: Decoupled, explicit, audit trail for every change. Con: More complex event processing, increased event volume; Need to refactor all delete command handlers to emit more events and it is significant code change and long term maintenance work.
Strategy B: Direct Application-Level Cascade
In a service that primarily acts as a projection (CQRS read model) and is tightly coupled with its projection logic, the simplest approach is to bundle the cascading logic directly into the parent handler’s processing.
- Incoming Event:
RoleDeletedEvent. - Event Processor: The
deleteRole(conn, event)method would execute the parent soft delete (UPDATE role_t SET active=FALSE). - Cascading Updates: Immediately after, within the same transaction, it would execute multiple cascading
UPDATEstatements on the child tables. Make sure that only the active flag is updated based on the primary key for child tables.
// Inside deleteRole(Connection conn, Map<String, Object> event)
// 1. Soft delete the parent
// UPDATE role_t SET active = FALSE WHERE ...
// 2. Soft delete the children in the same transaction
// UPDATE role_user_t SET active = FALSE, update_user = ?, update_ts = ? WHERE host_id = ? AND role_id = ?
// UPDATE role_permission_t SET active = FALSE, update_user = ?, update_ts = ? WHERE host_id = ? AND role_id = ?
Pro: Simple, fast, maintains transactional integrity easily. Con: Tightly couples the projection logic; no explicit events for child deletion in the event store; Many db provider update and long term maintenace work.
Strategy C: Direct Database-Level Cascade
Create a trigger in database to manage the cascade soft delete for child tables. This can be individual trigger on each table or a centralized trigger to apply on all tables.
Pro: Simple, fast, maintains transactional integrity easily. Minimum code change in app logic and easy to implement and maintain. Con: Need to make sure that the project team is aware of the logic to void confusions.
Create a cascade_relationships_v view based on the foreign keys.
-- create a view to simplify the foreign key relationship.
DROP VIEW IF EXISTS cascade_relationships_v;
CREATE VIEW cascade_relationships_v AS
WITH fk_details AS (
SELECT
pn.nspname::text AS parent_schema,
pc.relname::text AS parent_table,
cn.nspname::text AS child_schema,
cc.relname::text AS child_table,
c.conname::text AS constraint_name,
c.oid AS constraint_id,
cc.oid AS child_table_oid,
pc.oid AS parent_table_oid,
unnest.parent_col,
unnest.child_col,
unnest.ord
FROM pg_constraint c
JOIN pg_class pc ON c.confrelid = pc.oid
JOIN pg_namespace pn ON pc.relnamespace = pn.oid
JOIN pg_class cc ON c.conrelid = cc.oid
JOIN pg_namespace cn ON cc.relnamespace = cn.oid
CROSS JOIN LATERAL (
SELECT
unnest(c.confkey) AS parent_col,
unnest(c.conkey) AS child_col,
generate_series(1, array_length(c.conkey, 1)) AS ord
) unnest
WHERE c.contype = 'f'
)
SELECT
fd.parent_schema,
fd.parent_table,
fd.child_schema,
fd.child_table,
fd.constraint_name,
-- Human readable mapping
string_agg(
format('%I → %I',
(SELECT attname FROM pg_attribute
WHERE attrelid = fd.parent_table_oid
AND attnum = fd.parent_col),
(SELECT attname FROM pg_attribute
WHERE attrelid = fd.child_table_oid
AND attnum = fd.child_col)
),
', ' ORDER BY fd.ord
) AS foreign_key_mapping,
-- Structured data for trigger
jsonb_object_agg(
(SELECT attname FROM pg_attribute
WHERE attrelid = fd.parent_table_oid
AND attnum = fd.parent_col),
(SELECT attname FROM pg_attribute
WHERE attrelid = fd.child_table_oid
AND attnum = fd.child_col)
) AS foreign_key_json,
-- Arrays for easier processing
array_agg(
(SELECT attname FROM pg_attribute
WHERE attrelid = fd.parent_table_oid
AND attnum = fd.parent_col)
ORDER BY fd.ord
) AS parent_columns,
array_agg(
(SELECT attname FROM pg_attribute
WHERE attrelid = fd.child_table_oid
AND attnum = fd.child_col)
ORDER BY fd.ord
) AS child_columns,
COUNT(*) AS column_count,
fd.child_table_oid,
fd.parent_table_oid,
-- Check for required columns
EXISTS (
SELECT 1 FROM pg_attribute a
WHERE a.attrelid = fd.parent_table_oid
AND a.attname = 'delete_ts'
AND NOT a.attisdropped
) AS parent_has_delete_ts,
EXISTS (
SELECT 1 FROM pg_attribute a
WHERE a.attrelid = fd.child_table_oid
AND a.attname = 'delete_ts'
AND NOT a.attisdropped
) AS child_has_delete_ts,
EXISTS (
SELECT 1 FROM pg_attribute a
WHERE a.attrelid = fd.parent_table_oid
AND a.attname = 'delete_user'
AND NOT a.attisdropped
) AS parent_has_delete_user,
EXISTS (
SELECT 1 FROM pg_attribute a
WHERE a.attrelid = fd.child_table_oid
AND a.attname = 'delete_user'
AND NOT a.attisdropped
) AS child_has_delete_user
FROM fk_details fd
-- Only include relationships where both tables have deletion tracking
WHERE EXISTS (
SELECT 1 FROM pg_attribute a
WHERE a.attrelid = fd.parent_table_oid
AND a.attname = 'delete_ts'
AND NOT a.attisdropped
) AND EXISTS (
SELECT 1 FROM pg_attribute a
WHERE a.attrelid = fd.child_table_oid
AND a.attname = 'delete_ts'
AND NOT a.attisdropped
)
GROUP BY
fd.parent_schema, fd.parent_table,
fd.child_schema, fd.child_table,
fd.constraint_name, fd.constraint_id,
fd.child_table_oid, fd.parent_table_oid
ORDER BY fd.parent_schema, fd.parent_table, fd.child_schema, fd.child_table;
To test the view above.
SELECT * FROM cascade_relationships_v
WHERE parent_table = 'api_t' AND child_table = 'api_version_t';
And the result.
parent_schema parent_table child_schema child_table constraint_name foreign_key_mapping foreign_key_json parent_columns child_columns column_count child_table_oid parent_table_oid parent_has_delete_ts child_has_delete_ts parent_has_delete_user child_has_delete_user
------------- ------------ ------------ ------------- --------------------------------- ---------------------------------- ------------------------------------------ -------------------- -------------------- ------------ --------------- ---------------- -------------------- ------------------- ---------------------- ---------------------
public api_t public api_version_t api_version_t_host_id_api_id_fkey host_id → host_id, api_id → api_id {"api_id": "api_id", "host_id": "host_id"} ["host_id","api_id"] ["host_id","api_id"] 2 360279 360268 true true true true
Create a function for update active to true and false.
CREATE OR REPLACE FUNCTION smart_cascade_soft_delete()
RETURNS TRIGGER AS $$
DECLARE
fk_record RECORD;
where_clause TEXT;
query_text TEXT;
column_index INT;
current_user_name TEXT;
deletion_context TEXT;
deletion_context_pattern TEXT;
delete_timestamp TIMESTAMP;
BEGIN
-- Get current user
current_user_name := current_user;
-- Handle SOFT DELETE (active = false)
IF NEW.active = FALSE AND OLD.active = TRUE THEN
-- Generate deletion timestamp
delete_timestamp := CURRENT_TIMESTAMP;
-- Set deletion context
deletion_context := format('PARENT_CASCADE_%s_%s',
TG_TABLE_NAME,
to_char(delete_timestamp, 'YYYYMMDD_HH24MISSMS')
);
-- Update parent with deletion context if columns exist
IF EXISTS (
SELECT 1 FROM information_schema.columns
WHERE table_schema = TG_TABLE_SCHEMA
AND table_name = TG_TABLE_NAME
AND column_name = 'delete_user'
) THEN
NEW.delete_user := deletion_context;
END IF;
IF EXISTS (
SELECT 1 FROM information_schema.columns
WHERE table_schema = TG_TABLE_SCHEMA
AND table_name = TG_TABLE_NAME
AND column_name = 'delete_ts'
) THEN
NEW.delete_ts := delete_timestamp;
END IF;
-- Update parent's update columns
NEW.update_ts := delete_timestamp;
NEW.update_user := current_user_name;
FOR fk_record IN
SELECT *
FROM cascade_relationships_v
WHERE parent_schema = TG_TABLE_SCHEMA
AND parent_table = TG_TABLE_NAME
LOOP
-- Build WHERE clause
where_clause := '';
FOR column_index IN 1..fk_record.column_count LOOP
IF column_index > 1 THEN
where_clause := where_clause || ' AND ';
END IF;
where_clause := where_clause || format(
'%I = $1.%I',
fk_record.child_columns[column_index],
fk_record.parent_columns[column_index]
);
END LOOP;
-- Add condition to only update currently active records
where_clause := where_clause || ' AND active = TRUE';
-- Cascade the soft delete with context
query_text := format(
'UPDATE %I.%I
SET active = FALSE,
delete_ts = $2,
delete_user = $3,
update_ts = $2,
update_user = $4
WHERE %s',
fk_record.child_schema,
fk_record.child_table,
where_clause
);
EXECUTE query_text USING OLD, delete_timestamp, deletion_context, current_user_name;
END LOOP;
-- Handle RESTORE (active = true)
ELSIF NEW.active = TRUE AND OLD.active = FALSE THEN
-- Only restore children that were deleted by parent cascade
FOR fk_record IN
SELECT *
FROM cascade_relationships_v
WHERE parent_schema = TG_TABLE_SCHEMA
AND parent_table = TG_TABLE_NAME
LOOP
-- Pattern to match cascade deletions
deletion_context_pattern := format('PARENT_CASCADE_%s_%%', TG_TABLE_NAME);
-- Build WHERE clause
where_clause := '';
FOR column_index IN 1..fk_record.column_count LOOP
IF column_index > 1 THEN
where_clause := where_clause || ' AND ';
END IF;
where_clause := where_clause || format(
'%I = $1.%I',
fk_record.child_columns[column_index],
fk_record.parent_columns[column_index]
);
END LOOP;
-- Only restore cascade-deleted records
where_clause := where_clause ||
' AND delete_user LIKE $2 AND active = FALSE';
-- Restore the records
query_text := format(
'UPDATE %I.%I
SET active = TRUE,
delete_ts = NULL,
delete_user = NULL,
update_ts = CURRENT_TIMESTAMP,
update_user = $3
WHERE %s',
fk_record.child_schema,
fk_record.child_table,
where_clause
);
EXECUTE query_text USING OLD, deletion_context_pattern, current_user_name;
END LOOP;
-- Clear parent's deletion context
IF EXISTS (
SELECT 1 FROM information_schema.columns
WHERE table_schema = TG_TABLE_SCHEMA
AND table_name = TG_TABLE_NAME
AND column_name = 'delete_user'
) THEN
NEW.delete_user := NULL;
END IF;
IF EXISTS (
SELECT 1 FROM information_schema.columns
WHERE table_schema = TG_TABLE_SCHEMA
AND table_name = TG_TABLE_NAME
AND column_name = 'delete_ts'
) THEN
NEW.delete_ts := NULL;
END IF;
-- Update parent's update columns
NEW.update_ts := CURRENT_TIMESTAMP;
NEW.update_user := current_user_name;
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
Install the trigger.
-- Apply cascade triggers only to tables that have BOTH active AND delete_ts columns
DO $$
DECLARE
table_record RECORD;
has_active_column BOOLEAN;
has_delete_ts_column BOOLEAN;
BEGIN
FOR table_record IN
SELECT
n.nspname AS schema_name,
c.relname AS table_name,
c.oid AS table_oid
FROM pg_class c
JOIN pg_namespace n ON c.relnamespace = n.oid
WHERE c.relkind = 'r' -- Regular tables only
AND n.nspname NOT IN ('pg_catalog', 'information_schema')
AND EXISTS (
SELECT 1 FROM pg_constraint con
JOIN pg_class ref ON con.confrelid = ref.oid
WHERE con.contype = 'f'
AND ref.oid = c.oid
)
LOOP
-- Check if table has required columns
SELECT EXISTS (
SELECT 1 FROM pg_attribute a
WHERE a.attrelid = table_record.table_oid
AND a.attname = 'active'
AND NOT a.attisdropped
) INTO has_active_column;
SELECT EXISTS (
SELECT 1 FROM pg_attribute a
WHERE a.attrelid = table_record.table_oid
AND a.attname = 'delete_ts'
AND NOT a.attisdropped
) INTO has_delete_ts_column;
IF NOT (has_active_column AND has_delete_ts_column) THEN
RAISE NOTICE 'Skipping %.% - missing required columns (active: %, delete_ts: %)',
table_record.schema_name, table_record.table_name,
has_active_column, has_delete_ts_column;
CONTINUE;
END IF;
-- Drop existing trigger if it exists
EXECUTE format(
'DROP TRIGGER IF EXISTS trg_cascade_soft_ops ON %I.%I',
table_record.schema_name, table_record.table_name
);
-- Create new trigger
EXECUTE format(
'CREATE TRIGGER trg_cascade_soft_ops
AFTER UPDATE OF active ON %I.%I
FOR EACH ROW
EXECUTE FUNCTION smart_cascade_soft_delete()',
table_record.schema_name, table_record.table_name
);
RAISE NOTICE 'Created cascade trigger on %.%',
table_record.schema_name, table_record.table_name;
END LOOP;
END $$;
The above appoach has the following benefits.
-
Clean separation: delete_ts/delete_user are dedicated to soft delete tracking
-
Clear semantics: Easy to understand and query
-
No interference: Doesn’t conflict with update_ts/update_user for normal updates
-
Intelligent restoration: Can restore only cascade-deleted records
-
Audit trail: Complete history of who deleted what and when
This approach ensures you only restore child entities that were cascade-deleted, maintaining data integrity while providing a clear audit trail.
3. Special Handler for deletion of Host and Org
Due to the significant tables that needs to be updated when deleting a host or an org, we need to rely on the cascade delete of the database. So deletion of host or org will be implemented as hard delete and it should be warned to users on the UI interface.
4. Add delete_ts column to reverse cascade soft delete
After cascade soft delete for role_t, all children entities will be marked as active = false. When add back the same role again, we need to mark all the cascade delete children entities to active = true. However, we need to avoid updating the rows that were soft deleted individually. By adding a delete_ts, we can use it to find out all related children entities that are cascade deleted.
5. Update queries to add active = true condition
We need to update some queries in the db provider to add conditions for each joining table with active = true so that only active rows will be returned.
Conclusion:
Based on our team discussion, we are going to:
- Adopt the third option that use db trigger to do that same like the hard cascade delete.
- Change the org and host delete to hard delete.
- Update some queries to add condition to check the active = true.
Query Active Rows
Since we use soft deletes for most tables in the read model, we need to apply an active = true filter to our queries.
For single-table queries, this is straightforward—we can simply add AND active = true to the query. However, for join queries involving multiple tables, the active = true condition must be applied consistently across all participating tables, ideally in an automatic manner.
There are two approaches we can take on top of the current database provider implementation:
Active in filters
@Override
public Result<String> queryRolePermission(int offset, int limit, String filtersJson, String globalFilter, String sortingJson, String hostId) {
boolean isActive = true; // Default to true (active records only)
// Iterate safely to find and remove the 'active' filter to handle it manually
if (filters != null) {
Iterator<Map<String, Object>> it = filters.iterator();
while (it.hasNext()) {
Map<String, Object> filter = it.next();
if ("active".equals(filter.get("id"))) {
Object val = filter.get("value");
if (val != null) {
isActive = Boolean.parseBoolean(val.toString());
}
it.remove(); // Remove from list so dynamicFilter doesn't add it again
break;
}
}
}
StringBuilder activeSql = new StringBuilder();
if (isActive) {
// Strict consistency: A record is only "active" if all related entities are active
activeSql.append(" AND rp.active = true");
activeSql.append(" AND r.active = true");
activeSql.append(" AND ae.active = true");
activeSql.append(" AND av.active = true");
} else {
// Soft-deleted view: Usually we only care that the specific record itself is inactive
activeSql.append(" AND rp.active = false");
}
}
Pros
- No need to change the signature, UI and service layer.
Cons
- Need to iterate all filters to find the active flag per call.
Active as a seperate parameter
@Override
public Result<String> queryRolePermission(int offset, int limit, String filtersJson, String globalFilter, String sortingJson, boolean active, String hostId) {
StringBuilder activeSql = new StringBuilder();
if (active) {
// Strict consistency: A record is only "active" if all related entities are active
activeSql.append(" AND rp.active = true");
activeSql.append(" AND r.active = true");
activeSql.append(" AND ae.active = true");
activeSql.append(" AND av.active = true");
} else {
// Soft-deleted view: Usually we only care that the specific record itself is inactive
activeSql.append(" AND rp.active = false");
}
}
Pros
- Logic is simple in the query.
Cons
- Need to change the service layer and UI to add an additional parameter.
Conclusion
We recommend proceeding with Option 2. While it requires an initial refactor of the Service and UI layers, it provides strict type safety and cleaner code.
Reasoning:
-
Code Reuse: Option 1 requires repeating the filter iteration logic inside every DAO method. Option 2 keeps DAO methods clean.
-
Semantics: The active status affects multiple table joins (Data Integrity), distinguishing it from standard column filters. It should be an explicit argument.
-
Maintainability: Option 2 decouples the Database layer from the UI’s JSON structure. If the UI changes how it sends the active status, we only change the extraction logic in the Controller, not every SQL query method.
Distributed Scheduler Design
Introduction
The Distributed Scheduler is a robust, highly available component of the light-portal architecture that manages the periodic execution of tasks across a cluster of application instances. It ensures that scheduled tasks are executed exactly as defined, even in a distributed environment, by using a database-backed leader election and locking mechanism.
Architecture
The scheduler follows a Leader-Follower pattern to prevent redundant executions and ensure consistency.
- Leader Election: All scheduler instances compete for a global lock in the
scheduler_lock_ttable. - Lock Heartbeat: The leader periodically updates its heartbeat to maintain ownership. If the leader fails, another instance will eventually claim the lock after a timeout.
- Polling Loop: Only the leader performs the polling of the
schedule_ttable for due tasks. - Task Execution: When a task is due, the scheduler generates the corresponding event into the
event_store_tandoutbox_message_ttables and updates thenext_run_tsfor the next occurrence.
Database Schema
schedule_t
Stores the definitions and state of all scheduled tasks.
CREATE TABLE schedule_t (
schedule_id UUID NOT NULL,
host_id UUID NOT NULL,
schedule_name VARCHAR(126) NOT NULL,
frequency_unit VARCHAR(16) NOT NULL, -- e.g., 'MINUTES', 'HOURS', 'DAYS'
frequency_time INTEGER NOT NULL,
start_ts TIMESTAMP WITH TIME ZONE NOT NULL,
next_run_ts TIMESTAMP WITH TIME ZONE NOT NULL,
event_topic VARCHAR(126) NOT NULL,
event_type VARCHAR(126) NOT NULL,
event_data TEXT NOT NULL,
aggregate_version BIGINT DEFAULT 1 NOT NULL,
active BOOLEAN NOT NULL DEFAULT TRUE,
PRIMARY KEY(schedule_id)
);
CREATE INDEX idx_schedule_active_next_run ON schedule_t (active, next_run_ts);
scheduler_lock_t
Facilitates distributed locking and leader election.
CREATE TABLE scheduler_lock_t (
lock_id INT PRIMARY KEY, -- Static ID for the global scheduler lock
instance_id VARCHAR(255) NOT NULL, -- ID of the holding instance
last_heartbeat TIMESTAMP WITH TIME ZONE NOT NULL
);
Implementation Details
Leader Election and Heartbeat
Instances attempt to acquire the lock by updating the last_heartbeat if the existing heartbeat has expired (e.g., more than 60 seconds ago).
UPDATE scheduler_lock_t
SET instance_id = ?, last_heartbeat = CURRENT_TIMESTAMP
WHERE lock_id = 1 AND (instance_id = ? OR last_heartbeat < ?);
Polling Mechanism
The leader queries for tasks where next_run_ts <= CURRENT_TIMESTAMP and active = true.
SELECT * FROM schedule_t
WHERE active = true AND next_run_ts <= CURRENT_TIMESTAMP
ORDER BY next_run_ts ASC
LIMIT ?;
Next Run Timestamp Calculation
After a task is executed, the next_run_ts is incremented based on the frequency_unit and frequency_time.
- Interval-based: Adds the specified amount of time to the
next_run_ts. - Drift Correction: To prevent cumulative drift, the calculation is based on the original
start_tsor the previousnext_run_tsrather than the actual execution time.
Execution Flow
- Leader polls for due tasks.
- For each task:
- Starts a database transaction.
- Inserts the specified event into the event store and outbox message.
- Updates
next_run_tsinschedule_t. - Commits the transaction.
- The event is then picked up and processed by the Event Consumer (Kafka or Postgres).
Conclusion
The Distributed Scheduler provides a reliable and scalable way to handle periodic activities within the light-portal, ensuring that tasks are executed predictably and exclusively by a single active leader at any given time.
PostgreSQL Pub/Sub Design
Introduction
The PostgreSQL Pub/Sub mechanism provides an alternative to Kafka for event distribution within the light-portal architecture. It is designed for smaller deployments or environments where Kafka is not available, offering a reliable, low-latency, and strictly ordered event delivery system using native PostgreSQL features.
Architecture
The system utilizes a hybrid Polling + LISTEN/NOTIFY approach to achieve both high reliability and low latency.
1. Logical Partitioning
To support horizontal scalability and ensure ordered processing for multi-tenant environments, the system uses logical partitioning based on the host_id.
- Events are distributed across a fixed number of partitions (e.g., 8 or 16).
- Partition index =
abs(hashtext(host_id::text)) % total_partitions. - Each partition has its own progress tracker in
consumer_offsets.
2. Contiguous Offset Claiming
Within each partition, the consumer claims a batch of events using gapless logical offsets (c_offset).
3. Real-time Wake-up
To minimize latency without high-frequency polling, the system uses the PostgreSQL LISTEN/NOTIFY mechanism.
- A database trigger on the
outbox_message_ttable issues aNOTIFY event_channelwhenever new messages are inserted. - Consumers use
LISTEN event_channelto subscribe to these real-time signals. - The consumer loop calls
pgConn.getNotifications(timeout)to wait for signals. This allows the consumer thread to sleep efficiently and wake up immediately when work is available, while still falling back to a poll-based check if no notification is received within thewaitPeriodMs.
Database Schema
log_counter
Manages the global version/offset for the outbox.
CREATE TABLE log_counter (
id INT PRIMARY KEY,
next_offset BIGINT NOT NULL DEFAULT 1
);
INSERT INTO log_counter (id, next_offset) VALUES (1, 1);
consumer_offsets
Tracks the progress of each consumer partition.
CREATE TABLE consumer_offsets (
group_id VARCHAR(255),
topic_id INT, -- 1 for global outbox
partition_id INT, -- Logical partition index
next_offset BIGINT NOT NULL DEFAULT 1,
PRIMARY KEY (group_id, topic_id, partition_id)
);
outbox_message_t (Modified)
Stores the events to be published.
ALTER TABLE outbox_message_t ADD COLUMN c_offset BIGINT UNIQUE;
CREATE INDEX idx_outbox_offset ON outbox_message_t (c_offset);
Triggers and Functions
Enables the NOTIFY mechanism.
CREATE OR REPLACE FUNCTION notify_event() RETURNS TRIGGER AS $$
BEGIN
PERFORM pg_notify('event_channel', 'new_event');
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER event_trigger
AFTER INSERT ON outbox_message_t
FOR EACH STATEMENT EXECUTE FUNCTION notify_event();
Implementation Details
Offset Reservation
When inserting events, the system locks the log_counter row to reserve a range of offsets:
UPDATE log_counter SET next_offset = next_offset + ? WHERE id = 1 RETURNING next_offset - ?;
Competing Consumer Pattern
To support multiple instances within the same consumer group, logical offsets are “claimed” in batches using an atomic UPDATE ... RETURNING statement. This ensures that each event is processed exactly once by one member of the group.
WITH counter_tip AS (
SELECT (next_offset - 1) AS highest_committed_offset FROM log_counter WHERE id = 1
),
to_claim AS (
SELECT group_id, next_offset,
LEAST(batch_size, GREATEST(0, (SELECT highest_committed_offset FROM counter_tip) - next_offset + 1)) AS delta
FROM consumer_offsets
WHERE group_id = ? AND topic_id = 1
FOR UPDATE
),
upd AS (
UPDATE consumer_offsets c SET next_offset = c.next_offset + t.delta
FROM to_claim t
WHERE c.group_id = t.group_id AND c.topic_id = 1
RETURNING t.next_offset AS start_offset, (c.next_offset - 1) AS end_offset
)
SELECT start_offset, end_offset FROM upd;
Transactional User-Based Batching
To ensure that events generated from the same user are handled atomically and in order, the consumer employs a grouping strategy within its processing cycle:
- Fetch Batch: Read raw payloads from
outbox_message_tfor the assigned partition range. - Filter and Group:
- Filter messages by the partition hash:
abs(hashtext(host_id::text)) % ? = ?. - Group the filtered messages by
host_idanduser_id.
- Filter messages by the partition hash:
- Process by User:
- For each
(host_id, user_id)group, execute all events in a single database transaction.
- For each
Handling Large Atomic Transactions (Batch Extension)
If a business activity (e.g., “instance clone”) generates more events than the configured batchSize, these events should still be processed in a single transaction to maintain system consistency.
The consumer handles this via Atomic Batch Extension:
- After fetching the initial batch (e.g., 100 events), the consumer peeks at the next available event in the outbox.
- If the next event belongs to the same
user_idas the last event in the batch, the consumer continues fetching consecutive events for that user until the transaction boundary is found. - The
consumer_offsetsare then atomically updated to reflect the true end of the extended batch. - This ensures that even if 120 events were generated, all 120 are processed in a single transaction, regardless of the
batchSizelimit.
This approach ensures that even if events are processed in parallel across different partitions, events belonging to the same user are always handled in the same transaction, maintaining consistency across subsystems.
Transaction ID and Dead Letter Queue
Transaction ID
To provide precise boundaries for atomic transactions, the system uses a transaction_id column in the outbox_message_t table:
ALTER TABLE outbox_message_t ADD COLUMN transaction_id UUID;
When events are persisted to the outbox, all events generated within a single business transaction are assigned the same transaction_id (a UUID generated once per batch in EventPersistenceImpl.insertEventStore()).
This eliminates ambiguity when grouping events:
- Without
transaction_id: Events are grouped byhost_id:user_id, which may incorrectly group unrelated transactions from the same user. - With
transaction_id: Events are grouped by their exact transaction boundary, ensuring atomic processing of related events only.
Dead Letter Queue (DLQ)
When event processing fails, the system implements a granular fallback mechanism to prevent the entire batch from being blocked:
Schema
CREATE TABLE IF NOT EXISTS dead_letter_queue (
group_id VARCHAR(255),
host_id UUID,
user_id UUID,
c_offset BIGINT,
transaction_id UUID,
payload JSONB,
exception TEXT,
created_dt TIMESTAMP DEFAULT NOW()
);
Processing Flow
-
Normal Processing: The consumer attempts to process all events in a claimed batch within a single database transaction.
-
Batch Failure Detection: If any event in the batch fails (e.g., constraint violation, business logic error), the entire transaction is rolled back.
-
Fallback Mode: The consumer switches to
processBatchWithFallback():- Re-claims the same offset range.
- Groups events by
transaction_id. - For each transaction group:
- Creates a JDBC
Savepoint. - Attempts to process all events in that transaction.
- On success: Continues to the next transaction.
- On failure:
- Rolls back to the
Savepoint. - Inserts all events from the failed transaction into
dead_letter_queue. - Logs the error with the
transaction_idfor debugging.
- Rolls back to the
- Creates a JDBC
-
Commit: After processing all transactions (successful or moved to DLQ), the consumer commits the transaction, advancing the offset.
Benefits
- Isolation: Only the failing transaction is moved to DLQ; other transactions in the batch proceed normally.
- Atomicity: All events belonging to a single business transaction are either processed together or moved to DLQ together.
- No Blocking: The consumer never gets stuck on a single bad event.
- Debuggability: The DLQ table preserves the full context (payload, exception, transaction_id) for manual investigation and replay.
Configuration
The consumer is configured via db-event-consumer.yml and runs in a Java 21 Virtual Thread. This ensures that the frequent Thread.sleep (during retries) and the blocking pgConn.getNotifications() (waiting for wake-ups) do not tie up native system threads, making the consumer extremely lightweight.
# Postgres pub/sub event processor configuration
# Consumer group id and it is default to user-query-group. Please only change it if you
# know exactly what you are doing.
groupId: ${db-event-consumer.groupId:user-query-group}
# The batch size when polling from the database for events. It is not fixed and will be
# adjusted if there are more than 100 events belong to the same transaction.
batchSize: ${db-event-consumer.batchSize:100}
# The number of total partitions. It should be the same number of portal-query instances.
totalPartitions: ${db-event-consumer.totalPartitions:1}
# Partition id starting from 0 to totalPartitions - 1 to assign each portal query instance.
partitionId: ${db-event-consumer.partitionId:0}
# The poll interval from the Postgres database to process the events from outbox_message_t.
waitPeriodMs: ${db-event-consumer.waitPeriodMs:1000}
Clean Shutdown
To ensure resources are released cleanly when the application stops, a ShutdownHookProvider is implemented:
- DbEventConsumerShutdownHook: Sets the
doneflag to stop the consumer loop and shuts down theExecutorService. This ensures that the application doesn’t hang on exit and that the database connections are properly returned to the pool.
Conclusion
This native PostgreSQL implementation provides a robust alternative to Kafka, leveraging standard relational database features to maintain strict event ordering and delivery guarantees with minimal infrastructure overhead.
Comparison: Leader Election vs. Competing Consumer (Claiming)
The light-portal architecture employs two different distributed coordination strategies: Leader Election for the Scheduler and Competing Consumers (Offset Claiming) for the PostgreSQL Pub/Sub. Each approach is optimized for its specific use case.
Summary Table
| Feature | Leader Election (scheduler_lock_t) | Host Partitioning (consumer_offsets) |
|---|---|---|
| Primary Goal | Exclusive Control (Safety) | Horizontal Scalability (Throughput) |
| Mechanism | Centralized “lock” with heartbeat. | Logical partitioning via host_id hash. |
| Parallelism | None (Single active instance). | High (N partitions, N consumers). |
| Database Load | Very Low (Heartbeat only). | Moderate (Per-partition updates). |
| Failover | Detection delay (Timeout-based). | Instant (One processor per partition). |
| Complexity | Simple. | Moderate (Hashing + Batching). |
1. Leader Election (Used in Distributed Scheduler)
Why it’s used for the Scheduler:
The “work” done by the scheduler is extremely lightweight: it simply checks if a task is due, inserts a one-line event into the outbox, and updates the next run time. However, the cost of double execution (starting the same job twice) is high.
- Efficiency: Having one leader prevents multiple instances from redundant polling of the
schedule_ttable, which reduces database contention. - Safety: It provides a simple guarantee that only one controller is making decisions about what triggers and when.
- Scaling: Since the scheduler doesn’t do the actual “heavy lifting” (the work is done by event consumers), the leader bottleneck is rarely an issue.
2. Host-Based Partitioning (Used in Postgres Pub/Sub)
Why it’s used for Event Processing:
Event processing is the “Data Plane” of the system. By partitioning based on host_id, we emulate Kafka’s partitioning behavior within PostgreSQL.
- Ordered Processing: Ensures all events for a specific host (or user) are processed by the same partition sequence, avoiding race conditions on multi-tenant data.
- Throughput: Multiple consumers can process different partitions in parallel. 8 partitions = 8 instances working concurrently.
- Implicit Load Balancing: Distributes thousands of hosts across a fixed number of partitions.
- Resiliency: Each partition’s progress is independent. A failure in one host/partition doesn’t block others.
Conclusion: Which is “Better”?
Neither is universally better; they are complementary:
- Leader Election is better for orchestration and control: Where you need a single “brain” to make consistent decisions and volume is manageable.
- Competing Consumers is better for workload distribution: Where you need to process a high volume of independent tasks as quickly as possible.
In light-portal, we use the Scheduler (Leader) to reliably “kick off” tasks by emitting events, and the Pub/Sub (Competing Consumers) to at-scale process those events.
Kafka Event Processor
Overview
The Kafka Event Processor (PortalEventConsumerStartupHook) consumes events from Kafka topics that are populated by Debezium CDC from the outbox_message_t table. It provides robust event processing with transaction-level granularity and Dead Letter Queue (DLQ) support.
Architecture
The processor uses a two-phase processing strategy with automatic fallback to ensure both performance and reliability:
- Optimistic Batch Processing: Attempts to process all transactions in a single database transaction for maximum throughput
- Granular Fallback: On failure, switches to individual transaction processing with JDBC Savepoints to isolate failures
Transaction ID Header
Events published to Kafka include a transaction_id header added by Debezium’s HeaderFrom transform. This UUID groups all events that were generated within a single business transaction, enabling:
- Precise transaction boundaries: Events are grouped by their actual transaction, not just by user/host
- Atomic DLQ handling: Failed transactions are moved to DLQ as a complete unit
- Backward compatibility: Falls back to Kafka key-based grouping for events without the header
Debezium Configuration
The transaction_id header is added via the Debezium connector configuration:
{
"transforms": "unwrap,addTransactionIdHeader,timestamp_converter,...",
"transforms.addTransactionIdHeader.type": "org.apache.kafka.connect.transforms.HeaderFrom$Value",
"transforms.addTransactionIdHeader.fields": "transaction_id",
"transforms.addTransactionIdHeader.headers": "transaction_id",
"transforms.addTransactionIdHeader.operation": "copy"
}
Processing Flow
Phase 1: Optimistic Batch Processing
// 1. Group events by transaction_id from headers
Map<String, List<ConsumerRecord>> transactionBatches = groupByTransactionId(records);
// 2. Process all transactions in one DB transaction
Connection conn = ds.getConnection();
conn.setAutoCommit(false);
for (Map.Entry<String, List<ConsumerRecord>> entry : transactionBatches.entrySet()) {
for (ConsumerRecord record : entry.getValue()) {
updateDatabaseWithEvent(conn, record.getValue());
}
}
conn.commit();
commitOffset(records);
Benefits:
- High throughput with single database transaction
- Minimal overhead for the common success case
Phase 2: Fallback with Savepoints
If the batch processing fails, the processor switches to granular mode:
Connection conn = ds.getConnection();
conn.setAutoCommit(false);
for (Map.Entry<String, List<ConsumerRecord>> entry : transactionBatches.entrySet()) {
String transactionId = entry.getKey();
List<ConsumerRecord> txRecords = entry.getValue();
Savepoint sp = conn.setSavepoint("TX_" + transactionId.hashCode());
try {
for (ConsumerRecord record : txRecords) {
updateDatabaseWithEvent(conn, record.getValue());
}
// Success - continue to next transaction
} catch (Exception e) {
// Rollback only this transaction
conn.rollback(sp);
// Send to DLQ
produceDLQ(txRecords, e);
}
}
// Commit all successful transactions
conn.commit();
commitOffset(allRecords);
Benefits:
- Isolation: Only failing transactions are moved to DLQ
- Atomicity: All events in a transaction are processed together or fail together
- No Blocking: Consumer continues processing subsequent transactions
- Progress Guarantee: Offsets are committed for all records (successful + DLQ’d)
Dead Letter Queue (DLQ)
DLQ Topic
Failed transactions are sent to a DLQ topic: {original-topic}-dlq
Each DLQ message includes:
- Key: Original Kafka key (user_id)
- Value: Original event payload
- TraceabilityId: Exception stack trace for debugging
DLQ Producer Configuration
The DLQ producer is configured via DeadLetterProducerStartupHook and must be enabled in the consumer config:
# kafka-consumer.yml
deadLetterEnabled: true
deadLetterTopicExt: -dlq
Monitoring and Recovery
- Alerting: Set up monitoring on the DLQ topic for new messages
- Investigation: Inspect DLQ messages to identify root cause (bad data, code bug, constraint violation)
- Fix: Deploy code fix or correct data inconsistency
- Replay: Use a re-driver application to republish events from DLQ back to the original topic
Transaction Grouping Logic
The processor extracts transaction_id from Kafka record headers:
private String extractTransactionId(ConsumerRecord<Object, Object> record) {
Map<String, String> headers = record.getHeaders();
if (headers != null) {
return headers.get("transaction_id");
}
return null;
}
Fallback for Legacy Events:
If no transaction_id header is present (old events before the header was added), the processor falls back to using the Kafka key for grouping:
String transactionId = extractTransactionId(record);
if (transactionId == null) {
transactionId = (String) record.getKey(); // Backward compatibility
}
Error Handling Strategy
Permanent vs Transient Errors
The processor treats all exceptions during fallback processing as permanent errors that warrant DLQ routing. This includes:
- Database constraint violations (unique, foreign key, not null)
- Deserialization errors (malformed JSON, schema mismatch)
- Business logic errors (validation failures, state inconsistencies)
Rationale: If an event fails during fallback (after the initial batch attempt failed), it’s unlikely to succeed on retry without intervention.
Health Monitoring
The processor sets healthy = false on critical failures, which triggers Kubernetes health probes to restart the pod:
- Consumer instance not found
- Framework exceptions during polling
- Fatal errors in fallback processing (after DLQ attempt)
Configuration
Consumer configuration in kafka-consumer.yml:
# Kafka consumer properties
topic: portal-event
groupId: user-query-group
keyFormat: string
valueFormat: string
# DLQ configuration
deadLetterEnabled: true
deadLetterTopicExt: -dlq
# Polling configuration
waitPeriod: 1000 # ms to wait between polls when no records
Comparison with DB Event Consumer
| Feature | Kafka Consumer | DB Consumer |
|---|---|---|
| Event Source | Kafka topic (via Debezium CDC) | Direct PostgreSQL polling |
| Transaction ID | From Kafka headers | From outbox_message_t.transaction_id column |
| Grouping | Map<String, List<ConsumerRecord>> | Map<String, List<EventData>> |
| DLQ Target | Kafka DLQ topic | PostgreSQL dead_letter_queue table |
| Offset Management | Kafka consumer offsets | PostgreSQL consumer_offsets table |
| Fallback Mechanism | JDBC Savepoints | JDBC Savepoints |
Both implementations share the same core DLQ philosophy: isolate failures at the transaction level to prevent blocking the entire consumer.
Best Practices
- Idempotent Processing: Ensure
updateDatabaseWithEvent()logic is idempotent to handle potential reprocessing - Monitor DLQ: Set up alerts for DLQ topic activity
- Version Events: Use schema versioning to handle event evolution gracefully
- Test Failure Scenarios: Regularly test DLQ routing with intentional failures
- DLQ Retention: Configure appropriate retention for DLQ topics to allow investigation and replay
Configuration Snapshot Design
This document describes the design and implementation of the configuration snapshot feature in the light-portal.
Overview
A configuration snapshot captures the state of an instance’s configuration at a specific point in time. It includes all properties, files, and relationships defined for that instance, merging overrides from various levels (Product, Environment, Product Version) into a “burned-in” effective configuration.
Snapshots are created in two scenarios:
- Deployment Trigger: Automatically created when a deployment occurs (to capture the state being deployed).
- User Trigger: Manually created by a user via the UI (e.g., to save a milestone).
Data Model
Snapshot Header (config_snapshot_t)
Captures metadata about the snapshot.
snapshot_id: UUIDsnapshot_type: Type of snapshot (e.g.,DEPLOYMENT,USER_SAVE)instance_id: Target instancehost_id: Tenant identifierdeployment_id: Link to deployment (if applicable)product_version: Locked product version at time of snapshotservice_id: Locked service ID
Snapshot Content
Snapshot data is normalizing into shadow tables that mirror the runtime configuration tables. These tables differ from the runtime tables by including a snapshot_id and lacking some runtime-specific fields.
Key tables include:
snapshot_instance_property_tsnapshot_instance_file_tsnapshot_deployment_instance_property_tsnapshot_product_version_property_tsnapshot_environment_property_t- … (others for APIs, Apps, etc.)
Effective Configuration (config_snapshot_property_t)
A flattened, merged view of all properties for the snapshot. This table represents the “final” configuration values used by the instance.
- Calculated by merging properties from all levels (Deployment > Instance > Product Version > Environment > Product) based on priority.
Backend Implementation
Stored Procedure (create_snapshot)
Located in portal-db/postgres/sp_tr_fn.sql.
This procedure performs the heavy lifting:
- Validates the instance and retrieves scope data (product, environment, etc.).
- Creates the snapshot header record.
- Copies raw data from active runtime tables to snapshot tables (e.g.,
instance_property_t->snapshot_instance_property_t). - Merges properties from all levels into
config_snapshot_property_t.- Handles list/map merging (aggregation).
- Handles scalar overriding (last update wins/priority tiers).
Persistence Layer (ConfigPersistenceImpl.java)
Provides the Java interface to calls the stored procedure:
createConfigSnapshot: CallsCALL create_snapshot(...).getConfigSnapshot: Retrieves snapshot headers with filtering/sorting.updateConfigSnapshot: Updates metadata (description).deleteConfigSnapshot: Deletes a snapshot and its cascaded data (if cascade delete is set up in DB, otherwise manual cleanup might be needed).
Front End Implementation
Config Snapshot Page (ConfigSnapshot.tsx)
- Displays a list of snapshots for a selected instance.
- Supports filtering by
current, ID, date, etc. - Actions:
- Create: Navigates to
/app/form/createConfigSnapshot. - Update: Fetches fresh data and navigates to update form.
- Delete: Calls
deleteSnapshotcommand.
- Create: Navigates to
Gap Analysis & Missing Components
The following components are currently MISSING or incomplete:
-
Command Handlers:
CreateConfigSnapshothandler (for User Trigger) is missing inconfig-command.DeleteConfigSnapshothandler is missing inconfig-command.GetFreshConfigSnapshothandler is missing (required for the “Update” action in UI).
-
Deployment Integration:
CreateDeployment.java(indeployment-command) does NOT callcreateConfigSnapshot.- The automatic snapshot creation on deployment is currently not implemented.
-
API Definition:
- The
createConfigSnapshotanddeleteConfigSnapshotendpoints need to be defined in the schema/routing if they are not already.
- The
Action Plan
-
Implement Command Handlers:
- Create
CreateConfigSnapshothandler inconfig-commandthat invokesConfigPersistence.createConfigSnapshot. - Create
DeleteConfigSnapshothandler inconfig-command. - Create
GetFreshConfigSnapshothandler inconfig-query.
- Create
-
Integrate with Deployment:
- Modify
CreateDeployment.java(or the platform handler it invokes) to callConfigPersistence.createConfigSnapshotimmediately after a successful deployment job is submitted or completed.
- Modify
-
Review Idempotency:
- Ensure
create_snapshothandles re-runs gracefully (Idempotency is partially handled by UUID generation, but business logic should prevent duplicate snapshots for the exact same state if needed).
- Ensure
Config Clone
OAuth 2.0 State Parameter Design
This document outlines the design, generation, and flow of the state parameter within the LightAPI OAuth 2.0 architecture.
Overview
The state parameter is an opaque value used by the client to maintain state between the request and callback. In the OAuth 2.0 Authorization Code Flow, its primary and critical function is to prevent Cross-Site Request Forgery (CSRF) attacks.
Workflow
The flow involves three parties:
- Client: The application requesting access (e.g., Light Portal).
- Authorization Server UI: The front-end login interface (e.g., Login View).
- Authorization Service: The backend service validating credentials and issuing codes.
Step-by-Step Flow
-
Generation (Client Side)
- The User initiates a login action on the Client.
- The Client generates a cryptographically strong random string (the
state). - The Client stores this
statelocally (e.g., in a secure, HTTP-only cookie or Session Storage) bound to the user’s current session. - The Client redirects the browser to the Authorization Server UI (
login-view), appending thestateas a query parameter.
GET https://login.lightapi.net/?client_id=...&response_type=code&state=xyz123... -
Preservation (Authorization Server UI)
- The Authorization Server UI (
login-view) loads and parses the query parameters. - It must not modify or validate the
state. Its sole responsibility is preservation. - When the user submits credentials (username/password) or selects a social provider, the UI passes the
stateexactly as received to the backend Authorization Service.
- The Authorization Server UI (
-
Authorization (Authorization Service)
- The backend service authenticates the user.
- Upon success, it generates an Authorization Code.
- It constructs the redirect URL back to the Client.
- It must append the exact same
statevalue received from the UI to this redirect URL.
HTTP/1.1 302 Found Location: https://portal.lightapi.net/authorization?code=auth_code_abc&state=xyz123... -
Verification (Client Side)
- The Client receives the callback request.
- It extracts the
statefrom the URL parameters. - It retrieves the stored
statefrom its local session. - It compares the two values:
- Match: The request is valid. Proceed to exchange the code for a token.
- Mismatch: The request is potentially malicious (CSRF likely). Reject the request and show an error.
Security Requirements
- Uniqueness: The
statemust be unique per authentication request. - Entropy: It must be a cryptographically random string (high entropy) to be unguessable.
- Binding: It must be bound to the user’s specific browser session on the client side.
Responsibility Matrix
| Component | Responsibility | Action |
|---|---|---|
| Portal (Client) | Owner | Generate, Store, Verify. |
| Login View (UI) | Carrier | Receive, Preserve, Forward. |
| Auth Service | Echo | Receive, Echo back in Redirect. |
References
Auth Client Secret Regeneration
Problem
An OAuth auth client receives a client_id and client_secret when it is
created. The clear text client_secret is intentionally a one-time value. The
database projection stores only a verifier value in auth_client_t.client_secret
so the clear secret cannot be recovered later.
This is secure, but it creates an operational problem. Users can miss the one-time response, close the page, or forget to copy the secret into their deployment system. Once that happens, the portal needs a way to issue a new secret without weakening the storage model.
Current State
The current create flow in oauth-command generates both values in
CreateClient:
clientId: generated UUID.clientSecret: generated random/base64 UUID value.clientSecretEncrypted: generated withHashUtil.generateStrongPasswordHash(clientSecret).
The read model stores the verifier in auth_client_t.client_secret. The update
flow does not update client_secret, which is correct because normal client
metadata updates should not rotate credentials.
The Auth Client page currently supports:
- creating a client through the create form,
- creating tokens for an existing client,
- updating client metadata,
- deleting a client.
Options
Option 1: Delete And Recreate The Client
This works only as a workaround and should not be the product design.
Problems:
- It changes
client_id, so every downstream service, runtime config, token request, and automation script must be updated. - It creates avoidable downtime because the old credential is removed before the new one can be distributed.
- It loses the continuity of the auth client record and makes audit history harder to read.
- It can leave related state confusing, especially provider-client mappings, client tokens, and owner relationships.
- It trains users to use a destructive operation for a credential-management problem.
Option 2: Add A Regenerate Secret Action
This is the recommended option.
The client record and client_id remain stable. Only the secret verifier is
replaced. The clear text value is returned once in the command response and is
never stored in a recoverable form.
Benefits:
- Keeps existing client ownership, provider link, service references, and audit continuity.
- Avoids unnecessary delete/recreate events.
- Matches common OAuth client-management behavior.
- Enables a focused UI flow with explicit warning, confirmation, copy action, and audit trail.
Decision
Add a dedicated “Regenerate Secret” action on the Auth Client page.
Do not reuse delete/recreate as the normal path. Do not add a recoverable encrypted-secret store. The portal should continue treating client secrets as one-time credentials.
Command API
Add a new command action:
lightapi.net/oauth/regenerateClientSecret/0.1.0
Suggested request:
{
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f",
"clientId": "019e6235-1966-7322-bbcd-1cb432b5bb88",
"aggregateVersion": 11,
"ownerPositionId": "optional-position-id",
"reason": "optional user supplied reason"
}
aggregateVersion is required. Secret regeneration modifies the existing Client
aggregate, so the command must use the same optimistic concurrency pattern as
other update commands. If the submitted version is stale, the command should fail
with a refresh/retry response instead of silently rotating a secret against an
older client view.
Suggested response:
{
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f",
"clientId": "019e6235-1966-7322-bbcd-1cb432b5bb88",
"clientSecret": "new-one-time-secret",
"aggregateVersion": 12,
"rotatedTs": "2026-05-28T14:22:00Z"
}
The clear clientSecret is response-only. It must not be included in the event
payload, logs, audit payloads, read-model query responses, or notification
payloads.
Event Design
Add a new event type:
ClientSecretRegeneratedEvent
Use the existing Client aggregate. The aggregate id should be derived from
hostId and clientId, the same way ClientUpdatedEvent is derived.
Event data should contain only non-recoverable secret material:
{
"hostId": "01964b05-552a-7c4b-9184-6857e7f3dc5f",
"clientId": "019e6235-1966-7322-bbcd-1cb432b5bb88",
"clientSecretEncrypted": "PBKDF2 verifier",
"reason": "optional user supplied reason"
}
The command handler should keep two payloads:
- event payload: safe to persist and replay,
- response payload: includes the one-time clear secret.
This separation is important. If the current create-client event still includes
the clear clientSecret, harden CreateClient at the same time so the clear
secret is returned to the UI but not stored in event_store_t.
Projection Behavior
Add persistence handling for ClientSecretRegeneratedEvent.
The projection should update only credential-related fields:
UPDATE auth_client_t
SET client_secret = ?,
update_user = ?,
update_ts = ?,
aggregate_version = ?
WHERE host_id = ?
AND client_id = ?
AND active = TRUE
AND aggregate_version < ?;
update_user and update_ts should come from standard CloudEvent metadata
rather than from user-editable event data. The event payload can include an
optional reason, but the actor performing the rotation must be taken from the
authenticated command context and persisted through the event metadata used by
the existing projection framework.
No database schema change is required for the first implementation. The existing
auth_client_t.client_secret column can continue storing the PBKDF2 verifier.
The existing update_user, update_ts, and aggregate_version fields are
enough to show that the client changed.
Optional future projection fields:
secret_update_usersecret_update_tssecret_version
Only add these if the UI needs to display secret rotation metadata separately from normal client metadata updates.
UI Design
Add a row action on the Auth Client page:
Regenerate Secret
Enable it only when the current user can modify the client. Use the same owner
and oauth-client-admin rules as update/delete.
Recommended flow:
- User clicks the row action.
- Portal shows a confirmation dialog explaining that the old secret will stop working for future client authentication.
- User confirms.
- Portal calls
regenerateClientSecret. - Portal shows a modal with:
clientId,- new
clientSecret, - copy buttons for each field,
- a “copied” acknowledgement before closing.
- Portal refreshes the table row after the dialog closes.
The modal must make it clear that the secret is shown once. After it closes, the secret cannot be recovered. If the user loses it again, they must regenerate again.
Token And Runtime Impact
Regenerating the client secret changes future client authentication. Existing issued access tokens remain valid until their normal expiration unless token revocation is implemented separately.
OAuth servers may cache client credential records to avoid database lookups on every token request. The implementation must make the cache behavior explicit:
- Prefer subscribing to
ClientSecretRegeneratedEventand evicting the affected(hostId, clientId)credential entry immediately. - If event-driven eviction is not available, use a short and documented cache TTL so the new secret starts working and the old secret stops working within an acceptable window.
- Add an integration test or operational runbook check for the cache behavior, because the command can succeed while token requests still use a stale cached verifier.
Current Java oauth-kafka behavior does not require client-secret cache
invalidation. Its token handler validates client secrets through
PortalDbProvider.queryClientByClientId, and its signing handler uses
ClientUtil.queryClientByClientId, which delegates to the same provider method.
The current AuthPersistenceImpl.queryClientByClientId implementation performs
a direct SQL lookup from auth_client_t. The CacheStartupHookProvider entries
in oauth-kafka config are commented out and there is no active client
credential cache in that service path.
If a future oauth-kafka deployment enables a client credential cache, it must
evict the affected (hostId, clientId) entry on ClientSecretRegeneratedEvent.
It should also evict on client delete and any future event that changes the
stored verifier or active state.
If the secret is being rotated because of compromise, the UI should guide the user to review existing client tokens and revoke long-lived tokens if needed. This should be a separate action, not an implicit side effect of secret regeneration.
Secret regeneration should also emit an owner/admin notification. The event should not include the clear secret, but it should notify the client owner and, where appropriate, host or organization admins that a credential was rotated. This gives the owner a chance to detect unexpected rotations or client takeover attempts.
Security Requirements
- Generate the secret with the same or stronger entropy as create-client.
- Store only a verifier generated by
HashUtil.generateStrongPasswordHash. - Never persist the clear secret in
event_store_t,auth_client_t, logs, notifications, or audit detail payloads. - Return the clear secret only in the immediate command response.
- Require write scope and the same ownership checks as update/delete.
- Allow regeneration only for active clients.
- Treat repeated clicks as separate rotations. If the response is lost, the previous clear secret cannot be recovered; the user must regenerate again.
Implementation Checklist
oauth-command:
- Add
RegenerateClientSecretcommand handler. - Add
regenerateClientSecretRequestand action metadata tospec.yaml. - Require
aggregateVersionand reject stale commands with a refresh/retry error. - Generate
clientSecretandclientSecretEncrypted. - Build an event payload without the clear secret.
- Customize the response to include the clear secret once.
- Add handler tests that assert the event data excludes
clientSecret.
light-portal:
- Add
CLIENT_SECRET_REGENERATED_EVENTtoPortalConstants. - Update
EventTypeUtilso the event maps to the Client aggregate id. - Add
PortalDbProviderdispatch for the new event type. - Add
AuthPersistence.updateClientSecret. - Add persistence tests for monotonic replay and active-client checks.
- Add a side effect or notification processor entry so the client owner and relevant admins are notified when a secret is regenerated.
light-oauth:
- Verify whether client credential lookup is cached.
- If cached, evict
(hostId, clientId)onClientSecretRegeneratedEventor document and test the maximum TTL for stale secret acceptance. - Confirm old secret rejection and new secret acceptance after cache invalidation or TTL expiry.
oauth-kafka:
- Keep the current direct DB-backed client credential lookup, or add event-driven cache invalidation before enabling a client credential cache.
- If caching is introduced, evict
(hostId, clientId)onClientSecretRegeneratedEventand client deletion. - Add a regression test or operational check proving old secret rejection and new secret acceptance without waiting for process restart.
oauth-query:
- Prefer masking or omitting
clientSecretfrom query responses. Query APIs should not return the stored verifier as if it were a usable secret.
portal-view:
- Add the row action and confirmation/result modal to
AuthClient.tsx. - Reuse ownership checks already used by update/delete.
- Add copy-to-clipboard handling and a copied acknowledgement.
- Refresh the table after a successful rotation.
light-portal-doc:
- Add user help for the Auth Client page explaining one-time secret display and regeneration.
Test Plan
- Create client still returns a one-time secret and stores only a verifier.
- Regenerate secret returns a new one-time secret and updates only the verifier.
- Regenerate secret with a stale
aggregateVersionfails and asks the user to refresh. - Old secret fails client authentication after regeneration.
- New secret succeeds client authentication after regeneration.
- OAuth server cache invalidation or TTL behavior is verified.
- Existing metadata, owner mapping, provider mapping, and
client_idremain unchanged. - Unauthorized users cannot regenerate secrets for clients they do not own.
- Client owner or admin notification is emitted without leaking the secret.
- Replaying an older regeneration event does not overwrite a newer verifier.
- The UI does not expose stored verifier values from query responses.
Event Promotion Design: State-Based Reconciliation with Composite Keys
Overview
Traditional event sourcing replication involves copying raw events from one environment to another. However, this fails when the target environment has diverged (e.g., hotfixes), causing aggregateVersion conflicts. Additionally, strict global UUID constraints can prevent reusing the same ID across environments (Tenants). Finally, partial promotions can fail if parent dependencies (referential integrity) are missing in the target.
To resolve this, we adopt a State-Based Reconciliation approach (Semantic Replay) combined with Composite Keys for identity and Recursive Dependency Resolution for integrity.
Core Strategy: State-Based Reconciliation
Workflow
- Export (Lower Environment):
- Query the current state (Snapshot) of the entity from the Lower Environment (LE).
- Produce a “Canonical State Snapshot” (JSON).
- Import & Diff (Higher Environment):
- Read the LE Snapshot.
- Query the current state of the representative entity in the Higher Environment (HE).
- Compare:
- New? -> Generate
XxxCreatedEvent. - Changed? -> Calculate Delta -> Generate
XxxUpdatedEvent. - Same? -> No-op.
- New? -> Generate
Advantages
- Conflict Immunity: No
aggregateVersionconflicts; we always append new events. - Self-Healing: Automatically synchronizes diverged states.
Identity Strategy: Composite Keys
The Problem: Global UUID Uniqueness
In a multi-tenant system shareing a single database, a standard Primary Key UUID (e.g., user_id) is globally unique. This prevents us from having “User Steve” with UUID 123 in both the “Dev Tenant” and “Prod Tenant” if the DB enforces strict uniqueness on that column.
The Solution: Composite Keys (host_id + aggregate_id)
We scope all identity by the Tenant ID (host_id).
-
Schema Change:
- Primary Keys: Change from
PK(id)toPK(host_id, id). - Uniqueness: Change unique constraints (e.g., email) from
UK(email)toUK(host_id, email). - Event Store: Change unique constraint from
UK(aggregate_id, version)toUK(host_id, aggregate_id, version).
- Primary Keys: Change from
-
Promotion Benefit:
- Dev Tenant:
host_id=DEV, user_id=123 - Prod Tenant:
host_id=PROD, user_id=123 - Matching entities is trivial (compare
iddirectly).
- Dev Tenant:
Data Integrity: Recursive Dependency Resolution
The Problem: Missing Dependencies
Promoting a child entity (e.g., API Configuration) fails if its parent (e.g., API Instance) does not exist in the target environment (Higher Env).
The Solution: Deep Promotion (Recursive Bundling)
The exporter must be “Topology Aware”.
-
Dependency Metadata: Every Entity Type must declare its dependencies.
ApiConfigdepends onApiInstance.ApiInstancedepends onGatewayInstance.GatewayInstancedepends onHost.
-
Export Workflow (Recursive): When a user selects
ApiConfig-123for promotion:- System checks
ApiConfig-123-> ParentApiInstance-456. - System checks
ApiInstance-456-> ParentGatewayInstance-789. - Export Package: Includes
[GatewayInstance-789, ApiInstance-456, ApiConfig-123](Ordered by dependency).
- System checks
-
Import Workflow (Ordered): The Importer processes the list in order:
- GatewayInstance: Exists in Prod? Yes. (Skip).
- ApiInstance: Exists in Prod? No. Action: Create
ApiInstance. - ApiConfig: Exists in Prod? No. Action: Create
ApiConfig.
Dry Run Technical Implementation
Purpose
To guarantee the promotion will succeed without actually modifying the Higher Environment (Production).
Option 1: Application-Layer Simulation (Fast, Recommended for Planning)
- Logic: The Importer queries the DB (read-only) to fetch the current state of all entities in the package.
- Result: It calculates the “Diff Plan” purely in memory.
- Output: “Plan: Create API Instance (New), Update API Config (Diff)”.
- Pros: Very fast, zero DB locks.
- Cons: Does not verify deep database constraints (e.g., complex triggers or check constraints) that only trigger on write.
Option 2: Transaction Rollback (Robust, Recommended for Validation)
- Logic:
- Start a Database Transaction:
connection.setAutoCommit(false); - Simulate Execution: Perform the actual SQL Inserts and Updates generated by the Plan.
- Insert
ApiInstance… - Insert
ApiConfig…
- Insert
- Check for Errors: If any SQL Exception occurs (e.g., FK violation, unique constraint violation), catch it.
- Rollback: Regardless of success or failure, always call
connection.rollback().
- Start a Database Transaction:
- Output: “Validation Successful: The detailed plan is valid and safe to execute.” OR “Validation Failed: FK Violation on Table X”.
- Pros: 100% certainty that the data is valid according to the database schema.
- Cons: Slightly heavier key locks, but acceptable for admin operations.
Recommendation
Use Option 1 (App Simulation) for the UI preview to show the user “what will happen”. Use Option 2 (Transaction Rollback) immediately when the user clicks “Promote” (as a pre-flight check) or as an explicit “Verify” button to ensure deep integrity.
Sibling Deletion: Handling Orphaned Items
The User Case
When promoting a collection of items (e.g., “10 Config Properties” in HE vs “8 in LE”), simply creating or updating the 8 matching items from LE is insufficient. We must identify the 2 extra items in HE that likely need to be deleted to match the LE state.
Design Pattern: Scoped Reconciliation
To handle this, the import logic must be aware of the “Parent Scope” of the entities being promoted.
-
Export (Snapshot with Siblings):
- When promoting
ApiConfig-123, we fetch ALL associated properties for that config in LE. - LE Snapshot:
Properties = {P1, P2, ... P8}(Total 8).
- When promoting
-
Import (Set Difference Logic):
- Query ALL associated properties for
ApiConfig-123in HE. - HE State:
Properties = {P1, P2, ... P8, P9, P10}(Total 10). - Logic:
HE_Only = HE_Set - LE_Set=>{P9, P10}.
- Query ALL associated properties for
-
User Decision (Interactive Mode):
- The Dry Run Plan reports:
Updates:8 items synced (P1..P8).Deuntions (Potential):2 items exist in Prod but not Dev (P9, P10).
- Default Action: Do nothing (Safe Mode).
- Option: “Sync Deletes” -> Checkbox to delete extras?
- Strict Mode: Mirror exact state (Automatically schedule
ConfigPropertyDeletedEventfor P9, P10).
- The Dry Run Plan reports:
Implementation Checklist
- Exporter must include the full list of children IDs when exporting a parent container.
- Importer must realize that for “One-to-Many” relationships, it has to fetch the full target set to detect orphans.
UI and Service Design
Entity Dependency Graph
The exporter must be “Topology Aware”. When exporting an entity, all parent and child dependencies are included. Starting with instance_t as the primary promotable entity:
host_t
└── instance_t
├── instance_property_t
├── instance_file_t
├── instance_api_t
│ ├── instance_api_property_t
│ └── instance_api_path_prefix_t
├── instance_app_t
│ ├── instance_app_property_t
│ └── instance_app_api_t
│ └── instance_app_api_property_t
└── deployment_instance_t
└── deployment_instance_property_t
Promotion Modes
Two promotion modes are supported:
- Cross-Instance (JSON): Export entity snapshots as JSON files, then import them into a different environment/database instance. Used when source and target are in separate databases.
- Same-Instance (Data Table): Use
promotion_tandpromotion_item_ttables for tracking promotions between hosts within the same database. Source and target hosts share the same database.
Database: Promotion Tracking Tables
These tables are for same-instance promotions to track promotion jobs and their items.
CREATE TABLE promotion_t (
promotion_id UUID NOT NULL,
source_host_id UUID NOT NULL,
target_host_id UUID NOT NULL,
entity_type VARCHAR(64) NOT NULL, -- 'instance', 'rule', 'api', etc.
promotion_status VARCHAR(16) NOT NULL, -- 'Planned', 'DryRun', 'Executed', 'Failed', 'RolledBack'
plan_summary JSONB, -- The diff plan generated by dry run
created_by UUID NOT NULL,
aggregate_version BIGINT DEFAULT 1 NOT NULL,
active BOOLEAN NOT NULL DEFAULT TRUE,
delete_user VARCHAR(255),
delete_ts TIMESTAMP WITH TIME ZONE,
update_user VARCHAR(255) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY(promotion_id)
);
CREATE TABLE promotion_item_t (
promotion_id UUID NOT NULL,
item_id UUID NOT NULL,
entity_type VARCHAR(64) NOT NULL, -- 'instance', 'instance_property', etc.
entity_id VARCHAR(255) NOT NULL, -- The ID of the entity being promoted
action VARCHAR(16) NOT NULL, -- 'CREATE', 'UPDATE', 'DELETE', 'NOOP'
source_snapshot JSONB, -- State in source (LE)
target_snapshot JSONB, -- State in target (HE) for diff
diff_summary JSONB, -- Field-level diff
execution_status VARCHAR(16) DEFAULT 'Pending', -- 'Pending', 'Success', 'Failed'
error_message TEXT,
update_user VARCHAR(255) DEFAULT SESSION_USER NOT NULL,
update_ts TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP NOT NULL,
PRIMARY KEY(promotion_id, item_id),
FOREIGN KEY(promotion_id) REFERENCES promotion_t(promotion_id) ON DELETE CASCADE
);
Service API Contracts
All promotion services are implemented in the user-command module (net.lightapi.portal.user.command.handler) alongside the existing ExportPortalEvent and ImportPortalEvent handlers.
Export Snapshot (Query)
Exports the current state of selected entities and all their children as a canonical JSON snapshot.
- Service:
user - Action:
exportSnapshot - Request Data:
sourceHostId(UUID) – The host to export from.entityType(String) – e.g.,"instance".entityIds(Array<String>) – IDs of entities to export.includeChildren(Boolean) – Recursively include child entities.includeSiblings(Boolean) – Include full sibling sets for orphan detection.
- Response: Canonical State Snapshot JSON containing all entities ordered by dependency depth, with nested children. The nested format is preferred over flat-with-references because the tree depth is bounded (max 4 levels for
instance_t), making it self-contained and easy to process depth-first during import.
{
"exportVersion": "1.0.0",
"sourceHostId": "...",
"exportTs": "2026-03-09T20:00:00Z",
"entities": [
{
"entityType": "instance",
"entityId": "...",
"data": { },
"children": {
"instance_property": [ ],
"instance_file": [ ],
"instance_api": [
{
"data": { },
"children": {
"instance_api_property": [ ],
"instance_api_path_prefix": [ ]
}
}
],
"instance_app": [
{
"data": { },
"children": {
"instance_app_property": [ ],
"instance_app_api": [
{
"data": { },
"children": {
"instance_app_api_property": [ ]
}
}
]
}
}
],
"deployment_instance": [
{
"data": { },
"children": {
"deployment_instance_property": [ ]
}
}
]
}
}
]
}
Import Dry Run (Command)
Performs an application-layer simulation (Option 1) to calculate the diff plan without modifying the database.
- Service:
user - Action:
importDryRun - Request Data:
targetHostId(UUID) – The host to import into.snapshot(Object) – The exported canonical snapshot JSON.
- Response: Diff plan with summary counts and per-item actions.
{
"promotionId": "...",
"summary": { "create": 5, "update": 3, "noop": 2, "orphan": 1 },
"items": [
{
"entityType": "instance",
"entityId": "...",
"action": "UPDATE",
"diff": { "instance_name": { "from": "old-name", "to": "new-name" } }
},
{
"entityType": "instance_property",
"entityId": "...",
"action": "CREATE",
"diff": null
}
]
}
Import Execute (Command)
Executes supported promotion snapshots, applying changes to the target host through event sourcing.
The current implementation supports global migration snapshots whose payload contains a top-level tables object. These snapshots are imported through the existing event-based global import pipeline, which converts table rows into ordered events and writes them to event_store_t and outbox_message_t.
Selective entity promotion snapshots whose payload contains a top-level entities array are not executable yet. The dry-run planner can still calculate the diff plan, but importExecute must reject this snapshot shape until the selective entity event materializer is implemented. Returning PLANNED items from importExecute is not a valid execution result and the UI must not treat that response as a successful promotion.
- Service:
user - Action:
importExecute - Request Data:
targetHostId(UUID) – The host to apply changes to.snapshot(Object) – The canonical snapshot. Executable today only when it containstables.promotionId(UUID, optional) – Reserved for selective entity execution.orphanAction(String) – Reserved for selective entity execution:"keep"|"delete"|"sync".
- Response: For global snapshots, the global import result such as
{ "imported": 42, "total": 42 }. For selective entity snapshots, a validation error until the selective execution path is implemented.
Selective entity execution requires a new materialization layer:
- Translate each dry-run
CREATE,UPDATE, and optional orphanDELETEitem into the matching domain event. - Preserve dependency order from the exported snapshot.
- Write generated events through the same event-store/outbox transaction pattern used by the global import pipeline.
- Return per-item execution status only after the event write succeeds or fails.
UI Pages
All pages are located under portal-view/src/pages/promotion/ and accessible via a top-level “Promotion” sidebar menu with children: Export, Import, History.
PromotionExport.tsx (/app/promotion/export)
A 3-step wizard guiding the user through the export process:
- Select Source & Type: User picks a source host from a dropdown and selects the entity type (starting with “Instance”).
- Select Entities: A
MaterialReactTableloads entities for the selected host with checkbox selection. Supports filtering, sorting, and pagination. - Preview & Export: Two options:
- Download JSON – Downloads the canonical snapshot as a
.jsonfile for cross-instance promotion. - Promote to Host – Select a target host and navigate to the Import page with the snapshot pre-loaded for dry run.
- Download JSON – Downloads the canonical snapshot as a
PromotionImport.tsx (/app/promotion/import)
Handles the import and execution workflow:
- Select Import Source: Upload a JSON file, or receive a snapshot from the Export page via navigation state.
- Dry Run Preview: After selecting a target host and clicking “Run Dry Run,” displays the diff plan:
- New items (green) – Will be created.
- Changed items (yellow) – Will be updated, with expandable field-level diffs.
- Same items (gray) – No action needed.
- Orphaned items (red) – Exist in target but not in source.
- Execute: For selective entity snapshots, execution is disabled by the backend until event materialization is implemented. For global migration snapshots, the page bypasses the selective dry-run plan and calls
globalSnapshotImportdirectly.
PromotionHistory.tsx (/app/promotion/history)
A standard MaterialReactTable listing past promotions with columns: Source Host, Target Host, Entity Type, Status (color-coded chip), Created By, Timestamp, Promotion ID. Row action: View Details (navigates to diff view).
PromotionDiffView.tsx (/app/promotion/diff)
Displays detailed promotion metadata (source/target hosts, status, timestamps) and a table of all promotion items with expandable field-level diffs showing source vs. target values and per-item execution status.
Implementation Phases
- Phase 1 – UI Foundation: Create promotion pages, sidebar menu entry, route registration. (Completed)
- Phase 2 – Backend Services: Implement
exportSnapshot,importDryRun, and validation forimportExecute. (Partially completed: selective execution is blocked until event materialization is implemented.) - Phase 3 – Same-Instance Promotion: Integrate promotion tracking tables, add “Promote to Host” flow, orphan detection, and selective event materialization.
- Phase 4 – Additional Entity Types: Add selective export and dry-run support for additional entity types. (Partially completed:
config,rule,schema,api, and other entity snapshots are supported for export/dry-run; selective execution still waits on Phase 3 event materialization and dependency ordering remains entity-specific.) - Phase 5 – Global Migration Export: Implement dynamic table discovery for full-database migration. (Completed; see below.)
Global Migration Export
Motivation
The entity-level promotion (ExportSnapshot) is designed for selective promotion — the user picks specific entities (e.g., 3 instances) and promotes them from a lower environment to a higher one. For that use case, the export produces a rich nested JSON with children and dependencies, which requires hand-crafted exportXxxSnapshot() methods per entity type.
However, a full database migration has fundamentally different requirements:
- Scope: ALL entities across ALL entity types — not a user-selected subset.
- Maintainability: When new tables are added to the system, the migration should work automatically without code changes.
- Simplicity: A flat per-table export is sufficient since all data is exported together (no missing dependency risk).
Design: Dynamic Table Discovery
Instead of maintaining a manual list of entity types and per-type export methods, the Global Migration Export uses PostgreSQL DatabaseMetaData to automatically discover and export all projection tables.
How It Works
- Discover all tables ending in
_tin thepublicschema viaDatabaseMetaData.getTables(). - Skip infrastructure tables that should never be exported:
event_store_t— immutable event log (events will be regenerated on import)outbox_message_t— transient consumer outboxconsumer_offsets— operational stateconsumer_lock— operational lockpromotion_t,promotion_item_t— promotion tracking (environment-specific)
- For each discovered table:
- Inspect column metadata to detect if the table has
host_idandactivecolumns. - If
activecolumn exists:SELECT * FROM table_t WHERE active = TRUE [AND host_id = ?]. - If no
activecolumn:SELECT * FROM table_t [WHERE host_id = ?]. - Convert each row to
Map<String, Object>with camelCase key names.
- Inspect column metadata to detect if the table has
- Record a consistency marker:
SELECT MAX(id) FROM event_store_tat the start of the export transaction to stamp the snapshot with thelastEventId. - Use
REPEATABLE READtransaction isolation for consistency across all tables (PostgreSQL MVCC ensures a frozen-in-time view even if events are being processed concurrently).
Data Consistency Strategy
Querying projection tables directly is safe because:
- PostgreSQL MVCC:
REPEATABLE READprovides a consistent snapshot at transaction start time. Concurrent event processing does not affect the exported data. - Atomic event application: Each event is applied via
handleEvent()within its own transaction, so partial aggregate states are never visible. lastEventIdmarker: The export records the maximum event ID at transaction start, providing an auditable consistency boundary without the cost of event replay.
Why not replay events from event_store_t?
- The projection tables are the replayed event result — re-replaying is redundant.
handleEvent()has 120+ event type cases — duplicating that logic in an in-memory replayer is impractical.- Event replay would not unlock any consistency benefit beyond what MVCC already provides.
Output Format
{
"exportVersion": "1.0",
"sourceHostId": "N2CMw0HGQXeLvC1wBfln2A",
"lastEventId": "abc123...",
"exportTs": "2026-04-09T20:00:00Z",
"tables": {
"config_t": {
"count": 5,
"rows": [
{ "configId": "...", "configName": "...", "configPhase": "...", ... },
...
]
},
"user_t": {
"count": 12,
"rows": [
{ "userId": "...", "email": "...", "firstName": "...", ... },
...
]
},
"role_t": { ... },
"instance_t": { ... },
...
}
}
Key differences from the per-entity promotion export:
| Aspect | Per-Entity Promotion (ExportSnapshot) | Global Migration (ExportGlobalSnapshot) |
|---|---|---|
| Scope | User-selected entities | All active entities |
| Structure | Nested (parent/children/dependencies) | Flat per-table |
| New table support | Requires code changes | Automatic via DatabaseMetaData |
| Use case | Lower env → Higher env | Full database migration |
| Output | Entity-centric JSON | Table-centric JSON |
| Import mechanism | Same-instance via promotion_t or Cross-instance via JSON | Cross-instance via JSON only |
Import: Event-Based Migration (Refined in Phase 2.5)
To ensure maximum compatibility and maintain the integrity of the event-sourced system, the global import process follows a 3-step pipeline:
Source DB → Export (Flat JSON) → Convert to Events (Ordered JSON) → Import (Target DB)
1. Snapshot-to-Events Conversion
An intermediate step (ConvertSnapshotToEvents) transforms the flat table-centric snapshot into an ordered JSON array of CloudEvents. This format is 100% compatible with the existing event-importer CLI tool (matching the 00-bootstrap.json structure).
2. Topological Sequencing (Dependency Awareness)
Since a full migration often involves complex relationships, the converter is “Relationship Aware.” It uses DatabaseMetaData.getImportedKeys() to dynamically discover parent→child dependencies.
- Topological Sort: It implements Kahn’s algorithm to order events such that parent entities (e.g.,
Org,Host,User,Role) are processed before their children (e.g.,UserHost,RoleUser,AuthProviderClient). - Dynamic: This approach handles new tables and FK constraints automatically without requiring code changes to a “hard-coded” dependency list.
3. Batch Replay & Reconciliation
The import handler performs a batch insertion of these generated events into event_store_t and outbox_message_t within a single transaction.
- Nonce Re-calculation: Nonces are re-calculated on the target system during import to ensure uniqueness.
- Automatic Projections: Inserting into the outbox triggers the
DbEventConsumerStartupHookto rebuild all materialized projection tables on the target system.
Service API Contract
-
Export:
- Handler:
GlobalSnapshotExport(user-query) - Service ID:
lightapi.net/user/exportGlobalSnapshot/0.1.0 - Request:
{ "sourceHostId": "...", "entityTypes": [...] } - Response: Canonical snapshot JSON (flat tables)
- Handler:
-
Convert (New):
- Handler:
ConvertSnapshotToEvents(user-query) - Service ID:
lightapi.net/user/convertSnapshotToEvents/0.1.0 - Request:
{ "snapshot": "...", "targetHostId": "...", "adminUserId": "..." } - Response: JSON array of ordered CloudEvents (event-importer compatible)
- Handler:
-
Import:
- Handler:
GlobalSnapshotImport(user-command) - Service ID:
lightapi.net/user/importGlobalSnapshot/0.1.0 - Request:
{ "targetHostId": "...", "snapshot": "...", "entityTypes": [...] } - Response:
{ "imported": 42, "total": 42 }
- Handler:
Implementation Phases (Updated)
- Phase 1 – UI Foundation: Create promotion pages, sidebar menu entry. (Completed)
- Phase 2 – Global Export: Implement dynamic table discovery via JDBC metadata. (Completed)
- Phase 2.5 – Global Migration Step: Implement Topological Sorting and Snapshot-to-Events conversion for CLI compatibility. (Completed)
- Phase 3 – Entity Promotion (Selective): Implement recursive bundling for user-selected entities (e.g., Instance export).
- Phase 4 – Same-Instance Tracking: Integrate
promotion_ttracking for in-DB moves. (Not completed; history/detail handlers currently return placeholder data until the promotion tables and persistence are added.)
Deployment Workflow
Light Portal manages product, API, application, instance, runtime configuration, and deployment metadata for multiple tenants. The deployment workflow extends that model so a user can deploy a configured instance to a Kubernetes cluster from the Instance Admin page.
The goal is to provide a production-like deployment path for small businesses and enterprise tenants without requiring Light Portal to have direct network access to every customer cluster.
Problem
Each API or application repository can contain a k8s/ folder with Kubernetes
deployment templates. The templates contain variables in the following format:
${key:defaultValue}
For each configured portal instance, Light Portal can generate a values.yml
document that contains deployment-time values such as image URL, namespace,
replica count, service ports, config references, resource limits, ingress host,
and rollout options.
When a user clicks the Deployment button for an instance, the system should:
- Resolve the target instance and deployment environment.
- Generate or fetch the instance deployment
values.yml. - Send a deployment command to a deployer that can access the target Kubernetes cluster.
- Render the final Kubernetes manifests from the repository templates.
- Validate and apply the manifests.
- Track rollout status and return deployment results to Light Portal.
Recommended Architecture
The recommended default is to run a small Rust deployer inside each target Kubernetes cluster.
Light Portal
|
| deployment request / status query
v
Light Controller
|
| outbound WebSocket session / MCP tool call
v
In-cluster Rust Deployer Pod
|
| Kubernetes API via in-cluster ServiceAccount
v
Customer Kubernetes Cluster
This is similar to the agent model used by GitOps and cloud management systems: the cluster-local agent connects outbound to the control plane and performs cluster operations using tightly scoped Kubernetes RBAC.
Why In-Cluster Deployer
Running the deployer inside the cluster should be the default for production.
Kubernetes Authentication
An in-cluster deployer can use Kubernetes in-cluster configuration. The Rust
service can use kube-rs and call the equivalent of default client discovery.
Kubernetes mounts a ServiceAccount token into the pod, so no external
kubeconfig file needs to be copied, stored, rotated, or exposed.
Least-Privilege RBAC
The deployer should run as a dedicated ServiceAccount with only the permissions needed for the namespaces and resources it manages. If a deployer is compromised, the blast radius is limited by Kubernetes RBAC.
For a small-business deployment, the first version can bind the deployer to a dedicated namespace. For managed enterprise environments, the portal can create one deployer per cluster or per tenant namespace.
Firewall Traversal
Many customer clusters are behind firewalls or corporate networks. An in-cluster deployer can open an outbound WebSocket connection to Light Controller. This avoids inbound firewall rules and allows Light Portal to manage deployments without direct access to the Kubernetes API server.
Operational Simplicity
Customers do not need to run a separate VM or keep a standalone deployment process alive. They install the deployer with one Kubernetes YAML file or Helm chart, and Kubernetes restarts it if it fails.
Deployment Transports
The deployment system should support two transports.
Controller-Mediated WebSocket
This is the preferred transport for private customer environments.
- The deployer pod starts inside the customer cluster.
- It registers with Light Controller over an outbound WebSocket.
- The controller authenticates the deployer and records its tenant, cluster, environment, capabilities, and current status.
- Light Portal sends deployment commands to the controller.
- The controller forwards the command to the deployer using MCP-style tool calls over the existing session.
- The deployer streams status back through the controller.
This mode works when Light Portal cannot reach the customer environment.
Direct Deployer URL
This is useful for local MicroK8s, managed clusters, and environments where Light Portal can reach the deployer directly.
The deployer URL can be stored in deployment configuration or config server metadata. Light Portal or the workflow engine can call the deployer’s API/MCP endpoint directly.
Direct mode should be treated as an optimization, not the primary model for customer-managed private networks.
Deployer Responsibilities
The deployer is intentionally narrow. It should not own tenant configuration or business workflow decisions. It executes deployment instructions and reports results.
The deployer should support these actions:
render: Fetch templates and values, render manifests, and return a manifest summary.dryRun: Render manifests and validate them against the Kubernetes API without applying changes.deploy: Apply manifests and wait for rollout status.redeploy: Re-apply manifests and trigger rollout if needed.undeploy: Delete resources created by the deployment.status: Return current Kubernetes resource and rollout status.logs: Return recent pod logs for the deployed instance.rollback: Redeploy a previous Light Portal deployment snapshot.
The first implementation should include dryRun, deploy, undeploy, and
status.
Rollback should be implemented through Light Portal deployment history, not native Kubernetes rollout undo. Native Kubernetes rollback only reverts the Deployment pod template and does not reliably revert associated ConfigMaps, Secrets, or deployment values. A Light Portal rollback should redeploy a previous immutable deployment snapshot so pods, config, environment variables, and related resources return to the same known state.
Deployment Request
A deployment request should be explicit and auditable.
requestId: 01964b05-0000-7000-8000-000000000001
hostId: 01964b05-552a-7c4b-9184-6857e7f3dc5f
instanceId: petstore-dev
environment: dev
clusterId: microk8s-local
namespace: petstore-dev
action: deploy
valuesRef:
source: config-server
path: /deployments/petstore-dev/values.yml
template:
repoUrl: https://github.com/lightapi/petstore-api.git
ref: main
path: k8s
options:
dryRun: false
waitForRollout: true
timeoutSeconds: 300
The request should be created by Light Portal and persisted as deployment history before it is sent to the deployer.
Values File
The values.yml is instance-specific. It should contain all values needed to
render Kubernetes templates for one deployment target.
image:
repository: ghcr.io/lightapi/petstore-api
tag: 1.0.0
deployment:
replicas: 2
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
service:
port: 8080
ingress:
enabled: true
host: petstore-dev.example.com
config:
snapshotId: petstore-dev-20260427
configServerUrl: https://config.lightapi.net
template:
repoUrl: https://github.com/lightapi/petstore-api.git
ref: main
path: k8s
The deployer can receive the values inline or fetch them from config server
using the valuesRef in the deployment request.
Config Server should be the authoritative source of truth for deployment
values. At deployment time, Light Portal should create an immutable snapshot of
both the deployment values.yml and the runtime configuration values.yml.
That snapshot is the deployment evidence. If a deployment fails or must be
audited later, the team must be able to reconstruct exactly which values were
used even if the current config has changed.
Light Portal should persist the snapshot reference and hash in deployment history. It should not rely only on a mutable config path.
Template Rendering
The initial template format can use simple placeholders:
image: ${image.repository}:${image.tag}
replicas: ${deployment.replicas:1}
The renderer should support nested keys and defaults. If a key is missing and no default is provided, rendering should fail.
The deployer should render manifests in memory and avoid writing generated YAML to disk unless debug mode is explicitly enabled.
Longer term, the deployer can support additional renderers:
- Built-in
${key:default}renderer for simple service templates. - Kustomize for standard Kubernetes overlays.
- Helm for teams that already maintain charts.
The built-in renderer should be deterministic and small. It should not evaluate arbitrary code.
Do not use raw string replacement or regex replacement against raw YAML text. YAML is indentation sensitive, and multi-line values, certificates, JSON strings, and embedded config blocks can break when substituted as plain text.
The preferred first renderer is a constrained internal AST renderer:
- Parse each template document with
serde_yamlintoserde_yaml::Value. - Recursively traverse the YAML value tree.
- Resolve placeholders only inside string scalar values.
- Replace
${key:default}with values from the structured deployment values. - Serialize the YAML value back to YAML or convert it directly to Kubernetes dynamic objects.
This avoids most quoting, escaping, and indentation bugs because YAML parsing and serialization remain responsible for formatting. It also keeps the renderer small and prevents arbitrary code execution.
The implementation must include tests for ConfigMap multi-line blocks, JSON strings, certificate-shaped values, and Secret references before production use.
Kubernetes Execution
The Rust deployer should prefer kube-rs and the Kubernetes API over shelling
out to kubectl.
Benefits:
- no
kubectlbinary dependency - structured errors
- easier dry-run and rollout status handling
- better control over authentication and namespaces
- safer request construction
kubectl can remain a diagnostic or fallback mode, but it should not be the
default production implementation.
The deployer should use Kubernetes server-side dry run for validation:
dryRun=All
For apply, use server-side apply when possible so the deployer has a clear field manager identity.
The field manager must be explicit, for example:
fieldManager=light-deployer
Using a stable field manager is important for coexistence with other Kubernetes controllers. For example, a Horizontal Pod Autoscaler may own Deployment replica changes. Server-side apply helps the deployer avoid accidentally overwriting fields owned by other managers.
For rollout status, the deployer should use the Kubernetes watch API rather than only polling logs. The portal user experience should show resource status transitions such as:
Pending -> ContainerCreating -> Running -> Ready
Streaming watch events through the deployer gives Light Portal a precise deployment timeline similar to a CI/CD job log while still preserving structured Kubernetes state.
Security Model
Security is the central design constraint because this component can mutate a customer cluster.
Authentication
The deployer must authenticate to Light Controller or Light Portal before it can receive commands. Recommended options:
- mTLS for deployer-to-controller registration
- signed JWT enrollment token for first registration
- short-lived command tokens issued by Light Portal
The deployer should have a stable deployerId and should report cluster,
namespace, version, and capability metadata during registration.
Authorization
Light Portal must verify that the requesting user can deploy the target instance, environment, and tenant. The deployer must also enforce local constraints:
- allowed namespaces
- allowed repository hosts and repository names
- allowed image registries
- allowed Kubernetes resource kinds
- allowed actions
The deployer should reject commands outside its configured policy even if the portal sends them.
RBAC
For namespace-scoped deployments, prefer Role and RoleBinding over
ClusterRole and ClusterRoleBinding.
Version 1 should allow only application-level resource kinds:
DeploymentServiceIngressConfigMapSecret
Version 1 should explicitly block cluster-scoped and control-plane resources, including:
NamespaceClusterRoleClusterRoleBindingCustomResourceDefinition- admission webhooks
This keeps the default deployer RBAC narrow and supports least-privilege customer installations.
Example namespace-scoped installation:
apiVersion: v1
kind: ServiceAccount
metadata:
name: light-portal-deployer
namespace: petstore-dev
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: light-portal-deployer
namespace: petstore-dev
rules:
- apiGroups: ["", "apps", "networking.k8s.io"]
resources: ["deployments", "services", "ingresses", "configmaps"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: light-portal-deployer
namespace: petstore-dev
subjects:
- kind: ServiceAccount
name: light-portal-deployer
namespace: petstore-dev
roleRef:
kind: Role
name: light-portal-deployer
apiGroup: rbac.authorization.k8s.io
Secrets should be handled carefully. Avoid logging rendered manifests that contain secret values. Prefer references to existing Kubernetes Secrets, External Secrets, Sealed Secrets, or config-server secret references resolved inside the deployer.
The Rust implementation must also avoid logging raw Kubernetes apply payloads.
When using tracing or log, never log full kube-rs request objects,
patches, or serialized manifests for Secret resources. Kubernetes Secret
values are base64 encoded, not encrypted, and will leak credentials if written
to pod stdout.
Deployment Pod
The deployer can be installed as a Kubernetes Deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
name: light-portal-deployer
namespace: petstore-dev
spec:
replicas: 1
selector:
matchLabels:
app: light-portal-deployer
template:
metadata:
labels:
app: light-portal-deployer
spec:
serviceAccountName: light-portal-deployer
containers:
- name: deployer
image: ghcr.io/lightapi/light-portal-deployer:0.1.0
env:
- name: LIGHT_CONTROLLER_WS_URL
value: wss://controller.lightapi.net/deployer/ws
- name: DEPLOYER_ID
value: petstore-dev-microk8s
- name: DEPLOYER_TOKEN
valueFrom:
secretKeyRef:
name: light-portal-deployer-credentials
key: token
- name: ALLOWED_NAMESPACES
value: petstore-dev
Portal Workflow
The Instance Admin Deployment button should not synchronously run deployment logic in the browser request. It should create a deployment request and trigger an asynchronous workflow.
Recommended flow:
- User clicks Deployment for an instance.
- Portal validates authorization.
- Portal resolves instance, environment, product version, image, config snapshot, and template repository.
- Portal creates a deployment request row/event.
- Portal snapshots deployment values and runtime values.
- Portal or workflow engine runs
dryRun. - If the target environment requires approval, workflow waits for human approval.
- Workflow calls
deploy. - Deployer streams events: render complete, dry-run complete, apply started, pod phase changes, rollout progressing, rollout complete or failed.
- Portal updates deployment history and status.
- User can inspect rendered manifest summary, rollout status, pod status, and logs.
This fits the agentic workflow model. The workflow can ask the user to approve the rendered changes before applying them.
Approval should be configurable at the environment level. Development and test environments can allow automatic deployment. Production environments should normally require manual approval through Light Portal or an agentic workflow ask task.
Status And Audit
Light Portal should persist deployment history.
Suggested fields:
deploymentIdhostIdinstanceIdenvironmentclusterIdnamespaceactionstatusrequestUserdeployerIdtemplateRepoUrltemplateReftemplatePathvaluesHashvaluesSnapshotIdruntimeValuesHashruntimeValuesSnapshotIdmanifestHashtemplateCommitSharesourceSummaryimageRepositoryimageTagstartedTscompletedTserrorMessage
The deployer should return enough detail to reproduce the deployment intent without storing secrets.
Light Portal should store only the rendered manifest hash, Git commit SHA, and a redacted resource summary. It should not store full rendered YAML in the database because rendered manifests can contain environment variables, connection strings, or credentials.
Example resource summary:
[
{"kind": "Deployment", "namespace": "petstore-dev", "name": "petstore"},
{"kind": "Service", "namespace": "petstore-dev", "name": "petstore"}
]
Multi-Tenant Considerations
Small-business cloud service means multiple tenants may share Light Portal but deploy to separate clusters or namespaces.
Rules:
- Tenant identity must be present in every deployment request.
- A deployer must be bound to one tenant boundary. In most installations, that means one tenant namespace or a tightly controlled set of namespaces owned by that tenant.
- Do not share one deployer across unrelated tenants.
- Namespace policy must be enforced both by portal authorization and deployer local policy.
- Deployment history must be filtered by
hostId. - A compromised deployer must not be able to receive commands for another tenant.
Failure Handling
The deployer should classify failures:
- template repository fetch failure
- values file fetch failure
- render failure
- manifest validation failure
- Kubernetes API authorization failure
- apply failure
- rollout timeout
- health check failure
- controller WebSocket disconnected
- deployer registration rejected
Each failure should include a safe message and diagnostic metadata. Secret values must be redacted.
For controller-mediated deployments, the deployer must have a resilient WebSocket lifecycle. If Light Controller restarts or the network drops, the deployer should not crash. It should reconnect with exponential backoff and jitter, re-register after reconnecting, and resume accepting commands only after the controller confirms the deployer session.
First Implementation
The first implementation should target local MicroK8s and direct feedback in Light Portal.
Phase 1:
- Create Rust deployer service.
- Run it inside MicroK8s.
- Support direct API mode for local testing.
- Implement
render,dryRun,deploy,undeploy, andstatus. - Use
kube-rsand in-cluster ServiceAccount authentication. - Support built-in
${key:default}rendering. - Add deployment request and deployment history tables/events.
- Add Instance Admin deployment request flow.
Phase 2:
- Add controller-mediated WebSocket registration.
- Expose deployer operations as MCP tools through the controller.
- Stream deployment progress and Kubernetes watch events to Light Portal.
- Implement exponential backoff reconnect and re-registration.
- Add approval step through agentic workflow.
Phase 3:
- Add Helm/Kustomize renderer support if needed.
- Add rollback support.
- Add multi-cluster inventory and deployer health view.
- Add deployment policy and quota enforcement.
Resolved Design Decisions
- Config Server is the authoritative source of truth for values. Each deployment stores immutable deployment and runtime values snapshot references plus hashes.
- Light Portal stores rendered manifest hash, template Git commit SHA, and redacted resource summary. It does not store full rendered manifests by default.
- Regulated environments can add an opt-in enterprise artifact mode that stores the full rendered manifest in encrypted object storage with strict retention. Full manifests should stay out of the relational database.
- Deployment approval is configured at the environment level. Production should require approval by default.
- Deployers are installed per tenant boundary and should not be shared across unrelated tenants.
- Version 1 allows only application-level resources: Deployment, Service, Ingress, ConfigMap, and Secret.
- The first renderer should be a constrained internal AST renderer based on
serde_yaml, not raw text replacement. - The direct deployer URL mode should expose MCP immediately, using the same internal tool implementation that controller-mediated WebSocket mode will use later.
- Rollback is a redeploy of a previous Light Portal deployment snapshot, not a native Kubernetes rollout undo.
Open Questions
- Which object storage providers should enterprise artifact mode support first?
- What retention policies should be available for encrypted rendered manifest artifacts?
- Should direct MCP use streamable HTTP only, or should it also expose SSE for long-running deployment progress events?
- Should rollback require the same environment-level approval policy as deploy?
Recommendation
Use an in-cluster Rust deployer as the default production model. The deployer should connect outbound to Light Controller and execute deployment commands via MCP-style tools. Direct deployer URL mode is useful for MicroK8s and managed environments but should be secondary. The MCP tool implementation should be shared by both transports from the beginning.
Use kube-rs instead of shelling out to kubectl for the production execution
path. Keep the deployer small, policy-bound, and auditable. Let Light Portal own
deployment intent and history, while the deployer owns safe cluster-local
execution.
Light OAuth and OAuth Kafka AgentCore OIDC Discovery
Problem
Issue https://github.com/lightapi/portal-service/issues/44 asks whether
portal-service/apps/light-oauth can support AWS AgentCore JWT inbound
authorization.
The current Rust light-oauth service and the Java oauth-kafka service can
mint RS256 JWT access tokens and serve provider keys from:
GET /oauth2/{providerId}/keys
That is enough for internal services that are configured with an explicit
jwksUrl, but it is not enough for AWS AgentCore or AWS API Gateway HTTP JWT
authorizers. Those integrations discover the issuer metadata first, then use
the published jwks_uri to fetch signing keys.
The linked AWS AgentCore document requires a discovery URL ending in
/.well-known/openid-configuration, and validates configured audiences,
clients, scopes, and required claims against the JWT. The API Gateway debugging
document shows the same class of failure: without a valid OIDC discovery
endpoint, AWS cannot create or use the JWT authorizer correctly. The Authgear
OIDC guide summarizes the metadata fields expected by OIDC clients, including
issuer, authorization_endpoint, token_endpoint, jwks_uri,
response_types_supported, and signing algorithms.
Current Rust Behavior
The Rust service currently has these relevant routes:
POST /oauth2/{providerId}/code
POST /oauth2/{providerId}/token
GET /oauth2/{providerId}/keys
The service has static token issuer and audience settings:
jwtIssuer: ${jwt_issuer}
jwtAudience: ${jwt_audience}
Default values are URNs:
jwt_issuer: "urn:com:networknt:oauth2:v1"
jwt_audience: "urn:com.networknt"
Generated access tokens currently include:
iss: configured issuer
aud: configured audience
cid: client id
scp: array of scopes
The service does not currently publish:
/.well-known/openid-configuration/oauth2/{providerId}/.well-known/openid-configuration- an external/public issuer URL
- OIDC-compatible
client_idandscopetoken claims - a discovery document that maps the issuer to the existing JWKS endpoint
Current Java Behavior
The Java implementation in oauth-kafka has the same public OAuth shape:
GET /oauth2/{providerId}/code
POST /oauth2/{providerId}/code
POST /oauth2/{providerId}/token
GET /oauth2/{providerId}/keys
GET /oauth2/{providerId}/deref/{token}
POST /oauth2/{providerId}/signing
The route mapping lives in:
src/main/resources/config/handler.yml
The handler list and local values live in:
src/main/resources/config/values.yml
The current JWKS handler is:
src/main/java/com/networknt/oauth/handler/ProviderIdKeysGetHandler.java
It queries the provider by id, returns the jwk JSON from the database, and
returns 404 when the provider cannot be found. It does not publish discovery
metadata.
The Java token handler is:
src/main/java/com/networknt/oauth/handler/ProviderIdTokenPostHandler.java
Its token claim helpers currently emit Light-specific claims:
cid: client id
scp: array of scopes
The signing endpoint already emits client_id for signed custom payloads:
src/main/java/com/networknt/oauth/handler/ProviderIdSigningPostHandler.java
However, that endpoint still needs the same reserved-claim behavior if it is
used for AgentCore-facing tokens, because its custom payload is applied after
the initial client_id claim.
The Java OpenAPI document also only exposes /{providerId}/keys; it has no
discovery route:
src/main/resources/config/openapi.yaml
Gaps
1. Missing OIDC Discovery
AWS AgentCore expects a discovery URL matching:
^.+/\.well-known/openid-configuration$
Both light-oauth and oauth-kafka only expose
/oauth2/{providerId}/keys. AWS does not know how to discover that
provider-specific JWKS URL unless the OAuth service publishes a metadata
document with jwks_uri.
2. Issuer Is Not a Public HTTPS URL
The default issuer is a URN. AgentCore discovery expects the discovery URL to
point to an issuer URL, and the decoded token iss must match the issuer
metadata. API Gateway JWT authorizers have the same practical requirement.
For enterprise deployments, the issuer should be the externally reachable URL seen by AWS, not the container DNS name or localhost address.
3. Token Claims Do Not Match AgentCore Names
AgentCore validates:
audagainstallowedAudienceclient_idagainstallowedClientsscopeagainstallowedScopes
Current Rust and Java token flows expose the client as cid and scopes as
scp. That is useful for existing Light consumers but does not satisfy AWS
claim names by default.
4. Provider and Tenant Addressing Is Ambiguous
The existing JWKS route is provider-scoped. OIDC discovery commonly uses the
issuer base URL plus /.well-known/openid-configuration, but light-oauth
supports multiple providers. We need an explicit rule for how a discovery URL
selects a provider.
5. Public URL Construction Is Not Configurable
The service runs behind gateways, Docker networks, and potentially AWS-facing domains. Discovery metadata must publish public URLs such as:
https://oauth.example.com/oauth2/{providerId}/keys
It must not publish internal URLs such as:
https://light-oauth:6881/oauth2/{providerId}/keys
6. JWKS and Signing Key Consistency Needs a Test Contract
Tokens are signed with rows from auth_provider_key_t, while /keys returns
the provider jwk from auth_provider_t. The implementation should guarantee
that the JWT header kid is present in the returned JWKS for the same provider.
That guarantee matters more once external AWS services cache the discovery and
JWKS responses.
Goals
- Let AWS AgentCore use Rust
light-oauthor Javaoauth-kafkaas a JWT bearer token issuer. - Publish OIDC-compatible discovery metadata for each provider in both implementations.
- Keep existing
/oauth2/{providerId}/keysand Light-specificcid/scpclaims working. - Avoid exposing internal Docker or Kubernetes service names in public metadata.
- Keep issuer, audience, and discovery URLs deterministic across environments.
- Add tests that prove discovery, JWKS, and signed token claims line up.
Non-Goals
- Do not implement full OIDC identity-provider behavior in the first phase.
- Do not add dynamic client registration.
- Do not replace existing explicit
jwksUrlverification used by internal services. - Do not remove Light-specific token claims.
- Do not solve AgentCore outbound OAuth credential providers in this change.
Recommended Design
Add provider-scoped OIDC discovery to Rust light-oauth and Java
oauth-kafka, and make token output compatible with both Light and AWS
AgentCore.
Routes
Add the provider-scoped route first:
GET /oauth2/{providerId}/.well-known/openid-configuration
This avoids ambiguity because the route contains the provider identifier. The issuer for this route should be:
{publicIssuerBaseUrl}/oauth2/{providerId}
The discovery URL becomes:
{publicIssuerBaseUrl}/oauth2/{providerId}/.well-known/openid-configuration
The JWKS URI becomes:
{publicIssuerBaseUrl}/oauth2/{providerId}/keys
Optionally add a root route for a configured default provider:
GET /.well-known/openid-configuration
Only enable the root route when defaultProviderId is configured. Otherwise,
return 404 to avoid publishing metadata for the wrong tenant or provider.
Discovery Document
Return application/json and a compact OIDC-compatible document:
{
"issuer": "https://oauth.example.com/oauth2/AZZRJE52eXu3t1hseacnGQ",
"authorization_endpoint": "https://oauth.example.com/oauth2/AZZRJE52eXu3t1hseacnGQ/code",
"token_endpoint": "https://oauth.example.com/oauth2/AZZRJE52eXu3t1hseacnGQ/token",
"jwks_uri": "https://oauth.example.com/oauth2/AZZRJE52eXu3t1hseacnGQ/keys",
"response_types_supported": ["code"],
"grant_types_supported": [
"authorization_code",
"password",
"refresh_token",
"client_credentials",
"urn:ietf:params:oauth:grant-type:token-exchange"
],
"token_endpoint_auth_methods_supported": [
"client_secret_basic",
"client_secret_post"
],
"scopes_supported": ["portal.r"],
"claims_supported": [
"iss",
"aud",
"exp",
"iat",
"nbf",
"jti",
"client_id",
"scope",
"cid",
"scp"
],
"subject_types_supported": ["public"],
"id_token_signing_alg_values_supported": ["RS256"]
}
id_token_signing_alg_values_supported is included for compatibility because
many discovery consumers expect it, even if light-oauth does not issue ID
tokens yet. The design should document this as discovery compatibility metadata,
not as a promise that ID-token grant flows are complete.
Configuration
Add explicit public URL configuration:
oidcDiscoveryEnabled: ${oidc_discovery_enabled:true}
publicIssuerBaseUrl: ${public_issuer_base_url}
defaultProviderId: ${default_provider_id:}
Example local values:
public_issuer_base_url: "https://localhost:6882"
default_provider_id: "AZZRJE52eXu3t1hseacnGQ"
Example enterprise values:
public_issuer_base_url: "https://oauth.customer.example.com"
default_provider_id: "AZZRJE52eXu3t1hseacnGQ"
When publicIssuerBaseUrl is configured, generated token iss should default
to:
{publicIssuerBaseUrl}/oauth2/{providerId}
Keep jwtIssuer for backward compatibility. If both are set, use a strict rule:
- If
jwtIssueris set to a non-default value, keep using it and make discoveryissuerequal to that value. - If
jwtIssueris absent or equal to the current default URN, use the provider-scoped public issuer URL. - Log a startup warning if discovery is enabled but the issuer is not an HTTPS URL, unless running in local development.
Token Claim Compatibility
Extend JwtClaims without removing existing fields:
cid: existing Light client id claim
scp: existing Light scope array claim
client_id: OIDC/AWS client id claim
scope: OIDC/AWS space-delimited scope claim
For a client token, emit:
{
"client_id": "019c9273-2663-7a9e-82f4-94f9f5f79c3a",
"scope": "portal.r",
"cid": "019c9273-2663-7a9e-82f4-94f9f5f79c3a",
"scp": ["portal.r"]
}
For user grants, also emit a stable sub value. Prefer the portal user id if
the token represents a user; otherwise use the client id for client credentials
tokens. Keep the existing uid and uty claims.
Reserved claim names from request extra_claims must not override:
iss, aud, exp, iat, nbf, jti, kid, client_id, scope, cid, scp, sub
If an AgentCore runtime is configured with required custom claims, support them
through existing client custom_claim configuration or a new allowlisted static
claim configuration. For example, a customer that wants Cognito-like access
token semantics could configure:
{
"token_use": "access"
}
Do not hard-code Cognito-specific claims globally unless the Light token contract explicitly adopts them.
Scope Source
The token endpoint already resolves requested scope against the configured
client scope. Discovery can publish a conservative scopes_supported value:
- Use a configured
oidcScopesSupportedlist when set. - Otherwise publish the union of active client scopes for the provider.
- If querying client scopes is not added in phase 1, omit
scopes_supportedor publish a configured static list.
For AgentCore, the critical runtime behavior is that the token includes the
space-delimited scope claim expected by allowedScopes.
JWKS Response
Keep:
GET /oauth2/{providerId}/keys
Add response headers:
Content-Type: application/jwk-set+json
Cache-Control: public, max-age=300
Five minutes is a reasonable starting cache TTL. It limits repeated AWS fetches
while keeping key rotation practical. If existing clients depend on
application/json, application/jwk-set+json remains JSON-compatible; test the
known internal verifier before changing this header.
Add tests that assert:
- a token signed for provider
Phas akid /oauth2/P/keysreturns a JWKS containing thatkid- discovery
jwks_urireturns that same key set
AgentCore Configuration Example
An AgentCore runtime should be configured with the provider-scoped discovery URL:
{
"customJWTAuthorizer": {
"discoveryUrl": "https://oauth.customer.example.com/oauth2/AZZRJE52eXu3t1hseacnGQ/.well-known/openid-configuration",
"allowedClients": ["019c9273-2663-7a9e-82f4-94f9f5f79c3a"],
"allowedAudience": ["urn:com.networknt"],
"allowedScopes": ["portal.r"]
}
}
The token must then contain:
{
"iss": "https://oauth.customer.example.com/oauth2/AZZRJE52eXu3t1hseacnGQ",
"aud": "urn:com.networknt",
"client_id": "019c9273-2663-7a9e-82f4-94f9f5f79c3a",
"scope": "portal.r"
}
If the customer wants allowedAudience to be the AgentCore runtime or an API
identifier instead of urn:com.networknt, make jwtAudience environment
specific and align it with the AgentCore authorizer configuration.
Implementation Plan
Phase 1: Discovery Metadata
- Rust: add
publicIssuerBaseUrl,oidcDiscoveryEnabled, anddefaultProviderIdtoServerConfig. - Java: add
publicIssuerBaseUrl,oidcDiscoveryEnabled,defaultProviderId, and optionaloidcScopesSupportedtoOAuthConfig. - Rust: add provider-scoped discovery route in
apps/light-oauth/src/main.rs. - Java: add
ProviderIdOpenIdConfigurationGetHandlerand register it inhandler.ymlandvalues.yml. - Java: add the provider-scoped discovery path to
openapi.yamland explicitly mark it as a public endpoint (security: []) so the endpoint remains public ifJwtVerifyHandleris included in the route chain. - Build discovery URLs from the public issuer base URL and provider id.
- Return
404if discovery is disabled or the provider does not exist. - Add tests for discovery JSON shape and URL construction.
- Update local/dev config examples with a public issuer base URL.
Phase 2: AgentCore Claim Compatibility
- Rust: add
client_id,scope, andsubtoJwtClaims. - Java: update
ProviderIdTokenPostHandlerclaim builders:mockCcClaims,mockBsClaims, andmockAcClaims. - Keep
cidandscpin both implementations. - Add a reserved-claim guard for flattened/custom claims in both implementations.
- Java: decide whether
ProviderIdSigningPostHandlershould use put-if-absent behavior for reserved claims, or document that the signing endpoint is for trusted callers that control the full JWT payload. - Add tests that decode a generated token and assert AgentCore claim names.
- Add a sample AgentCore authorizer configuration to docs/config notes.
Phase 3: JWKS and Rotation Contract
- Add tests proving the token
kidis available in/keys. - Decide whether
/keysshould returnapplication/jwk-set+jsonimmediately or stayapplication/jsonfor one release. - Add
Cache-Controlwith a short TTL. - Add an operational check that warns if the current signing key is missing from the published provider JWKS.
- Java: keep
ProviderIdKeysGetHandlerbehavior aligned with the Rust/keysendpoint, including status codes and cache headers.
Phase 4: Optional Root Discovery
- Add
GET /.well-known/openid-configurationonly whendefaultProviderIdis configured. - Make the root metadata identical to the provider-scoped metadata for the default provider.
- Document that multi-provider enterprise deployments should prefer provider-scoped discovery URLs.
Java Implementation Notes
The Java implementation should stay structurally close to the existing
oauth-kafka handler model.
Add a new handler:
src/main/java/com/networknt/oauth/handler/ProviderIdOpenIdConfigurationGetHandler.java
Register it in handler.yml:
- path: '/oauth2/{providerId}/.well-known/openid-configuration'
method: 'GET'
exec:
- default
- openidConfigurationGet
Note: Ensure that this endpoint is marked with security: [] in openapi.yaml
so that the endpoint remains public if JwtVerifyHandler is included in the route
chain (which may happen in enterprise overrides).
Register the handler alias in values.yml:
- com.networknt.oauth.handler.ProviderIdOpenIdConfigurationGetHandler@openidConfigurationGet
Extend oauth.yml and OAuthConfig:
oidcDiscoveryEnabled: ${oauth.oidcDiscoveryEnabled:true}
publicIssuerBaseUrl: ${oauth.publicIssuerBaseUrl:}
defaultProviderId: ${oauth.defaultProviderId:}
oidcScopesSupported: ${oauth.oidcScopesSupported:}
Use Config.getInstance().getJsonObjectConfig(OAuthConfig.CONFIG_NAME, OAuthConfig.class) or the local equivalent pattern already used by the token
handler to load this configuration.
The discovery handler should:
- read
{providerId}fromexchange.getQueryParameters() - return
404when discovery is disabled or the provider lookup fails - build
issuer,token_endpoint,authorization_endpoint, andjwks_urifrompublicIssuerBaseUrlplus/oauth2/{providerId} - return
application/json - avoid using
HostorX-Forwarded-*headers as the default source of the public issuer URL
For token claims, change Java helper methods as follows:
mockCcClaims:
cid, scp, client_id, scope, sub=clientId
mockBsClaims:
cid, scp, client_id, scope, sub=clientId
mockAcClaims:
uid, uty, cid, scp, client_id, scope, sub=userId
Keep existing Java tests for legacy claims, and add new tests that decode the
JWT and assert client_id, scope, and sub.
Validation Checklist
For a customer-facing AgentCore setup, validate:
curl -k https://oauth.customer.example.com/oauth2/{providerId}/.well-known/openid-configuration
curl -k https://oauth.customer.example.com/oauth2/{providerId}/keys
Then decode a minted token and confirm:
issequals discoveryissuer- discovery URL ends with
/.well-known/openid-configuration - discovery
jwks_uriis externally reachable by AWS - JWT header
kidexists in the JWKS audmatches AgentCoreallowedAudienceclient_idmatches AgentCoreallowedClientsscopecontains each required AgentCoreallowedScopesentry- token is signed with
RS256 - certificate chain for the public issuer URL is trusted by AWS
For API Gateway HTTP authorizer deployments, enable the equivalent of
FailOnWarnings so discovery failures fail deployment loudly.
Security Notes
- Do not derive public issuer URLs from untrusted request headers by default. Use explicit configuration. If proxy headers are supported later, trust them only behind a configured gateway.
- Prefer HTTPS public issuer URLs. Local development can allow localhost and self-signed certificates, but enterprise AgentCore setup should use a public CA trusted by AWS.
- Do not let custom token claims override reserved claims.
- Keep short-lived access tokens for AgentCore invocation unless the customer has a specific long-lived service token use case.
- Keep client secrets out of browser flows. Use backend-mediated token exchange or confidential clients where needed.
- CORS: While AgentCore calls the discovery endpoint server-to-server, if
any SPAs need to read this metadata, ensure that the provider-scoped and optional
root discovery paths are placed on a handler chain that includes
cors(sincecorsis not in thedefaultchain by default inoauth-kafka), and ensurecors.ymlallowsGETon these paths.
Resolved Questions
- Should
jwtAudienceremain a single string, or shouldlight-oauthsupport multiple audiences inaudfor AgentCore plus existing Light services? Resolution: Support either a string or an array of strings foraud, but keep the default as the existing single string. The current Rust issuer and verifier are string-shaped and may fail to decode tokens ifaudbecomes an unconditional array. Update the verifiers and tests to support an array before enabling multi-audience output by default. - Should
auth_client_t.client_idremain the only client identifier, or do we need an external client alias for customers that cannot use UUID client ids in AWS configuration? Resolution: Keep it as the only identifier for Phase 1 to reduce scope. If AWS AgentCore restricts UUID formats, a client alias feature can be proposed in Phase 2. - Should the service expose OAuth 2.0 Authorization Server Metadata at
/.well-known/oauth-authorization-serverin addition to OIDC discovery? Resolution: No, OIDC discovery (openid-configuration) is sufficient for AgentCore and most standard OIDC consumers. - Should discovery include only configured scopes, or query active client scopes
dynamically per provider?
Resolution: Use a static configured list (
oidcScopesSupported) for Phase 1. Querying active scopes dynamically could introduce performance overhead for discovery. - Should key rotation update
auth_provider_t.jwktransactionally withauth_provider_key_t, or should/keysbe generated directly fromauth_provider_key_t? Resolution: They must be updated transactionally or/keysshould generate its payload directly fromauth_provider_key_t. Serving mismatched JWKS metadata will break token verification. Generating directly fromauth_provider_key_tis the most reliable design. The dynamic JWKS must include every active public verification key that can validate currently valid tokens (including current, previous rotation keys, and long-lived keys if long-lived tokens are still issued). It must never expose private key material.
Source Links
- GitHub issue: https://github.com/lightapi/portal-service/issues/44
- AWS AgentCore OAuth and JWT inbound auth: https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/runtime-oauth.html
- AWS API Gateway OIDC JWT authorizer debugging: https://loige.co/debugging-api-gateway-http-oidc-jwt-authorizer/
- OIDC discovery field overview: https://www.authgear.com/post/well-known-openid-configuration/
OpenAPI Endpoint Parameter Mapping Design
This document outlines the design for passing OpenAPI parameter mapping details (path parameters, query parameters, headers, cookies, and body) from SpecUtil to the mcp-router in light-fabric. This enables the MCP router to correctly invoke the backend REST APIs based on flat tool call arguments provided by AI agents.
Context & Motivation
When the OpenAPI specification is parsed by SpecUtil.java, endpoints are registered in the Light Portal database, and a flat toolSchema is generated to represent the input schema.
For example, given a GET request with query parameters (like /offers) or path parameters (like /customers/{customerId}), the parameters are flattened into a single JSON schema structure:
{
"type": "object",
"properties": {
"segment": { "type": "string", "description": "Customer segment filter." },
"state": { "type": "string", "description": "Region or province filter." }
}
}
The AI agent invokes this tool by passing a flat map of arguments:
{
"segment": "premium",
"state": "ON"
}
Currently, the mcp-router in light-fabric does not know where each argument belongs (e.g., whether it should be placed in the URL path, query string, headers, or request body). For GET requests, it defaults to appending all arguments as query parameters. For POST/PUT/PATCH requests, it defaults to placing all arguments in the JSON body.
This leads to several failures:
- Path parameters (e.g.
{customerId}) are not substituted in the URL path. - Header parameters and Cookies are completely lost or put in the wrong place.
- Mixed requests (e.g. a
POSTwith a URL path parameter and a JSON body) cannot be assembled correctly.
Design Requirements
- Accuracy: The router must place every argument in the exact location (path, query, header, cookie, or body) defined by the OpenAPI specification.
- Efficiency / Cleanliness: The solution must not increase token usage for the LLM agents. Gateway-specific routing details should remain hidden from public tool schemas exposed to agents.
- Backward Compatibility: If no mapping metadata is provided, the router should fall back to its existing default routing rules.
Design Options for Storing Parameter Locations
We evaluated two options for conveying parameter mapping information from the Spec parser to the gateway router:
Option A: Schema-Level Annotations (toolSchema)
Inject custom attributes (such as "x-in": "query", "x-in": "path") directly into the JSON Schema properties:
{
"type": "object",
"properties": {
"customerId": {
"type": "string",
"x-in": "path"
}
}
}
- Pros: Self-contained schema where each field is annotated with its location.
- Cons: Increases the payload size of
inputSchemasent to the LLM agent viatools/list, leading to wasted token count and exposing gateway-internal routing details to the agent.
Option B: Metadata-Level Mappings (toolMetadata) - RECOMMENDED
Store the parameter locations in the private toolMetadata payload, which is saved in the database and loaded by the gateway, but is filtered out and never sent to the LLM agent.
{
"routing": {
"domain": "Offers",
"sourceProtocol": "openapi"
},
"parameters": {
"customerId": "path",
"segment": "query",
"X-Trace-Id": "header",
"body": "body"
}
}
- Pros:
- Keeps the public
toolSchemaclean and minimal. - Saves LLM token costs.
- Consistently places all gateway-internal routing decisions inside the private
toolMetadatastructure.
- Keeps the public
- Cons: Slightly split parsing (schema for validation, metadata for execution), but since the gateway already deserializes both, this has negligible overhead.
Detailed Solution
We will implement Option B. The design requires updates to two components: SpecUtil.java (spec parsing) and mcp.rs (routing execution in the Rust gateway).
1. Spec Parser Changes (SpecUtil.java)
When parsing an OpenAPI spec in SpecUtil.java, we will build a parameters location map of type Map<String, String> mapping each parameter name to its location:
path->"path"query->"query"header->"header"cookie->"cookie"- Request Body ->
"body"(mapped from the unified schema body property for body-capable HTTP methods)
This map will be attached to routingExtras during metadata enrichment under the "parameters" key, resulting in the following toolMetadata structure:
{
"routing": {
"domain": "Offers",
"sourceProtocol": "openapi",
"parameters": {
"segment": "query",
"state": "query",
"customerId": "path"
}
},
"safety": {
"read_only": true,
"destructive": false
}
}
2. Rust Gateway Router Changes (mcp.rs)
The mcp.rs module in light-pingora will be updated as follows:
- Extract Parameter Locations: When caching or loading tools, the router will deserialize the
parametersmap fromtool_metadata.routing.parameters. - Argument Placement: When executing an HTTP tool call, the router will partition the
argumentsmap into:- Path Map: Key-value pairs where location is
"path". - Query Map: Key-value pairs where location is
"query". - Header Map: Key-value pairs where location is
"header". - Cookie Map: Key-value pairs where location is
"cookie". - Body Val: The argument corresponding to the key mapped to
"body". If no explicit body mapping is defined but the HTTP method allows a body (POST/PUT/PATCH), any arguments not explicitly mapped to path/query/header/cookie will be packed into the JSON request body.
- Path Map: Key-value pairs where location is
- Build Outbound Request:
- Path Substitution: Iterate through the path map and replace
{key}placeholders in the tool URL path. - Query Serialization: Append the query map properties to the target URL’s query string using URL-encoding.
- Header Injection: Append header map values as HTTP headers.
- Cookie Injection: Format cookie map values into the
Cookieheader. - Body Serialization: Attach the JSON body payload to the outbound HTTP request.
- Path Substitution: Iterate through the path map and replace
Concrete Examples
Example 1: GET /offers (Query Filters)
Original OpenAPI Specification
/offers:
get:
operationId: searchOffers
parameters:
- name: segment
in: query
schema:
type: string
- name: state
in: query
schema:
type: string
Generated Database Artifacts
toolSchema:{ "type": "object", "properties": { "segment": { "type": "string" }, "state": { "type": "string" } } }toolMetadata:{ "routing": { "domain": "Offers", "sourceProtocol": "openapi", "parameters": { "segment": "query", "state": "query" } } }
Tool Call Arguments
{
"segment": "premium",
"state": "ON"
}
Outgoing REST Call
GET /offers?segment=premium&state=ON HTTP/1.1
Host: backend-service
Example 2: GET /customers/{customerId} (Path Parameter)
Original OpenAPI Specification
/customers/{customerId}:
get:
operationId: getCustomerProfile
parameters:
- name: customerId
in: path
required: true
schema:
type: string
Generated Database Artifacts
toolSchema:{ "type": "object", "properties": { "customerId": { "type": "string" } }, "required": ["customerId"] }toolMetadata:{ "routing": { "domain": "Customers", "sourceProtocol": "openapi", "parameters": { "customerId": "path" } } }
Tool Call Arguments
{
"customerId": "CUST-1001"
}
Outgoing REST Call
GET /customers/CUST-1001 HTTP/1.1
Host: backend-service
Example 3: PUT /customers/{customerId}/preferences (Mixed Path & Body)
Original OpenAPI Specification
/customers/{customerId}/preferences:
put:
operationId: updateCustomerPreferences
parameters:
- name: customerId
in: path
required: true
schema:
type: string
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
channel:
type: string
consent:
type: boolean
Generated Database Artifacts
toolSchema:{ "type": "object", "properties": { "customerId": { "type": "string" }, "body": { "type": "object", "properties": { "channel": { "type": "string" }, "consent": { "type": "boolean" } } } }, "required": ["customerId", "body"] }toolMetadata:{ "routing": { "domain": "Customers", "sourceProtocol": "openapi", "parameters": { "customerId": "path", "body": "body" } } }
Tool Call Arguments
{
"customerId": "CUST-1001",
"body": {
"channel": "portal",
"consent": true
}
}
Outgoing REST Call
PUT /customers/CUST-1001/preferences HTTP/1.1
Host: backend-service
Content-Type: application/json
{"channel":"portal","consent":true}
Portal View Help
This is the fallback help page for portal-view.
Use this section when a page, form, or task does not yet have a more specific
help page. The contextual help design expects the portal UI to link here when a
specific helpPath is missing.
Common Starting Points
- Pages explain what a screen is used for and which actions are available.
- Forms explain when to submit a command and what happens after submission.
- Tasks explain multi-step workflows that span pages and forms.
- Concepts explain reusable portal ideas such as ownership, hosts, and API versioning.
Portal View Page Help
This section contains page-level help for portal-view.
Page help should explain what the screen is for, who can access it, which records are visible, and which common actions are available.
Available page guides:
- Task Center
- User Session
- API Catalog
- Service Endpoint
- Workflow Catalog
- Schema Catalog
- Skill Workspace
Task Center
Use Task Center to start guided portal workflows that span multiple existing pages and forms.
Task Center does not replace the underlying pages. It gives each workflow a single starting point, carries useful context in the URL, and links to the forms or admin pages needed to finish the work.
Where Task Context Is Stored
Task context is stored in the user’s browser sessionStorage, not in the portal
database. The saved values are local to the current browser session and are used
to restore Recent Tasks, skipped checklist steps, and the context chips shown on
task pages.
Task Center uses session storage keys such as:
portal-view.taskContext.<taskId>portal-view.taskSkippedSteps.<taskId>portal-view.recentTaskContextsportal-view.recentPages
Because this state is browser-local, it is not shared across users, devices, or different browser sessions. Clearing browser session storage, using Clear Context, or completing a task removes the local task context and the task no longer appears in Recent Tasks.
Common areas:
- search for tasks, pages, forms, or entity context
- filter tasks by category
- continue tasks shown in Recent Tasks
- open context-aware suggestions when the URL already contains entity IDs
- open a task detail page to review required and optional steps
Recent Tasks and Suggested Tasks are shown separately from the category list. When there is no search query, tasks already shown in those sections are hidden from the category cards so the same task does not appear twice on the page.
Task details show each workflow step, progress status, related pages, and actions for opening the next page or form. When a task opens another page, the portal carries task context through the URL so the destination can prefill or highlight the relevant record when supported.
Reference Table Admin
The Reference Table Admin page allows you to create and manage reference-data tables for your portal view.
Global vs. Host-Specific Tables
Reference tables can be defined at two levels:
- Global Reference Tables: These are built-in or system-wide tables that have no specific
hostIdassigned (the Host ID column will display as “Global”). They provide a baseline set of reference data accessible to all hosts. - Host-Specific Reference Tables: These are tables created by and assigned to a specific host (displaying the host’s ID in the Host ID column). They contain reference data that is isolated and only accessible to that particular host.
Tip
Expanding Global Tables: You can define a host-specific reference table using the exact same table name as an existing global reference table. By doing this, you can expand or override the global reference table entries with your own host-specific values, tailoring the reference data to your host’s needs without affecting other hosts.
Usage in Forms.json
The primary consumer of reference tables in portal-view is the React Schema Form component, which dynamically renders dropdowns, radios, and multi-select fields based on Forms.json.
In portal-view/src/data/Forms.json, fields that require dynamic reference data specify a URL pointing to the backend API.
Example of a standard dropdown:
{
"key": "user_type",
"type": "select",
"titleMap": {
"url": "/r/data?name=user_type"
}
}
Example of a cascading (dependent) dropdown using the host context and a parent field value:
{
"key": "province",
"type": "select",
"titleMap": {
"url": "/r/data?name=province&host={0}&rela=country-province&from={1}"
}
}
The /r/data API
The /r/data endpoint is exposed by the portal-service (specifically in apps/portal-service) to serve reference data securely and efficiently to the frontend.
It accepts several important query parameters to shape the response:
name: ThetableNameof the reference table you want to fetch (e.g.,country,user_type).host: ThehostIdof the current user’s workspace. Passing this parameter ensures that any host-specific reference values (overrides/expansions) are merged seamlessly with the global values.rela: The ID of a relationship mapping (Reference Relation). This is used for dependent datasets (e.g.,country-province).from: The actual selected value of the parent field in the relationship (e.g., ifcountrywas set toUS,from=USwould fetch only provinces belonging to the US).
The portal-service securely resolves these requests, fetches the necessary values from the underlying ref-query service, evaluates relationships, and returns a key-value map compatible with react-schema-form’s titleMap or dynaselect.
Example: Global vs. Host-Specific Expansion (createInstance form)
A perfect example of how global and host-specific tables interact is found in the Create Instance form, specifically between the environment and envTag fields.
1. The Global Field (environment)
The environment field is designed to ONLY show the standard global environments. It does not pass the host parameter to the API.
{
"key": "environment",
"type": "dynaselect",
"multiple": false,
"action": {
"url": "/r/data?name=environment"
}
}
2. The Expanded Field (envTag)
The envTag field allows you to select a specific environment tag. This field passes the hostId to the API, meaning the resulting dropdown will combine the global environments WITH any host-specific environment tags you have defined.
{
"key": "envTag",
"type": "dynaselect",
"multiple": false,
"action": {
"url": "/r/data?name=environment&host={0}",
"params": [
"hostId"
]
}
}
Viewing Both Tables
To see both the global and your host-specific reference tables in action:
- Go to the Reference Table Admin page.
- In the column filters, type
environmentunder the Table Name column. - You will see two results:
- One row with an empty (or “Global”) Host ID. This is the global table.
- One row with your specific Host ID. This is where you can add custom tags that will only appear in your
envTagdropdown.
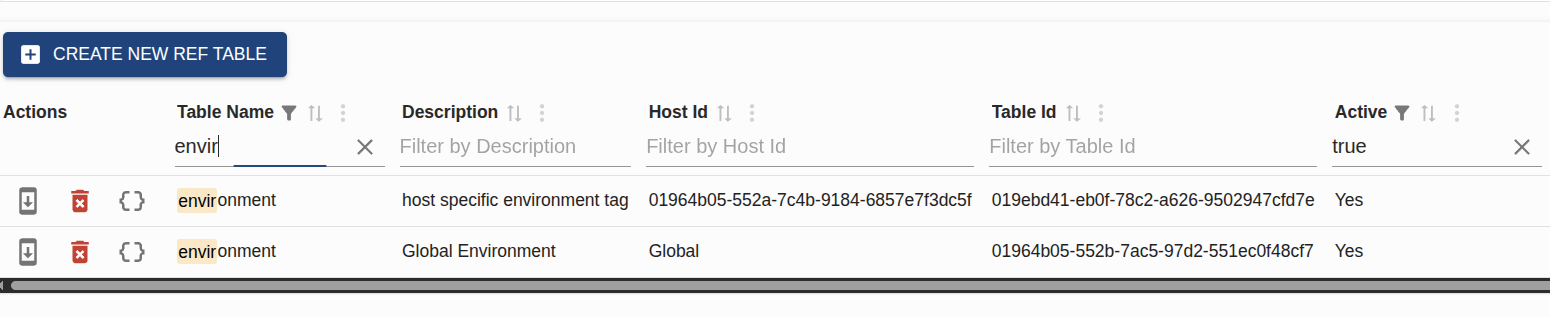
List Rule
The List Rule page allows administrators to view, search, and manage YAML rules associated with specific service API endpoints.
This page is designed for users to add existing rules to the endpoint for request access control (req-acc) and response filter (res-fil).
The rule setup on this page associates one or more rules with the current endpoint. These CEL-backed rules are invoked from either the access-control handler for API access or the mcp-router handler for MCP access to enforce fine-grained authorization by matching the user security profile with the endpoint security definitions.
For more details on light rule and security configuration, please refer to the following resources:
Key Features
- Filter Active Rules: Toggle search filters to view active/inactive rules.
- Add Rule to Endpoint: Easily attach a rule to the selected endpoint.
- Delete Rules: Remove rule configurations from endpoints.
Rule Admin
The Rule Admin page allows administrators to create and manage YAML rules with CEL condition expressions and actions.
For most users, they just need to pick up rules pre-defined in this page. We have defined some global rules to share with all tenants. Each tenant can create host-specific rules that can be used with the tenant.
When creating a new rule, the default condition security profile is strict. If standard profile is selected, a workflow task will be assigned to the rule-admin role for approval.
References
User Session
Use User Session to review and revoke OAuth sessions for your own account.
The User Session pages are self-service pages. They use the signed-in user’s identity from the authenticated session, and the backend self-service actions apply the current user scope again. Browser table filters are only usability controls; they are not the authorization boundary.
Available views:
- My Sessions shows active login sessions by default. Change the status filter if you need to review older revoked or expired sessions.
- My Refresh Tokens shows active refresh-token-backed sessions for your account.
- My Session Audit shows login, refresh, failure, and revocation events for your account.
Common actions:
- open audit history for a session
- open refresh tokens for a session
- revoke one of your sessions
- revoke a refresh-token-backed session
Revoking your current browser session signs you out after the revoke succeeds. If the portal cannot identify whether the selected session is the current browser session, it still warns that the action may sign you out.
Administrators should continue to use OAuth Admin for host-wide session, refresh-token, and audit review.
API Catalog
Use API Catalog to browse APIs that are ready for consumer discovery.
The catalog is backed by the same API records, categories, and tags used by API Admin and the API create/update forms. It is intended for browse and discovery, not bulk administration.
Common filters:
- search text for API name, id, and description
- categories for stable browse buckets
- grouped tags for capability, protocol, lifecycle, security, runtime, domain, consumer, operations, and integration facets
- active or inactive status
- sort and card/list view options
Catalog cards show a compact operational summary:
- active API version count and latest version
- endpoint count across active versions
- runtime bindings through instance APIs
- access-control coverage from active endpoint rules
Common actions:
- open API details and versions
- open endpoints for the latest active version
- create a new API version
- update API metadata when you own the API or have API administrator access
- continue related publish, MCP onboarding, or access-control tasks
Service Endpoint
The Service Endpoint page lists the endpoints generated for an API version. Use it to review endpoint metadata and configure endpoint-level access control.
Endpoint-Level Access Control
Access rules, permissions, row filters, and column filters are stored against individual endpoints. Bulk operations on this page write the same endpoint-level records used by the existing per-endpoint pages.
The page does not define API-version-level inherited defaults. After a bulk update, each affected endpoint has its own materialized access-control records.
Bulk Access
Select one or more endpoint rows and choose Bulk Access to apply one access-control operation to all selected endpoints.
Supported operation groups include:
- endpoint rule assignment
- role, group, position, and attribute permissions
- role, group, position, and attribute row filters
- role, group, position, and attribute column filters
The default conflict mode is Skip Existing, which avoids changing matching records that already exist. Use Overwrite Existing only when the selected endpoints should receive the submitted configuration.
Access Overview
Choose Access Overview to review the final endpoint-level configuration for the current API version.
The overview shows:
- endpoint rule assignments grouped by rule type
- permissions by principal type
- row filters by principal type
- column filters by principal type
- summary counts for endpoints with missing configuration, permissions, row filters, and column filters
Use the missing-only filter to find endpoints that still have no access configuration after a bulk update.
Per-Endpoint Adjustments
Use the row action icons when one endpoint needs a specific exception. The per-endpoint pages remain the detailed editors for rule lists, permissions, row filters, and column filters.
Workflow Catalog
Use Workflow Catalog to browse workflow definitions that can be discovered or started from Marketplace.
Visible records include workflow definitions published to the catalog and workflow definitions you can already access through ownership or position scope. Workflow administrators can see all workflow definitions for the current host.
Common filters:
- search text for namespace, name, and version
- workflow categories
- grouped workflow tags
- active or inactive status
- sort and card/list view options
Catalog cards show workflow metadata, publication state, categories, tags, and a short definition preview. Use the details drawer to inspect the workflow id, owner metadata, taxonomy, and read-only YAML preview without leaving the catalog.
Common actions:
- start a workflow from the selected definition
- open the details drawer
- edit workflow definitions you own or administer
- create a new workflow definition
- open Workflow Admin for table-based management
Publishing a workflow to the catalog is controlled by the workflow definition’s
catalogVisible setting. Publishing makes the workflow discoverable in
Marketplace, but editing and deleting remain restricted to owners, owner
positions, workflow administrators, and administrators.
Schema Catalog
Use Schema Catalog to browse reusable schema contracts from Marketplace.
The catalog is backed by schema registry records, categories, and tags. It is intended for discovery and inspection, not bulk schema administration.
Visible records include published global schemas, published schemas for the current host, and draft or retired schemas that you own or can administer.
Common filters:
- search text for schema id, name, description, source, and owner metadata
- schema type, starting with JSON Schema
- schema status, such as draft, published, and retired
- schema categories
- grouped schema tags
- active or inactive status
- sort and card/list view options
Catalog cards show a compact contract summary:
- schema id, name, latest published version, and type
- spec version, source, status, and scope
- schema alias and external URL when external access is enabled
- categories and tags
- whether the schema body is available for preview
- whether the schema can drive config-backed form generation
Common actions:
- open the schema details drawer
- preview JSON Schema source
- copy a schema reference
- copy an external schema URL when available
- create a new schema version when you have permission
- edit draft metadata and taxonomy when you own or administer the schema
- open Schema Admin for table-based management
Skill Workspace
Use Skill Workspace to review and assemble one GenAI skill after the skill record has been created.
A skill contains the reusable instruction content that an agent can use. The workspace shows the skill metadata, taxonomy, linked tools, linked workflows, and test entry points in one place.
Opening The Workspace
Open the workspace from the GenAI Skills page by selecting the workspace action for a skill row.
The workspace needs a skillId. If the page is opened from a task or another
GenAI page, the portal carries that context through the URL so related actions
can prefill the current skill.
Header Actions
Common actions:
Back: return to the source page that opened the workspace.Tool: create a structured skill-to-tool link for the current skill.Workflow: create a structured skill-to-workflow link for the current skill.Edit Skill: update the skill metadata, parent skill, taxonomy, version, and content markdown.Help: open this guide in the portal documentation.
Overview Tab
Use the Overview tab to confirm the skill identity and routing metadata.
The Skill panel shows:
- skill name
- version
- parent skill id
- active state
The Routing panel shows human-readable category and tag labels. These labels
come from the taxonomy tables. The update form stores the selected
categoryIds and tagIds, while the workspace displays the resolved labels.
The Description panel is a short human-readable summary of what the skill is for.
Tools Tab
Use the Tools tab to review the executable tools linked to the skill.
Each row shows:
- tool name
- tool id
- access level
- link configuration
Add tool links with the Tool button in the header. Tool links are structured
records; they are not parsed from the skill’s markdown content.
Workflow Tab
Use the Workflow tab to review workflows linked to the skill.
Each row shows:
- workflow name or workflow definition id
- workflow version
- workflow role
- start mode
- row actions
Available row actions:
- validate workflow tool links
- open the workflow editor
- start the workflow
Validation checks whether the linked workflow can resolve the tool references needed by the skill workflow connection.
Preview Tab
Use the Preview tab to inspect the skill’s contentMarkdown and composition.
contentMarkdown is the instruction body for the skill. It should describe the
skill’s goal, operating rules, and expected output format. It is not the source
of truth for executable tool, workflow, or endpoint references.
The Composition panel summarizes how many tools and workflows are linked and which workflow is treated as primary.
Test Tab
Use the Test tab to start the primary workflow linked to the skill.
The Start Primary Workflow button is enabled only when the skill has at least
one linked workflow. The primary workflow is the workflow with role primary;
if no primary role exists, the workspace uses the first linked workflow.
Recommended Skill Authoring Flow
- Create the skill with a clear name, description, content markdown, taxonomy, and optional parent skill.
- Open the Skill Workspace.
- Add the tools the skill is allowed to use.
- Add the workflow that should execute or validate the skill.
- Validate workflow tool links.
- Preview the skill content and composition.
- Start the primary workflow for a manual test.
- Edit the skill if metadata, taxonomy, or instructions need adjustment.
Troubleshooting
If categories or tags are missing, edit the skill and confirm taxonomy values are selected.
If a tool or workflow is missing, add the structured link from the workspace.
Do not rely on a markdown References section to create executable links.
If workflow validation fails, open the workflow editor and confirm the workflow uses tools that are linked to the skill.
If the Test tab is disabled, link a workflow to the skill first.
API Admin
Use API Admin to create, review, update, and retire APIs owned by your team or visible to your administrator role.
This page is owner-aware. Regular users should see only APIs they own or can access through their position. API administrators can see all APIs for the host.
Common actions:
- create a new API
- update API metadata
- open API versions
- link the API into onboarding or marketplace tasks
API Detail
Use API Detail to review API versions and version-specific integration details.
This page helps users move from a business API record to the concrete API versions that can be linked to instances, MCP tools, marketplace listings, or access control rules.
Common actions:
- create an API version
- update version metadata
- review endpoint and scope details
- start related task flows from the selected API version
App Admin
Use App Admin to manage client applications that own OAuth clients and instance application links.
This page is owner-aware. Regular users should see only apps they own or can access through their position. App administrators can see all apps for the host.
Common actions:
- create a client app
- update app metadata
- open OAuth clients for the app
- link the app to an instance
OAuth Client
Use OAuth Client to create and manage OAuth clients for applications, APIs, or instances.
This page is owner-aware. Regular users should see only OAuth clients they own or can access through their position. OAuth client administrators can see all OAuth clients for the host.
Common actions:
- create an OAuth client
- update client metadata
- regenerate a client secret
- review scopes and token-exchange settings
- open client tokens
Client Secrets
When a client is created, the page returns the generated clientId and
clientSecret. Copy and store the secret immediately. The portal stores only a
password verifier for future authentication; it cannot show the original clear
secret again.
If the secret is lost, use the Regenerate Client Secret row action. The action creates a new secret, replaces the stored verifier, and shows the new clear secret one time. Copy it before closing the dialog.
Regenerating a secret affects future client authentication. Existing access tokens remain valid until they expire, but new token requests must use the new secret after the event is processed.
OAuth Client Token
Use OAuth Client Token to create and review long-lived client tokens.
Tokens are sensitive. Users should create tokens only for clients they own or are authorized to manage. Administrators can review all client tokens for the host when their role allows it.
Common actions:
- create a client token
- review token metadata
- delete or rotate tokens according to operational policy
Instance Admin
Use Instance Admin to manage service instances for the current host.
This page is owner-aware. Regular users should see only instances they own or can access through their position. Instance administrators can see all instances for the host.
Common actions:
- create an instance
- update instance metadata
- review linked APIs and apps
- open runtime endpoints and configuration links
Runtime Instance
Use Runtime Instance to review runtime endpoints for services.
Runtime instances describe where a service is running and how the portal can reach it for deployment, gateway, or operational workflows.
Common actions:
- create a runtime endpoint
- update endpoint status and connection details
- review active runtime records for an instance or service
Instance API
Use Instance API to link API versions to service instances.
This relationship tells the portal which API version is served by which instance and is used by gateway, MCP, configuration, and access-control tasks.
Common actions:
- link an API version to an instance
- review existing instance API links
- open path prefixes or MCP tool mappings
Instance API Path Prefix
Use Instance API Path Prefix to manage route prefixes for an API version linked to an instance.
Path prefixes help gateways and tools route traffic to the correct API surface.
Common actions:
- add a path prefix
- update a path prefix ownership position
- review prefixes for an instance API link
Instance App
Use Instance App to link client apps to service instances.
This relationship is used when an application needs to interact with a deployed instance and related APIs.
Common actions:
- link an app to an instance
- review app links for an instance
- open app API relationship records
Instance App API
Use Instance App API to link an instance app relationship to an instance API relationship.
This page connects which app can use which API on a specific service instance.
Common actions:
- create an instance app API link
- review existing links
- open configuration for the relationship
Schedule Admin
Use Schedule Admin to create and manage scheduled portal events.
This page is owner-aware. Regular users should see only schedules they own or can access through their position. Schedule administrators can see all schedules for the host.
Common actions:
- create a schedule
- update schedule timing or event data
- delete schedules no longer needed
Workflow Definition
Use Workflow Definition to create and manage workflow definitions.
Workflow definitions describe repeatable processes that can be started manually or triggered by other portal events.
Common actions:
- create a workflow definition
- update workflow YAML
- start or review related workflow execution records
Portal View Form Help
This section contains form-level help for generated and custom portal-view
forms.
Form help should explain when to use the form, what happens after submit, important required fields, important optional fields, ownership behavior, and common validation problems.
Create API
Use this form to register a new API record for the current host.
After submission, the API becomes available for version creation, marketplace publishing, MCP onboarding, instance links, and access-control tasks.
Important fields:
apiId: stable API identifier for the hostapiName: user-facing API nameapiStatus: lifecycle statusownerPositionId: optional position owner for team access
Update API
Use this form to update API metadata.
Updating an API changes descriptive and ownership metadata for the API record. It does not replace the API version specification.
Important fields:
apiName: user-facing API nameapiStatus: lifecycle statusownerPositionId: optional position owner for team access
Create API Version
Use this form to add a version to an existing API.
After submission, the API version can be linked to instances, gateway flows, MCP tools, marketplace publishing, and access-control rules.
Important fields:
apiId: parent APIapiVersion: version labelapiType: API style such as OpenAPI, GraphQL, Hybrid, or MCPserviceId: backing service identifierspec: API specification text, or MCPtools/listJSON output for MCP API versionstransportConfig: MCP transport and URL whenapiTypeis MCPownerPositionId: optional position owner for team access
MCP Tool Discovery
For MCP API versions, there are two ways to populate tools:
- If the portal service can reach the MCP server, select
MCPas the API Type and filltransportConfig, for example{"transport":"streamable http","url":"http://localhost:5000/mcp"}. - If the portal service cannot reach the MCP server because of firewall or security boundaries, call the MCP server yourself and paste the response into
spec.
Example manual discovery call:
curl --location --request POST 'http://localhost:5000/mcp' \
--header 'Content-Type: application/json' \
--data-raw '{"jsonrpc":"2.0","id":1,"method":"tools/list","params":{}}'
Paste the response into Spec / MCP Tools JSON. The form accepts any of these
payload shapes.
Full JSON-RPC response:
{
"jsonrpc": "2.0",
"result": {
"tools": [
{
"name": "echo",
"description": "Echoes back the input",
"inputSchema": {
"type": "object",
"properties": {
"message": {
"type": "string"
}
},
"required": [
"message"
]
}
}
]
},
"id": 1
}
Object with a top-level tools array:
{
"tools": [
{
"name": "echo",
"description": "Echoes back the input",
"inputSchema": {
"type": "object",
"properties": {
"message": {
"type": "string"
}
},
"required": [
"message"
]
}
}
]
}
Raw tools array:
[
{
"name": "echo",
"description": "Echoes back the input",
"inputSchema": {
"type": "object",
"properties": {
"message": {
"type": "string"
}
},
"required": [
"message"
]
}
}
]
Keep transportConfig populated with the real MCP transport and URL when the runtime still needs it for invocation.
Update API Version
Use this form to update API version metadata and integration details.
Updating a version can affect downstream instance links, gateway behavior, and task flows that reference the API version.
Important fields:
apiVersion: version labelapiType: API styleserviceId: backing service identifierspec: API specification text, or MCPtools/listJSON output for MCP API versionstransportConfig: MCP transport and URL whenapiTypeis MCPprotocol,envTag, andtargetHost: runtime routing detailsownerPositionId: optional position owner for team access
MCP Tool Discovery
For MCP API versions, there are two ways to refresh tools:
- If the portal service can reach the MCP server, select
MCPas the API Type and filltransportConfig, for example{"transport":"streamable http","url":"http://localhost:5000/mcp"}. - If the portal service cannot reach the MCP server because of firewall or security boundaries, call the MCP server yourself and paste the response into
spec.
Example manual discovery call:
curl --location --request POST 'http://localhost:5000/mcp' \
--header 'Content-Type: application/json' \
--data-raw '{"jsonrpc":"2.0","id":1,"method":"tools/list","params":{}}'
Paste the response into Spec / MCP Tools JSON. The form accepts any of these
payload shapes.
Full JSON-RPC response:
{
"jsonrpc": "2.0",
"result": {
"tools": [
{
"name": "echo",
"description": "Echoes back the input",
"inputSchema": {
"type": "object",
"properties": {
"message": {
"type": "string"
}
},
"required": [
"message"
]
}
}
]
},
"id": 1
}
Object with a top-level tools array:
{
"tools": [
{
"name": "echo",
"description": "Echoes back the input",
"inputSchema": {
"type": "object",
"properties": {
"message": {
"type": "string"
}
},
"required": [
"message"
]
}
}
]
}
Raw tools array:
[
{
"name": "echo",
"description": "Echoes back the input",
"inputSchema": {
"type": "object",
"properties": {
"message": {
"type": "string"
}
},
"required": [
"message"
]
}
}
]
Keep transportConfig populated with the real MCP transport and URL when the runtime still needs it for invocation.
Create App
Use this form to register a client application.
After submission, the app can own OAuth clients and can be linked to service instances.
Important fields:
appId: stable app identifier for the hostappName: user-facing app nameisKafkaApp: whether this app uses Kafka-specific behaviorownerPositionId: optional position owner for team access
Update App
Use this form to update client application metadata.
Updating an app does not automatically change OAuth clients or instance app links that reference the app.
Important fields:
appName: user-facing app nameoperationOwneranddeliveryOwner: business ownership metadataownerPositionId: optional position owner for team access
Create Client
Use this form to create an OAuth client.
An OAuth client can be associated with an app, API version, or instance, depending on the selected ownership context.
Important fields:
clientName: user-facing client nameclientType: client typeclientProfile: OAuth profileproviderId: OAuth providerownerPositionId: optional position owner for team access
Save The Generated Secret
After the client is created, the portal returns the generated clientId and
clientSecret. Copy both values and store them in your secret manager before
leaving the result page.
The portal does not persist the clear clientSecret. It stores only a verifier
for future authentication, so the original secret cannot be shown again. If the
secret is lost, regenerate it from the OAuth Client page and update any systems
that use the old secret.
Save The Generated Credentials
After the client is created, the response includes the generated clientId and
clientSecret. Copy both values and store them in the target application’s
secret manager or deployment configuration immediately.
The clear clientSecret is shown only once. The portal stores only a verifier
for later authentication, so it cannot show the original secret again after you
leave the result page.
If the secret is lost, use the OAuth Client page to regenerate it. Regeneration creates a new secret and invalidates the old secret for future token requests.
Update Client
Use this form to update OAuth client metadata.
Changing client settings can affect token issuance, access scope, and downstream integrations that use the client.
Important fields:
clientName: user-facing client nameclientScope: requested scopestokenExType: token exchange typeownerPositionId: optional position owner for team access
Create Client Token
Use this form to create a long-lived token for an OAuth client.
Client tokens are sensitive. Create them only for clients you own or are authorized to manage.
Important fields:
clientId: OAuth client that will receive the tokenclientSecret: client credential used for token creationownerPositionId: optional position owner for team access
Create Instance
Use this form to create a product/service instance.
After submission, the instance can be linked to API versions, client apps, runtime endpoints, and configuration records.
Important fields:
instanceName: user-facing instance nameproductVersionId: product version for the instanceserviceId: service identifierenvironment,region, andlob: deployment metadataownerPositionId: optional position owner for team access
Environment Configuration Templates
The environment field provides a dropdown of standard environments defined globally in light-portal (e.g., dev, sit, uat, stg, prd).
When setting up a host, you can customize configurations at this environment level. By doing so, the environment acts as a configuration template.
For example, if you customize the dev environment for your host, any new instances you create that select dev as their environment will automatically inherit those customized properties. This prevents you from needing to repeatedly define the same baseline configuration for every single instance.
Of course, this inheritance is flexible: if a specific instance requires unique settings, you can override those environment-level properties directly at the instance level.
Env Tag
The envTag (Environment Tag) acts as a label to logically separate an instance based on its configuration, deployment namespace, or simply to serve as an alias for the same Service ID.
Critically, the combination of Host ID, Service ID, and Env Tag is used to uniquely identify an instance. This unique triad is what the system uses to load the correct configuration from the config server and to register the instance to the controller.
By default, the options in the Env Tag dropdown mirror the standard global environment list. However, because it supports host-specific overrides, each host or tenant can add their own customized Env Tags via the Ref Table Admin page (by creating a table named environment under their Host ID).
Update Instance
Use this form to update service instance metadata.
Updating an instance can affect task context, instance links, and owner-scoped visibility.
Important fields:
instanceName: user-facing instance nameserviceId: service identifiercurrent: whether this instance is the current instance for the serviceownerPositionId: optional position owner for team access
Environment Configuration Templates
The environment field provides a dropdown of standard environments defined globally in light-portal (e.g., dev, sit, uat, stg, prd).
When setting up a host, you can customize configurations at this environment level. By doing so, the environment acts as a configuration template.
For example, if you customize the dev environment for your host, any new instances you create that select dev as their environment will automatically inherit those customized properties. This prevents you from needing to repeatedly define the same baseline configuration for every single instance.
Of course, this inheritance is flexible: if a specific instance requires unique settings, you can override those environment-level properties directly at the instance level.
Env Tag
The envTag (Environment Tag) acts as a label to logically separate an instance based on its configuration, deployment namespace, or simply to serve as an alias for the same Service ID.
Critically, the combination of Host ID, Service ID, and Env Tag is used to uniquely identify an instance. This unique triad is what the system uses to load the correct configuration from the config server and to register the instance to the controller.
By default, the options in the Env Tag dropdown mirror the standard global environment list. However, because it supports host-specific overrides, each host or tenant can add their own customized Env Tags via the Ref Table Admin page (by creating a table named environment under their Host ID).
Create Instance API
Use this form to link an API version to an instance.
After submission, the relationship can be used for route prefixes, MCP tools, configuration, and access-control workflows.
Important fields:
instanceId: target instanceapiVersionId: API version to linkownerPositionId: optional position owner for team access
Create Instance API Path Prefix
Use this form to add a path prefix to an instance API link.
Path prefixes help map incoming gateway paths to the correct API surface.
Important fields:
instanceApiId: instance API relationshippathPrefix: route prefixownerPositionId: optional position owner for team access
Update Instance API Path Prefix
Use this form to update ownership metadata for an instance API path prefix.
The path prefix itself is part of the relationship key and should be treated as stable for the existing record.
Important fields:
instanceApiId: instance API relationshippathPrefix: route prefixownerPositionId: optional position owner for team access
Create Instance App
Use this form to link a client app to an instance.
After submission, the app can be connected to APIs exposed by the same instance.
Important fields:
instanceId: target instanceappId: client appappVersion: app versionownerPositionId: optional position owner for team access
Create Instance App API
Use this form to connect an instance app relationship to an instance API relationship.
This link tells the portal which app can use which API on a specific instance.
Important fields:
instanceAppId: instance app relationshipinstanceApiId: instance API relationshipownerPositionId: optional position owner for team access
Create Runtime Instance
Use this form to create a runtime endpoint for a service.
Runtime instances describe where a service is reachable and support operational workflows.
Important fields:
serviceId: service identifierprotocol: runtime protocolipAddressandportNumber: endpoint locationinstanceStatus: runtime statusownerPositionId: optional position owner for team access
Update Runtime Instance
Use this form to update a runtime endpoint.
Updating runtime details can affect operational workflows that depend on the service endpoint.
Important fields:
runtimeInstanceId: runtime endpoint recordserviceId: service identifieripAddressandportNumber: endpoint locationinstanceStatus: runtime statusownerPositionId: optional position owner for team access
Create Schedule
Use this form to create a scheduled portal event.
After submission, the scheduler can emit the configured event according to the selected frequency and start time.
Important fields:
scheduleName: user-facing schedule namefrequencyUnitandfrequencyTime: schedule cadencestartTs: first scheduled timeeventTopic,eventType, andeventData: event payloadownerPositionId: optional position owner for team access
Update Schedule
Use this form to update a scheduled portal event.
Changing schedule timing or event data affects future executions.
Important fields:
scheduleName: user-facing schedule namefrequencyUnitandfrequencyTime: schedule cadenceeventTopic,eventType, andeventData: event payloadownerPositionId: optional position owner for team access
Create Workflow Definition
Use this form to create a workflow definition.
After submission, the workflow definition can be started manually or referenced by task flows and automation.
Important fields:
namespace: workflow namespacename: workflow nameversion: workflow versiondefinition: workflow YAMLcatalogVisible: publish the workflow in Marketplace Workflow CatalogownerPositionId: optional position owner for team access
Update Workflow Definition
Use this form to update workflow definition metadata and YAML.
Updating the definition affects future workflow starts. Existing process instances may continue according to their already captured definition state.
Important fields:
wfDefId: workflow definition recordnamespace,name, andversion: workflow identitydefinition: workflow YAMLcatalogVisible: publish or remove the workflow from Marketplace Workflow CatalogownerPositionId: optional position owner for team access
Portal View Task Help
This section contains task-level help for workflows that span multiple pages and forms.
Task help should explain the goal, prerequisites, required steps, optional steps, and common next actions.
Available task guides:
- Onboard API to MCP Gateway
- Register Standalone MCP Server
- Publish API
- Register AI Agent
- Manage Instance
- Manage Client App
- Manage Workflow
Onboard API to MCP Gateway
Use this task to expose an existing API through MCP Gateway.
Typical steps:
- select or create an API
- select or create an API version
- choose a deployment mode
- link the API version to a gateway or sidecar instance
- select MCP tools
- configure access control when required
Register Standalone MCP Server
Use this task to register an MCP server that is not derived from an existing API version.
Typical steps:
- register the MCP server
- add a server version
- link the server to a gateway
- review MCP tools
Publish API
Use this task to prepare an API for publication and review.
Typical steps:
- create or select the API
- create or select an API version
- review the marketplace listing
Register AI Agent
Use this task to register an AI agent as an API marketplace asset.
Typical steps:
- create or select the API
- create the API version with API type
agt - create the agent definition for the same API version id
- assign skills when the agent needs reusable behavior
- review tools exposed through the assigned skills
- configure role permissions before exposing the agent
- link the agent API version to a runtime instance when deployment metadata is available
If the agent does not need reusable skills yet, skip the skill assignment step. The tool review step is only useful after skills are assigned, so it can remain optional while you continue to access control or runtime linking.
After all required steps are complete and the remaining optional steps are complete or skipped, use Complete Task on the task detail page. Completing the task clears its stored task context so it no longer appears in Recent Tasks.
The agent definition id is the API version id. This keeps the API catalog and GenAI agent profile as one logical asset instead of two separate identities.
Manage Instance
Use this task to create, review, and connect service instances.
Typical steps:
- create or review the instance
- create or review runtime endpoints
- link APIs to the instance
- link apps to the instance
- manage app API links and path prefixes
Manage Client App
Use this task to manage a client app and its OAuth clients.
Typical steps:
- create or review the client app
- create or review OAuth clients
- link the app to an instance
- create or review client tokens
Manage Workflow
Use this task to create and operate workflow definitions.
Typical steps:
- create or review workflow definitions
- start a workflow
- review process instances, tasks, assignments, worklists, and audit logs
Configs
Use config help pages to understand runtime configuration properties managed through portal-view and the config server.
Common config areas:
- logging filter
- handler chains and paths
Logging Filter
Use logging.filter to control Rust runtime logging for light-gateway and other light-fabric services from config server values.yml.
The value uses the Rust tracing filter syntax. Set a default level first, then add more specific module targets when you need detailed logs for one area.
Example:
logging.filter: info,light_pingora::security=debug
This keeps the service at info level overall and enables debug logs only for the light_pingora::security target. This is useful when debugging JWT verification failures without turning on debug logs for HTTP clients, TLS, and every gateway request.
Log Levels
Supported levels, from least to most verbose:
| Level | Use |
|---|---|
error | Only failures that require attention. |
warn | Warnings and errors. |
info | Normal operational events. This is the recommended default. |
debug | Diagnostic details for troubleshooting. |
trace | Very detailed execution flow. Use for short troubleshooting windows only. |
off can be used for a specific noisy target when you want to suppress it.
Filter Syntax
Common patterns:
# Default info for all targets.
logging.filter: info
# Debug only JWT/security logic.
logging.filter: info,light_pingora::security=debug
# Trace unified-security routing while keeping the rest at info.
logging.filter: info,light_pingora::unified_security=trace
# Debug MCP request handling.
logging.filter: info,light_pingora::mcp=debug
# Debug config loading and runtime reloads.
logging.filter: info,light_runtime=debug
# Reduce noisy dependency logs while debugging gateway code.
logging.filter: info,light_pingora::security=debug,reqwest=warn,hyper_util=warn,rustls=warn
Rules:
- Separate directives with commas.
- The first bare level, such as
info, is the default for all targets. - Use
target=levelfor a specific crate or module. - More specific targets override broader targets.
- Target names use Rust module paths, such as
light_pingora::security.
Common Gateway Targets
These targets are useful for light-gateway troubleshooting:
| Target | What it covers |
|---|---|
light_gateway | Gateway application code and proxy handling. |
light_pingora | Shared Pingora framework code. |
light_pingora::security | JWT verification, JWK loading, issuer and audience checks. |
light_pingora::unified_security | Unified security handler routing across JWT, SJWT, Basic Auth, and API key. |
light_pingora::mcp | MCP routing, backend MCP calls, and MCP response diagnostics. |
light_pingora::handler | Handler duration reporting when handler timing is enabled. |
light_pingora::pii_tokenization | PII tokenization and detokenization runtime warnings. |
light_runtime | Runtime bootstrap, config loading, module registry, config reload, and controller registration. |
light_client | HTTP client configuration and OAuth client support. |
portal_registry | Control-plane websocket registration and registry client behavior. |
reqwest | Outbound HTTP client internals. |
hyper_util | Lower-level HTTP client connection and pooling logs. |
rustls | TLS handshake and certificate details. |
pingora_core | Pingora server lifecycle, listeners, and protocol logs. |
pingora_proxy | Pingora proxy request handling. |
tungstenite | WebSocket handshake and frame-level support used by registry connections. |
Use the narrowest target that contains the evidence you need. For example, prefer info,light_pingora::security=debug over plain debug when investigating JWT verification.
Reload Behavior
logging.filter is reloadable. If the control plane reloads all modules, the runtime logging module reloads the filter from the latest config server values. If logging.filter is not present in values.yml, an all-module reload can return the process to the default filter.
To keep a debug filter across reloads, store it in config server values.yml:
logging.filter: info,light_pingora::security=debug
Then reload the runtime configuration from the control plane. The new filter applies without restarting the gateway.
Recommendations
- Keep the default at
infoin shared environments. - Add
debugortraceonly for the module under investigation. - Remove short-term
debugortraceoverrides after the issue is resolved. - Avoid logging full tokens, secrets, request bodies, or response bodies unless the target log point is known to mask sensitive data.
MSAL Auth: Cookie SameSite
The cookieSameSite property in the msal-auth (and msal-exchange / stateless-auth) configuration maps directly to the SameSite attribute in HTTP Set-Cookie headers. It controls whether the browser should send session cookies (such as accessToken and csrf) along with cross-site requests. This is a foundational browser security mechanism designed to protect against Cross-Site Request Forgery (CSRF) and govern cross-origin tracking.
Configuration Options
You can configure this property in your handler’s configuration file (e.g., msal-auth.yml):
cookieSameSite: None
The gateway maps this property directly to the standard HTTP options (case-sensitive as None, Lax, or Strict):
None: The browser sends the cookie with both cross-site and same-site requests.- Requirement: Modern browsers mandate that if
SameSite=None, the cookie must also be marked asSecure(meaningcookieSecure: true). If you setNonewithSecure: false, browsers like Chrome and Edge will silently block the cookie.
- Requirement: Modern browsers mandate that if
Lax: The cookie is not sent on cross-site API requests (e.g., AJAX/Fetch), except for top-level navigations (like a user clicking a standard link to your site from another site). This is the default behavior of modern browsers if theSameSiteattribute is missing entirely.Strict: The cookie is sent only if the request originates from the exact same site that set the cookie. Cross-site requests will never include the cookie.
Why Default to None?
In modern microservice and Single Page Application (SPA) architectures, the frontend UI and the backend API Gateway are frequently hosted on different origins, especially during development.
For example:
- Frontend SPA:
http://localhost:3000(Local React/Angular dev server) - Backend Gateway:
https://api.dev.mycompany.com(orhttps://localhost:8443)
Because the ports and/or domains don’t match, the browser considers API requests between them as “cross-site”. If cookieSameSite defaulted to Lax or Strict, the browser would refuse to send the authentication cookies when the local UI calls the backend API, leading to immediate 401 Unauthorized errors out of the box.
Defaulting to None provides a seamless developer experience for decoupled SPAs. To safely allow None, light-fabric pairs this behavior with robust Double Submit Cookie CSRF protections (requiring the X-CSRF-TOKEN header). This ensures that even though the browser attaches the cookie cross-origin, an attacker cannot successfully forge a state-changing request because they cannot read or supply the necessary CSRF header token.
MSAL Auth: Enabled
The enabled property controls whether the msal-auth handler is active and processing requests in the gateway.
Configuration Options
enabled: true
true: The handler is fully active. It will intercept requests to theloginPathandlogoutPath, validate sessions on protected routes, and enforce CSRF protections.false: The handler is effectively disabled. Even if it is listed in the execution chain inhandler.yml, it will immediately yield control to the next handler without performing any authentication checks or modifications.
Usage
This toggle is extremely useful for temporarily bypassing authentication in local development or test environments without having to re-write the entire handler.yml routing chain.
MSAL Auth: Login Path
The loginPath property specifies the endpoint where the Single Page Application (SPA) submits a Microsoft Entra ID token to establish a gateway session.
Configuration Options
loginPath: /auth/ms/login
Usage
When the msal-auth handler receives a request (typically a POST) matching this exact path:
- It expects a valid Microsoft Entra ID token in the
Authorization: Bearerheader. - It validates the token using the
security-msal.ymlconfiguration. - If valid, it generates a fresh CSRF token and responds with the
accessTokenandcsrfcookies usingSet-Cookieheaders.
This path must also be mapped in handler.yml to trigger the msal-auth handler.
paths:
- path: /auth/ms/login
method: POST
exec:
- msal-auth
MSAL Auth: Logout Path
The logoutPath property specifies the endpoint where the Single Page Application (SPA) can explicitly terminate an active session.
Configuration Options
logoutPath: /auth/ms/logout
Usage
When the msal-auth handler receives a request matching this exact path, it handles the session termination by clearing the session cookies.
Specifically, it returns Set-Cookie headers with a past expiration date for the accessToken and csrf cookies, ensuring the browser immediately removes them from storage.
This path must also be mapped in handler.yml to trigger the msal-auth handler.
paths:
- path: /auth/ms/logout
exec:
- msal-auth
MSAL Auth: Cookie Domain
The cookieDomain property controls the Domain attribute applied to all Set-Cookie headers generated by the handler.
Configuration Options
cookieDomain: localhost
or
cookieDomain: .mycompany.com
Usage
The Domain attribute tells the browser which hosts are allowed to receive the cookie.
- If you specify a host without a leading dot (e.g.,
localhostorapi.mycompany.com), the browser will only send the cookie to that exact domain. - If you specify a domain with a leading dot (e.g.,
.mycompany.com), the browser will send the cookie to that domain and all of its subdomains (e.g.,app.mycompany.com,admin.mycompany.com).
Note: If the domain is misconfigured or doesn’t match the URL you are using to access the gateway, the browser will refuse to save the cookie entirely.
MSAL Auth: Cookie Path
The cookiePath property controls the Path attribute applied to all Set-Cookie headers generated by the handler.
Configuration Options
cookiePath: /
Usage
The Path attribute dictates the URL paths for which the cookie is valid. The browser will only send the cookie if the request URL matches or is a subdirectory of this path.
In most Single Page Application (SPA) configurations, this should be set to /. Setting it to / ensures that the accessToken and csrf cookies are sent on every API request directed at the gateway, regardless of the API’s specific path (e.g., /api/v1/users, /v2/data).
If you run multiple distinct applications behind the same domain and want to isolate their cookies by route, you can specify a narrower path (e.g., /my-app/).
MSAL Auth: Cookie Secure
The cookieSecure property maps to the Secure attribute on the Set-Cookie headers generated by the gateway.
Configuration Options
cookieSecure: false
or
cookieSecure: true
Usage
When cookieSecure is set to true, the browser will only transmit the cookie over a secure, encrypted connection (HTTPS). It will flatly refuse to send the cookie over plain HTTP.
- Development: You typically set this to
falsewhen developing locally overhttp://localhost. - Production: You must set this to
truein production to prevent cookies from being intercepted by network eavesdroppers. - SameSite Dependency: If you configure
cookieSameSite: None(which allows cross-origin requests), modern browsers requirecookieSecureto betrue. IfcookieSameSite: Noneis paired withcookieSecure: false, browsers like Chrome and Edge will reject the cookie outright.
MSAL Auth: Session Timeout
The sessionTimeout property specifies the default expiration time (in seconds) for the session cookies, if the provided Microsoft Entra ID token lacks an explicit exp claim.
Configuration Options
sessionTimeout: 3600
Usage
When a user logs in via the /auth/ms/login endpoint, the gateway parses the Microsoft Entra ID token and looks for the exp (expiration) claim.
- If the token contains a valid
expclaim, the cookies are set to expire exactly when the Entra ID token expires. - If the token lacks an
expclaim, thesessionTimeoutvalue is used as a fallback to calculate the expiration duration.
When the cookies expire, the browser will stop sending them. To maintain uninterrupted access, the SPA is responsible for silently refreshing the Entra ID token via MSAL.js and calling /auth/ms/login again before the cookies expire.
Handler Config
Use the handler config to define which handlers are available, how handler chains are composed, and which chain runs for each request path.
Common properties:
handlers: handler aliases enabled for this gatewaychains: named handler chainspaths: request path and method mappingsdefaultHandlers: fallback chain when no path entry matches
Handler Path
Use handler paths to select the handler chain for an incoming gateway request.
Each path entry matches a request by HTTP method and path. The exec list names the chain or handlers to run.
Supported path patterns:
- exact path, such as
/customers - path template, such as
/customers/{customerId} - trailing wildcard, such as
/customers/*or/*
Examples:
paths:
- path: /customers/{customerId}
method: GET
exec:
- apiChain
- path: /customers/*
method: GET
exec:
- apiChain
- path: /*
method: POST
exec:
- apiChain
Important behavior:
/customersmatches only/customers/customers/{customerId}matches one segment after/customers/customers/*matches/customersand any deeper path under/customers/*matches any path for the configured method
For sidecar API proxy routes, point the matching API methods to the API proxy chain.
Portal View Concepts
This section contains reusable explanations for portal concepts referenced by many pages, forms, and tasks.
Concept help should be linked from page or field-level help when a short label or tooltip is not enough.
Ownership And Positions
Portal records can have an individual owner and a position owner.
owner_user_id is derived from the authenticated user when a record is created.
It should not be submitted from normal browser forms.
owner_position_id is optional and can be selected on owner-aware forms. It
allows users with the matching effective position to see or manage the record
when service-side authorization grants that scope.
Rows with no owner user and no owner position are legacy or unassigned records. They should normally be visible only to all-scope administrators until ownership is assigned.
Hosts And User Hosts
A host is the tenant boundary for most portal records.
User-host membership determines which host a user can work in. Most admin pages and generated forms operate against the currently selected host.
When a user cannot see expected records, first confirm that the correct host is selected and that the user has membership for that host.
API Versioning
An API is the stable business record. An API version is the concrete version that can be linked to instances, MCP tools, marketplace listings, and access control rules.
Create the API first, then create one or more API versions under it. Operational relationships should usually reference the API version instead of only the API.
OAuth Client Ownership
OAuth clients can be owned by apps, API versions, or instances depending on the selected creation context.
Ownership affects which users can see or modify client records. Regular users should manage only clients they own or can access through their position. Administrators can manage all clients for the host when their role allows it.
Implementation
Local Portal Setup
This guide starts the local Light Portal runtime from two sibling repositories:
~/lightapi/portal-config-loc
~/lightapi/service-asset
portal-config-loc contains the local Compose stacks and startup script.
service-asset contains the checked-in service jars, UI assets, released image
tags, and the event snapshot used to initialize a new local database.
Quick Start
Clone or update both repositories under ~/lightapi:
cd ~
mkdir -p lightapi
cd lightapi
git clone [email protected]:lightapi/portal-config-loc.git
git clone [email protected]:lightapi/service-asset.git
If they are already cloned:
cd ~/lightapi/portal-config-loc
git pull --rebase
cd ~/lightapi/service-asset
git pull --rebase
Optional: Use Your Own Events
The importer always reads this exact file:
~/lightapi/service-asset/events.json
To initialize a new local database with your own snapshot, replace
~/lightapi/service-asset/events.json before running deploy-local.sh for the
first time:
cp /path/to/your/events.json ~/lightapi/service-asset/events.json
Do not use a different filename. deploy-local.sh rejects EVENT_IMPORT_FILE
so every import path uses only service-asset/events.json. After the script has
started and imported events into Postgres, replacing the file will not change
the existing database. To reinitialize from a different file, remove the
Postgres named volume, replace service-asset/events.json, and then start the
script again with IMPORT_EVENTS=auto.
For Podman:
cd ~/lightapi/portal-config-loc/all-in-lt
podman compose -f docker-compose.yml -f docker-compose-rust.yml down -v
For Docker:
cd ~/lightapi/portal-config-loc/all-in-lt
docker compose -f docker-compose.yml -f docker-compose-rust.yml down -v
Start the Rust stack with Docker Compose:
cd ~/lightapi/portal-config-loc
COMPOSE_CMD="docker compose" \
CONTAINER_CMD=docker \
IMPORT_EVENTS=auto \
RUST_LOG=info \
./scripts/deploy-local.sh lt rust
Start the Rust stack with Podman Compose:
cd ~/lightapi/portal-config-loc
COMPOSE_CMD="podman compose" \
CONTAINER_CMD=podman \
IMPORT_EVENTS=auto \
RUST_LOG=info \
./scripts/deploy-local.sh lt rust
Open the portal at:
https://localhost
If the selected configuration uses hostnames such as dev.lightapi.net, add
them to the local hosts file and point them to 127.0.0.1.
What The Script Does
deploy-local.sh copies assets from the sibling service-asset repository into
the selected portal-config-loc stack only when the target directories are
missing or empty. It does not overwrite populated asset directories during a
normal run.
For the lt rust stack, the script starts all-in-lt with the Rust compose
override. It also passes service-asset/docker-images.env to Compose when that
file is present, so the stack can use the released image tags generated by the
asset release process.
When IMPORT_EVENTS=auto is set, the script waits for Postgres, checks
event_store_t, and imports service-asset/events.json only if the event
store is empty. This is intended for a brand new environment or after removing
the Postgres named volume. Leave IMPORT_EVENTS unset for normal restarts.
Automatic event import uses the event-importer container image by default:
CONTAINER_CMD=podman
EVENT_IMPORTER_IMAGE=networknt/event-importer:latest
Use EVENT_IMPORT_RUNNER=local only when you intentionally want to run the
host-side importer scripts from service-asset.
Postgres uses a Compose named volume called postgres-data instead of the
host bind directory postgres-db/data. This avoids rootless Podman permission
and SELinux label issues on Fedora Silverblue. To reset Postgres for a selected
stack, run Compose directly from that stack directory with down -v.
Ubuntu
Docker Compose is the simplest Ubuntu path. Install Docker Engine and the Compose plugin by following the official Docker Ubuntu guide, then run:
cd ~/lightapi/portal-config-loc
COMPOSE_CMD="docker compose" \
CONTAINER_CMD=docker \
IMPORT_EVENTS=auto \
RUST_LOG=info \
./scripts/deploy-local.sh lt rust
Podman also works on Ubuntu after installing Podman and a Compose provider:
cd ~/lightapi/portal-config-loc
COMPOSE_CMD="podman compose" \
CONTAINER_CMD=podman \
IMPORT_EVENTS=auto \
RUST_LOG=info \
./scripts/deploy-local.sh lt rust
References:
Fedora Silverblue
Fedora Silverblue already fits a Podman-first local workflow. Install the Compose provider once, then reboot into the new deployment:
sudo rpm-ostree install podman-compose
systemctl reboot
Rootless Podman normally cannot bind host port 443. The local configuration
expects https://localhost, so allow unprivileged processes to bind from 443
upward before starting the stack:
printf 'net.ipv4.ip_unprivileged_port_start=443\n' | \
sudo tee /etc/sysctl.d/99-rootless-low-ports.conf
sudo sysctl --system
Then start the stack:
cd ~/lightapi/portal-config-loc
COMPOSE_CMD="podman compose" \
CONTAINER_CMD=podman \
IMPORT_EVENTS=auto \
RUST_LOG=info \
./scripts/deploy-local.sh lt rust
References:
Postgres Permission Recovery
Postgres data is stored in a Compose named volume, not in
postgres-db/data. If you previously started the stack before this change and
hit a permission error on the old bind-mounted data directory, pull the latest
config and recreate the stack:
cd ~/lightapi/portal-config-loc
git pull --rebase
COMPOSE_CMD="podman compose" CONTAINER_CMD=podman ./scripts/deploy-local.sh lt rust stop
COMPOSE_CMD="podman compose" CONTAINER_CMD=podman IMPORT_EVENTS=auto ./scripts/deploy-local.sh lt rust
If you need a completely fresh database after a failed first run, remove the Compose volume before starting again:
cd ~/lightapi/portal-config-loc/all-in-lt
podman compose -f docker-compose.yml -f docker-compose-rust.yml down -v
Controller Certificate Recovery
If controller-rs fails with a message that
CONTROLLER_TLS_CERT_PATH points to missing /keystore/server.pem, use the
latest Compose files and recreate the Rust stack. The cert files are tracked in
all-in-lt/light-controller-rust, but rootless Podman on Silverblue needs the
keystore bind mount to be SELinux relabeled.
cd ~/lightapi/portal-config-loc
git pull --rebase
COMPOSE_CMD="podman compose" CONTAINER_CMD=podman ./scripts/deploy-local.sh lt rust restart
macOS
Docker Desktop is the simplest macOS path. Install Docker Desktop, start it, then run the same script from Terminal:
cd ~/lightapi/portal-config-loc
COMPOSE_CMD="docker compose" \
CONTAINER_CMD=docker \
IMPORT_EVENTS=auto \
RUST_LOG=info \
./scripts/deploy-local.sh lt rust
Podman Desktop can also be used. Start the Podman machine first, then use the Podman command form:
cd ~/lightapi/portal-config-loc
COMPOSE_CMD="podman compose" \
CONTAINER_CMD=podman \
IMPORT_EVENTS=auto \
RUST_LOG=info \
./scripts/deploy-local.sh lt rust
References:
Windows
Use WSL2 Ubuntu for the local development shell. Clone the repositories under the WSL home directory, not under a Windows drive mount:
~/lightapi/portal-config-loc
~/lightapi/service-asset
With Docker Desktop, enable WSL integration for the Ubuntu distribution and run the script inside the WSL shell:
cd ~/lightapi/portal-config-loc
COMPOSE_CMD="docker compose" \
CONTAINER_CMD=docker \
IMPORT_EVENTS=auto \
RUST_LOG=info \
./scripts/deploy-local.sh lt rust
Podman on Windows also works through a Podman machine, but WSL2 plus Docker Desktop is usually the shortest setup path for this local stack.
References:
Common Commands
Show status:
COMPOSE_CMD="podman compose" ./scripts/deploy-local.sh lt rust status
Show logs:
COMPOSE_CMD="podman compose" ./scripts/deploy-local.sh lt rust logs
Restart:
COMPOSE_CMD="podman compose" ./scripts/deploy-local.sh lt rust restart
Stop:
COMPOSE_CMD="podman compose" ./scripts/deploy-local.sh lt rust stop
Force event import:
COMPOSE_CMD="podman compose" \
CONTAINER_CMD=podman \
IMPORT_EVENTS=true \
./scripts/deploy-local.sh lt rust start
Sign In
Portal Dashboard
The Portal Dashboard is served by the portal-view single-page application.
-
Guest User Access:
Upon landing on the dashboard, a guest user can:- View certain menus.
- Perform limited actions within the application.
-
Accessing Privileged Features:
To access additional features:- Click the User button.
- Select the Sign In menu item.
Login View
-
Redirection to Login View:
When the Sign In menu item is clicked, the browser is redirected to the Login View single-page application. This application is served by the same instance oflight-gatewayand handles user authentication against the OAuth 2.0 server (OAuth Kafka) to initiate the Authorization Code grant flow. -
OAuth 2.0 Client ID:
Theclient_idis included in the redirect URL as a query parameter. This ensures that theclient_idis sent to the OAuth 2.0 server to obtain the authorization code. In this context, theclient_idis associated with theportal-viewapplication. -
Login View Responsibilities:
The Login View is a shared single-page application used by all other SPAs across various hosts. It is responsible for:- Authenticating users.
- Ensuring that user credentials are not passed to any other single-page applications or business APIs.
-
SaaS Deployment in the Cloud:
In a SaaS environment, all users are authenticated by the OAuth 2.0 server using thelight-portaluser database. As a result, the user type does not need to be passed from the Login View. -
On-Premise Deployment:
For on-premise deployments, a customized Login View should include a radio button for selecting the user type. Typical options for most organizations are:- Employee (E)
- Customer (C)
-
Customized Authentication:
Based on the selected user type:- Employees are authenticated via Active Directory.
- Customers are authenticated using the customer database.
A customized authenticator implementation should handle this logic, ensuring the correct authentication method is invoked for each user type.
Login Form Submission
-
Form Submission Endpoint:
/oauth2/N2CMw0HGQXeLvC1wBfln2A/code -
Request Details:
- Headers:
Content-Type:application/x-www-form-urlencoded
- Method:
POST
- Body Parameters:
j_username: The user’s username.j_password: The user’s password.remember: Indicates whether the session should persist.client_id: The OAuth 2.0 client identifier.state: A hardcoded value (requires additional work for dynamic handling).user_type: (Optional) Specifies the type of user (e.g., employee or customer).redirect_uri: (Optional) The URI to redirect after authentication.
- Headers:
Light Gateway
The light-gateway instance acts as a BFF and it has a routing rule to route any request with prefix /oauth2 to kafka-oauth server.
OAuth Kafka
-
LightPortalAuthenticator
A request to hybrid-query:
{"host":"lightapi.net","service":"user","action":"loginUser","version":"0.1.0","data":{"email":"%s","password":"%s"}}
User Query
- LoginUser
This handler calls loginUserByEmail method from PortalDbProviderImpl.
PortalDbProviderImpl
The input for this method is the user’s email. Upon successful execution, the method returns a JSON string containing all user properties retrieved from the login query.
LightPortalAuthenticator
The authenticator will utilize the user data returned from the above query to validate the password. Upon successful password verification, it will return an Account object with the following attributes:
- Principal: The user’s identifier, which is the email.
- Roles: A collection containing a single element—the user’s JSON
After the Account object is created and returned, control is passed to the HostIdCodePostHandler.
HostIdCodePostHandler
It get the client_id from the submitted form and call dbProvider.queryClientByClientId to get client information. Upon successful, it get the Account object created by the authenticator above from the security context.
Create a UUID authorization code and a map associates with the code. The map contains properties that need to create authorization code token. Some properties from the client and the entire user json.
Call the ClientUtil.createAuthCode with the codeMap to create the authorization code and then redirect the code to back to the redirect uri.
ClientUtil.createAuthCode
The ClientUtil gets a client credentials token and call the CreateAuthCode handler in the hybrid-command to publish the code to the Kafka cluster in order to notify other party about this code. The codeMap is passed to the handler as data.
CreateAuthCode Handler
The handler create a MarketCodeCreatedEvent and pass the entire input map to the event as value field.
MarketQueryStreams
It processes the MarketCodeCreatedEvent and calls dbProvider.createMarketCode with the event.
createMarketCode
This method in dbProvider will put the event value into cacheManager cache named “auth_code”. Now, the code is ready to be query from the market-query.
Portal View
The HostIdCodePostHandler redirects the code to the Portal View with /authorization?code=??? and this request will be sent to the light-gateway StatelessAuthHandler.
StatelessAuthHandler
If the request path matches to the configured authPath, it will retrieve the code from the query parameter. Then create a csrf UUID token and an AuthorizationCodeRequest to get a token via OauthHelper. This request will have the auth code, the csrf token and other properties from the configuration. The request is sent to the HostIdTokenPostHandler to create the authorization code token.
HostIdTokenPostHandler
It calls dbProvider.queryClientByClientId and then verify the clientId and clientSecret matches.
It invokes ClientUtil.getAuthCodeDetail from the market-query service and calls the ClientUtil.deleteAuthCode to remove the auth code as it is one-time code.
Login View
The login-view is a Single Page Application (SPA) built with React and Vite. It serves as the user interface for the OAuth 2.0 Authorization Code flow within the LightAPI ecosystem.
Overview
This application acts as the front-end for the Authorization Server. When a user attempts to access a protected resource on a client application (the “Portal”), they are redirected to this application to authenticate and grant consent.
It handles:
- User Authentication (Username/Password).
- Social Login (Google, Facebook, GitHub).
- OAuth 2.0 Consent Granting.
- Password Management (Forgot Password, Reset Password).
Technology Stack
- Framework: React 18
- Build Tool: Vite
- UI Library: Material UI (MUI) v6
- Routing: React Router DOM v6
- Social Login:
- Google:
@react-oauth/google - Facebook:
@greatsumini/react-facebook-login - GitHub: Manual OAuth 2.0 flow with
react-social-login-buttons
- Google:
Key Flows
1. OAuth 2.0 Authorization
The application expects to be opened with standard OAuth 2.0 query parameters:
client_id: The ID of the client application requesting access.response_type: Typicallycode.redirect_uri: Where to redirect after success.state: A random string generated by the client to prevent CSRF.scope: Requested permissions.
Process:
- The
Logincomponent extracts these parameters from the URL. - User submits credentials or uses social login.
- On success, the application receives an authorization code from the backend.
- To grant consent (if configured), the user is shown the
Consentscreen. - Finally, the browser is redirected to the
redirect_uriwith thecodeandstate.
2. Social Login Configuration
The application supports multiple identity providers.
- Google: Uses the modern Google Identity Services. Configured in
src/main.jsxviaGoogleOAuthProvider. - Facebook: Uses the Facebook SDK wrapper. Configured in
src/components/FbLogin.jsx. - GitHub: Uses a manual popup flow. The client ID is configured in
src/components/GithubLogin.jsx. The redirect URI/github/callbackhandles the code extraction.
3. Backend Integration
The application proxies API requests to the backend (Light Gateway/OAuth Provider) using vite.config.js proxy settings during development.
/oauth2/*: For token and code endpoints./portal/*: For user management commands (login query)./google,/facebook,/github: Endpoints to exchange social tokens/codes for LightAPI authorization codes.
Development
Setup
yarn install
Run Locally
yarn dev
Runs on https://localhost:5173 by default.
Build
yarn build
Generates production assets in the dist folder.
Project Structure
src/components/: Reusable UI components (Login forms, Social buttons).src/theme.js: MUI theme configuration.src/main.jsx: Application entry point and providers.vite.config.js: Vite configuration including proxy rules.
Portal Services
This section provides an overview of the services utilized by Light Portal. Each service is implemented as a separate repository and is initialized during the hybrid-query or hybrid-command startup process. These services are designed to handle specific functionalities within the portal and may interact with one another to execute complex operations.
Light Portal adopts the Command Query Responsibility Segregation (CQRS) pattern, categorizing services into two types: Query and Command. Query services manage read operations, while Command services handle write operations, ensuring a clear separation of responsibilities.
Attribute Service
Attribute Query Service
Handles queries related to attributes.
Important Links
Services Used
–
Attribute Command Service
Handles commands related to attributes.
Important Links
Services Used
user-query
Client Service
Client Query Service
Handles queries related to clients.
Important Links
Services Used
–
Client Command Service
Handles commands related to clients.
Important Links
Services Used
user-query
Config Service
Config Query Service
Handles queries related to configurations.
Important Links
Services Used
–
Config Command Service
Handles commands related to configurations.
Important Links
Services Used
user-queryconfig-query
Deployment Service
Deployment Query Service
Handles queries related to deployments.
Important Links
Services Used
–
Deployment Command Service
Handles commands related to deployments.
Important Links
Services Used
user-query
Group Service
Group Query Service
Handles queries related to groups.
Important Links
Services Used
–
Group Command Service
Handles commands related to groups.
Important Links
Services Used
user-query
Host Service
Host Query Service
Handles queries related to hosts.
Important Links
Services Used
–
Host Command Service
Handles commands related to hosts.
Important Links
Services Used
user-query
Instance Service
Instance Query Service
Handles queries related to instances.
Important Links
Services Used
–
Instance Command Service
Handles commands related to instances.
Important Links
Services Used
user-query
OAuth Service
OAuth Query Service
Handles queries related to OAuth.
Important Links
Services Used
–
OAuth Command Service
Handles commands related to OAuth.
Important Links
Services Used
user-queryoauth-query
Position Service
Position Query Service
Handles queries related to positions.
Important Links
Services Used
–
Position Command Service
Handles commands related to positions.
Important Links
Services Used
user-query
Product Service
Product Query Service
Handles queries related to products.
Important Links
Services Used
–
Product Command Service
Handles commands related to products.
Important Links
Services Used
user-query
Role Service
Role Query Service
Handles queries related to roles.
Important Links
Services Used
–
Role Command Service
Handles commands related to roles.
Important Links
Services Used
user-query
Rule Service
Rule Query Service
Handles queries related to rules.
Important Links
Services Used
service-query
Rule Command Service
Handles commands related to rules.
Important Links
Services Used
user-queryhost-query
Service Service
Service Query Service
Handles queries related to services.
Important Links
Services Used
–
Service Command Service
Handles commands related to services.
Important Links
Services Used
user-query
User Service
User Query Service
Handles queries related to users.
Important Links
Services Used
–
User Command Service
Handles commands related to users.
Important Links
Services Used
user-queryservice-query
Portal View
OAuth 2.0 State Verification
This document describes the implementation of CSRF protection for the OAuth 2.0 authorization code flow in the portal-view application.
Overview
To prevent Cross-Site Request Forgery (CSRF) attacks during the OAuth 2.0 authentication process, we implement a state parameter check. A random state string is generated before the authentication request and verified upon the callback.
Implementation Details
State Generation
Location: src/components/Header/ProfileMenu.tsx
When the user initiates the sign-in process:
- A random alphanumeric string is generated.
- This string is stored in the browser’s
localStorageunder the keyportal_auth_state. - The string is appended as the
statequery parameter to the OAuth 2.0 authorization URL.
// Generate a random state for CSRF protection
const state = Math.random().toString(36).substring(7);
localStorage.setItem('portal_auth_state', state);
const defaultUrl =
`https://locsignin.lightapi.net?client_id=...&state=${state}`;
Redirect Handling
Location: src/App.tsx
To ensure the state query parameter is preserved during the redirect from the root path (/) to the dashboard, a custom RedirectWithQuery component is used. This component handles both standard query parameters and hash-based redirects (common with certain OAuth providers or router configurations).
- Checks
window.location.hashfor paths (e.g.,/#/app/dashboard?state=...). - Prioritizes the hash path if present to ensure
react-routerreceives the correct target. - Appends existing query parameters from
useLocation().search. - Uses
useNavigatefor the redirection.
const RedirectWithQuery = ({ to }: { to: string }) => {
// ... logic to preserve search params and handle hash paths
if (window.location.pathname === to) return; // Prevent loop
// ...
navigate(target, { replace: true });
};
State Verification
Location: src/pages/dashboard/Dashboard.tsx
Upon successful authentication, the provider redirects the user back to the application (defaulting to the Dashboard).
- The application retrieves the
stateparameter from the URL query string. - It retrieves the stored state from
localStorage(portal_auth_state). - The two values are compared:
- Match: The verification succeeds, and the
portal_auth_stateis removed fromlocalStorage. - Mismatch: The verification fails. The user is alerted and immediately logged out via
signOutto protect the session.
- Match: The verification succeeds, and the
useEffect(() => {
const searchParams = new URLSearchParams(location.search);
const state = searchParams.get('state');
// Check if we have a state and haven't attempted verification yet in this mount
if (state && !verificationAttempted.current) {
verificationAttempted.current = true;
const storedState = localStorage.getItem('portal_auth_state');
if (storedState === state) {
console.log('OAuth state verified successfully.');
localStorage.removeItem('portal_auth_state');
// Remove state from URL to prevent re-verification
const newSearchParams = new URLSearchParams(location.search);
newSearchParams.delete('state');
navigate({ search: newSearchParams.toString() }, { replace: true });
} else {
console.error('OAuth state mismatch. Potential CSRF attack.');
alert('OAuth state mismatch. Potential CSRF attack. Logging out...');
signOut(userDispatch, navigate);
}
}
}, [location, navigate, userDispatch]);
Testing State Mismatch (Manual Steps)
To manually verify the security logout mechanism:
- Ensure you are logged in to the application.
- Open your browser’s Developer Tools (F12) and go to the Console tab.
- Set a dummy “valid” state in your local storage:
localStorage.setItem('portal_auth_state', 'my_secret_state'); - Manually modify the URL to include a different state parameter.
- Example:
https://localhost:3000/app/dashboard?state=attackers_fake_state - Note: If using hash routing, ensure it is inside the hash:
https://localhost:3000/#/app/dashboard?state=attackers_fake_state
- Example:
- Press Enter to navigate.
Expected Result:
- An alert appears: “OAuth state mismatch. Potential CSRF attack. Logging out…”
- The user is immediately signed out of the application.
Configuration
light-gateway
Client Credentials Token
All the accesses from the light-gateway to the downstream APIs should have at least one token in the Authorization header. If there is an authorization code token in the Authorization header, then a client credentials token will be added to the X-Scope-Token header by the TokenHandler.
Since all light portal services have the same scopes (portal.r and portal.w), one token should be enough for accessing all APIs.
Add the client credentials token config in client.yml section.
# Client Credential
client.tokenCcUri: /oauth2/N2CMw0HGQXeLvC1wBfln2A/token
client.tokenCcClientId: f7d42348-c647-4efb-a52d-4c5787421e72
client.tokenCcClientSecret: f6h1FTI8Q3-7UScPZDzfXA
client.tokenCcScope:
- portal.r
- portal.w
Add TokenHandler to the handler.yml section.
# handler.yml
handler.handlers:
.
.
.
- com.networknt.router.middleware.TokenHandler@token
.
.
.
handler.chains.default:
.
.
.
- prefix
- token
- router
Add the TokenHandler configuration token.yml section.
# token.yml
token.enabled: true
token.appliedPathPrefixes:
- /r
light-reference
Cors Configuration
As the light-gateway is handling the SPA interaction and cors, we don’t need to enable the cors on the reference API. However, the cors handler is still registered in the default handler.yml in case the reference API is used as a standalone service.
In the light-portal configuration, we need to disable the cors.
# cors.yml
cors.enabled: false
Client Configuration
We need to load the jwk from the oauth-kafka service to validate the incoming jwk tokens. To set up the jwk, add the following lines to the values.yml file.
# client.yml
client.tokenKeyServerUrl: https://localhost:6881
client.tokenKeyUri: /oauth2/N2CMw0HGQXeLvC1wBfln2A/keys
Test
Automated Integration Testing & AI Agent Strategy for Light-Portal
Document Type: Engineering Strategy / Architecture
System: Light-Portal (Multi-Service Architecture)
1. Executive Summary
As Light-Portal scales into a complex multi-service ecosystem, traditional end-to-end (E2E) tests become too slow, brittle, and difficult to maintain. To enable rapid updates without fear of regression, we must adopt a Shift-Left Layered Integration Approach.
Furthermore, to minimize the manual overhead of test creation and maintenance, this strategy incorporates AI QA Agents capable of autonomously generating, executing, and self-healing test suites based on structured declarative specifications.
2. Core Automated Integration Strategy
To test inter-service communication reliably and rapidly, we will implement the following methodologies:
A. Consumer-Driven Contract (CDC) Testing
Instead of spinning up the entire portal ecosystem to test a single integration, we will use Pact.
- How it works: The “Consumer” service defines the expected API structure (the contract). The “Provider” service checks its responses against this contract during its CI pipeline.
- Benefit: Catches breaking API changes instantaneously without requiring a full staging environment.
B. Ephemeral Environments
Tests should never rely on shared, persistent environments which are prone to state pollution.
- Tooling: Testcontainers or dynamic Docker Compose files.
- Execution: During the CI/CD pipeline, isolated instances of necessary services (e.g., databases, message brokers like Kafka, OAuth providers) are spun up, tested against, and destroyed.
C. API-First Testing
Because Light-Portal relies on strict API boundaries, UI-based testing should be minimized for integration validation.
- Tooling: Karate DSL or REST Assured.
- Benefit: Tests the actual data contracts and service boundaries directly, resulting in faster and more resilient tests.
D. Mocking External Dependencies
- Tooling: WireMock or Mountebank.
- Usage: Stub out third-party APIs or external legacy systems to ensure our integration tests are entirely deterministic and not subject to external network failures.
3. AI Agent Automation Capabilities
Autonomous AI agents can significantly reduce the testing bottleneck. Within this architecture, AI agents will be utilized for the following tasks:
- Test Generation: Automatically parse OpenAPI specifications to generate exhaustive test suites covering positive paths, edge cases, and error handling (400, 401, 429, 500).
- Self-Healing Test Pipelines: When an engineer modifies an API schema intentionally, the AI agent will detect the resulting broken test, read the commit diff, and automatically generate a Pull Request to align the test with the new API schema.
- Synthetic Data Generation: Generate realistic, schema-compliant JSON payloads for testing, avoiding hard-coded or outdated mock data.
- State Machine Exploration: Execute multi-step user journeys by exploring the API state (e.g., Authenticate -> Register Service -> Query Gateway -> Validate Routing).
4. AI-Optimized Test Specifications & Plans
AI agents require structured, semantic, and declarative inputs to function reliably. To direct the AI agent, we will provide test plans in the following formats:
A. OpenAPI / AsyncAPI Specifications (The Golden Source)
The most effective way to instruct an AI is to provide the API design spec.
- AI Action: The agent reads
openapi.yaml, identifies required headers (e.g., JWT authorizations) and payload schemas, and writes the baseline integration code automatically.
B. Behavior-Driven Development (BDD) / Gherkin Syntax
For complex business logic, engineers and product managers will write Gherkin specs. The AI agent translates this plain English into executable API scripts.
Example Spec:
Feature: Light-Portal Service Registration
Scenario: Registering a new microservice routing path
Given the light-oauth2 service provides a valid admin JWT
When I send a POST request to "/portal/services" with the following payload:
"""
{
"serviceId": "demo-service",
"route": "/api/v1/demo"
}
"""
Then the response status should be 201
And the service should be discoverable via the light-router instance
C. Declarative YAML Test Workflows
Instead of writing imperative code (Java/Node.js), test workflows should be written in YAML. YAML is highly deterministic and minimizes AI syntax hallucinations.
Example Spec:
# AI Agent Workflow Instructions
name: Developer Onboarding Flow
steps:
- name: Get Token
api: POST /oauth/token
extract:
token: response.body.access_token
- name: Register Service
api: POST /portal/services
headers:
Authorization: Bearer ${token}
assert:
status: 200
D. Flow-Based “User Stories” (Agentic Prompting)
For autonomous exploration, the AI can be given high-level flow objectives. The agent is responsible for breaking the flow into actual API requests.
Example Prompt to Agent:
“Simulate a developer onboarding flow for Light-Portal. 1. Request an OAuth token. 2. Register a new mock-service to the portal. 3. Update the rate-limiting configuration for that service to 5 requests per minute. 4. Send 10 concurrent requests to verify the rate limit correctly throws a 429 error.”
5. Conclusion & Next Steps
By combining Contract Testing (Pact), Ephemeral Environments (Testcontainers), and Declarative AI-driven Automation, Light-Portal can scale its microservices with confidence.
Immediate Action Items:
- Standardize and centralize all
openapi.yamlfiles for Light-Portal services. - Integrate Testcontainers into the primary CI/CD pipeline.
- Select an AI testing tool/framework (e.g., CodiumAI, Postman Postbot, or a custom LLM script) and seed it with our initial Gherkin business flows.